Архитектура больших данных предназначена для обработки приема, обработки и анализа данных, слишком больших или сложных для традиционных систем баз данных.

Решения для больших данных обычно включают один или несколько следующих типов рабочей нагрузки:
- Пакетная обработка неактивных источников больших данных.
- Обработка больших данных в режиме реального времени.
- Интерактивное изучение больших данных.
- Прогнозная аналитика и машинное обучение.
Большинство архитектур больших данных включают некоторые или все следующие компоненты:
источники данных: все решения больших данных начинаются с одного или нескольких источников данных. Примеры:
- Хранилища данных приложения, такие как реляционные базы данных.
- Статические файлы, созданные приложениями, такими как файлы журнала веб-сервера.
- Источники данных в режиме реального времени, такие как устройства Интернета вещей.
хранилище данных: данные для операций пакетной обработки обычно хранятся в распределенном хранилище файлов, которое может содержать большие объемы больших файлов в различных форматах. Этот вид хранилища часто называется озера данных. Варианты реализации этого хранилища включают в себя Azure Data Lake Store или контейнеры BLOB-объектов в службе хранилища Azure.
пакетной обработки. Так как наборы данных настолько большие, часто решение больших данных должно обрабатывать файлы данных с помощью длительных пакетных заданий для фильтрации, агрегирования и подготовки данных к анализу. Обычно эти задания включают чтение исходных файлов, их обработку и запись выходных данных в новые файлы. Варианты включают использование потоков данных, конвейеров данных в Microsoft Fabric.
прием сообщений в режиме реального времени. Если решение включает источники в режиме реального времени, архитектура должна включать способ записи и хранения сообщений в режиме реального времени для потоковой обработки. Это может быть простое хранилище данных, в котором входящие сообщения удаляются в папку для обработки. Однако многим решениям требуется хранилище приема сообщений для работы в качестве буфера для сообщений, а также для поддержки горизонтальной обработки, надежной доставки и другой семантики очереди сообщений. К ним относятся Центры событий Azure, Центры Интернета вещей Azure и Kafka.
потоковой обработки: после записи сообщений в режиме реального времени решение должно обрабатывать их путем фильтрации, агрегирования и подготовки данных для анализа. Затем обработанные данные потока записываются в приемник выходных данных. Azure Stream Analytics предоставляет управляемую службу обработки потоков на основе постоянно выполняющихся sql-запросов, работающих на несвязанных потоках. Другим вариантом является использование аналитики в режиме реального времени в Microsoft Fabric, которая позволяет выполнять запросы KQL по мере приема данных.
аналитическое хранилище данных. Многие решения больших данных подготавливают данные для анализа, а затем служат обработанным данным в структурированном формате, который можно запрашивать с помощью аналитических инструментов. Аналитическое хранилище данных, используемое для обслуживания этих запросов, может быть реляционным хранилищем реляционных данных в стиле Кимбола, как показано в большинстве традиционных решений бизнес-аналитики (BI) или озера с архитектурой медальона (Бронза, Silver и Gold). Azure Synapse Analytics предоставляет управляемую службу для крупномасштабных облачных хранилищ данных. Кроме того, Microsoft Fabric предоставляет оба варианта — склад и озеро, которые можно запрашивать с помощью SQL и Spark соответственно.
анализ и отчеты. Цель большинства решений больших данных — предоставить аналитические сведения о данных с помощью анализа и создания отчетов. Чтобы пользователи могли анализировать данные, архитектура может включать уровень моделирования данных, например многомерный куб OLAP или табличную модель данных в Службах Azure Analysis Services. Она также может поддерживать самостоятельную бизнес-аналитику, используя технологии моделирования и визуализации в Microsoft Power BI или Microsoft Excel. Анализ и отчеты также могут принимать форму интерактивного исследования данных специалистами по обработке и анализу данных. В этих сценариях Microsoft Fabric предоставляет такие инструменты, как записные книжки, где пользователь может выбрать SQL или язык программирования.
оркестрации. Большинство решений больших данных состоят из повторяющихся операций обработки данных, инкапсулированных в рабочих процессах, которые преобразуют исходные данные, перемещают данные между несколькими источниками и приемниками, загружают обработанные данные в аналитическое хранилище данных или передают результаты прямо в отчет или панель мониторинга. Для автоматизации этих рабочих процессов можно использовать технологию оркестрации, например конвейеры Фабрики данных Azure или Microsoft Fabric.
Azure включает множество служб, которые можно использовать в архитектуре больших данных. Они делятся примерно на две категории:
- Управляемые службы, включая Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Центры событий Azure, Центр Интернета вещей Azure и фабрику данных Azure.
- Технологии с открытым кодом на основе платформы Apache Hadoop, включая HDFS, HBase, Hive, Spark и Kafka. Эти технологии доступны в Azure в службе Azure HDInsight.
Эти варианты не являются взаимоисключающими, и многие решения объединяют технологии с открытым исходным кодом со службами Azure.
Когда следует использовать эту архитектуру
Рассмотрим этот стиль архитектуры, когда необходимо:
- Хранение и обработка данных в томах слишком большой для традиционной базы данных.
- Преобразование неструктурированных данных для анализа и отчетности.
- Сбор, обработка и анализ несвязанных потоков данных в режиме реального времени или с низкой задержкой.
- Используйте Машинное обучение Azure или Azure Cognitive Services.
Преимущества
- варианты технологий. Вы можете смешивать и сопоставлять управляемые службы Azure и технологии Apache в кластерах HDInsight, чтобы использовать существующие навыки или инвестиции в технологии.
- производительность через параллелизм. Решения с большими данными используют преимущества параллелизма, что позволяет выполнять высокопроизводительные решения, масштабируемые до больших объемов данных.
- эластичного масштабирования. Все компоненты архитектуры больших данных поддерживают горизонтальное масштабирование подготовки, чтобы вы могли настроить решение на небольшие или большие рабочие нагрузки и платить только за используемые ресурсы.
- взаимодействие с существующими решениями. Компоненты архитектуры больших данных также используются для обработки Интернета вещей и корпоративных решений бизнес-аналитики, что позволяет создавать интегрированное решение для рабочих нагрузок данных.
Проблемы
- сложности. Решения больших данных могут быть чрезвычайно сложными, с многочисленными компонентами для обработки приема данных из нескольких источников данных. Это может быть сложно для создания, тестирования и устранения неполадок процессов больших данных. Кроме того, в нескольких системах может быть большое количество параметров конфигурации, которые должны использоваться для оптимизации производительности.
- набор навыков. Многие технологии больших данных являются высоко специализированными и используют платформы и языки, которые не являются типичными для более общей архитектуры приложений. С другой стороны, технологии больших данных развивают новые API, которые создаются на более установленных языках.
- зрелости технологий
. Многие технологии, используемые в больших данных, развиваются. Хотя основные технологии Hadoop, такие как Hive и spark, стабилизировались, новые технологии, такие как delta или айсберг, вносят обширные изменения и улучшения. Управляемые службы, такие как Microsoft Fabric, являются относительно молодыми, по сравнению с другими службами Azure и, скорее всего, будут развиваться с течением времени. - безопасности. Решения больших данных обычно используют хранение всех статических данных в централизованном озере данных. Защита доступа к этим данным может быть сложной задачей, особенно если данные должны быть приняты и использованы несколькими приложениями и платформами.
Рекомендации
использовать параллелизм. Большинство технологий обработки больших данных распределяют рабочую нагрузку между несколькими единицами обработки. Для этого требуется, чтобы статические файлы данных были созданы и хранятся в разделенном формате. Распределенные файловые системы, такие как HDFS, могут оптимизировать производительность чтения и записи, а фактическая обработка выполняется несколькими узлами кластера параллельно, что сокращает общее время задания. Использование разделенного формата данных настоятельно рекомендуется, например Parquet.
данных секционирования. Пакетная обработка обычно выполняется в регулярном расписании, например еженедельно или ежемесячно. Файлы данных секционирования и структуры данных, такие как таблицы, на основе временных периодов, соответствующих расписанию обработки. Это упрощает прием данных и планирование заданий и упрощает устранение сбоев. Кроме того, секционирование таблиц, используемых в hive, spark или SQL-запросах, может значительно повысить производительность запросов.
Применить семантику схемы на чтение. Использование озера данных позволяет объединять хранилище для файлов в нескольких форматах, будь то структурированное, полуструктурированное или неструктурированное. Используйте семантику схемы на чтение, которая проектирует схему на данные при обработке данных, а не при хранении данных. Это создает гибкость в решении и предотвращает узкие места во время приема данных, вызванных проверкой данных и проверкой типов.
обработка данных на месте. Традиционные решения бизнес-аналитики часто используют процесс извлечения, преобразования и загрузки (ETL) для перемещения данных в хранилище данных. С большими объемами данных и большим количеством форматов решения больших данных обычно используют варианты ETL, такие как преобразование, извлечение и загрузка (TEL). При таком подходе данные обрабатываются в распределенном хранилище данных, преобразуя его в необходимую структуру, прежде чем перемещать преобразованные данные в аналитическое хранилище данных.
Баланс использования и затрат на время. Для заданий пакетной обработки важно учитывать два фактора: затраты на единицу вычислительных узлов и затраты на каждую минуту использования этих узлов для выполнения задания. Например, пакетное задание может занять восемь часов с четырьмя узлами кластера. Однако может оказаться, что задание использует все четыре узла только в течение первых двух часов, и после этого требуются только два узла. В этом случае выполнение всего задания на двух узлах увеличит общее время задания, но не удвоит его, поэтому общая стоимость будет меньше. В некоторых бизнес-сценариях более длительное время обработки может быть предпочтительнее для использования неиспользуемых ресурсов кластера.
Отдельные ресурсы. По возможности следует разделить ресурсы на основе рабочих нагрузок, чтобы избежать таких сценариев, как одна рабочая нагрузка, используя все ресурсы во время ожидания других.
оркестрации данных. В некоторых случаях существующие бизнес-приложения могут записывать файлы данных для пакетной обработки непосредственно в контейнеры BLOB-объектов хранилища Azure, где их можно использовать нижестоящими службами, такими как Microsoft Fabric. Однако часто необходимо оркестрировать прием данных из локальных или внешних источников данных в озеро данных. Используйте рабочий процесс оркестрации или конвейер, например поддерживаемые Фабрикой данных Azure или Microsoft Fabric, для достижения этого в предсказуемой и централизованно управляемой форме.
конфиденциальные данные scrub в начале. Рабочий процесс приема данных должен крабовать конфиденциальные данные в начале процесса, чтобы избежать его хранения в озере данных.
Архитектура Интернета вещей
Интернет вещей (IoT) — это специализированное подмножество решений больших данных. На следующей схеме показана возможная логическая архитектура для Интернета вещей. Схема подчеркивает компоненты потоковой передачи событий архитектуры.
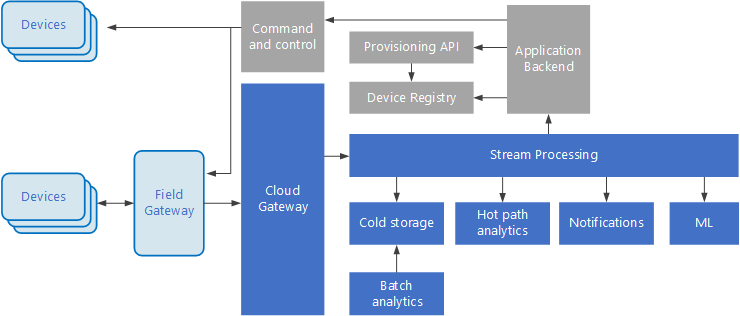
облачный шлюз прием событий устройства на границе облака с помощью надежной системы обмена сообщениями с низкой задержкой.
Устройства могут отправлять события непосредственно в облачный шлюз или через шлюз полей . Шлюз полей — это специализированное устройство или программное обеспечение, обычно размещенное с устройствами, которое получает события и пересылает их в облачный шлюз. Шлюз полей также может предварительно обработать необработанные события устройства, выполняя такие функции, как фильтрация, агрегирование или преобразование протокола.
После приема события проходят через один или несколько потоковых процессоров, которые могут направлять данные (например, в хранилище) или выполнять аналитику и другую обработку.
Ниже приведены некоторые распространенные типы обработки. (Этот список, безусловно, не является исчерпывающим.)
Запись данных событий в холодное хранилище для архивации или пакетной аналитики.
Аналитика горячих путей, анализ потока событий в режиме реального времени для обнаружения аномалий, распознавания шаблонов с течением скользящего времени или активации оповещений при возникновении конкретного условия в потоке.
Обработка специальных типов сообщений без телеметрии с устройств, таких как уведомления и оповещения.
Обучение машины.
В полях, которые затеняются серым цветом, отображаются компоненты системы Интернета вещей, которые не связаны напрямую с потоковой передачей событий, но включены здесь для полноты.
реестр устройств — это база данных подготовленных устройств, включая идентификаторы устройств и обычно метаданные устройства, например расположение.
API подготовки — это общий внешний интерфейс для подготовки и регистрации новых устройств.
Некоторые решения Интернета вещей позволяют отправлять сообщения команд и управления на устройства.
В этом разделе представлено очень высокоуровневое представление Интернета вещей, и есть много тонкостей и проблем, которые следует рассмотреть. Дополнительные сведения см. в разделе архитектуры Интернета вещей.
Дальнейшие действия
- Дополнительные сведения об архитектуре больших данных .
- Дополнительные сведения об архитектурах Интернета вещей.