Непрерывная проверка с помощью Azure Load Testing и Azure Chaos Studio
Так как облачные приложения и службы становятся более сложными, развертывание изменений и новых выпусков для них может быть сложной задачей. Сбои часто вызываются неисправными развертываниями или выпусками. Но ошибки также могут возникать после развертывания, когда приложение начинает получать реальный трафик, особенно в сложных рабочих нагрузках, работающих в высокораспространяемых мультитенантных облачных средах и поддерживаемых несколькими командами разработчиков. В этих средах требуется больше мер устойчивости, таких как логика повторных попыток и автомасштабирование, которые обычно трудно протестировать во время процесса разработки.
Именно поэтому непрерывная проверка в среде, которая похожа на рабочую среду, важна, чтобы можно было найти и устранить все проблемы или ошибки как можно раньше в цикле разработки. Команды рабочей нагрузки должны протестировать на ранних этапах процесса разработки (shift слева) и сделать его удобным для разработчиков для тестирования в среде, близкой к рабочей среде.
Критически важные рабочие нагрузки имеют требования к доступности с целевыми показателями 3, 4 или 5 девяти (99,9%, 99,99%, или 99,999%, соответственно). Важно реализовать тщательное автоматизированное тестирование для достижения этих целей.
Непрерывная проверка зависит от каждой рабочей нагрузки и от архитектурных характеристик. В этой статье приведено руководство по подготовке и интеграции Azure Load Testing и Azure Chaos Studio в обычный цикл разработки.
1. Определение тестов на основе ожидаемых пороговых значений
Непрерывное тестирование — это сложный процесс, требующий надлежащей подготовки. Что будет проверено, и ожидаемые результаты должны быть четкими.
В PE:06 — Рекомендации для тестирования производительности и RE:08 — Рекомендации для разработки стратегии тестирования надежности, платформа Azure Well-Architected Framework рекомендует начать с определения ключевых сценариев, зависимостей, ожидаемого использования, доступности, производительности и целевых показателей масштабируемости.
Затем необходимо определить набор измеримых пороговых значений , чтобы оценить ожидаемую производительность ключевых сценариев.
Совет
Примеры пороговых значений включают ожидаемое количество входов пользователей, запросов в секунду для заданного API и операций в секунду для фонового процесса.
Для разработки модели работоспособности приложения следует использовать пороговые значения, как для тестирования, так и для работы приложения в рабочей среде.
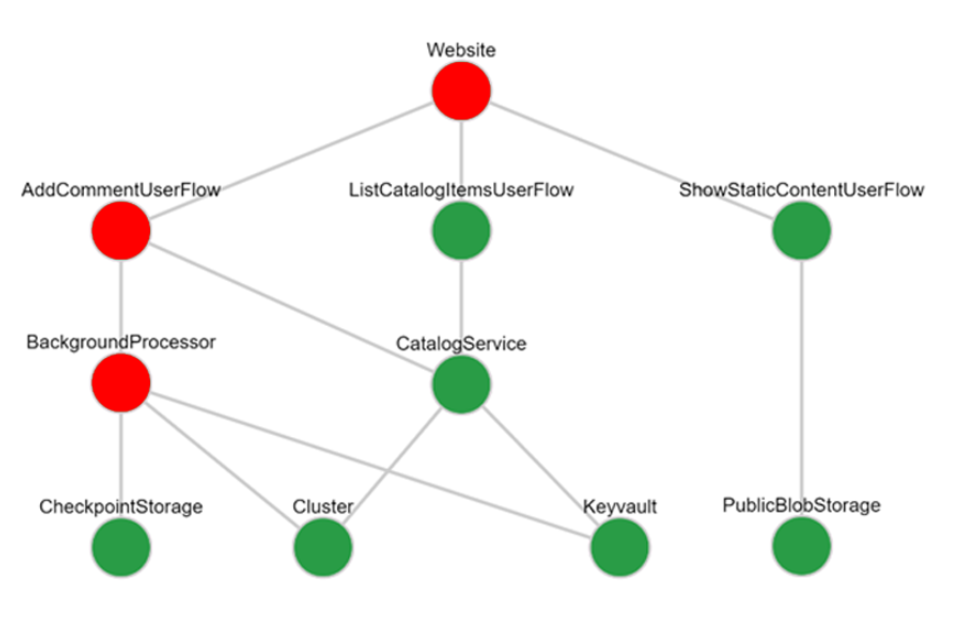
Затем используйте значения для определения нагрузочного теста, который создает реалистичный трафик для тестирования базовой производительности приложения, проверки ожидаемых операций масштабирования и т. д. Устойчивый искусственный трафик пользователей необходим в предварительной среде, так как без использования трудно выявить проблемы со средой выполнения.
Нагрузочное тестирование гарантирует, что изменения, внесенные в приложение или инфраструктуру, не вызывают проблем, и система по-прежнему соответствует ожидаемым критериям производительности и тестирования. Сбой тестового запуска, который не соответствует критериям теста, указывает, что необходимо настроить базовый план или произошла непредвиденная ошибка.
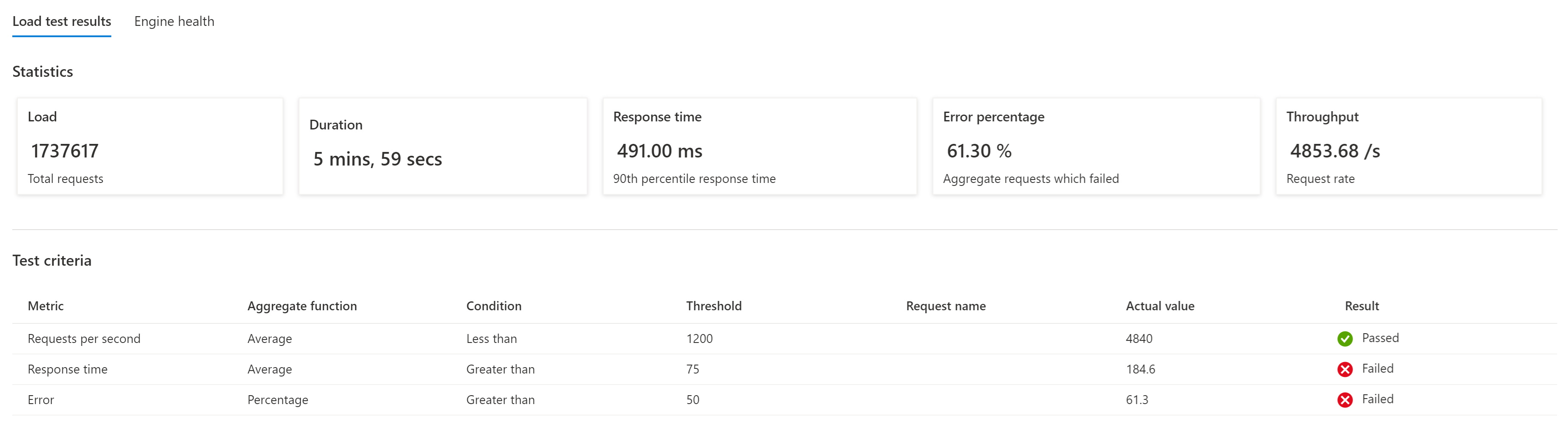
Несмотря на то, что автоматические тесты представляют ежедневное использование, следует регулярно запускать нагрузочные тесты вручную, чтобы проверить, как система реагирует на непредвиденные пики.
Второй частью непрерывной проверки является внедрение сбоев (инженерии хаоса). На этом шаге проверяется устойчивость системы, проверяя, как она реагирует на ошибки. Кроме того, все меры устойчивости, такие как логика повторных попыток, автомасштабирование и другие, работают должным образом.
2. Реализация проверки с помощью Load Testing и Chaos Studio
Microsoft Azure предоставляет эти управляемые службы для реализации нагрузочного тестирования и проектирования хаоса:
- Нагрузочное тестирование Azure создает синтетическую нагрузку пользователей на приложения и службы.
- Azure Chaos Studio предоставляет возможность выполнять эксперименты с хаосом, систематически внедряя сбои в компоненты приложений и инфраструктуру.
Вы можете развернуть и настроить Студию Хаоса и нагрузочное тестирование с помощью портал Azure, но в контексте непрерывной проверки более важно, чтобы у вас есть API для развертывания, настройки и запуска тестов программным и автоматизированным способом. Использование этих двух средств позволяет наблюдать, как система реагирует на проблемы и ее способность самостоятельно исцеляться в ответ на ошибки инфраструктуры или приложений.
В следующем видео показана объединенная реализация Chaos и Load Testing , интегрированная в Azure DevOps:
Если вы разрабатываете критически важную рабочую нагрузку, воспользуйтесь эталонными архитектурами, подробными рекомендациями, примерами реализаций и артефактами кода, предоставляемыми в рамках проекта Azure Mission-Critical и Azure Well-Architected Framework.
Реализация Критически важных задач развертывает службу нагрузочного тестирования с помощью Terraform и содержит коллекцию скриптов оболочки PowerShell Core для взаимодействия со службой через его API. Эти скрипты можно внедрить непосредственно в конвейер развертывания.
Одним из вариантов в эталонной реализации является выполнение нагрузочного теста непосредственно из сквозного конвейера (e2e), который используется для создания отдельных сред разработки (ветвей).

Конвейер автоматически запускает нагрузочный тест с экспериментами хаоса (в зависимости от выбора) параллельно:
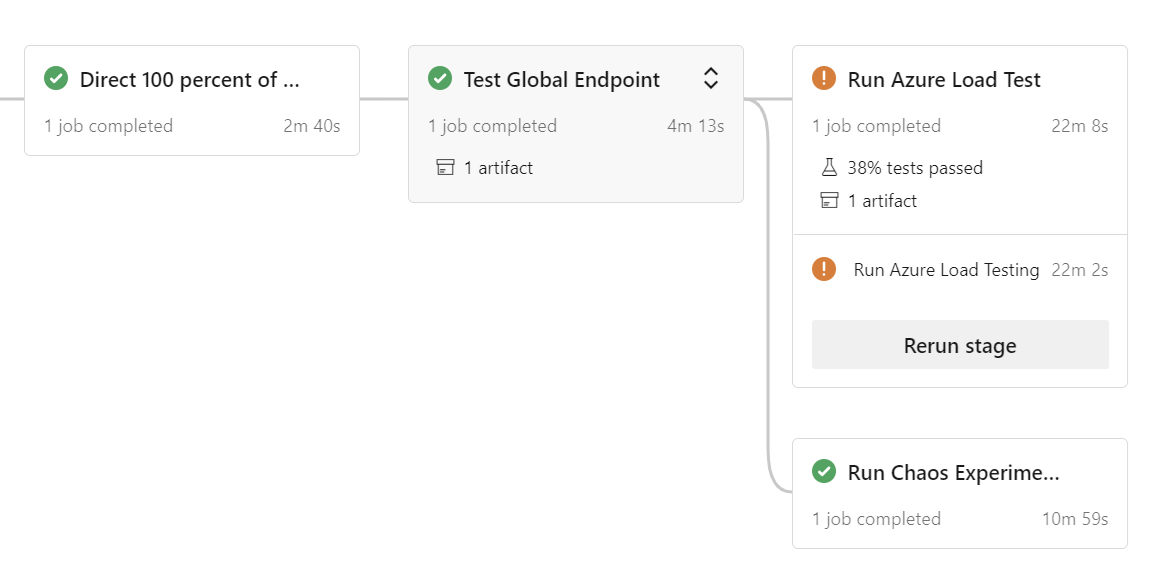
Примечание.
Выполнение экспериментов хаоса во время нагрузочного теста может привести к увеличению задержки, увеличению времени отклика и временному увеличению частоты ошибок. Вы заметите более высокие числа до завершения операции горизонтального масштабирования или отработки отказа по сравнению с запуском без экспериментов хаоса.
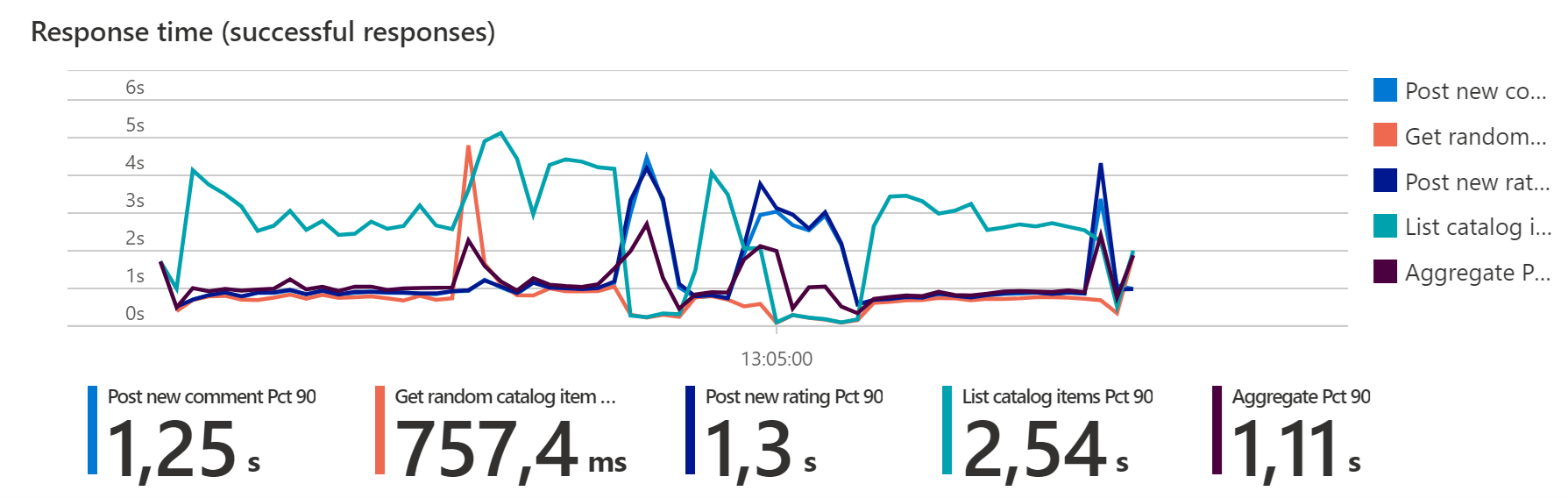
В зависимости от того, включено ли тестирование хаоса и выбор экспериментов, определения базовых показателей могут отличаться, так как допустимость ошибок может отличаться в "обычном" состоянии и "хаосе".
3. Настройка пороговых значений и установка базовых показателей
Наконец, настройте пороговые значения нагрузочного теста для регулярных запусков, чтобы убедиться, что приложение (по-прежнему) обеспечивает ожидаемую производительность и не создает никаких ошибок. У вас есть отдельный базовый план для тестирования хаоса, который допускает ожидаемые пики ошибок и временные снижение производительности. Это действие непрерывно и должно повторяться регулярно. Например, после внедрения новых функций, изменения номеров SKU службы и других.
Служба нагрузочного тестирования Azure предоставляет встроенную возможность, называемую критериями тестирования, которые позволяют указать определенные критерии, необходимые для прохождения теста. Эту возможность можно использовать для реализации различных базовых показателей.

Эта возможность доступна через портал Azure, а также с помощью API нагрузочного тестирования, а скрипты-оболочки, разработанные в рамках миссии Azure, предоставляют возможность передачи определения базовых показателей на основе JSON.
Мы настоятельно рекомендуем интегрировать эти тесты непосредственно в конвейеры CI/CD и запускать их на ранних этапах разработки компонентов. Пример реализации см. в примере реализации критически важных ссылок Azure.
В итоге сбой неизбежен в любой сложной распределенной системе, поэтому решение должно быть архитектором (и тестировать) для обработки сбоев. Рекомендации по критически важным рабочим нагрузкам и эталонные реализации платформы well-architected Framework помогают разрабатывать и работать с высоконадежными приложениями, чтобы получить максимальное значение из облака Майкрософт.
Следующий шаг
Просмотрите область разработки развертывания и тестирования для критически важных рабочих нагрузок.