Краткое руководство. Распознавание и преобразование речи в текст
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этом кратком руководстве описана попытка преобразования речи в режиме реального времени в текст в Azure AI Foundry.
Необходимые компоненты
- Подписка Azure — создайте бесплатную учетную запись.
- Некоторые функции служб искусственного интеллекта Azure можно использовать на портале Azure AI Foundry. Для доступа ко всем возможностям, описанным в этой статье, необходимо подключить службы ИИ в Azure AI Foundry.
Попробуйте преобразование речи в режиме реального времени в текст
Перейдите в проект Azure AI Foundry. Если вам нужно создать проект, см . статью "Создание проекта Azure AI Foundry".
Выберите площадки на левой панели и выберите нужную площадку. В этом примере выберите " Попробовать игровую площадку "Речь".
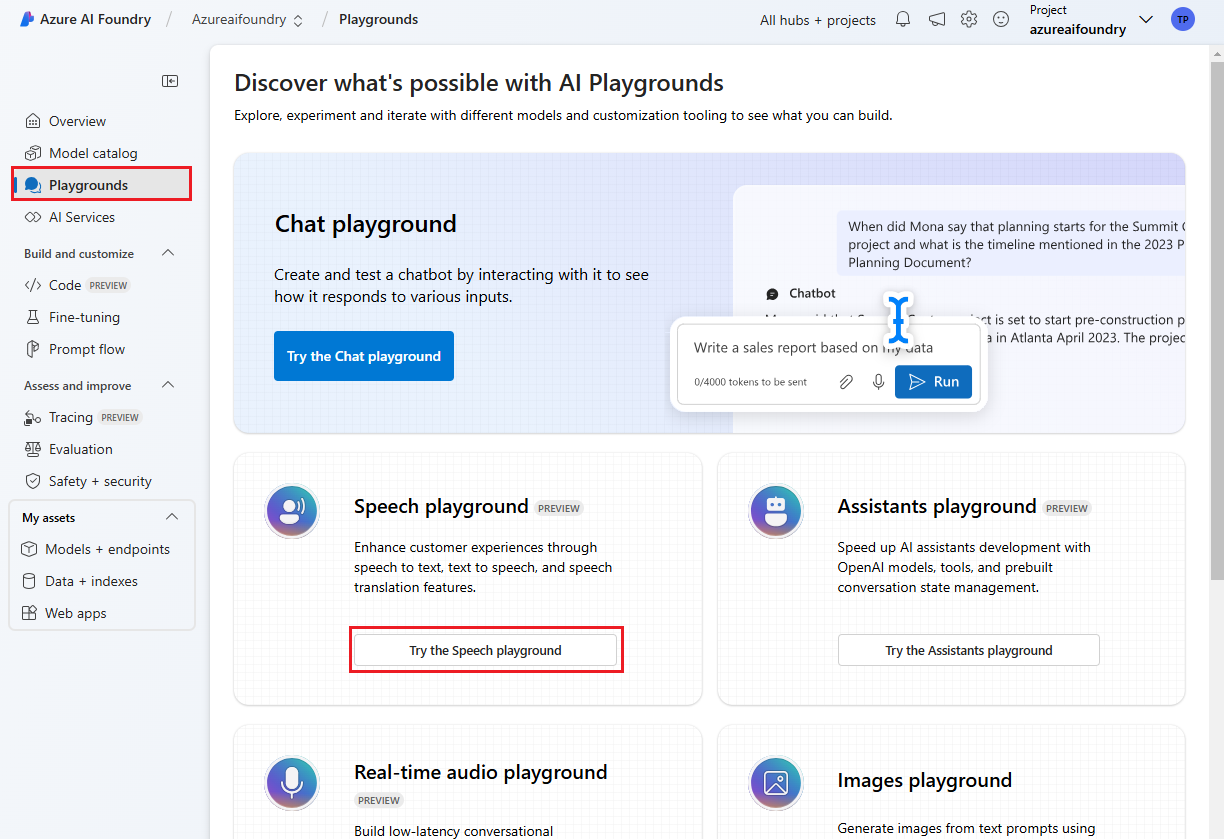
При необходимости можно выбрать другое подключение для использования на детской площадке. На игровой площадке службы "Речь" можно подключиться к ресурсам служб искусственного интеллекта Azure или ресурсам службы "Речь".
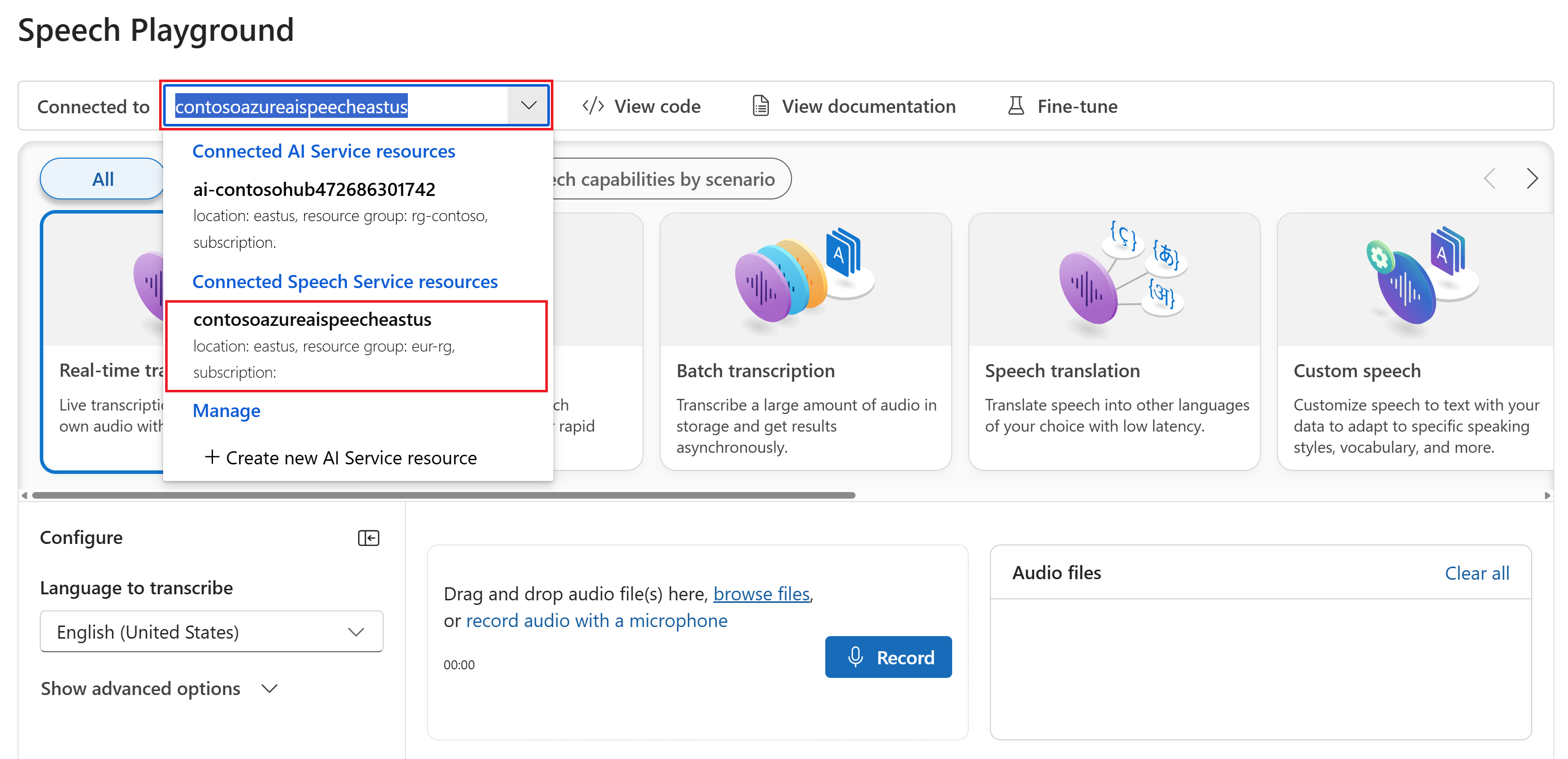
Выберите транскрибирование в режиме реального времени.
Выберите "Показать дополнительные параметры", чтобы настроить речь на текстовые параметры , например:
- Идентификация языка: используется для идентификации языков, которые говорят в аудио по сравнению со списком поддерживаемых языков. Дополнительные сведения о параметрах идентификации языка, таких как при запуске и непрерывном распознавании, см. в разделе "Идентификация языка".
- Диаризация говорящего: используется для идентификации и разделения динамиков в аудио. Диаризация различает различных докладчиков, участвующих в беседе. Служба "Речь" предоставляет сведения о том, какой докладчик говорил определенную часть транскрибированного речи. Дополнительные сведения о диаризации динамиков см. в кратком руководстве по распознаванию речи в режиме реального времени в тексте с кратким руководством по диаризации говорящего.
- Настраиваемая конечная точка: используйте развернутую модель из пользовательской речи для повышения точности распознавания. Чтобы использовать базовую модель Майкрософт, оставьте этот параметр равным None. Дополнительные сведения о пользовательской речи см. в разделе "Настраиваемая речь".
- Формат выходных данных: выбор между простыми и подробными форматами выходных данных. Простые выходные данные включают формат отображения и метки времени. Подробные выходные данные включают дополнительные форматы (например, отображение, лексический, ITN и маскированный ITN), метки времени и N-лучшие списки.
- Список фраз: повышение точности транскрибирования путем предоставления списка известных фраз, таких как имена людей или определенных расположений. Используйте запятые или запятые, чтобы разделить каждое значение в списке фраз. Дополнительные сведения о списках фраз см. в списках фраз.
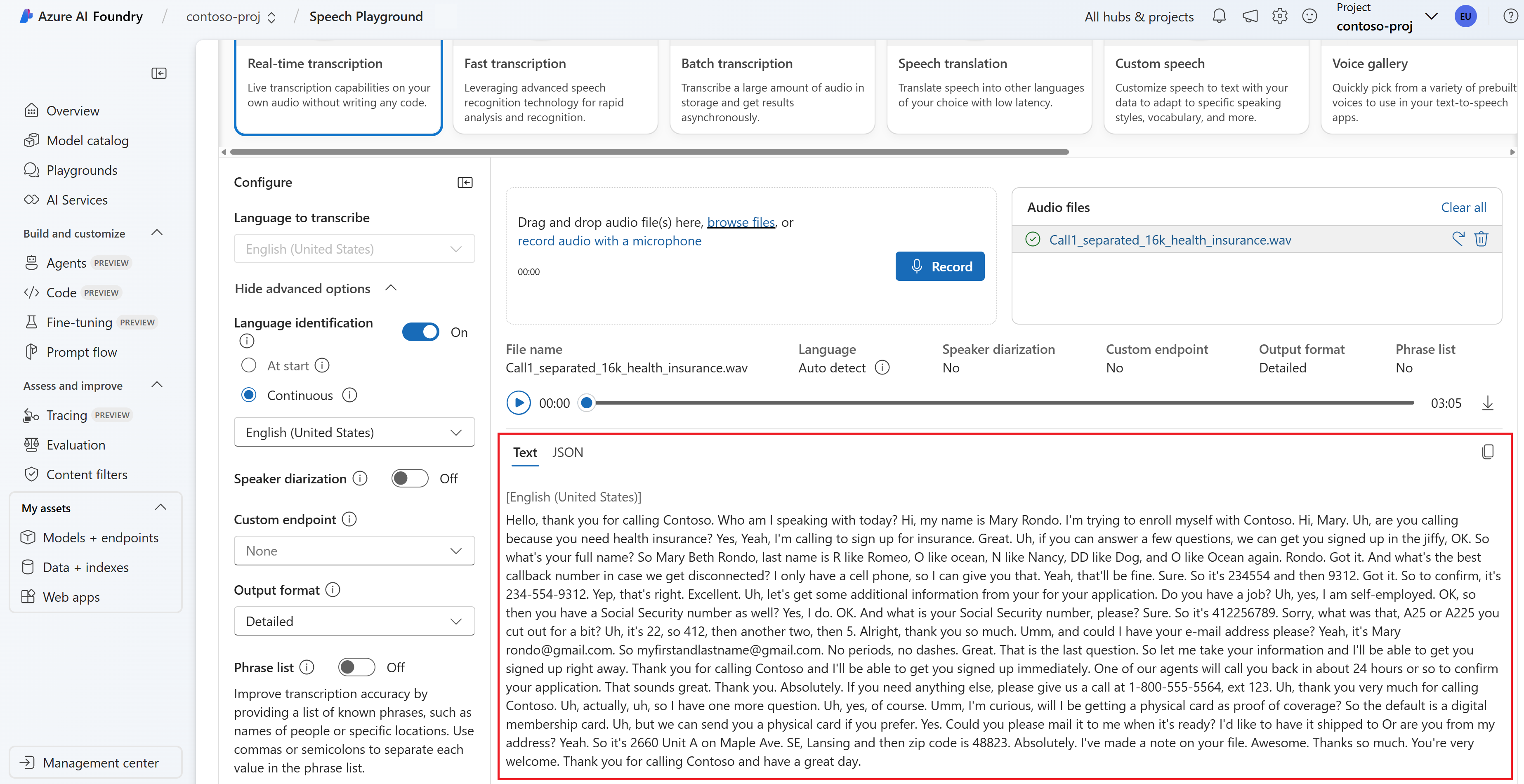
Выберите звуковой файл для отправки или записи звука в режиме реального времени. В этом примере мы используем файл, доступный
Call1_separated_16k_health_insurance.wavв репозитории пакета SDK службы "Речь" на GitHub. Вы можете скачать файл или использовать собственный звуковой файл.
Транскрибирование в режиме реального времени можно просмотреть в нижней части страницы.
Вы можете выбрать вкладку JSON, чтобы просмотреть выходные данные JSON транскрибирования. Свойства включают
Offset,DurationLexicalRecognitionStatusDisplayиITNмногое другое.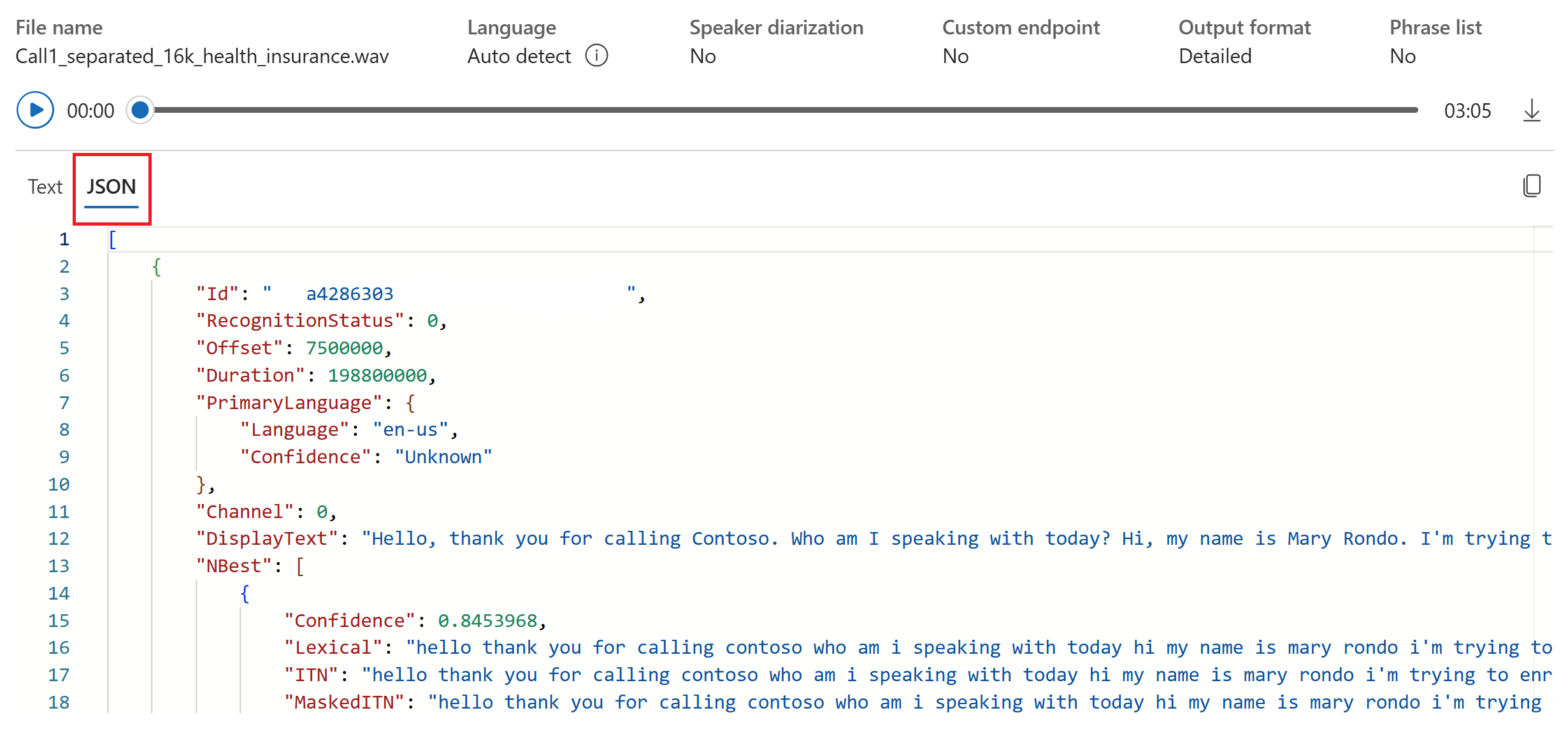





Справочные примеры пакета документации | (NuGet) | Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Пакет SDK для службы "Речь" доступен в виде пакета NuGet и реализует .NET Standard 2.0. Вы установите пакет SDK службы "Речь" далее в этом руководстве. Дополнительные сведения см. в разделе "Установка пакета SDK службы "Речь".
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Совет
Попробуйте использовать набор средств службы "Речь Azure AI", чтобы легко создавать и запускать примеры в Visual Studio Code.
Выполните следующие действия, чтобы создать консольное приложение и установить пакет SDK службы "Речь".
Откройте окно командной строки в папке, в которой требуется создать проект. Выполните эту команду, чтобы создать консольное приложение с помощью .NET CLI.
dotnet new consoleЭта команда создает файл Program.cs в каталоге проекта.
Установите пакет SDK для службы "Речь" в новом проекте с помощью CLI .NET.
dotnet add package Microsoft.CognitiveServices.SpeechЗамените содержимое файла Program.cs кодом, приведенным ниже.
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, которые могут быть разговоры, см. в разделе "Идентификация языка".Запустите новое консольное приложение, чтобы начать распознавание речи с микрофона:
dotnet runВнимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.При появлении запроса начните говорить в микрофон. То, что вы говорите, должно отображаться как текст:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Замечания
Ниже приведены некоторые другие рекомендации.
В этом примере операция
RecognizeOnceAsyncиспользуется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.Чтобы распознать речь из аудиофайла, используйте
FromWavFileInputвместоFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Для сжатых звуковых файлов, таких как MP4, установите GStreamer и используйте
PullAudioInputStreamилиPushAudioInputStream. Дополнительные сведения см. в разделе Как использовать сжатые входные аудиофайлы.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочные примеры пакета документации | (NuGet) | Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Пакет SDK для службы "Речь" доступен в виде пакета NuGet и реализует .NET Standard 2.0. Вы установите пакет SDK службы "Речь" далее в этом руководстве. Дополнительные сведения см. в разделе "Установка пакета SDK службы "Речь".
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Совет
Попробуйте использовать набор средств службы "Речь Azure AI", чтобы легко создавать и запускать примеры в Visual Studio Code.
Выполните следующие действия, чтобы создать консольное приложение и установить пакет SDK службы "Речь".
Создайте проект консоли C++ в Visual Studio Community с именем
SpeechRecognition.Выберите инструменты>Nuget диспетчер пакетов> диспетчер пакетов консоли. В консоли диспетчер пакетов выполните следующую команду:
Install-Package Microsoft.CognitiveServices.SpeechЗамените все содержимое
SpeechRecognition.cppследующим кодом:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, которые могут быть разговоры, см. в разделе "Идентификация языка".Создайте и запустите новое консольное приложение, чтобы начать распознавание речи с микрофона.
Внимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.При появлении запроса начните говорить в микрофон. То, что вы говорите, должно отображаться как текст:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Замечания
Ниже приведены некоторые другие рекомендации.
В этом примере операция
RecognizeOnceAsyncиспользуется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.Чтобы распознать речь из аудиофайла, используйте
FromWavFileInputвместоFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Для сжатых звуковых файлов, таких как MP4, установите GStreamer и используйте
PullAudioInputStreamилиPushAudioInputStream. Дополнительные сведения см. в разделе Как использовать сжатые входные аудиофайлы.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочные примеры пакета документации | (Go) | Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Установите пакет SDK службы "Речь" для Go. Требования и инструкции см. в разделе "Установка пакета SDK службы "Речь".
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Выполните следующие действия, чтобы создать модуль GO.
Откройте окно командной строки в папке, в которой требуется создать проект. Создайте файл с именем speech-recognition.go.
Скопируйте следующий код в speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Выполните приведенные ниже команды, чтобы создать файл go.mod со ссылкой на компоненты, размещенные в GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goВнимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.Выполните сборку и запуск кода:
go build go run speech-recognition
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочная документация | по Дополнительным примерам на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Чтобы настроить среду, установите пакет SDK службы "Речь". Пример, приведенный в этом кратком руководстве, работает со средой выполнения Java.
Установите Apache Maven. Затем выполните команду
mvn -v, чтобы подтвердить успешную установку.Создайте файл
pom.xmlв корне проекта и скопируйте в него следующий код:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Установите пакет SDK службы "Речь" и зависимости.
mvn clean dependency:copy-dependencies
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Выполните следующие действия, чтобы создать консольное приложение для распознавания речи.
Создайте файл с именем SpeechRecognition.java в том же корневом каталоге проекта.
Скопируйте следующий код в SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, которые могут быть разговоры, см. в разделе "Идентификация языка".Запустите новое консольное приложение, чтобы начать распознавание речи с микрофона:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionВнимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.При появлении запроса начните говорить в микрофон. То, что вы говорите, должно отображаться как текст:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Замечания
Ниже приведены некоторые другие рекомендации.
В этом примере операция
RecognizeOnceAsyncиспользуется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.Чтобы распознать речь из аудиофайла, используйте
fromWavFileInputвместоfromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Для сжатых звуковых файлов, таких как MP4, установите GStreamer и используйте
PullAudioInputStreamилиPushAudioInputStream. Дополнительные сведения см. в разделе Как использовать сжатые входные аудиофайлы.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочные примеры пакета документации | (npm) | Дополнительные примеры в исходном коде библиотеки GitHub |
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Вам также потребуется .wav звуковой файл на локальном компьютере. Вы можете использовать собственный файл .wav (до 30 секунд) или скачать https://crbn.us/whatstheweatherlike.wav пример файла.
Настройка среды
Чтобы настроить среду, установите пакет SDK службы "Речь" для JavaScript. Выполните следующую команду: npm install microsoft-cognitiveservices-speech-sdk. Инструкции по установке см. в разделе "Установка пакета SDK службы "Речь".
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
по распознаванию речи из файла
Совет
Попробуйте использовать набор средств службы "Речь Azure AI", чтобы легко создавать и запускать примеры в Visual Studio Code.
Выполните следующие действия, чтобы создать консольное приложение Node.js для распознавания речи.
Откройте окно командной строки, в котором требуется новый проект, и создайте файл с именем SpeechRecognition.js.
Установите пакет SDK службы "Речь" для JavaScript:
npm install microsoft-cognitiveservices-speech-sdkСкопируйте следующий код в SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();В SpeechRecognition.js замените YourAudioFile.wav собственным файлом .wav . В этом примере распознается только речь из файла .wav . Дополнительные сведения о других форматах звука см. в разделе Как использовать сжатые входные аудиофайлы. В этом примере поддерживается до 30 секунд звука.
Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, которые могут быть разговоры, см. в разделе "Идентификация языка".Запустите новое консольное приложение, чтобы начать распознавание речи из файла:
node.exe SpeechRecognition.jsВнимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.Речь из аудиофайла должна быть выведена в виде текста:
RECOGNIZED: Text=I'm excited to try speech to text.
Замечания
В этом примере операция recognizeOnceAsync используется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.
Примечание.
Распознавание речи с микрофона не поддерживается в Node.js. Эта функция поддерживается только в среде JavaScript на основе браузера. Дополнительные сведения см. в примере React и реализации речи с микрофона на GitHub.
В примере React показаны конструктивные шаблоны для обмена и управления маркерами проверки подлинности, В нем также показана запись звука с микрофона или файла для преобразования речи в текст.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочные примеры пакета документации | (PyPi) | Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Пакет SDK для Python доступен в виде модуля индекса пакетов Python (PyPI). Пакет SDK для службы "Речь" (Python) совместим с Windows, Linux и macOS.
- Для Windows установите microsoft Распространяемый компонент Visual C++ для Visual Studio 2015, 2017, 2019 и 2022 для своей платформы. При первой установке этого пакета может потребоваться перезагрузка.
- В Linux необходимо использовать целевую архитектуру x64.
Установите версию Python с версии 3.7 или более поздней версии. Дополнительные сведения см. в разделе "Установка пакета SDK службы "Речь".
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Совет
Попробуйте использовать набор средств службы "Речь Azure AI", чтобы легко создавать и запускать примеры в Visual Studio Code.
Выполните следующие действия, чтобы создать консольное приложение.
Откройте окно командной строки в папке, в которой требуется создать проект. Создайте файл с именем speech_recognition.py.
Выполните следующую команду для установки пакета SDK для службы "Речь".
pip install azure-cognitiveservices-speechСкопируйте следующий код в speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, на которых могут говорить, см. в разделе Определение языка.Запустите новое консольное приложение, чтобы начать распознавание речи с микрофона:
python speech_recognition.pyВнимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.При появлении запроса начните говорить в микрофон. То, что вы говорите, должно отображаться как текст:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Замечания
Ниже приведены некоторые другие рекомендации.
В этом примере операция
recognize_once_asyncиспользуется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.Чтобы распознать речь из аудиофайла, используйте
filenameвместоuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Для сжатых звуковых файлов, таких как MP4, установите GStreamer и используйте
PullAudioInputStreamилиPushAudioInputStream. Дополнительные сведения см. в разделе Как использовать сжатые входные аудиофайлы.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Справочный пакет документации | (скачивание) | Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Пакет SDK службы "Речь" для Swift сейчас доступен в виде пакета платформы. Платформа поддерживает как Objective-C, так и SWIFT как в iOS, так и в macOS.
Пакет SDK службы "Речь" можно использовать в проектах Xcode в качестве КакаоПода или скачать напрямую и связать вручную. В этом руководстве используется диспетчер зависимостей CocoaPods. Установите диспетчер зависимостей CocoaPods, следуя его инструкциям по установке.
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
Распознавание речи с микрофона
Выполните следующие действия для распознавания речи в приложении macOS.
Клонируйте репозиторий Azure-Samples/cognitive-services-speech-sdk, чтобы получить пример проекта Распознавание речи с микрофона в Swift в macOS. Репозиторий также содержит примеры для iOS.
Перейдите в каталог скачанного примера приложения (
helloworld) в терминале.Выполните команду
pod install. Эта команда создает рабочуюhelloworld.xcworkspaceобласть Xcode, содержащую пример приложения и пакет SDK службы "Речь" в качестве зависимости.Откройте рабочую область
helloworld.xcworkspaceв Xcode.Откройте файл с именем AppDelegate.swift и найдите
applicationDidFinishLaunchingметоды,recognizeFromMicкак показано здесь.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }В AppDelegate.m используйте переменные среды, заданные ранее для ключа ресурса службы "Речь" и региона.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Чтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию . Дополнительные сведения о том, как определить один из нескольких языков, которые могут быть разговоры, см. в разделе "Идентификация языка".Чтобы сделать выходные данные отладки видимыми, выберите "Просмотреть>консоль активации области>отладки".
Создайте и запустите пример кода, выбрав "Запуск продукта>" в меню или нажав кнопку "Воспроизвести".
Внимание
Убедитесь, что заданы
SPEECH_KEYпеременные среды иSPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.
После нажатия кнопки в приложении и проговорив несколько слов, вы увидите текст, который вы говорили на нижней части экрана. При первом запуске приложения вам будет предложено предоставить приложению доступ к микрофону компьютера.
Замечания
В этом примере операция recognizeOnce используется для транскрибирования речевых фрагментов продолжительностью до 30 секунд или до обнаружения тишины. Сведения о непрерывном распознавании для более продолжительных аудиофайлов, в том числе бесед на нескольких языках, см. в разделе Распознавание речи.
Objective-C
Пакет SDK службы "Речь" для клиентских библиотек Objective-C и справочная документация с пакетом SDK службы "Речь" для Swift. Примеры кода Objective-C см . в примере проекта Распознавания речи с микрофона в Objective-C в macOS в GitHub.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
Преобразование речи в текст REST API ссылки на | речь на текстовый REST API для краткой справки по звуковой ссылке | на Дополнительные примеры на GitHub
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Вам также потребуется .wav звуковой файл на локальном компьютере. Вы можете использовать собственный .wav файл до 60 секунд или скачать https://crbn.us/whatstheweatherlike.wav пример файла.
Настройка переменных среды
Для доступа к службам ИИ Azure необходимо пройти проверку подлинности приложения. В этой статье показано, как использовать переменные среды для хранения учетных данных. Затем вы можете получить доступ к переменным среды из кода для проверки подлинности приложения. Для рабочей среды используйте более безопасный способ хранения и доступа к учетным данным.
Внимание
Мы рекомендуем использовать проверку подлинности Идентификатора Microsoft Entra с управляемыми удостоверениями для ресурсов Azure, чтобы избежать хранения учетных данных с приложениями, работающими в облаке.
Если вы используете ключ API, сохраните его в другом месте, например в Azure Key Vault. Не включайте ключ API непосредственно в код и никогда не публикуйте его.
Дополнительные сведения о безопасности служб ИИ см. в статье "Проверка подлинности запросов к службам ИИ Azure".
Чтобы задать переменные среды для ключа ресурса службы "Речь" и региона, откройте окно консоли и следуйте инструкциям для вашей операционной системы и среды разработки.
- Чтобы задать
SPEECH_KEYпеременную среды, замените ключ одним из ключей ресурса. - Чтобы задать
SPEECH_REGIONпеременную среды, замените регион одним из регионов для ресурса.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Примечание.
Если вам нужно получить доступ только к переменным среды в текущей консоли, можно задать переменную set среды вместо setx.
После добавления переменных среды может потребоваться перезапустить все программы, которые должны считывать переменные среды, включая окно консоли. Например, если вы используете Visual Studio в качестве редактора, перезапустите Visual Studio перед запуском примера.
по распознаванию речи из файла
Откройте окно консоли и выполните следующую команду cURL. Замените YourAudioFile.wav путем и именем звукового файла.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Внимание
Убедитесь, что заданы SPEECH_KEY переменные среды и SPEECH_REGIONсреды. Если эти переменные не заданы, образец завершается ошибкой с сообщением об ошибке.
Вы должны получить ответ, аналогичный представленному здесь.
DisplayText — это текст, распознанный из аудиофайла. Команда распознает до 60 секунд звука и преобразует его в текст.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Дополнительные сведения см. в статье "Речь в текстовом REST API" для короткого звука.
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.
В этом кратком руководстве вы создадите и запустите приложение для распознавания и транскрибирования речи в текст в режиме реального времени.
Чтобы вместо этого асинхронно транскрибировать звуковые файлы, см. раздел "Что такое пакетная транскрибирование". Если вы не уверены, какая речь в текстовом решении подходит для вас, см. статью "Что такое речь в тексте?"
Необходимые компоненты
- Подписка Azure. Вы можете создать бесплатную учетную запись.
- Создайте ресурс службы "Речь" в портал Azure.
- Получение ключа ресурса службы "Речь" и региона. После развертывания ресурса службы "Речь" выберите Перейти к ресурсу для просмотра ключей и управления ими.
Настройка среды
Выполните следующие действия и ознакомьтесь с кратким руководством по интерфейсу командной строки службы "Речь" для других требований для платформы.
Выполните следующую команду .NET CLI, чтобы установить интерфейс командной строки службы "Речь".
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIВыполните следующие команды, чтобы настроить ключ ресурса службы "Речь" и регион. Замените ключом ресурса "Речь" и замените
SUBSCRIPTION-KEYREGIONрегионом ресурсов службы "Речь".spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Распознавание речи с микрофона
Выполните следующую команду, чтобы начать распознавание речи с микрофона:
spx recognize --microphone --source en-USНачните говорить в микрофон, и вы увидите расшифровки слов в виде текста, появляющиеся в реальном времени. Интерфейс командной строки службы "Речь" останавливается после периода молчания, 30 секунд или при нажатии клавиш CTRL+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Замечания
Ниже приведены некоторые другие рекомендации.
Чтобы распознать речь из аудиофайла, используйте
--fileвместо--microphone. Для сжатых звуковых файлов, таких как MP4, установите GStreamer и используйте--format. Дополнительные сведения см. в разделе Как использовать сжатые входные аудиофайлы.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyЧтобы повысить точность распознавания конкретных слов или речевых фрагментов, используйте список фраз. Вы включаете список фраз в строку или текстовый файл вместе с командой
recognize:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtЧтобы изменить язык распознавания речи, замените
en-USна другой поддерживаемый язык. Например, используетсяes-ESдля испанского языка (Испания). Если язык не указан, значениеen-USпо умолчанию .spx recognize --microphone --source es-ESДля непрерывного распознавания звука дольше 30 секунд добавьте
--continuous:spx recognize --microphone --source es-ES --continuousВыполните следующую команду, чтобы узнать больше о параметрах распознавания речи, таких как входные и выходные данные файлов:
spx help recognize
Очистка ресурсов
Для удаления созданного ресурса службы "Речь" можно использовать портал Azure или интерфейс командной строки (CLI) Azure.