Руководство. Использование персонализатора в записной книжке Azure
Внимание
Начиная с 20 сентября 2023 г. вы не сможете создавать новые ресурсы Персонализатора. Служба Персонализатора отменяется 1 октября 2026 года.
В этом руководстве описано, как в Azure Notebook выполняется цикл Персонализатора, на примере которого мы рассмотрим соответствующий полный жизненный цикл.
Этот цикл предлагает виды кофе, которые могут заказывать клиенты. Пользователи и их предпочтения хранятся в наборе данных о пользователях. Сведения о кофе хранятся в наборе данных о кофе.
Пользователи и кофе
Записная книжка, моделирующая взаимодействие пользователя с веб-сайтом, случайным образом выбирает из набора данных пользователя, время суток и тип погоды. Сводка сведений о пользователе.
| Клиенты — компоненты контекста | Время суток | Тип погоды |
|---|---|---|
| Алиса Борис Катя Dave |
Утро День Вечер |
Солнечно Дождь Снег |
Чтобы Персонализатор постепенно запоминал сведения, цикл system также использует сведения о выборе кофе для каждого человека.
| Кофе — компоненты действия | Типы сущностей temperature | Источники происхождения | Типы обжарки | Органический |
|---|---|---|---|---|
| Капучино | высокая | Кения | Темный | Органический |
| Капельный | низкая | Бразилия | Светлый | Органический |
| Мокко со льдом | низкая | Эфиопия | Светлый | Не органический |
| Латте | высокая | Бразилия | Темный | Не органический |
Задачей цикла Персонализатора является поиск наилучшего соответствия между пользователями и видом кофе в максимальном количестве случаев.
Исходный код для этого краткого руководства размещен в репозитории GitHub с примерами для Персонализатора.
Принцип работы моделирования
Вначале предложения Персонализатора будут успешными только в 20–30 % случаев. Успешный результат обозначается вознаграждением, отправляемым в API вознаграждения Персонализатора с оценкой 1. Система улучшается после некоторых вызовов ранжирования и вознаграждения.
Выполните автономную оценку после первых запросов. Это позволит Персонализатору изучить данные и создать оптимальную политику обучения. Примените новую политику обучения и снова запустите записную книжку с 20 % предыдущего числа запросов. С новой политикой обучения цикл будет работать лучше.
Оценка и вознаграждение вызовов
Для каждого из нескольких тысяч вызовов к службе Персонализатора Azure Notebook отправляет запрос оценки (Rank) в REST API:
- Уникальный идентификатор для события "оценка — запрос".
- Компоненты контекста — случайное сочетание пользователя, погоды и времени суток, который моделирует поведение пользователя на веб-сайте или мобильном устройстве
- Действия с компонентами — все данные о кофе, на основе которых Персонализатор создает предложения
Система получает запрос, а затем сравнивает прогноз с известным вариантом пользователя в то же время дня и в ту же погоду. Если известный вариант совпадает с предложенным вариантом, Персонализатору возвращается параметр Reward со значением 1. В противном случае возвращается значение 0.
Примечание.
Для этой имитации используется очень простой алгоритм вознаграждения. В реальном сценарии для определения оценки вознаграждения в этом алгоритме нужно применять для оценки бизнес-логику, возможно, с весовыми коэффициентами для разных аспектов взаимодействия с клиентом.
Необходимые компоненты
- Учетная запись Azure Notebook.
- Ресурс Персонализатора ИИ Azure.
- Если вы уже использовали ресурс Персонализатора, не забудьте очистить данные для этого ресурса на портале Azure.
- Отправьте все файлы этого примера в проект Azure Notebook.
Описание файлов.
- Personalizer.ipynb содержит записную книжку Jupyter для этого руководства.
- Набор данных о пользователях хранится в виде объекта JSON.
- Набор данных о кофе хранится в виде объекта JSON.
- Пример запроса в формате JSON описывает ожидаемый формат запроса POST к API оценки.
Настройка ресурса Персонализатора
На портале Azure настройте ресурс Персонализатора, указав частоту обновления модели в 15 секунд и время ожидания вознаграждения в 10 минут. Эти значения находятся на странице Настройка.
| Параметр | Значение |
|---|---|
| Частота обновления модели | 15 секунд |
| Время ожидания вознаграждения | 10 минут |
Мы используем небольшие значения длительности, чтобы быстро отображать изменения при работе с руководством. Такие значения не следует использовать в рабочем сценарии, не проверив предварительно, подходят ли они для конкретных задач цикла Персонализатора.
Настройка Azure Notebook
- Укажите для ядра значение
Python 3.6. - Откройте файл
Personalizer.ipynb.
Выполнение ячеек записной книжки
Запустите каждую из исполняемых ячеек и дождитесь завершения работы. Когда работа ячейки завершается, в скобках рядом с ней вместо * отображается числовое значение. В следующих разделах описаны программы каждой из ячеек и их ожидаемые выходные данные.
Включение модулей Python
Включение обязательных модулей Python. Эта ячейка не имеет выходных данных.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Настройка ключа и имени ресурса Персонализатора
На портале Azure найдите значения ключа и конечной точки на странице Быстрое начало для ресурса персонализации. Измените значение <your-resource-name> на реальное имя ресурса Персонализатора. Измените значение <your-resource-key> на реальное значение ключа Персонализатора.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Вывод текущей даты и времени
Эта функция используется для фиксации времен начала, завершения итерационной функции и каждой итерации.
Эти ячейки не имеют выходных данных. Эта функция выводит текущую дату и время при вызове.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Получение времени последнего обновления модели
Вызываемая функция get_last_updated выводит дату и время последнего изменения модели.
Эти ячейки не имеют выходных данных. Эта функция выводит дату и время последнего обучения модели.
Функция использует метод GET REST API для получения свойств модели.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Получение конфигурации политики и службы
Эти два вызова REST позволяют проверить состояние службы.
Эти ячейки не имеют выходных данных. Эта функция выводит значения службы при вызове.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Создание URL-адресов и чтение файлов данных JSON
Эта ячейка:
- создает URL-адреса, которые используются в вызовах REST;
- задает заголовок безопасности с помощью ключа ресурса Персонализатора;
- задает случайное начальное значение для идентификатора события оценки (Rank);
- считывает данные из файлов JSON;
- вызывает метод
get_last_updated(из выходных данных в примере удалена политика обучения); - вызывает метод
get_service_settings.
Ячейка выводит данные, полученные при вызове функций get_last_updated и get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Убедитесь, что для выходных данных rewardWaitTime задано значение 10 минут, а для modelExportFrequency — 15 секунд.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Устранение неполадок при первом вызове REST
Описанная выше ячейка создает первый запрос к Персонализатору. Убедитесь, что в выходных данных код состояния для вызова REST имеет значение <Response [200]>. Если вы получаете сообщение об ошибке (например, 404), но уверены в правильности значений ключа и имени ресурса, перезагрузите записную книжку.
Убедитесь, что количество значений для видов кофе и пользователей равно 4. При возникновении ошибки убедитесь, что вы загрузили все 3 файла JSON.
Настройка схемы метрик на портале Azure
Далее в этом руководстве описан длительный процесс обработки 10 000 запросов, который отображается в браузере с обновляющимся значением в текстовом поле. Возможно, эти данные проще изучать на диаграмме или в виде итоговой суммы, которые будут доступны по завершении длительного процесса. Чтобы просмотреть эти сведения, используйте предоставляемые с ресурсом метрики. Теперь, после выполнения запроса к службе, вы можете создать диаграмму и периодически обновлять ее, пока выполняется длительный процесс.
Выберите ресурс "Персонализатор" на портале Azure.
В области навигации по ресурсам выберите Метрики под разделом "Мониторинг".
В диаграмме щелкните Добавить метрику.
Здесь уже заполнены значения ресурса и пространства имен для метрики. Вам осталось лишь выбрать метрику successful calls (успешные вызовы) и агрегирование по функции sum (сумма).
Укажите для фильтра времени последние 4 часа.
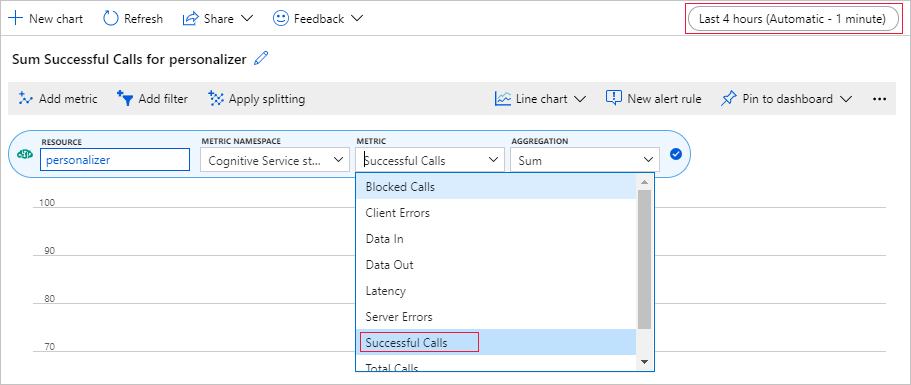
Теперь в диаграмме вы увидите 3 успешных вызова.
Создание уникального идентификатора события
Эта функция создает глобально уникальный идентификатор для каждого вызова оценки. Этот идентификатор используется для идентификации сведений о вызове оценки и вознаграждения. Это значение можно получить из бизнес-процесса. Например, это может быть идентификатор веб-представления или транзакции.
Эта ячейка не имеет выходных данных. Эта функция выводит уникальный идентификатор при вызове.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Получение случайного набора из пользователя, погоды и времени суток
Эта функция выбирает уникальное сочетание пользователя, погоды и времени суток, а затем добавляет эти элементы в объект JSON для отправки в запрос оценки.
Эта ячейка не имеет выходных данных. При вызове эта функция возвращает выбранные случайным образом значения имени пользователя, погоды и времени суток.
Список содержит 4 пользователя и их предпочтения. Для краткости мы приводим его не полностью.
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Добавление данных о кофе
Эта функция добавляет весь список вариантов кофе в объект JSON для отправки в запрос оценки.
Эта ячейка не имеет выходных данных. Функция изменяет значение rankjsonobj при вызове.
Ниже приведен пример характеристик кофе:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Сравнение прогнозов с известными предпочтениями пользователей
Эта функция вызывается для каждой итерации после вызова API оценки.
Она сравнивает известные предпочтения пользователя по выбору кофе в зависимости от погоды и времени суток, с предложением Персонализатора для того же пользователя по тем же параметрам. Если предложение совпадает с выбором пользователя, возвращается значение оценки 1, в противном случае — значение 0. Эта ячейка не имеет выходных данных. Эта функция выводит значение оценки при вызове.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Циклический перебор вызовов для оценки и вознаграждений
Следующая ячейка содержит основной рабочий процесс записной книжки, который случайным образом получает пользователя и список кофе, а также отправляет эти данные в API оценки. Сравнение прогноза с известными предпочтениями пользователя с последующей отправкой вознаграждений обратно в службу Персонализатора.
Этот цикл выполняется соответствующее количество раз: num_requests. При создании модели Персонализатор выполняет несколько тысяч вызовов для получения оценки и вознаграждения.
Ниже приведен пример данных в формате JSON, которые отправляются в API оценки. Список видов кофе для краткости приводится не полностью. Полный код JSON с данными о кофе вы можете найти в coffee.json.
Код JSON, который отправляется в API оценки:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Ответ JSON, который возвращается из API оценки:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Наконец, для каждого цикла предоставляется случайный набор пользователя, погоды и времени суток, а также вычисленное значение вознаграждения. Значение 1 обозначает, что ресурс Персонализатора правильно выбрал вид кофе для предоставленного сочетания пользователя, погоды и времени суток.
1 Alice Rainy Morning Latte 1
Эта функция использует следующее:
- Оценка — запрос POST к REST API для получения оценки.
- Вознаграждение — запрос POST к REST API для передачи вознаграждения.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Выполнение 10 000 итераций
Выполните цикл Персонализатора 10 000 раз. Это длительный процесс. Не закрывайте браузер, пока в нем выполняется записная книжка. Время от времени обновляйте диаграмму метрик на портале Azure, чтобы отслеживать количество вызовов службы. Когда счетчик дойдет до 20 000 вызовов (вызов оценки и вызов вознаграждения для каждой итерации цикла), процесс завершится.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Откройте диаграмму результатов, чтобы оценить улучшения
Диаграмма создается на основе count и rewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Диаграммы выполнений для 10 000 запросов оценки
Выполните функцию createChart.
createChart(count,rewards)
Анализ данных на диаграмме
Эта диаграмма демонстрирует успешность модели для текущей политики обучения по умолчанию.
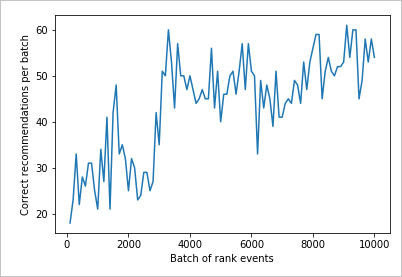
В идеале к моменту завершения теста цикл должен демонстрировать близкую к 100 % долю успешных прогнозов, без учета исследований. Значение исследования по умолчанию составляет 20 %.
100-20=80
Это значение исследования можно найти на портале Azure на странице Настройка для ресурса Персонализатора.
Чтобы определить более эффективную политику обучения на основе данных, предоставленных в API оценки, выполните на портале автономную оценку для цикла Персонализатора.
Выполнение автономной оценки
На портале Azure откройте страницу Оценки для ресурса Персонализатора.
Щелкните Создать оценку.
Введите необходимые данные: имя оценки и диапазон дат для оценки цикла. Диапазон дат должен включать только дни, для которых вы хотите получить оценку.
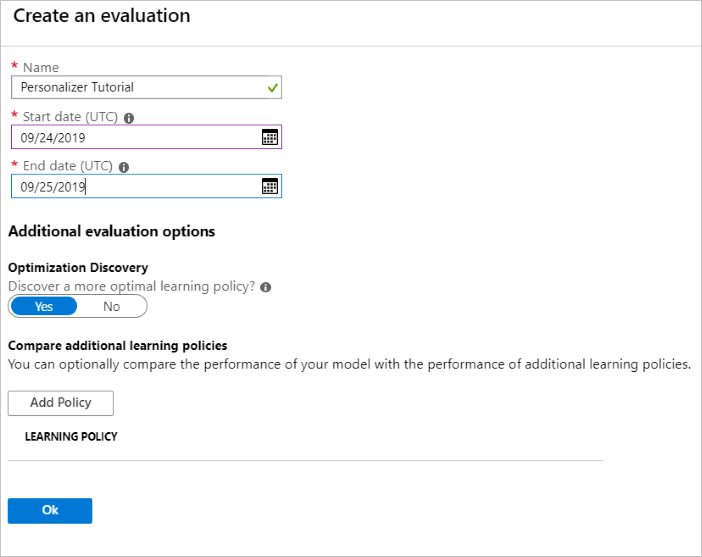
Цель выполнения этой автономной оценки заключается в определении более эффективной политики обучения по тем компонентам и действиям, которые используются в этом цикле. Чтобы найти более эффективную политику обучения, не забудьте включить обнаружение оптимизации.
Выберите ОК, чтобы начать процесс оценки.
На странице Оценки отобразится новая оценка и ее текущее состояние. В зависимости от объема данных процесс оценки может занять некоторое время. Вы можете вернуться на эту страницу через несколько минут, чтобы увидеть результаты.
Когда процесс завершится, выберите эту оценку и щелкните Сравнение разных политик обучения. Это действие отображает доступные политики обучения и их эффективность для предоставленных данных.
Выберите в таблице наиболее эффективную политику обучения и щелкните Применить. Это действие применяет к модели лучшую политику обучения и выполняет переобучение.
Изменение интервала обновления модели на 5 минут
- На портале Azure выберите страницу Настройка для ресурса Персонализатора.
- Измените значения частоты обновления модели и времени ожидания вознаграждения на 5 минут и щелкните Сохранить.
Изучите дополнительные сведения о времени ожидания вознаграждения и частоте обновления модели.
#Verify new learning policy and times
get_service_settings()
Убедитесь, что в выходных данных параметры rewardWaitTime и modelExportFrequency имеют значение 5 минут.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Проверка новой политики обучения
Вернитесь к файлу Записных книжек Azure и повторите тот же цикл, но на этот раз по 2000 итераций. Время от времени обновляйте диаграмму метрик на портале Azure, чтобы отслеживать количество вызовов службы. Когда счетчик отобразит приблизительно 4000 вызовов (вызов оценки и вызов вознаграждения для каждой итерации цикла), процесс завершится.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
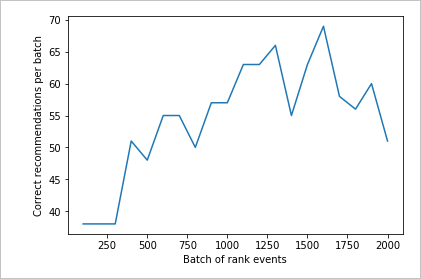
Диаграмма выполнений для 2000 запросов оценки
Выполните функцию createChart.
createChart(count2,rewards2)
Анализ второй диаграммы
Вторая диаграмма демонстрирует заметное увеличение совпадений между прогнозами оценки и предпочтениями пользователей.
Очистка ресурсов
Если вы не собираетесь продолжать работу с этой серией руководств, очистите следующие ресурсы:
- Удалите проект Azure Notebook.
- Удалите ресурс Персонализатора.
Следующие шаги
Записная книжка Jupyter и файлы данных, которые используются в этом примере, можно получить в репозитории GitHub для Персонализатора.