Разработка приложений с помощью LangChain и Azure AI Foundry
LangChain — это экосистема разработки, которая позволяет разработчикам создавать приложения по этой причине. Экосистема состоит из нескольких компонентов. Большинство из них можно использовать самостоятельно, позволяя выбирать и выбирать все компоненты, которые вам нравится лучше всего.
Модели, развернутые в Azure AI Foundry, можно использовать с LangChain двумя способами:
Использование API вывода модели Azure. Все модели, развернутые в Azure AI Foundry, поддерживают API вывода модели ИИ Azure, который предлагает общий набор функциональных возможностей, которые можно использовать для большинства моделей в каталоге. Преимуществом этого API является то, что, так как это одинаково для всех моделей, переход от одного к другому так же просто, как изменение используемого развертывания модели. Дальнейшие изменения в коде не требуются. При работе с LangChain установите расширения
langchain-azure-ai.Использование конкретного API поставщика модели: некоторые модели, такие как OpenAI, Cohere или Mistral, предлагают собственный набор API и расширений для LlamaIndex. Эти расширения могут включать определенные функциональные возможности, которые поддерживают модель и поэтому подходят, если вы хотите использовать их. При работе с LangChain установите расширение, конкретное для модели, которую вы хотите использовать, например
langchain-openaiилиlangchain-cohere.
В этом руководстве описано, как использовать пакеты langchain-azure-ai для создания приложений с помощью LangChain.
Необходимые компоненты
Для работы с этим руководством необходимы указанные ниже компоненты.
Развертывание модели, поддерживающее развернутый API вывода модели ИИ Azure. В этом примере мы используем
Mistral-Large-2407развертывание в выводе модели ИИ Azure.Python 3.9 или более поздней версии, включая pip.
LangChain установлен. Это можно сделать с помощью:
pip install langchain-coreВ этом примере мы работаем с API вывода модели ИИ Azure, поэтому мы устанавливаем следующие пакеты:
pip install -U langchain-azure-ai
Настройка среды
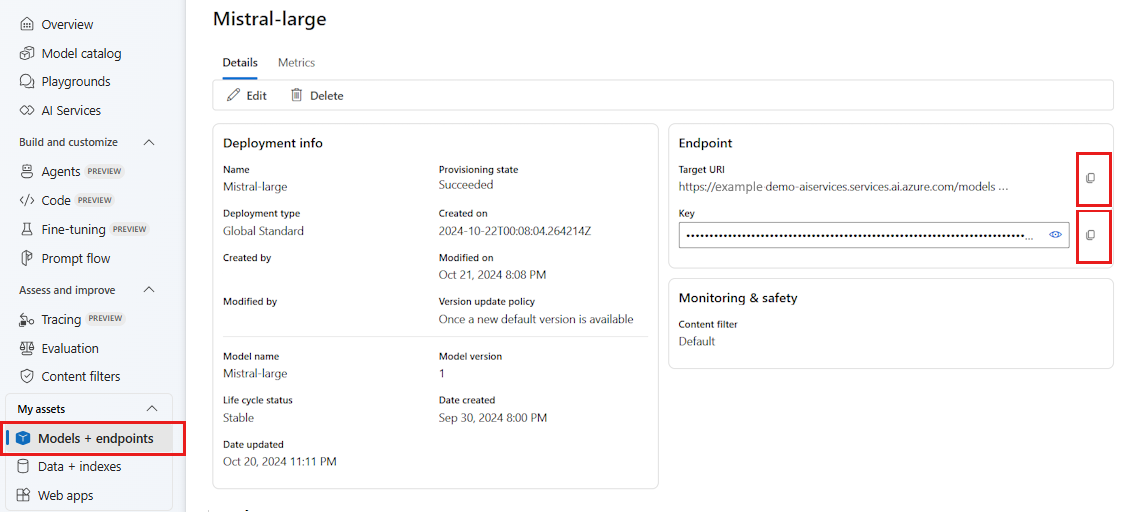
Чтобы использовать LLM, развернутые на портале Azure AI Foundry, вам потребуется конечная точка и учетные данные для подключения к нему. Выполните следующие действия, чтобы получить необходимые сведения из модели, которую вы хотите использовать:
Перейдите в Azure AI Foundry.
Откройте проект, в котором развернута модель, если она еще не открыта.
Перейдите к моделям и конечным точкам и выберите развернутую модель, как указано в предварительных требованиях.
Скопируйте URL-адрес конечной точки и ключ.
Совет
Если модель была развернута с поддержкой идентификатора Microsoft Entra ID, вам не нужен ключ.

В этом сценарии мы помещали URL-адрес конечной точки и ключ в следующие переменные среды:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
После настройки создайте клиент для подключения к конечной точке. В этом случае мы работаем с моделью завершения чата, поэтому импортируем класс AzureAIChatCompletionsModel.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
Совет
Для моделей Azure OpenAI настройте клиент, как указано при использовании моделей Azure OpenAI.
Чтобы создать клиент, можно использовать следующий код, если конечная точка поддерживает идентификатор Microsoft Entra:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
Примечание.
При использовании идентификатора Microsoft Entra убедитесь, что конечная точка была развернута с помощью этого метода проверки подлинности и у вас есть необходимые разрешения для вызова.
Если вы планируете использовать асинхронный вызов, рекомендуется использовать асинхронную версию для учетных данных:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
Если конечная точка обслуживает одну модель, например с конечными точками API без сервера, вам не нужно указывать model_name параметр:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Использование моделей завершения чата
Сначала будем использовать модель напрямую.
ChatModels — это экземпляры LangChain Runnable, что означает, что они предоставляют стандартный интерфейс для взаимодействия с ними. Чтобы просто вызвать модель, мы можем передать в метод список сообщений invoke .
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
Вы также можете создавать операции по мере необходимости в цепочках, которые называются цепочками. Теперь используйте шаблон запроса для перевода предложений:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
Как видно из шаблона запроса, эта цепочка имеет language входные данные и text входные данные. Теперь создадим средство синтаксического анализа выходных данных:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
Теперь можно объединить шаблон, модель и средство синтаксического анализа выходных данных выше с помощью оператора канала (|).
chain = prompt_template | model | parser
Чтобы вызвать цепочку, определите необходимые входные данные и укажите значения с помощью invoke метода:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
Объединение нескольких LLM
Модели, развернутые в Azure AI Foundry, поддерживают API вывода модели Azure, которая является стандартной для всех моделей. Цепочка нескольких операций LLM на основе возможностей каждой модели, чтобы оптимизировать правильную модель на основе возможностей.
В следующем примере мы создадим два клиента модели, один — производитель, а другой — проверяющий. Чтобы четко определить различие, мы используем конечную точку с несколькими моделями, например службу вывода модели искусственного интеллекта Azure, и поэтому мы передаваем параметр model_name для использования Mistral-Large и Mistral-Small модели, цитируя тот факт, что производство содержимого является более сложным, чем проверка.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
Совет
Изучите карточку модели каждой из моделей, чтобы понять лучшие варианты использования для каждой модели.
В следующем примере создается стихотворение, написанное городским поэтом:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
Теперь давайте прицедим куски:
chain = producer_template | producer | parser | verifier_template | verifier | parser
Предыдущая цепочка возвращает только выходные данные шага verifier . Так как мы хотим получить доступ к промежуточному результату, созданному в producerLangChain, необходимо использовать RunnablePassthrough объект для вывода этого промежуточного шага. В следующем коде показано, как это сделать:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
Чтобы вызвать цепочку, определите необходимые входные данные и укажите значения с помощью invoke метода:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
Использование моделей внедрения
Таким же образом вы создаете клиент LLM, вы можете подключиться к модели внедрения. В следующем примере мы устанавливаем переменную среды, чтобы она указывала на модель внедрения:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Затем создайте клиент:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
В следующем примере показан простой пример использования векторного хранилища в памяти:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
Давайте добавим некоторые документы:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
Давайте ищем по подобию:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
Использование моделей Azure OpenAI
Если вы используете службу Azure OpenAI или службу вывода моделей ИИ Azure с моделями OpenAI с langchain-azure-ai пакетом, может потребоваться использовать api_version параметр для выбора определенной версии API. В следующем примере показано, как подключиться к развертыванию модели Azure OpenAI в службе Azure OpenAI:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Внимание
Проверьте, какая версия API используется в развертывании. Использование неправильного api_version или не поддерживаемого моделью приводит к исключению ResourceNotFound .
Если развертывание размещено в Службах ИИ Azure, можно использовать службу вывода модели ИИ Azure:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
Отладка и устранение неполадок
Если необходимо выполнить отладку приложения и понять запросы, отправленные в модели в Azure AI Foundry, можно использовать возможности отладки интеграции следующим образом:
Сначала настройте ведение журнала на нужный уровень:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
Чтобы просмотреть полезные данные запросов при создании экземпляра клиента, передайте аргумент logging_enable=True в :client_kwargs
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
Используйте клиент как обычно в коде.
Трассировка
Вы можете использовать возможности трассировки в Azure AI Foundry, создав трассировщик. Журналы хранятся в приложение Azure Insights и могут запрашиваться в любое время с помощью портала Azure Monitor или Azure AI Foundry. С каждым центром ИИ связана приложение Azure Insights.
Получение строка подключения инструментирования
Вы можете настроить приложение для отправки телеметрии в приложение Azure Insights следующими способами:
Использование строка подключения для приложение Azure Insights напрямую:
Перейдите на портал Azure AI Foundry и выберите "Трассировка".
Выберите " Управление источником данных". На этом экране вы увидите экземпляр, связанный с проектом.
Скопируйте значение строки подключения и задайте для нее следующую переменную:
import os application_insights_connection_string = "instrumentation...."
Использование пакета SDK для Azure AI Foundry и проекта строка подключения.
Убедитесь, что пакет
azure-ai-projectsустановлен в вашей среде.Перейдите на портал Azure AI Foundry.
Скопируйте строка подключения проекта и задайте для него следующий код:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Настройка трассировки для Azure AI Foundry
Следующий код создает трассировщик, подключенный к приложение Azure Insights за проектом в Azure AI Foundry. Обратите внимание, что для параметра enable_content_recording задано значение True. Это позволяет записывать входные и выходные данные всего приложения, а также промежуточные шаги. Это полезно при отладке и создании приложений, но может потребоваться отключить его в рабочих средах. По умолчанию используется переменная AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLEDсреды:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
Чтобы настроить трассировку в цепочке invoke , укажите конфигурацию значения в операции в качестве обратного вызова:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
Чтобы настроить саму цепочку для трассировки, используйте .with_config() метод:
chain = chain.with_config({"callbacks": [tracer]})
Затем используйте invoke() метод как обычно:
chain.invoke({"topic": "living in a foreign country"})
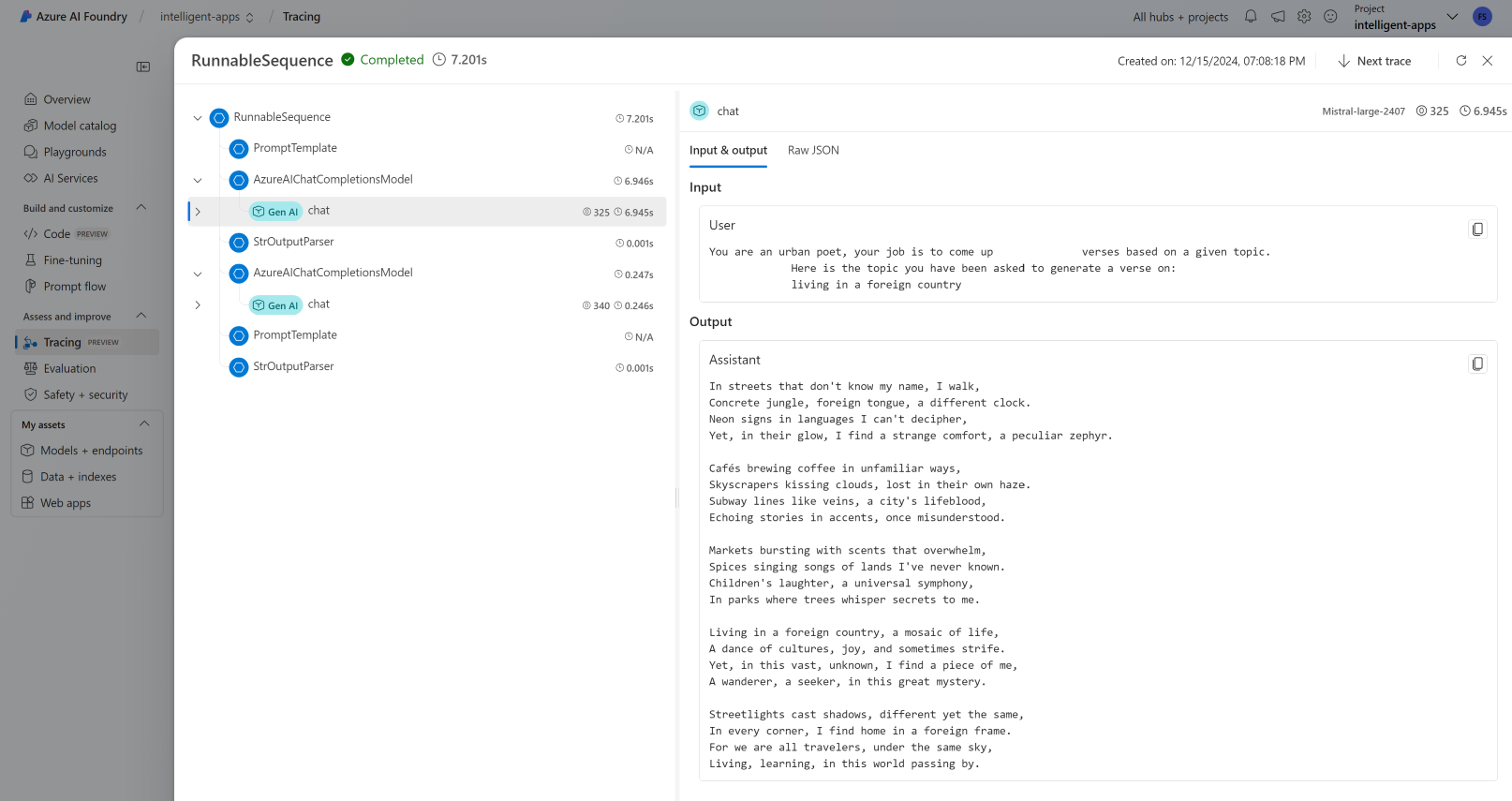
Просмотр трассировок
Чтобы просмотреть трассировки:
Перейдите на портал Azure AI Foundry.
Перейдите к разделу трассировки .
Определите созданную трассировку. Для отображения трассировки может потребоваться несколько секунд.

Узнайте больше о том, как визуализировать трассировки и управлять ими.