В этой статье представлено решение и руководство по разработке автономных операций с данными и управления данными (DataOps) для автоматизированной системы вождения. Решение DataOps основано на платформе, описанной в руководстве по проектированию автономных транспортных средств (AVOps). DataOps является одним из стандартных блоков AVOps. Другие стандартные блоки включают операции машинного обучения (MLOps), операции проверки (ValOps), DevOps и централизованные функции AVOps.
Apache®, Apache Sparkи Apache Parquet являются зарегистрированными товарными знаками или товарными знаками Apache Software Foundation в США и/или других странах. Никакое одобрение Apache Software Foundation не подразумевается с помощью этих меток.
Архитектура

Скачайте файл Visio, содержащий схемы архитектуры в этой статье.
Поток данных
Данные измерения возникают в потоках данных транспортного средства. Источники включают камеры, телеметрию транспортных средств, а также радиолокационные, звуковые и лидарные датчики. Средства ведения журнала данных в транспортном средстве хранят данные измерения на устройствах хранения средства ведения журнала. Данные хранилища средства ведения журнала передаются в целевое озеро данных. Служба, например Azure Data Box или Azure Stack Edge, или выделенное подключение, например Azure ExpressRoute, отправляет данные в Azure. Данные измерений в следующих форматах хранятся в Azure Data Lake Storage: формат данных измерений версии 4 (MDF4), технические системы управления данными (TDMS) и rosbag. Отправленные данные входят в выделенную учетную запись хранения с именем Целевой, которая предназначена для получения и проверки данных.
Конвейер Фабрики данных Azure активируется с запланированным интервалом для обработки данных в целевой учетной записи хранения. Конвейер обрабатывает следующие действия:
- Выполняет проверку качества данных, например контрольную сумму. Этот шаг удаляет данные низкого качества, чтобы до следующего этапа проходили только высококачественные данные. Служба приложений Azure используется для запуска кода проверки качества. Данные, которые считаются неполными, архивируются для дальнейшей обработки.
- Для отслеживания происхождения вызывает API метаданных с помощью службы приложений. На этом шаге обновляются метаданные, хранящиеся в Azure Cosmos DB, чтобы создать новый поток данных. Для каждого измерения существует необработанный поток данных.
- Копирует данные в учетную запись хранения с именем Необработанные в Data Lake Storage.
- Вызывает API метаданных, чтобы пометить поток данных как полный, чтобы другие компоненты и службы могли использовать поток данных.
- Архивирует измерения и удаляет их из целевой учетной записи хранения.
Фабрика данных и пакетная служба Azure обрабатывают данные в необработанной зоне для извлечения сведений, которые могут использовать нижестоящий системе:
- Пакет считывает данные из разделов в необработанном файле и выводит данные в выбранные разделы в соответствующих папках.
- Так как файлы в необработанной зоне могут иметь размер более 2 ГБ, функции извлечения параллельной обработки выполняются в каждом файле. Эти функции извлекают данные об обработке изображений, лидаре, радаре и GPS. Они также выполняют обработку метаданных. Фабрика данных и пакетная служба позволяют выполнять параллелизм масштабируемым способом.
- Данные сокращаются, чтобы уменьшить объем данных, которые необходимо пометить и заметить.
Если данные из средства ведения журнала транспортных средств не синхронизируются между различными датчиками, конвейер фабрики данных активируется, который синхронизирует данные для создания допустимого набора данных. Алгоритм синхронизации выполняется в пакетной службе.
Конвейер фабрики данных запускается для обогащения данных. Примеры улучшений включают данные телеметрии, данные средства ведения журнала транспортных средств и другие данные, такие как погода, карта или данные объекта. Обогащенные данные помогают специалистам по обработке и анализу данных предоставлять аналитические сведения, которые они могут использовать в разработке алгоритмов, например. Созданные данные хранятся в файлах Apache Parquet, совместимых с синхронизированными данными. Метаданные о обогащенных данных хранятся в хранилище метаданных в Azure Cosmos DB.
Сторонние партнеры выполняют ручную или автоматическую маркировку. Данные передаются сторонним партнерам через Azure Data Share и интегрируются в Microsoft Purview. Data Share использует выделенную учетную запись хранения с именем Помеченные в Data Lake Storage для возврата помеченных данных в организацию.
Конвейер фабрики данных выполняет обнаружение сцены. Метаданные сцены хранятся в хранилище метаданных. Данные сцены хранятся в виде объектов в файлах Parquet или Delta.
Помимо метаданных для данных обогащения и обнаруженных сцен, хранилище метаданных в Azure Cosmos DB хранит метаданные для измерений, таких как данные диска. Это хранилище также содержит метаданные для происхождения данных, так как он проходит через процессы извлечения, уменьшения, синхронизации, обогащения и обнаружения сцены. API метаданных используется для доступа к измерениям, происхождению и данным сцены и поиску места хранения данных. В результате API метаданных служит диспетчером уровней хранилища. Он распределяет данные между учетными записями хранения. Он также предоставляет разработчикам способ использовать поиск на основе метаданных для получения расположений данных. По этой причине хранилище метаданных является централизованным компонентом, который обеспечивает трассировку и происхождение в потоке данных решения.
Azure Databricks и Azure Synapse Analytics используются для подключения к API метаданных и доступа к Data Lake Storage и проведения исследований по данным.
Компоненты
- Data Box предоставляет способ отправки терабайтов данных в Azure и из него в быстрый, недорогой и надежный способ. В этом решении Data Box используется для передачи собранных данных транспортных средств в Azure через региональный перевозчик.
- устройства Azure Stack Edge предоставляют функциональные возможности Azure в пограничных расположениях. Примерами возможностей Azure являются вычислительные ресурсы, хранилище, сеть и аппаратное ускорение машинного обучения.
- ExpressRoute расширяет локальную сеть в Microsoft Cloud через частное подключение.
- Data Lake Storage содержит большой объем данных в собственном, необработанном формате. В этом случае Data Lake Storage сохраняет данные на основе этапов, например необработанных или извлеченных.
- фабрика данных — это полностью управляемое бессерверное решение для создания и планирования извлечения, преобразования, загрузки (ETL) и извлечения, загрузки, преобразования (ELT). Здесь фабрика данных выполняет ETL с помощью пакетной вычислительной и создает рабочие процессы на основе данных для оркестрации перемещения данных и преобразования данных.
- пакетной эффективно выполняет крупномасштабные параллельные и высокопроизводительные вычислительные задания (HPC) в Azure. Это решение использует пакетную службу для выполнения крупномасштабных приложений для таких задач, как обработка данных, фильтрация и подготовка данных, а также извлечение метаданных.
- Azure Cosmos DB — это глобально распределенная база данных с несколькими моделями. Здесь хранятся результаты метаданных, такие как сохраненные измерения.
- общий ресурс данных совместно использовать данные с партнерскими организациями с повышенной безопасностью. Используя общий доступ на месте, поставщики данных могут совместно использовать данные, в которых он находится, не копируя данные или выполняя моментальные снимки. В этом решении Data Share делится данными с компаниями по маркировке.
- Azure Databricks предоставляет набор средств для обслуживания решений данных корпоративного уровня в масштабе. Это необходимо для длительных операций с большими объемами данных транспортного средства. Инженеры данных используют Azure Databricks в качестве аналитики workbench.
- Azure Synapse Analytics сокращает время для анализа между хранилищами данных и системами больших данных.
- службы поиска ИИ Azure предоставляют службы поиска по каталогу данных.
- служба приложений предоставляет бессерверную службу веб-приложений. В этом случае служба приложений размещает API метаданных.
- Microsoft Purview обеспечивает управление данными в организациях.
- реестр контейнеров Azure — это служба, которая создает управляемый реестр образов контейнеров. Это решение использует реестр контейнеров для хранения контейнеров для обработки тем.
- Application Insights — это расширение Azure Monitor, которое обеспечивает управление производительностью приложений. В этом сценарии Application Insights помогает создавать наблюдаемость при извлечении измерений: с помощью Application Insights можно регистрировать пользовательские события, пользовательские метрики и другие сведения, а решение обрабатывает каждое измерение для извлечения. Вы также можете создавать запросы в Log Analytics, чтобы получить подробные сведения о каждом измерении.
Сведения о сценарии
Проектирование надежной платформы DataOps для автономных транспортных средств имеет решающее значение для использования данных, трассировки его происхождения и обеспечения его доступности во всей организации. Без хорошо разработанного процесса DataOps большое количество данных, создаваемых автономными автомобилями, может быстро стать подавляющим и трудным для управления.
При реализации эффективной стратегии DataOps вы помогаете убедиться, что данные правильно хранятся, легко доступны и имеют четкие происхождения. Вы также упрощаете управление и анализ данных, что приводит к более информированным принятию решений и повышению производительности транспортных средств.
Эффективный процесс DataOps позволяет легко распределять данные по всей организации. Затем различные команды могут получить доступ к информации, необходимой для оптимизации своих операций. DataOps упрощает совместную работу и совместное использование аналитических сведений, что помогает повысить общую эффективность вашей организации.
Типичные проблемы для операций с данными в контексте автономных транспортных средств:
- Управление ежедневным объемом терабайтов или петабайтового масштаба данных измерения от исследовательских и разработки транспортных средств.
- Совместное использование данных и совместная работа между несколькими командами и партнерами, например для меток, заметок и проверок качества.
- Возможность трассировки и происхождения для стека критического восприятия безопасности, который фиксирует управление версиями и происхождение данных измерений.
- Метаданные и обнаружение данных для улучшения семантической сегментации, классификации изображений и моделей обнаружения объектов.
Это решение AVOps DataOps предоставляет рекомендации по устранению этих проблем.
Возможные варианты использования
Это решение обеспечивает преимущества изготовителей автомобильного оборудования (OEM), поставщиков уровня 1 и независимых поставщиков программного обеспечения (ISV), которые разрабатывают решения для автоматического управления.
Федеративные операции с данными
В организации, реализующей AVOps, несколько команд участвуют в DataOps из-за сложности, необходимой для AVOps. Например, одна команда может отвечать за сбор данных и прием данных. Другая команда может отвечать за управление качеством данных лидарных данных. По этой причине для DataOps важно учитывать следующие принципы архитектуры сетки данных
- Ориентация на домены владения данными и архитектуры. Одна выделенная команда отвечает за один домен данных, предоставляющий продукты данных для этого домена, например помеченные наборы данных.
- Данные как продукт. Каждый домен данных содержит различные зоны в контейнерах хранилища, реализованных в data lake. Существуют зоны для внутреннего использования. Существует также зона, содержащая опубликованные продукты данных для других доменов данных или внешнего использования, чтобы избежать дублирования данных.
- Самостоятельное использование данных в качестве платформы для включения автономных групп данных, ориентированных на домен.
- Федеративное управление для обеспечения взаимодействия и доступа между доменами данных AVOps, для которых требуется централизованное хранилище метаданных и каталог данных. Например, домену данных с метками может потребоваться доступ к домену сбора данных.
Дополнительные сведения о реализации сетки данных см. в аналитики в облаке.
Пример структуры для доменов данных AVOps
В следующей таблице приведены некоторые идеи для структурирования доменов данных AVOps:
| Домен данных | Опубликованные продукты данных | Шаг решения |
|---|---|---|
| Сбор данных | Отправленные и проверенные файлы измерений | Посадка и сырая |
| Извлеченные изображения | Выбранные и извлеченные изображения или кадры, лидар и радарные данные | Извлекаемый |
| Извлеченный радар или лидар | Выбранные и извлеченные лидарные и радарные данные | Извлекаемый |
| Извлеченные данные телеметрии | Выбранные и извлеченные данные телеметрии автомобиля | Извлекаемый |
| Меченый | Помеченные наборы данных | Меченый |
| Перекомпьютировать | Созданные ключевые показатели производительности (ключевые показатели эффективности) на основе повторяющихся запусков имитации | Перекомпьютировать |
Каждый домен данных AVOps настраивается на основе структуры схемы. Эта структура включает фабрику данных, Data Lake Storage, базы данных, пакетную среду выполнения и среду выполнения Apache Spark с помощью Azure Databricks или Azure Synapse Analytics.
Обнаружение метаданных и данных
Каждый домен данных децентрализован и управляет соответствующими продуктами данных AVOps. Для централизованного обнаружения данных и получения данных о расположении продуктов данных требуются два компонента:
- Хранилище метаданных, которое сохраняет метаданные о обработанных файлах измерений и потоках данных, таких как последовательности видео. Этот компонент делает данные обнаруживаемыми и трассируемыми с помощью заметок, которые необходимо индексировать, например для поиска метаданных неназначенных файлов. Например, может потребоваться, чтобы хранилище метаданных возвращали все кадры для определенных идентификаторов транспортных средств (VIN) или кадров с пешеходами или другими объектами на основе обогащения.
- Каталог данных, показывающий происхождение, зависимости между доменами данных AVOps и хранилищами данных, участвующими в цикле данных AVOps. Примером каталога данных является Microsoft Purview.
Azure Data Explorer или Azure Cognitive Search можно использовать для расширения хранилища метаданных, основанного на Azure Cosmos DB. Выбор зависит от окончательного сценария, необходимого для обнаружения данных. Используйте Когнитивный поиск Azure для возможностей семантического поиска.
На следующей схеме модели метаданных показана стандартная унифицированная модель метаданных, используемая в нескольких основных элементах цикла данных AVOps:
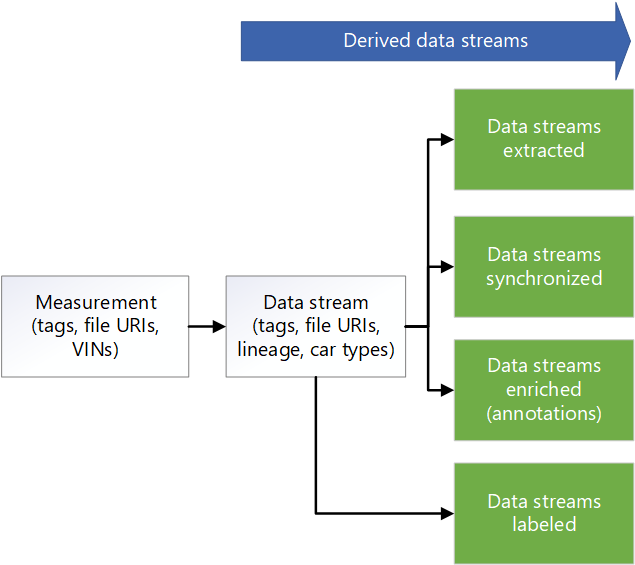
Общий доступ к данным
Общий доступ к данным — это распространенный сценарий в цикле данных AVOps. Используется включение общего доступа к данным между доменами данных и внешним общим доступом, например для интеграции партнеров по маркировке. Microsoft Purview предоставляет следующие возможности для эффективного совместного использования данных в цикле данных:
Рекомендуемые форматы для обмена данными меток включают общие объекты в наборах данных в контексте (COCO) и Ассоциации по стандартизации наборов данных Автоматизации и измерений (ASAM) OpenLABEL.
В этом решении помеченные наборы данных используются в процессах MLOps для создания специализированных алгоритмов, таких как модели восприятия и слияния датчиков. Алгоритмы могут обнаруживать сцены и объекты в среде, такие как изменение полосы движения автомобиля, заблокированные дороги, пешеходное движение, светофор и знаки дорожного движения.
Конвейер данных
В этом решении DataOps перемещение данных между разными этапами конвейера данных автоматизировано. Благодаря этому подходу процесс обеспечивает эффективность, масштабируемость, согласованность, воспроизводимость, адаптируемость и преимущества обработки ошибок. Он улучшает общий процесс разработки, ускоряет ход выполнения и поддерживает безопасное и эффективное развертывание автономных технологий вождения.
В следующих разделах описывается, как реализовать перемещение данных между этапами и структуру учетных записей хранения.
Иерархическая структура папок
Хорошо упорядоченная структура папок является жизненно важным компонентом конвейера данных в автономном управлении разработкой. Такая структура обеспечивает систематическую и легкодоступную структуру файлов данных, упрощая эффективное управление данными и получение.
В этом решении данные в папке необработанных
регион/необработанный/<измерение-идентификатор>/<data-stream-ID>/YYYY/MM/DD
Данные в учетной записи хранения извлеченной зоны используют аналогичную иерархическую структуру:
регион/извлеченный/<идентификатор измерения>/<data-stream-ID>/YYYY/MM/DD
Используя аналогичные иерархические структуры, вы можете воспользоваться преимуществами возможностей иерархического пространства имен Data Lake Storage. Иерархические структуры помогают создавать масштабируемое и экономичное хранилище объектов. Эти структуры также повышают эффективность поиска объектов и извлечения. Секционирование по годам и VIN упрощает поиск соответствующих изображений из определенных транспортных средств. В озере данных контейнер хранилища создается для каждого датчика, например камеры, GPS-устройства или лидара или датчика радара.
Целевая учетная запись хранения в необработанной учетной записи хранения
Конвейер фабрики данных активируется на основе расписания. После активации конвейера данные копируются из целевой учетной записи хранения в учетную запись необработанного хранения.
схема архитектуры 
Конвейер извлекает все папки измерений и выполняет итерацию. При каждом измерении решение выполняет следующие действия:
Функция проверяет измерение. Функция извлекает файл манифеста из манифеста измерения. Затем функция проверяет, существуют ли все файлы измерений MDF4, TDMS и rosbag для текущего измерения в папке измерения. Если проверка выполнена успешно, функция переходит к следующему действию. Если проверка завершается ошибкой, функция пропускает текущее измерение и переходит в следующую папку измерения.
Вызов веб-API выполняется в API, который создает измерение, а полезные данные JSON из JSON-файла манифеста измерения передаются в API. Если вызов выполнен успешно, ответ анализируется для получения идентификатора измерения. Если вызов завершается сбоем, измерение перемещается в действие on-error для обработки ошибок.
Заметка
Это решение DataOps основано на предположении, что вы ограничиваете количество запросов к службе приложений. Если решение может сделать неопределенное количество запросов, рассмотрите шаблон ограничения скорости.
Вызов веб-API выполняется в API, который создает поток данных, создавая необходимые полезные данные JSON. Если вызов выполнен успешно, ответ анализируется для получения идентификатора потока данных и расположения потока данных. Если вызов завершается ошибкой, измерение перемещается в действие по ошибке.
Вызов веб-API выполняется для обновления состояния потока данных до
Start Copy. Если вызов выполнен успешно, действие копирования копирует файлы измерений в расположение потока данных. Если вызов завершается ошибкой, измерение перемещается в действие по ошибке.Конвейер фабрики данных вызывает пакетную службу для копирования файлов измерений из целевой учетной записи хранения в учетную запись необработанного хранения. Модуль копирования приложения оркестратора создает задание со следующими задачами для каждого измерения:
- Скопируйте файлы измерений в учетную запись хранения Raw.
- Скопируйте файлы измерений в архивную учетную запись хранения.
- Удалите файлы измерений из целевой учетной записи хранения.
Заметка
В этих задачах пакетная служба использует пул оркестратора и средство AzCopy для копирования и удаления данных. AzCopy использует маркеры SAS для выполнения задач копирования или удаления. Маркеры SAS хранятся в хранилище ключей и ссылаются с помощью терминов
landingsaskey,archivesaskeyиrawsaskey.Вызов веб-API выполняется для обновления состояния потока данных до
Copy Complete. Если вызов выполнен успешно, последовательность переходит к следующему действию. Если вызов завершается ошибкой, измерение перемещается в действие по ошибке.Файлы измерений перемещаются из целевой учетной записи хранения в целевой архив. Это действие может повторно выполнить определенное измерение, переместив его обратно в учетную запись хранения Целевой платформы с помощью конвейера копирования гидрата. Управление жизненным циклом включается для этой зоны, чтобы измерения в этой зоне были автоматически удалены или архивированы.
Если с измерением возникает ошибка, измерение перемещается в зону ошибок. Затем его можно переместить в целевую учетную запись хранения для повторного запуска. Кроме того, управление жизненным циклом может автоматически удалять или архивировать измерение.
Обратите внимание на следующие моменты:
- Эти конвейеры активируются на основе расписания. Этот подход помогает улучшить трассировку запусков конвейера и избежать ненужных запусков.
- Каждый конвейер настроен со значением параллелизма одного, чтобы убедиться, что предыдущие запуски завершаются до следующего запланированного запуска.
- Каждый конвейер настраивается для параллельного копирования измерений. Например, если запланированное выполнение выбирает 10 измерений для копирования, шаги конвейера можно выполнять одновременно для всех десяти измерений.
- Каждый конвейер настроен для создания оповещения в Мониторе, если конвейер занимает больше времени завершения.
- Действие по ошибке реализуется в последующих историях наблюдаемости.
- Управление жизненным циклом автоматически удаляет частичные измерения, например измерения с отсутствующими файлами rosbag.
Пакетная разработка
Логика извлечения упаковывается в разные образы контейнеров с одним контейнером для каждого процесса извлечения. Пакетная служба параллельно запускает рабочие нагрузки контейнера при извлечении сведений из файлов измерений.
схема архитектуры 
Пакетная служба использует пул оркестратора и пул выполнения для обработки рабочих нагрузок:
- Пул оркестраторов имеет узлы Linux без поддержки среды выполнения контейнеров. Пул запускает код Python, использующий API пакетной службы для создания заданий и задач для пула выполнения. Этот пул также отслеживает эти задачи. Фабрика данных вызывает пул оркестратора, который управляет рабочими нагрузками контейнера, извлекающими данные.
- Пул выполнения содержит узлы Linux с средами выполнения контейнеров для поддержки рабочих нагрузок контейнеров. Для этого пула задания и задачи запланированы с помощью пула оркестратора. Все образы контейнеров, необходимые для обработки в пуле выполнения, отправляются в реестр контейнеров с помощью JFrog. Пул выполнения настроен для подключения к этому реестру и извлечения необходимых образов.
Учетные записи хранения, из которых данные считываются и записываются, подключены через NFS 3.0 на узлах пакетной службы и контейнерах, выполняемых на узлах. Этот подход помогает пакетным узлам и контейнерам быстро обрабатывать данные без необходимости скачивать файлы данных локально на узлы пакетной службы.
Заметка
Учетные записи пакетной службы и хранения должны находиться в одной виртуальной сети для подключения.
Вызов пакетной службы из фабрики данных
В конвейере извлечения триггер передает путь файла метаданных и путь к потоку необработанных данных в параметрах конвейера. Фабрика данных использует действие подстановки для анализа JSON из файла манифеста. Идентификатор потока необработанных данных можно извлечь из пути потока необработанных данных, проанализировав переменную конвейера.
Фабрика данных вызывает API для создания потока данных. API возвращает путь для извлеченного потока данных. Извлеченный путь добавляется к текущему объекту, а фабрика данных вызывает пакетную службу через настраиваемое действие, передав текущий объект после добавления пути к извлеченной потоку данных:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
Пошаговый процесс извлечения

Фабрика данных планирует задание с одной задачей для пула оркестраторов для обработки измерения для извлечения. Фабрика данных передает следующие сведения в пул оркестратора:
- Идентификатор измерения
- Расположение файлов измерений типа MDF4, TDMS или rosbag, которые необходимо извлечь
- Путь к целевому расположению хранилища извлеченного содержимого
- Идентификатор извлеченного потока данных
Пул оркестратора вызывает API для обновления потока данных и задания его состояния на
Processing.Пул оркестратора создает задание для каждого файла измерения, который является частью измерения. Каждое задание содержит следующие задачи:
Задача Цель Заметка Ратификация Проверяет, можно ли извлечь данные из файла измерения. Все остальные задачи зависят от этой задачи. Метаданные процесса Извлекает метаданные из файла измерения и дополняет метаданные файла с помощью API для обновления метаданных файла. Обработка StructuredTopicsИзвлекает структурированные данные из заданного файла измерения. Список разделов для извлечения структурированных данных передается в виде объекта конфигурации. Обработка CameraTopicsИзвлекает данные изображения из заданного файла измерения. Список разделов для извлечения изображений из объекта конфигурации передается в виде объекта конфигурации. Обработка LidarTopicsИзвлекает данные lidar из заданного файла измерения. Список разделов для извлечения данных lidar из передается в виде объекта конфигурации. Обработка CANTopicsИзвлекает данные сети области контроллера (CAN) из заданного файла измерения. Список разделов для извлечения данных из объекта конфигурации передается в виде объекта конфигурации. Пул оркестраторов отслеживает ход выполнения каждой задачи. После завершения всех заданий для всех файлов измерений пул вызывает API для обновления потока данных и задания его состояния
Completed.Оркестратор завершается корректно.
Заметка
Каждая задача — это отдельный образ контейнера с логикой, которая правильно определена для своей цели. Задачи принимают объекты конфигурации в качестве входных данных. Например, входные данные указывают, где записывать выходные данные и какой файл измерения для обработки. Массив типов разделов, таких как
sensor_msgs/Image, является еще одним примером входных данных. Так как все остальные задачи зависят от задачи проверки, для нее создается зависимое задание. Все остальные задачи могут обрабатываться независимо и выполняться параллельно.
Соображения
Эти рекомендации реализуют основные принципы платформы Azure Well-Architected Framework, которая представляет собой набор руководящих принципов, которые можно использовать для повышения качества рабочей нагрузки. Дополнительные сведения см. в статье Microsoft Azure Well-Architected Framework.
Надёжность
Надежность гарантирует, что ваше приложение может выполнять обязательства, которые вы выполняете для клиентов. Дополнительные сведения см. в разделе Обзоркомпонента надежности.
- В решении рекомендуется использовать зонах доступности Azure, которые являются уникальными физическими расположениями в одном регионе Azure.
- Планирование аварийного восстановления и учетной записи отработки отказа.
Безопасность
Безопасность обеспечивает гарантии от преднамеренного нападения и злоупотребления ценными данными и системами. Дополнительные сведения см. в разделе Обзоркомпонента безопасности.
Важно понимать разделение ответственности между автомобильным изготовителем оборудования и корпорацией Майкрософт. В транспортном средстве OEM владеет целым стеком, но по мере перемещения данных в облако некоторые обязанности передаются в Корпорацию Майкрософт. Уровни платформы Azure как услуги (PaaS) обеспечивают встроенную безопасность в физическом стеке, включая операционную систему. Вы можете добавить следующие возможности в существующие компоненты безопасности инфраструктуры:
- Управление удостоверениями и доступом, использующими удостоверения Microsoft Entra и
политики условного доступа Microsoft Entra. - Управление инфраструктурой, использующее политику Azure.
- Управление данными, использующее Microsoft Purview.
- Шифрование неактивных данных, использующих собственные службы хранилища Azure и базы данных. Дополнительные сведения см. в рекомендации по защите данных.
- Защита криптографических ключей и секретов. Используйте Azure Key Vault для этой цели.
Оптимизация затрат
Оптимизация затрат рассматривает способы сокращения ненужных расходов и повышения эффективности работы. Дополнительные сведения см. в разделе
Ключевой проблемой для изготовителей оборудования и поставщиков уровня 1, работающих с DataOps для автоматизированных транспортных средств, является стоимость эксплуатации. Это решение использует следующие методики для оптимизации затрат:
- Использование различных вариантов, которые Azure предлагает для размещения кода приложения. Это решение использует службу приложений и пакетную службу. Инструкции по выбору подходящей службы для развертывания см. в статье Выбор службы вычислений Azure.
- Использование совместного использования данных на месте службы хранилища Azure.
- Оптимизация затрат с помощью управления жизненным циклом .
- Экономия затрат на службу приложений с помощью зарезервированных экземпляров.
Участников
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участниками.
Основные авторы:
- Райан Матсумура | Старший менеджер по программам
- Джохен Шройер | Ведущий архитектор (Service Line Mobility)
- Бридж Сингх | Главный инженер программного обеспечения
- Ginette Vellera | Старший руководитель по проектированию программного обеспечения
Чтобы просмотреть профили LinkedIn, войдите в LinkedIn.
Дальнейшие действия
- Что такое пакетная служба Azure?
- Что такое фабрика данных Azure?
- Введение в Azure Data Lake Storage 2-го поколения
- добро пожаловать в Azure Cosmos DB
- Обзор службы приложений
- Что такое Общий ресурс данных Azure?
- Что такое Azure Data Box?
- документации по Azure Stack Edge
- Что такое Azure ExpressRoute?
- Что такое Машинное обучение Azure?
- Что такое Azure Databricks?
- Что такое Azure Synapse Analytics?
- обзор Azure Monitor
- файлы журналов ROS (rosbags)
- масштабируемую платформу операций с данными для автономных транспортных средств
Связанные ресурсы
Дополнительные сведения о разработке ValOps для автономной системы вождения см. в следующем разделе:
Вы также можете быть заинтересованы в следующих статьях: