Архитектурные подходы к ИИ и ML в мультитенантных решениях
Постоянно увеличивающееся число мультитенантных решений строится вокруг искусственного интеллекта (ИИ) и машинного обучения (ML). Мультитенантное решение AI/ML — это решение, которое предоставляет аналогичные возможности на основе машинного обучения любому количеству клиентов. Как правило, клиенты не могут просматривать или предоставлять общий доступ к данным любого другого клиента, но в некоторых ситуациях клиенты могут использовать те же модели, что и другие клиенты.
Архитектуры многотенантного искусственного интеллекта и машинного обучения должны учитывать требования к данным и моделям, а также вычислительные ресурсы, необходимые для обучения моделей и выполнения вывода из моделей. Важно учитывать, насколько многотенантные модели ИИ/ML развертываются, распределяются и оркестрируются, а также обеспечивают точность, надежность и масштабируемость решения.
Как генерируемые технологии ИИ, созданные на основе больших и небольших языковых моделей, получают популярность, важно установить эффективные операционные методики и стратегии управления этими моделями в рабочих средах с помощью внедрения Машинное обучение Operations (MLOps) и GenAIOps (иногда известных как LLMOps).
Ключевые рекомендации и требования
При работе с ИИ и машинным обучением важно отдельно учитывать требования к обучению и выводу. Цель обучения — создать прогнозную модель, основанную на наборе данных. Вы выполняете вывод при использовании модели для прогнозирования чего-то в приложении. Каждый из этих процессов имеет разные требования. В мультитенантном решении следует учитывать, как модель аренды влияет на каждый процесс. Учитывая все эти требования, вы можете убедиться, что ваше решение обеспечивает точные результаты, хорошо работает под нагрузкой, экономичен и может масштабироваться для будущего роста.
Изоляция арендаторов
Убедитесь, что клиенты не получают несанкционированный или нежелательный доступ к данным или моделям других клиентов. Обработка моделей с аналогичной чувствительностью к необработанным данным, обученным им. Убедитесь, что клиенты понимают, как их данные используются для обучения моделей и как модели, обученные на данных других клиентов, могут использоваться для вывода в своих рабочих нагрузках.
Существует три распространенных подхода к работе с моделями машинного обучения в мультитенантных решениях: модели для конкретного клиента, общие модели и настроенные общие модели.
Модели для конкретного клиента
Модели, относящиеся к клиенту, обучены только для данных для одного клиента, а затем применяются к одному клиенту. Модели, относящиеся к клиенту, подходят для конфиденциальных данных клиентов или при наличии малой области для изучения данных, предоставляемых одним клиентом, и применяете модель к другому клиенту. На следующей схеме показано, как можно создать решение с моделями для отдельных клиентов для двух клиентов:
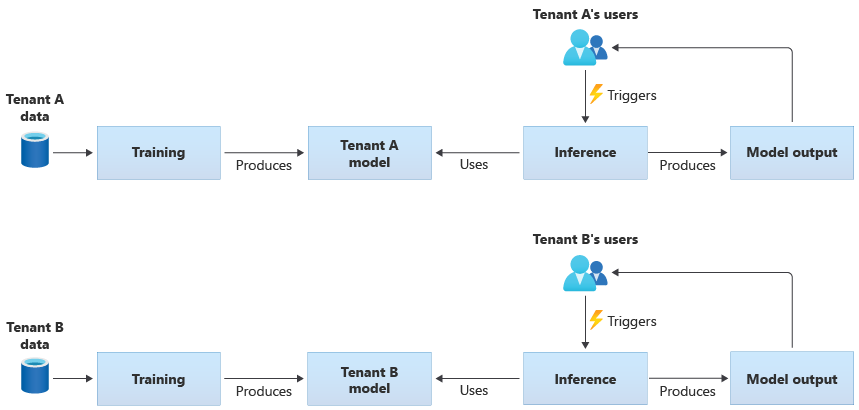
Общие модели
В решениях, использующих общие модели, все клиенты выполняют вывод на основе одной общей модели. Общие модели могут быть предварительно обученными моделями, которые вы приобретаете или получаете из источника сообщества. На следующей схеме показано, как можно использовать одну предварительно обученную модель для вывода всеми клиентами:
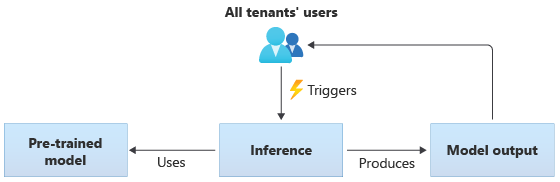
Вы также можете создавать собственные общие модели, обучая их на основе данных, предоставляемых всеми клиентами. На следующей схеме показана одна общая модель, которая обучена данным из всех клиентов:
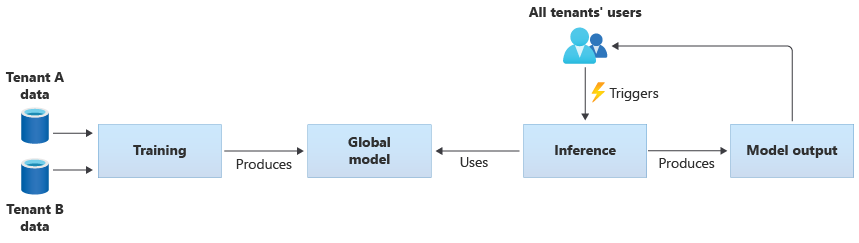
Внимание
Если вы обучаете общую модель из данных клиентов, убедитесь, что ваши клиенты понимают и согласны использовать свои данные. Убедитесь, что данные идентификации удаляются из данных клиентов.
Рассмотрим, что делать, если объекты клиента для их данных используются для обучения модели, которая будет применена к другому клиенту. Например, вы сможете исключить данные конкретных клиентов из обучаемого набора данных?
Настроенные общие модели
Вы также можете приобрести предварительно обученную базовую модель, а затем выполнить дальнейшую настройку модели, чтобы сделать ее применимой к каждому клиенту на основе собственных данных. На следующей схеме показан такой подход:
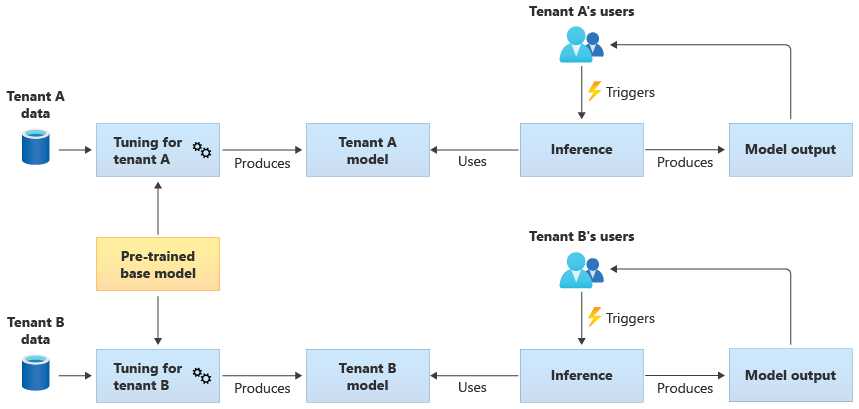
Масштабируемость
Рассмотрим, как рост вашего решения влияет на использование компонентов искусственного интеллекта и машинного обучения. Рост может ссылаться на увеличение числа клиентов, объема данных, хранящихся для каждого клиента, количества пользователей и объема запросов к решению.
Учебный курс. Существует несколько факторов, влияющих на ресурсы, необходимые для обучения моделей. Эти факторы включают количество моделей, которые необходимо обучить, объем данных, с которыми вы обучаете модели, и частоту обучения или переобучения моделей. Если вы создаете модели для конкретного клиента, то по мере роста числа клиентов объем вычислительных ресурсов и хранилища, которые требуется, также будет расти. Если вы создаете общие модели и обучаете их на основе данных всех клиентов, скорее всего, ресурсы для обучения будут масштабироваться на том же уровне, что и рост числа клиентов. Однако увеличение общего объема обучающих данных повлияет на используемые ресурсы для обучения как общих, так и для конкретных клиентов моделей.
Вывод. Ресурсы, необходимые для вывода, обычно пропорциональны количеству запросов, обращаюющихся к моделям вывода. По мере увеличения числа клиентов число запросов также может увеличиться.
Рекомендуется использовать службы Azure, которые хорошо масштабируется. Так как рабочие нагрузки AI/ML обычно используют контейнеры, Служба Azure Kubernetes (AKS) и Экземпляры контейнеров Azure (ACI), как правило, являются общими вариантами для рабочих нагрузок AI/ML. AKS обычно является хорошим выбором, чтобы обеспечить высокий масштаб и динамически масштабировать вычислительные ресурсы на основе спроса. Для небольших рабочих нагрузок ACI может быть простой вычислительной платформой для настройки, хотя она не масштабируется так же легко, как AKS.
Производительность
Учитывайте требования к производительности для компонентов ИИ/ML решения как для обучения, так и для вывода. Важно уточнить задержку и требования к производительности для каждого процесса, чтобы можно было измерять и улучшать по мере необходимости.
Учебный курс. Обучение часто выполняется как пакетный процесс, что означает, что это может быть не так важно, как производительность, как и другие части рабочей нагрузки. Однако необходимо убедиться, что вы подготавливаете достаточные ресурсы для эффективного обучения модели, в том числе по мере масштабирования.
Вывод: вывод — это процесс с учетом задержки, часто требующий быстрого или даже ответа в режиме реального времени. Даже если вам не нужно выполнять вывод в режиме реального времени, убедитесь, что вы отслеживаете производительность решения и используете соответствующие службы для оптимизации рабочей нагрузки.
Рекомендуется использовать высокопроизводительные вычислительные возможности Azure для рабочих нагрузок искусственного интеллекта и машинного обучения. Azure предоставляет множество различных типов виртуальных машин и других экземпляров оборудования. Рассмотрите возможность использования ЦП, GPU, FPGAs или других аппаратных сред. Azure также предоставляет вывод в режиме реального времени с графическими процессорами NVIDIA, включая серверы вывода NVIDIA Triton. Для низкоприоритетных требований к вычислительным ресурсам рекомендуется использовать пулы точечных узлов AKS. Дополнительные сведения об оптимизации вычислительных служб в мультитенантном решении см. в разделе "Архитектурные подходы" для вычислений в мультитенантных решениях.
Обучение модели обычно требует большого количества взаимодействий с хранилищами данных, поэтому важно также рассмотреть стратегию данных и производительность уровня данных. Дополнительные сведения о мультитенантности и службах данных см. в разделе "Архитектурные подходы к хранилищу и данным" в мультитенантных решениях.
Рассмотрите возможность профилирования производительности решения. Например, Машинное обучение Azure предоставляет возможности профилирования, которые можно использовать при разработке и инструментировании решения.
Сложность реализации
При создании решения для использования искусственного интеллекта и машинного обучения можно использовать предварительно созданные компоненты или создавать пользовательские компоненты. Необходимо принять два ключевых решения. Первым является платформа или служба , используемая для искусственного интеллекта и машинного обучения. Во-вторых, следует ли использовать предварительно обученные модели или создавать собственные пользовательские модели.
Платформы. Существует множество служб Azure, которые можно использовать для рабочих нагрузок искусственного интеллекта и машинного обучения. Например, службы ИИ Azure и Служба Azure OpenAI предоставляют API для выполнения вывода с предварительно созданными моделями, а корпорация Майкрософт управляет базовыми ресурсами. Службы искусственного интеллекта Azure позволяют быстро развертывать новое решение, но это дает вам меньше контроля над выполнением обучения и вывода, и это может не соответствовать каждому типу рабочей нагрузки. В отличие от этого, Машинное обучение Azure — это платформа, которая позволяет создавать, обучать и использовать собственные модели машинного обучения. Машинное обучение Azure обеспечивает контроль и гибкость, но повышает сложность проектирования и реализации. Просмотрите продукты и технологии машинного обучения от Корпорации Майкрософт , чтобы принять обоснованное решение при выборе подхода.
Модели. Даже если вы не используете полную модель, предоставляемую службой, такой как службы ИИ Azure, вы все равно можете ускорить разработку с помощью предварительно обученной модели. Если предварительно обученная модель не соответствует вашим потребностям, рассмотрите возможность расширения предварительно обученной модели, применяя метод, называемый передачей обучения или тонкой настройки. Передача обучения позволяет расширить существующую модель и применить ее к другому домену. Например, если вы создаете службу рекомендаций по мультитенантной музыке, вы можете рассмотреть возможность создания предварительно обученной модели рекомендаций по музыке и использовать обучение для обучения модели для настройки музыки конкретного пользователя.
Используя предварительно созданные платформы машинного обучения, такие как Службы ИИ Azure или Azure OpenAI Service, или предварительно обученную модель, вы можете значительно сократить начальные затраты на исследования и разработку. Использование предварительно созданных платформ может спасти вас много месяцев исследований и избежать необходимости набирать высококвалифицированных специалистов по обработке и анализу данных для обучения, проектирования и оптимизации моделей.
Оптимизация затрат
Как правило, рабочие нагрузки искусственного интеллекта и машинного обучения влечет за собой большую долю своих затрат на вычислительные ресурсы, необходимые для обучения и вывода моделей. Ознакомьтесь с подходами архитектуры для вычислений в мультитенантных решениях , чтобы понять, как оптимизировать затраты на рабочую нагрузку вычислений для ваших требований.
При планировании затрат на ИИ и машинное обучение следует учитывать следующие требования:
- Определите номера SKU вычислений для обучения. Например, ознакомьтесь с рекомендациями по работе с Машинное обучение Azure.
- Определите номера SKU вычислений для вывода. Пример оценки затрат для вывода см. в руководстве по Машинное обучение Azure.
- Отслеживайте использование. Наблюдая за использованием вычислительных ресурсов, вы можете определить, следует ли уменьшать или увеличивать их емкость, развертывая разные номера SKU или масштабируя вычислительные ресурсы по мере изменения требований. См. Машинное обучение Azure Монитор.
- Оптимизируйте среду кластеризации вычислений. При использовании вычислительных кластеров отслеживайте использование кластера или настраивайте автоматическое масштабирование для уменьшения масштаба вычислительных узлов.
- Общий доступ к вычислительным ресурсам. Рассмотрим, можно ли оптимизировать затраты вычислительных ресурсов, предоставив им общий доступ между несколькими клиентами.
- Рассмотрим бюджет. Узнайте, есть ли у вас фиксированный бюджет, и следите за потреблением соответствующим образом. Вы можете настроить бюджеты, чтобы предотвратить перерасход и выделить квоты на основе приоритета клиента.
Подходы и шаблоны, которые следует учитывать
Azure предоставляет набор служб для включения рабочих нагрузок искусственного интеллекта и машинного обучения. Существует несколько распространенных подходов к архитектуре, используемых в мультитенантных решениях: для использования предварительно созданных решений ИИ/ML, создания пользовательской архитектуры ИИ/ML с помощью Машинное обучение Azure и использования одной из платформ аналитики Azure.
Использование предварительно созданных служб AI/ML
Рекомендуется использовать предварительно созданные службы ИИ/МАШИНного обучения, где можно. Например, ваша организация может начать смотреть на ИИ/ML и быстро интегрироваться с полезной службой. Кроме того, у вас могут быть базовые требования, которые не требуют обучения и разработки пользовательской модели машинного обучения. Предварительно созданные службы машинного обучения позволяют использовать вывод без создания и обучения собственных моделей.
Azure предоставляет несколько служб, которые предоставляют технологии искусственного интеллекта и машинного обучения в различных доменах, включая распознавание речи, распознавание речи, знания, распознавание документов и форм, а также компьютерное зрение. Предварительно созданные службы ИИ и машинного обучения Azure включают Службы ИИ Azure, Службу Azure OpenAI, поиск ИИ Azure и аналитику документов ИИ Azure. Каждая служба предоставляет простой интерфейс для интеграции, а также коллекцию предварительно обученных и проверенных моделей. В качестве управляемых служб они предоставляют соглашения на уровне обслуживания и требуют мало конфигурации или текущего управления. Вам не нужно разрабатывать или тестировать собственные модели для использования этих служб.
Многие управляемые службы машинного обучения не требуют обучения моделей или данных, поэтому обычно нет проблем с изоляцией данных клиента. Однако при работе с поиском ИИ в мультитенантном решении просмотрите шаблоны конструктора для мультитенантных приложений SaaS и поиска ИИ Azure.
Рассмотрите требования к масштабированию для компонентов в решении. Например, многие API в Службах искусственного интеллекта Azure поддерживают максимальное количество запросов в секунду. Если вы развертываете один ресурс служб ИИ для общего доступа между клиентами, то по мере увеличения числа клиентов может потребоваться масштабирование до нескольких ресурсов.
Примечание.
Некоторые управляемые службы позволяют обучать собственные данные, включая службу Пользовательское визуальное распознавание, API распознавания лиц, пользовательские модели аналитики документов и некоторые модели OpenAI, поддерживающие настройку и точное тонирование. При работе с этими службами важно учитывать требования к изоляции данных клиентов.
Настраиваемая архитектура ИИ/ML
Если для решения требуются пользовательские модели или вы работаете в домене, который не охватывается управляемой службой машинного обучения, то рассмотрите возможность создания собственной архитектуры ИИ/МАШИНного обучения. Машинное обучение Azure предоставляет набор возможностей для оркестрации обучения и развертывания моделей машинного обучения. Машинное обучение Azure поддерживает множество библиотек машинного обучения с открытым кодом, включая PyTorch, TensorFlow, Scikitи Keras. Вы можете постоянно отслеживать метрики производительности моделей, обнаруживать смещение данных и запускать переобучение для повышения производительности модели. На протяжении всего жизненного цикла моделей машинного обучения Машинное обучение Azure обеспечивает возможность аудита и управления встроенными средствами отслеживания и происхождения для всех артефактов машинного обучения.
При работе с мультитенантным решением важно учитывать требования к изоляции клиентов как на этапах обучения, так и вывода. Кроме того, необходимо определить процесс обучения модели и развертывания. Машинное обучение Azure предоставляет конвейер для обучения моделей и их развертывания в среде для вывода. В мультитенантном контексте рассмотрите, следует ли развертывать модели в общих вычислительных ресурсах или если у каждого клиента есть выделенные ресурсы. Проектирование конвейеров развертывания модели на основе модели изоляции и процесса развертывания клиента.
При использовании моделей с открытым исходным кодом может потребоваться переобучение этих моделей с помощью передачи обучения или настройки. Рассмотрим, как управлять различными моделями и данными обучения для каждого клиента, а также версиями модели.
На следующей схеме показан пример архитектуры, которая использует Машинное обучение Azure. В этом примере используется подход к изоляции моделей для конкретного клиента.
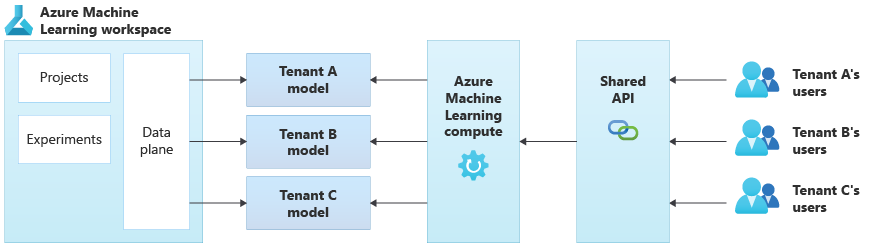
Интегрированные решения искусственного интеллекта и машинного обучения
Azure предоставляет несколько мощных платформ аналитики, которые можно использовать для различных целей. К этим платформам относятся Azure Synapse Analytics, Databricks и Apache Spark.
Вы можете использовать эти платформы для искусственного интеллекта и машинного обучения, если необходимо масштабировать возможности машинного обучения до очень большого количества клиентов, а также при необходимости крупномасштабных вычислений и оркестрации. Вы также можете использовать эти платформы для искусственного интеллекта и машинного обучения, если вам нужна широкая платформа аналитики для других частей решения, например для аналитики данных и интеграции с отчетами через Microsoft Power BI. Вы можете развернуть одну платформу, которая охватывает все потребности аналитики и искусственного интеллекта и машинного обучения. При реализации платформ данных в мультитенантном решении просмотрите архитектурные подходы к хранилищу и данным в мультитенантных решениях.
Операционная модель машинного обучения
При внедрении ИИ и машинного обучения, включая методы создания ИИ, рекомендуется постоянно улучшать и оценивать возможности организации в управлении ими. Введение MLOps и GenAIOps объективно предоставляет платформу для постоянного расширения возможностей методик искусственного интеллекта и машинного обучения в вашей организации. Дополнительные рекомендации см. в документах модели зрелости MLOps и LLMOps Для получения дополнительных рекомендаций.
Неподходящие антишаблоны
- Не рекомендуется учитывать требования к изоляции. Важно тщательно рассмотреть способ изоляции данных и моделей клиентов как для обучения, так и вывода. Не удалось это сделать, может нарушить юридические или договорные требования. Кроме того, это может снизить точность обучения моделей между данными нескольких клиентов, если данные существенно отличаются.
- Шумные соседи. Рассмотрите возможность того, могут ли процессы обучения или вывода быть подвержены проблеме шумного соседа. Например, если у вас есть несколько крупных клиентов и один небольшой клиент, убедитесь, что обучение модели для крупных клиентов не случайно потребляет все вычислительные ресурсы и голодает меньших клиентов. Используйте управление ресурсами и мониторинг, чтобы снизить риск вычислительных рабочих нагрузок клиента, затронутых действиями других клиентов.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Автор субъекта:
- Кевин Эшли | Старший инженер по работе с клиентами, FastTrack для Azure
Другие участники:
- Пол Берпо | Главный инженер клиента, FastTrack для Azure
- Джон Даунс | Главный инженер программного обеспечения
- Даниэль Скотт-Райнсфорд | Стратег технологий партнеров
- Арсен Владимирский | Главный инженер клиента, FastTrack для Azure
- Вик Пердана | Архитектор решений партнеров ISV
Следующие шаги
- Ознакомьтесь с подходами к архитектуре для вычислений в мультитенантных решениях .
- Дополнительные сведения о проектировании конвейеров Машинное обучение Azure для поддержки нескольких клиентов см. в статье "Решение для конвейера машинного обучения" в многотенантном режиме.