Обработка естественного языка (NLP) имеет множество приложений, таких как анализ тональности, обнаружение тем, обнаружение языка, извлечение ключевых фраз и классификация документов.
В частности, можно использовать NLP для:
- Классифицируйте документы, например метки как конфиденциальные или нежелательные.
- Выполнение последующей обработки или поиска с помощью выходных данных NLP.
- Суммируйте текст, определяя сущности в документе.
- Пометьте документы с ключевыми словами, используя идентифицированные сущности.
- Проводите поиск на основе контента и извлечение с помощью тегов.
- Сводка ключевых разделов документа с использованием определенных сущностей.
- Классификация документов для навигации с использованием обнаруженных разделов.
- Перечисление связанных документов на основе выбранного раздела.
- Оцените тон текста, чтобы понять его положительный или отрицательный тон.
Благодаря усовершенствованиям технологий NLP можно использовать не только для классификации и анализа текстовых данных, но и для улучшения интерпретируемых функций ИИ в различных доменах. Интеграция крупных языковых моделей (LLM) значительно повышает возможности NLP. МОДУЛИ LLMS, такие как GPT и BERT, могут генерировать человеческий, контекстно осведомленный текст, что делает их высокоэффективными для сложных задач обработки языка. Они дополняют существующие методы NLP, обрабатывая более широкие когнитивные задачи, которые улучшают системы общения и взаимодействие с клиентами, особенно с моделями, такими как Databricks'Dolly 2.0.
Связь и различия между языковыми моделями и NLP
NLP — это комплексное поле, охватывающее различные методы обработки человеческого языка. В отличие от этого, языковые модели — это определенное подмножество в NLP, ориентированное на глубокое обучение для выполнения высокоуровневых языковых задач. Хотя языковые модели улучшают NLP, предоставляя расширенные возможности создания текста и понимания, они не являются синонимами NLP. Вместо этого они служат мощными инструментами в более широком домене NLP, что обеспечивает более сложную обработку языка.
Заметка
Эта статья посвящена NLP. Связь между NLP и языковыми моделями демонстрирует, что языковые модели улучшают процессы NLP с помощью улучшенных возможностей распознавания речи и создания.
Apache, Apache® Spark и логотип пламени являются зарегистрированными товарными знаками или товарными знаками Apache Software Foundation в США и/или других странах. Использование этих меток не подразумевает подтверждения от Apache Software Foundation.
Потенциальные варианты использования
Бизнес-сценарии, которые могут воспользоваться пользовательскими NLP, включают:
- Аналитика документов для рукописных или машинных документов в финансах, здравоохранении, розничной торговле, правительстве и других секторах.
- Задачи NLP, не зависящие от отрасли, для обработки текста, такие как распознавание сущностей имен (NER), классификация, суммирование и извлечение связей. Эти задачи автоматизируют процесс извлечения, идентификации и анализа сведений о документе, таких как текст и неструктурированные данные. Примерами этих задач являются модели стратификации рисков, классификация онтологии и сводные данные розничной торговли.
- Получение информации и создание графа знаний для семантического поиска. Эта функция позволяет создавать медицинские графы знаний, поддерживающие обнаружение наркотиков и клинические испытания.
- Перевод текста для систем ИИ для общения в клиентских приложениях в розничной торговле, финансах, путешествиях и других отраслях.
- Тональность и улучшенная эмоциональная аналитика в аналитике, особенно для мониторинга восприятия бренда и аналитики отзывов клиентов.
- Автоматическое создание отчетов. Синтезируйте и создавайте комплексные текстовые отчеты из структурированных входных данных, помогая таким секторам, как финансы и соответствие, где требуется тщательная документация.
- Интерфейсы с активацией голоса для улучшения взаимодействия пользователей в приложениях Интернета вещей и смарт-устройств путем интеграции NLP для распознавания голоса и естественных возможностей беседы.
- Адаптивные языковые модели для динамической настройки выходных данных языка в соответствии с различными уровнями понимания аудитории, что имеет решающее значение для улучшения образовательного содержимого и специальных возможностей.
- Анализ текста кибербезопасности для анализа шаблонов связи и использования языка в режиме реального времени для выявления потенциальных угроз безопасности в цифровой связи, улучшения обнаружения фишинговых попыток или ложной информации.
Apache Spark в качестве настраиваемой платформы NLP
Apache Spark — это мощная платформа параллельной обработки, которая повышает производительность приложений аналитики больших данных с помощью обработки в памяти. Azure Synapse Analytics, Azure HDInsightи Azure Databricks по-прежнему обеспечивают надежный доступ к возможностям обработки Spark, обеспечивая простое выполнение крупномасштабных операций с данными.
Для настраиваемых рабочих нагрузок NLP Spark остается эффективной платформой, способной обрабатывать огромные объемы текста. Эта библиотека с открытым исходным кодом предоставляет широкие функциональные возможности с помощью библиотек Python, Java и Scala, которые обеспечивают сложности, найденные в известных библиотеках NLP, таких как spacy и NLTK. Spark NLP включает в себя расширенные функции, такие как проверка орфографии, анализ тональности и классификация документов, последовательно обеспечивая точность и масштабируемость.
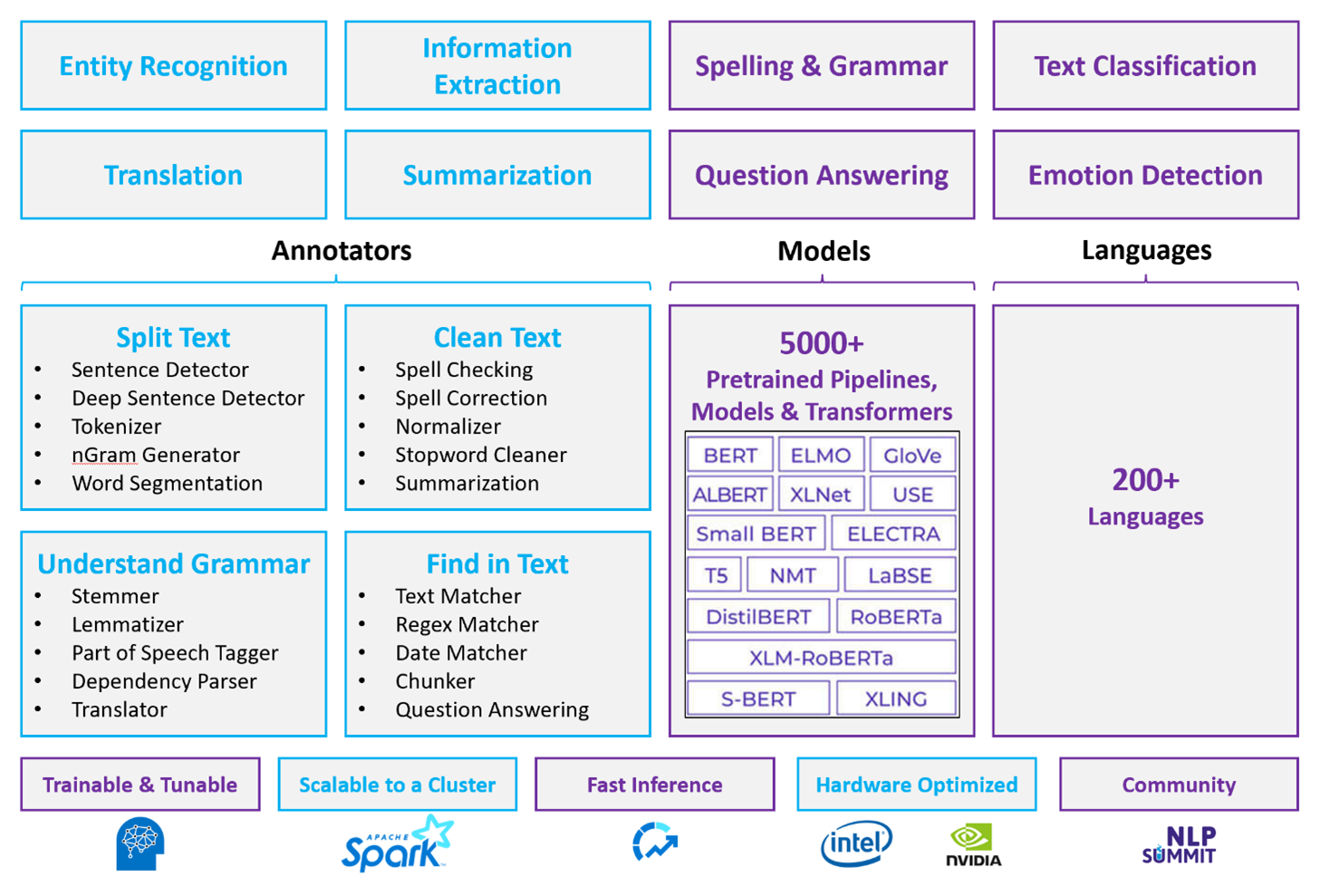
Последние общедоступные тесты показывают производительность Spark NLP, демонстрируя значительные улучшения скорости по сравнению с другими библиотеками при сохранении сравнимой точности для обучения пользовательских моделей. В частности, интеграция моделей Llama-2 и OpenAI Whisper улучшает диалоговые интерфейсы и многоязычное распознавание речи, отмечая значительные успехи в оптимизированных возможностях обработки.
Уникально, spark NLP эффективно использует распределенный кластер Spark, работающий в качестве собственного расширения машинного обучения Spark, который работает непосредственно на кадрах данных. Эта интеграция поддерживает повышение производительности кластеров, упрощая создание унифицированных конвейеров NLP и машинного обучения для таких задач, как классификация документов и прогнозирование рисков. Введение внедрения MPNet и расширенная поддержка ONNX расширяют эти возможности, позволяя точной и контекстной обработке.
Помимо преимуществ производительности, Платформа NLP Spark обеспечивает точность по всему масштабу задач NLP. Библиотека поставляется с предварительно созданными моделями глубокого обучения для распознавания именованных сущностей, классификации документов, обнаружения тональности и многого другого. Его многофункциональный дизайн включает предварительно обученные языковые модели, поддерживающие слова, блоки, предложения и внедрения документов.
Благодаря оптимизированным сборкам для ЦП, GPU и новейших микросхем Intel Xeon инфраструктура Spark NLP предназначена для масштабируемости, что позволяет процессам обучения и вывода полностью использовать кластеры Spark. Это обеспечивает эффективную обработку задач NLP в различных средах и приложениях, сохраняя свою позицию на переднем крае инноваций NLP.
Сложности
обработка ресурсов: Обработка коллекции текстовых документов свободной формы требует значительного объема вычислительных ресурсов, а обработка также является трудоемкой. Такая обработка часто включает развертывание вычислений GPU. Недавние улучшения, такие как оптимизация в архитектурах NLP Spark, таких как Llama-2, которые поддерживают квантизацию, помогают упростить эти интенсивные задачи, что делает выделение ресурсов более эффективным.
проблемы стандартизации: без стандартного формата документа, при использовании обработки текста свободной формы для извлечения конкретных фактов из документа может быть сложно. Например, извлечение номера счета и даты из различных счетов вызывает проблемы. Интеграция адаптируемых моделей NLP, таких как M2M100, улучшена точность обработки на нескольких языках и форматах, что повышает согласованность результатов.
разнообразие и сложность данных: решение различных структур документов и лингвистических нюансов остается сложным. Инновации, такие как внедрение MPNet, обеспечивают расширенное контекстное понимание, предлагая более интуитивно понятное управление различными текстовыми форматами и повышая общую надежность обработки данных.
Основные критерии выбора
В Azure службы Spark, такие как Azure Databricks, Microsoft Fabric и Azure HDInsight, предоставляют функции NLP при использовании с Spark NLP. Службы ИИ Azure — это еще один вариант для функций NLP. Чтобы решить, какую службу следует использовать, рассмотрите следующие вопросы:
Вы хотите использовать предварительно созданные или предварительно обученные модели? Если да, рассмотрите возможность использования API, предлагаемых службами ИИ Azure, или скачайте модель с помощью NLP Spark, которая теперь включает в себя расширенные модели, такие как Llama-2 и MPNet для расширенных возможностей.
Нужно ли обучать пользовательские модели на основе большой совокупности текстовых данных? Если да, рассмотрите возможность использования Azure Databricks, Microsoft Fabric или Azure HDInsight с NLP Spark. Эти платформы обеспечивают вычислительную мощность и гибкость, необходимую для обширного обучения модели.
Требуются ли низкоуровневые возможности NLP, например разметка, выделение корней слов, лемматизация и частота условия или инверсная частота в документе? Если да, рассмотрите возможность использования Azure Databricks, Microsoft Fabric или Azure HDInsight с NLP Spark. Кроме того, используйте библиотеку программного обеспечения с открытым исходным кодом в выбранном средстве обработки.
Требуются ли простые, высокоуровневые возможности NLP, например распознавание сущностей и намерений, распознавание темы, проверка орфографии и анализ тональности. Если да, рассмотрите возможность использования API, предоставляемых службами ИИ Azure. Или скачайте модель с помощью NLP Spark, чтобы использовать предварительно созданные функции для этих задач.
Матрица возможностей
В следующих таблицах приведены основные различия в возможностях служб NLP.
Общие возможности
| Возможность | Служба Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Предоставление предварительно обученных моделей как услуги | Да | Да |
| REST API | Да | Да |
| Программируемость | Python, Scala | Сведения о поддерживаемых языках см. в разделе "Дополнительные ресурсы" |
| Поддерживает обработку наборов больших данных и больших документов | Да | Нет |
Низкоуровневые возможности NLP
Возможности аннотаторов
| Возможность | Служба Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Детектор предложений | Да | Нет |
| Детектор глубоких предложений | Да | Да |
| Tokenizer | Да | Да |
| Генератор N-грамм | Да | Нет |
| Сегментация Word | Да | Да |
| Парадигматический модуль | Да | Нет |
| Лемматический модуль | Да | Нет |
| Лексико-грамматический анализ | Да | Нет |
| Средство синтаксического анализа зависимостей | Да | Нет |
| Перевод текста | Да | Нет |
| Стоп-слово более чистое | Да | Нет |
| Исправление орфографии | Да | Нет |
| Нормализатор | Да | Да |
| Сопоставление текста | Да | Нет |
| TF/IDF | Да | Нет |
| Сопоставление регулярных выражений | Да | Внедрено в распознавание речи общения (CLU) |
| Сопоставление дат | Да | Возможно, в CLU через распознаватели DateTime |
| Блокировщик | Да | Нет |
Заметка
Microsoft Language Understanding (LUIS) будет прекращен 1 октября 2025 г. Существующие приложения LUIS рекомендуется перенести в CLU, возможности Служб искусственного интеллекта Azure для языка, что улучшает возможности распознавания речи и предлагает новые функции.
Высокоуровневые возможности NLP
| Возможность | Служба Spark (Azure Databricks, Microsoft Fabric, Azure HDInsight) с помощью Spark NLP | Службы ИИ Azure |
|---|---|---|
| Проверка орфографии | Да | Нет |
| Сводка | Да | Да |
| Ответы на вопросы | Да | Да |
| Определение тональности | Да | Да |
| Определение эмоций | Да | Поддержка интеллектуального анализа мнений |
| Классификация токенов | Да | Да, с помощью пользовательских моделей |
| Классификация текстов | Да | Да, с помощью пользовательских моделей |
| Текстовое представление | Да | Нет |
| Распознавание именованных сущностей | Да | Да— анализ текста предоставляет набор NER, а пользовательские модели находятся в распознавании сущностей. |
| Распознавание сущностей | Да | Да, с помощью пользовательских моделей |
| Распознавание языка | Да | Да |
| Поддерживает языки, кроме английского языка | Да, поддерживает более 200 языков | Да, поддерживает более 97 языков |
Настройка NLP Spark в Azure
Чтобы установить NLP Spark, используйте следующий код, но замените <version> последним номером версии. Дополнительные сведения см. в документации по NLP Spark.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Разработка конвейеров NLP
Для порядка выполнения конвейера NLP Spark NLP следует той же концепции разработки, что и традиционные модели машинного обучения Spark ML, применяя специализированные методы NLP.
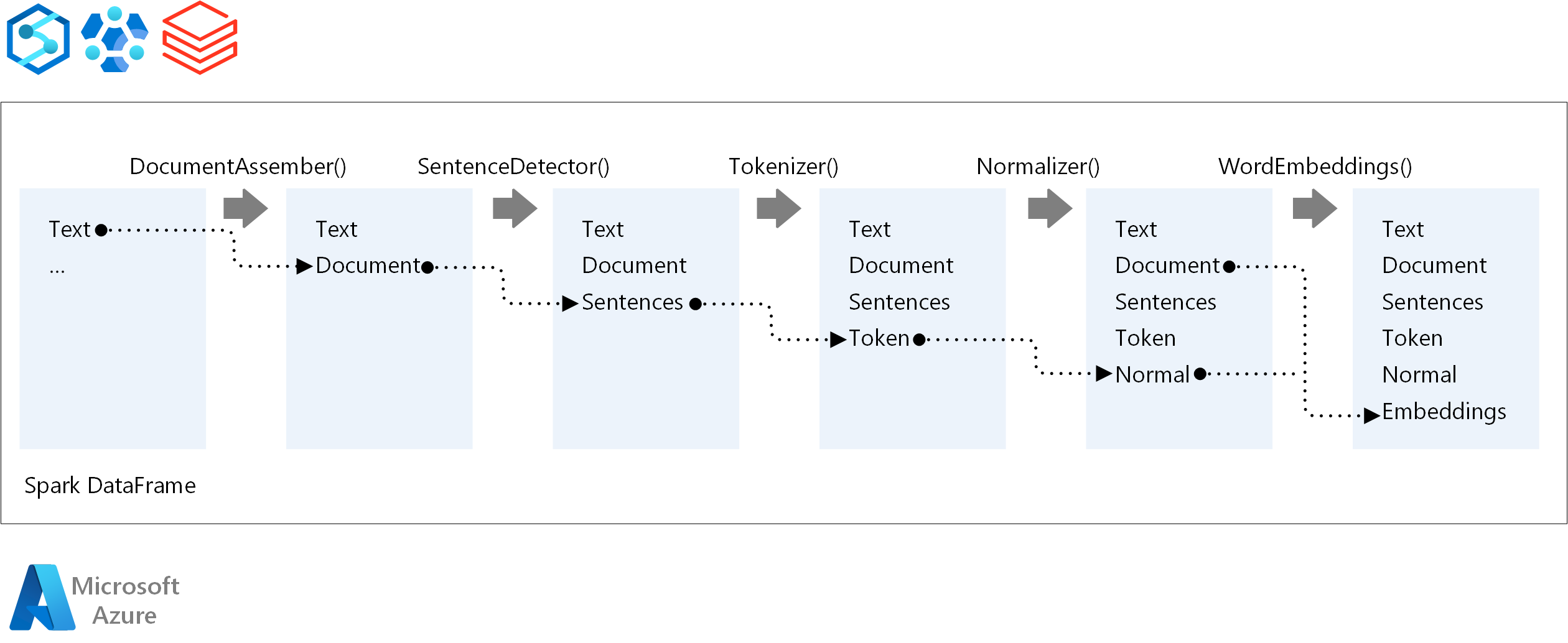
Основные компоненты конвейера NLP Spark:
DocumentAssembler: преобразователь, который подготавливает данные, преобразовав его в формат, который может обрабатывать NLP Spark. Этот этап является точкой входа для каждого конвейера NLP Spark. DocumentAssembler считывает столбец
StringилиArray[String]с параметрами предварительной обработки текста с помощьюsetCleanupMode, которая по умолчанию отключена.SentenceDetector: аннатор, определяющий границы предложений с помощью предопределенных подходов. Он может возвращать каждое обнаруженное предложение в
Arrayили в отдельных строках, еслиexplodeSentencesзадано значение true.токенизатор: аннотатор, разделяющий необработанный текст на дискретные маркеры — слова, цифры и символы— вывод этих символов в виде
TokenizedSentence. Токенизатор не настроен и использует входную конфигурацию вRuleFactoryдля создания правил маркеризации. Пользовательские правила можно добавлять, если по умолчанию недостаточно.нормализатор: annotator, на который выполняется уточнение маркеров. Нормализатор применяет регулярные выражения и преобразования словаря для очистки текста и удаления лишних символов.
WordEmbeddings: аноматоры поиска, которые сопоставляют маркеры с векторами, упрощая семантику обработки. Можно указать пользовательский словарь внедрения с помощью
setStoragePath, где каждая строка содержит маркер и вектор, разделенные пробелами. Неразрешенные маркеры по умолчанию равны нулю векторам.
Spark NLP использует конвейеры Spark MLlib с собственной поддержкой MLflow, платформы с открытым исходным кодом, которая управляет жизненным циклом машинного обучения. Ключевые компоненты MLflow включают:
отслеживание MLflow: записывает экспериментальные запуски и предоставляет надежные возможности запросов для анализа результатов.
MLflow Projects: позволяет выполнять код обработки и анализа данных на различных платформах, повышая переносимость и воспроизводимость.
модели MLflow: поддерживает универсальное развертывание моделей в разных средах с помощью согласованной платформы.
реестр моделей: обеспечивает комплексное управление моделями, централизованное хранение версий для упрощенного доступа и развертывания, упрощающее готовность к работе.
MLflow интегрирован с такими платформами, как Azure Databricks, но также можно установить в других средах Spark для управления и отслеживания экспериментов. Эта интеграция позволяет использовать реестр моделей MLflow для обеспечения доступности моделей для рабочих целей, что упрощает процесс развертывания и поддерживает управление моделями.
Используя MLflow вместе с Spark NLP, вы можете обеспечить эффективное управление и развертывание конвейеров NLP, устраняя современные требования к масштабируемости и интеграции, поддерживая расширенные методы, такие как внедрение слов и адаптация больших языковых моделей.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Основные авторы:
- Фредди Айала | Архитектор облачных решений
- Мориц Стеллер | Старший архитектор облачных решений
Следующие шаги
Документация по Spark NLP:
Компоненты Azure:
Сведения о ресурсах: