Руководство. Часть 3. Оценка пользовательского приложения чата с помощью пакета SDK для Azure AI Foundry
В этом руководстве вы используете пакет SDK для ИИ Azure (и другие библиотеки) для оценки приложения чата, созданного в серии учебников 2. В этой части 3 вы узнаете, как:
- Создание набора данных оценки
- Оценка приложения чата с помощью вычислителей ИИ Azure
- Итерацию и улучшение приложения
Это руководство является частью трех из трех частей учебника.
Необходимые компоненты
- Выполните часть 2 серии учебников для создания приложения чата.
- Убедитесь, что вы выполнили действия по добавлению ведения журнала телеметрии из части 2.
Оценка качества ответов приложения чата
Теперь, когда вы знаете, что ваше приложение чата хорошо отвечает на ваши запросы, в том числе с журналом чата, пришло время оценить, как это делается в нескольких различных метрик и других данных.
Вы используете средство оценки с набором данных оценки и get_chat_response() целевой функцией, а затем оцениваете результаты оценки.
После запуска оценки вы можете внести улучшения в логику, например улучшить системный запрос и наблюдать за изменением и улучшением ответов приложения чата.
Создание набора данных оценки
Используйте следующий набор данных оценки, содержащий примеры вопросов и ожидаемых ответов (истина).
Создайте файл с именем chat_eval_data.jsonl в папке ресурсов .
Вставьте этот набор данных в файл:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Оценка с помощью вычислителей ИИ Azure
Теперь определите скрипт оценки, который будет:
- Создайте оболочку целевой функции вокруг логики приложения чата.
- Загрузите пример
.jsonlнабора данных. - Запустите оценку, которая принимает целевую функцию и объединяет набор данных оценки с ответами из приложения чата.
- Создайте набор метрик с поддержкой GPT (релевантность, заземленность и согласованность), чтобы оценить качество ответов приложения чата.
- Выводит результаты локально и записывает результаты в облачный проект.
Скрипт позволяет просматривать результаты локально, выводя результаты в командной строке и в json-файл.
Скрипт также записывает результаты оценки в облачный проект, чтобы можно было сравнить выполнение оценки в пользовательском интерфейсе.
Создайте файл с именем evaluate.py в главной папке.
Добавьте следующий код для импорта необходимых библиотек, создания клиента проекта и настройки некоторых параметров:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Добавьте код для создания функции-оболочки, реализующей интерфейс оценки для оценки запросов и ответа:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Наконец, добавьте код для выполнения оценки, просмотрите результаты локально и предоставляет ссылку на результаты оценки на портале Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Настройка модели оценки
Так как скрипт оценки вызывает модель много раз, может потребоваться увеличить количество маркеров в минуту для модели оценки.
В части 1 этого руководства вы создали env-файл, указывающий имя модели оценки. gpt-4o-mini Попробуйте увеличить маркеры в минуту для этой модели, если у вас есть доступная квота. Если у вас нет достаточной квоты, чтобы увеличить значение, не волнуйтесь. Скрипт предназначен для обработки ошибок ограничения.
- В проекте на портале Azure AI Foundry выберите "Модели + конечные точки".
- Выберите gpt-4o-mini.
- Выберите Изменить.
- Если у вас есть квота, чтобы увеличить токены в минуту, попробуйте увеличить его до 30.
- Выберите Сохранить и закрыть.
Запуск скрипта оценки
В консоли войдите в учетную запись Azure с помощью Azure CLI:
az loginУстановите необходимый пакет:
pip install azure-ai-evaluation[remote]Теперь запустите скрипт оценки:
python evaluate.py
Интерпретация выходных данных оценки
В выходных данных консоли вы увидите ответ на каждый вопрос, а затем таблицу с сводными метриками. (В выходных данных могут отображаться разные столбцы.)
Если вы не смогли увеличить предел маркеров в минуту для модели, могут появиться некоторые ошибки времени ожидания, которые ожидаются. Скрипт оценки предназначен для обработки этих ошибок и продолжения выполнения.
Примечание.
Вы также можете увидеть много WARNING:opentelemetry.attributes: - они могут быть безопасно проигнорированы и не влияют на результаты оценки.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Просмотр результатов оценки на портале Azure AI Foundry
После завершения выполнения оценки перейдите по ссылке, чтобы просмотреть результаты оценки на странице оценки на портале Azure AI Foundry.
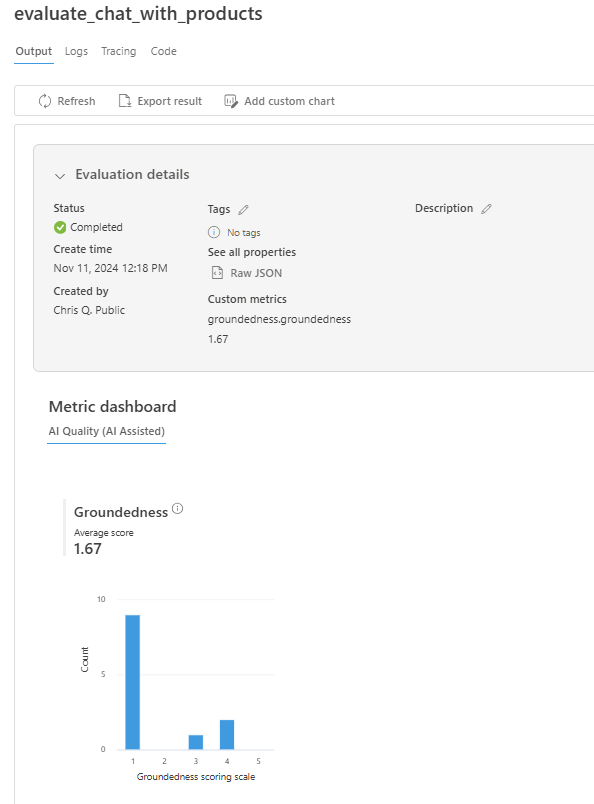
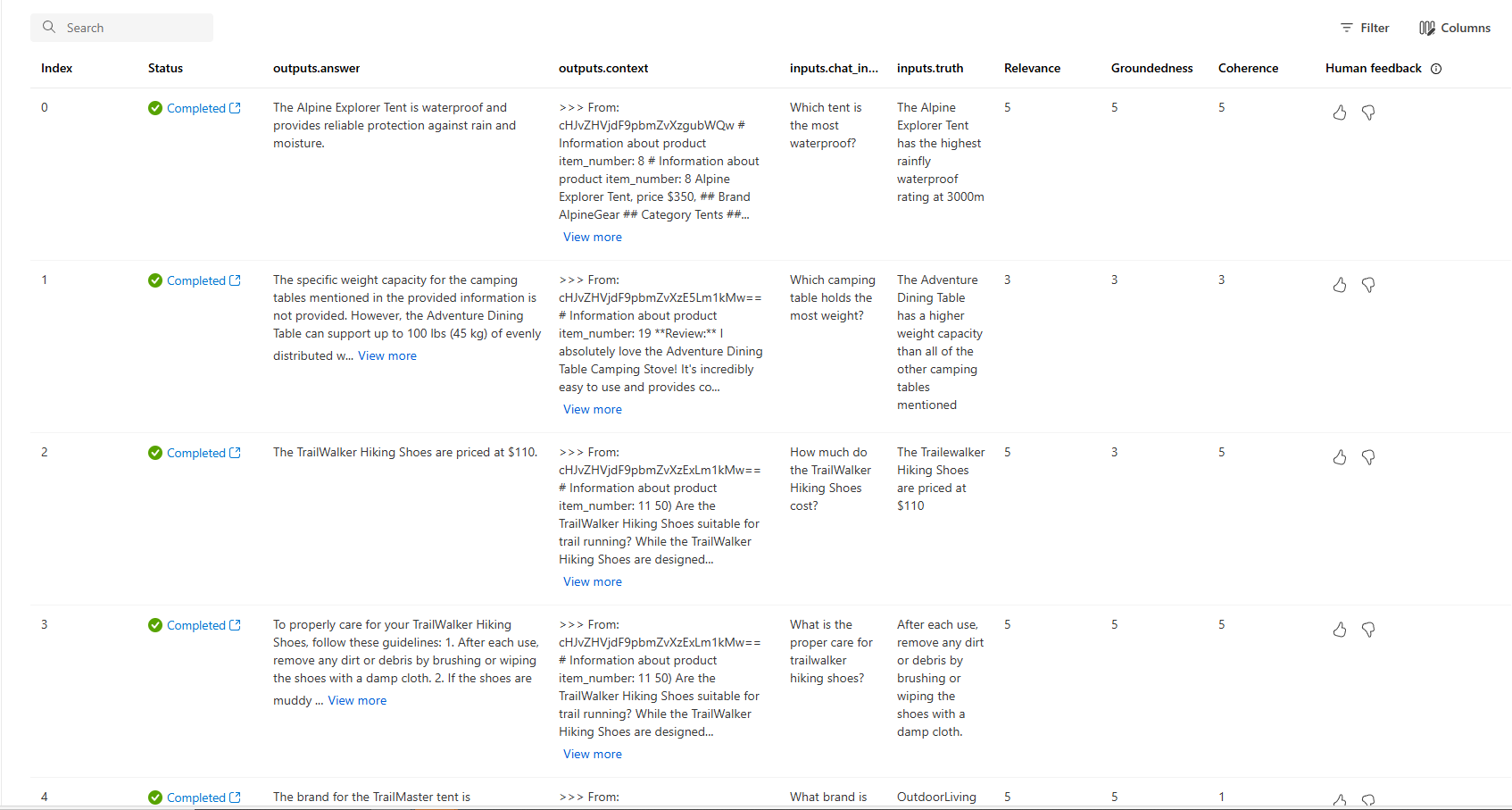
Вы также можете просмотреть отдельные строки и просмотреть оценки метрик для каждой строки и просмотреть все извлеченные контекст/документы. Эти метрики могут быть полезны при интерпретации и отладке результатов оценки.
Дополнительные сведения о результатах оценки на портале Azure AI Foundry см . на портале Azure AI Foundry.
Итерацию и улучшение
Обратите внимание, что ответы не являются хорошо обоснованными. Во многих случаях модель отвечает на вопрос, а не ответ. Это результат инструкций шаблона запроса.
- В файле assets/grounded_chat.prompty найдите предложение "Если вопрос связан с открытым и кемпингом шестеренки и одежды, но расплывчатый, попросите уточнять вопросы вместо ссылки на документы".
- Измените предложение на "Если вопрос связан с открытым или кемпингом шестеренки и одежды, но расплывчатым, попробуйте ответить на основе справочных документов, а затем попросите уточняющие вопросы".
- Сохраните файл и повторно запустите скрипт оценки.
Попробуйте другие изменения в шаблоне запроса или попробуйте другие модели, чтобы узнать, как изменения влияют на результаты оценки.
Очистка ресурсов
Чтобы избежать ненужных затрат Azure, следует удалить ресурсы, созданные в этом руководстве, если они больше не нужны. Для управления ресурсами можно использовать портал Azure.