Этап генерации эмбеддингов RAG
На предыдущих шагах вашего решения для генерации Retrieval-Augmented (RAG) вы разделили документы на части и обогатили их. На этом шаге вы создаете внедрения для этих блоков и всех полей метаданных, в которых планируется выполнять поиск векторов.
Эта статья является частью серии. Ознакомьтесь с введением .
Внедрение — это математическое представление объекта, например текста. При обучении нейронной сети создается множество представлений объекта. Каждое представление имеет подключения к другим объектам в сети. Внедрение важно, так как оно фиксирует семантический смысл объекта.
Представление одного объекта имеет связи с представлениями других объектов, чтобы можно было математически сравнивать объекты. В следующем примере показано, как эмбеддинги фиксируют семантические значения и связи друг с другом.
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
Встраивания сравниваются друг с другом с помощью понятий сходства и расстояния. В следующей сетке показано сравнение внедрения.

В решении RAG часто внедряете запрос пользователя с помощью той же модели внедрения, что и блоки. Затем вы ищете базу данных для получения соответствующих векторов, чтобы вернуть наиболее семантические блоки. Исходный текст соответствующих фрагментов передается в языковую модель в качестве основных данных.
Заметка
Векторы представляют семантический смысл текста таким образом, что позволяет выполнять математическое сравнение. Необходимо очистить блоки, чтобы математическая близость между векторами точно отражала их семантическую релевантность.
Важность модели внедрения
Выбранная модель внедрения может существенно повлиять на релевантность результатов векторного поиска. Необходимо учитывать словарь модели встраивания. Каждая модель внедрения обучена определенным словарем. Например, размер словаря модели BERT составляет около 30 000 слов.
Словарь эмбеддинговой модели важен, так как он уникальным образом обрабатывает слова, которые не входят в его словарь. Если слово не в словаре модели, оно по-прежнему вычисляет вектор для него. Для этого многие модели разбивают слова на вложенные слова. Они обрабатывают подслова как отдельные токены или объединяют векторы подслов для создания единого векторного представления.
Например, слово гистамин может не находиться в словаре модели встраивания. Слово гистамин понимается как химическое вещество, которое ваше тело выделяет и которое вызывает симптомы аллергии. Модель внедрения не содержит гистомин. Таким образом, он может разделить слово на подслова, которые находятся в его словаре, таких как его, таи мой.

Семантические значения этих субслов далеки от смысла гистамина. Отдельные или комбинированные векторные значения вложенных слов приводят к менее точным векторным совпадениям по сравнению с тем, если гистамин был в словаре модели.
Выбор модели внедрения
Определите правильную модель внедрения для вашего варианта использования. Учитывайте перекрытие между словарным запасом модели встраивания и словами ваших данных при выборе модели встраивания.

Сначала определите, есть ли у вас содержимое для конкретного домена. Например, документы относятся к конкретному случаю использования, вашей организации или сфере? Хороший способ определить специфику домена — проверить, можно ли найти сущности и ключевые слова в содержимом в Интернете. Если это можете сделать вы, то, вероятно, сможет и общая модель встраивания.
Общее содержимое или недоменное содержимое
При выборе общей модели встраивания начните с таблицы лидеров Hugging Face . Получите рейтинг модели встраивания данных up-to. Оцените работу моделей с данными и начните с моделей верхнего ранжирования.
Содержимое для конкретного домена
Для содержимого для конкретного домена определите, можно ли использовать модель для конкретного домена. Например, данные могут находиться в биомедиатической области, поэтому вы можете использовать модель BioGPT. Эта языковая модель предварительно обучена на большой коллекции биомедической литературы. Его можно использовать для биомедической добычи текста и создания. Если доступны модели, относящиеся к домену, оцените, как эти модели работают с данными.
Если у вас нет модели для конкретного домена или модель для конкретного домена не работает хорошо, вы можете настроить общую модель эмбеддингов с помощью словаря вашего домена.
Важный
Для любой выбранной модели необходимо убедиться, что лицензия соответствует вашим потребностям и модель обеспечивает необходимую языковую поддержку.
Оценка моделей внедрения
Чтобы оценить модель внедрения, визуализировать внедрения и оценить расстояние между вопросом и векторами фрагментов.
Визуализировать векторные представления
Вы можете использовать библиотеки, такие как t-SNE, для построения векторов для блоков и вашего вопроса на графе X-Y. Затем можно определить, насколько далеко куски находятся друг от друга и от вопроса. На следующем графике показаны векторы фрагментов. Две стрелки рядом друг с другом представляют два вектора сегментов. Другая стрелка представляет вектор вопроса. Эту визуализацию можно использовать для того, чтобы понять, насколько далеко вопрос находится от фрагментов.
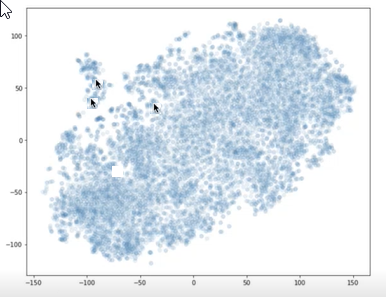
Две стрелки указывают на точки на графике, расположенные вблизи друг от друга, а другая стрелка показывает точку на графике, находящуюся далеко от этих двух.
Вычисление расстояний внедрения
Вы можете использовать программный метод для оценки того, насколько хорошо работает модель внедрения с вашими вопросами и блоками. Вычислите расстояние между векторами вопросов и векторами блоков. Вы можете использовать расстояние Евклидеана или манхэттенское расстояние.
Внедрение экономики
При выборе модели внедрения необходимо перейти к компромиссу между производительностью и затратами. Большие модели внедрения обычно имеют более высокую производительность при тестировании наборов данных. Но, увеличение производительности добавляет затраты. Для больших векторов требуется больше места в базе данных векторов. Кроме того, им требуется больше вычислительных ресурсов и времени для сравнения внедрения. Небольшие модели внедрения обычно имеют более низкую производительность в одних и том же тестах. Они требуют меньше места в векторной базе данных и меньше вычислительных ресурсов и времени для сравнения внедрения.
При разработке системы следует учитывать затраты на внедрение с точки зрения хранения, вычислений и производительности. Необходимо проверить производительность моделей с помощью экспериментирования. Общедоступные тесты являются главным образом академическими наборами данных и могут не применяться непосредственно к бизнес-данным и вариантам использования. В зависимости от требований вы можете использовать производительность по сравнению с затратами или принять компромисс с достаточной производительностью за более низкую стоимость.