Производительность и задержка
В этой статье описано, как задержка и пропускная способность работают с Azure OpenAI и как оптимизировать среду для повышения производительности.
Общие сведения о пропускной способности и задержке
Существует два ключевых понятия, о которых следует думать при изменении размера приложения: (1) Пропускная способность уровня системы, измеряемая в маркерах в минуту (TPM) и (2) время отклика на вызов (также называется задержкой).
Пропускная способность уровня системы
Это проверяет общую емкость развертывания— сколько запросов в минуту и общих маркеров можно обрабатывать.
Для стандартного развертывания квота, назначенная развертыванию, частично определяет объем пропускной способности, которую можно достичь. Однако квота определяет только логику допуска для вызовов развертывания и не напрямую применяет пропускную способность. Из-за вариаций задержки каждого вызова возможно, вы не сможете достичь пропускной способности так же, как квота. Дополнительные сведения об управлении квотой.
В подготовленном развертывании набор емкости обработки модели выделяется конечной точке. Объем пропускной способности, которую можно достичь в конечной точке, является фактором фигуры рабочей нагрузки, включая объем входных маркеров, объем выходных данных, частоту вызовов и частоту сопоставления кэша. Количество одновременных вызовов и общих маркеров может отличаться в зависимости от этих значений.
Для всех типов развертывания понимание пропускной способности на уровне системы является ключевым компонентом оптимизации производительности. Важно учитывать пропускную способность уровня системы для данной модели, версии и сочетания рабочих нагрузок, так как пропускная способность зависит от этих факторов.
Оценка пропускной способности на уровне системы
Оценка доверенного платформенного модуля с помощью метрик Azure Monitor
Одним из подходов к оценке пропускной способности на уровне системы для данной рабочей нагрузки является использование данных об использовании исторических маркеров. Для рабочих нагрузок Azure OpenAI все исторические данные об использовании можно получить и визуализировать с помощью собственных возможностей мониторинга, предлагаемых в Azure OpenAI. Для оценки пропускной способности уровня системы для рабочих нагрузок Azure OpenAI требуются две метрики: (1) Обработанные маркеры запроса и (2) Созданные маркеры завершения.
При объединении метрики обработанных маркеров запроса (входной TPM) и созданных маркеров завершения (выходной TPM) предоставляют предполагаемое представление пропускной способности на уровне системы на основе фактического трафика рабочей нагрузки. Этот подход не учитывает преимущества кэширования запросов, поэтому это будет консервативная оценка пропускной способности системы. Эти метрики можно анализировать с помощью минимального, среднего и максимального агрегирования в течение 1 минутных окон в течение нескольких недель. Рекомендуется проанализировать эти данные в течение многонедельного горизонта времени, чтобы убедиться, что для оценки достаточно точек данных. На следующем снимке экрана показан пример метрики обработанных маркеров запроса, визуализированной в Azure Monitor, которая доступна непосредственно через портал Azure.
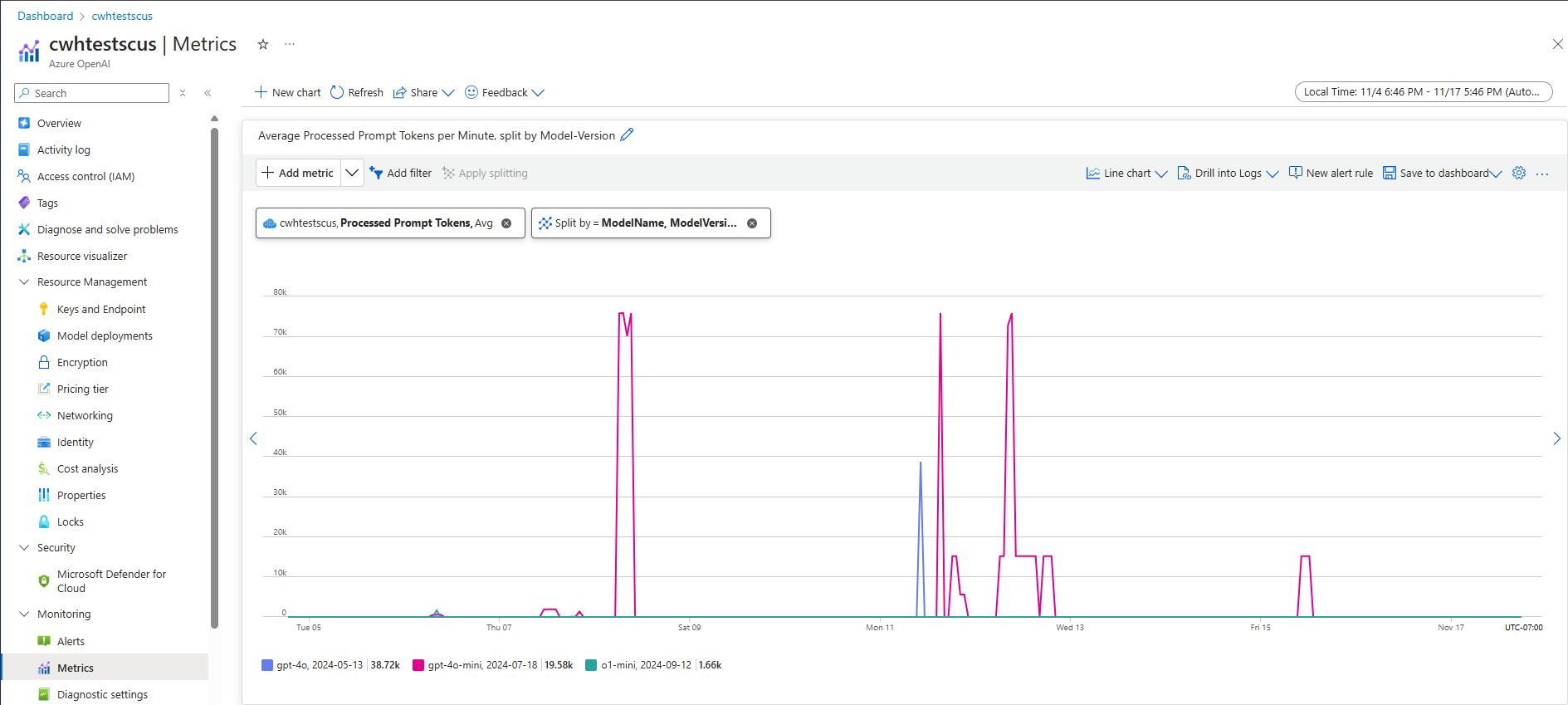
Оценка доверенного платформенного модуля из данных запроса
Второй подход к предполагаемой пропускной способности на уровне системы включает сбор сведений об использовании маркеров из данных запроса API. Этот метод обеспечивает более детализированный подход к пониманию фигуры рабочей нагрузки на запрос. Объединение сведений об использовании маркера запроса с томом запроса, измеряемым в минутах (RPM), обеспечивает оценку пропускной способности на уровне системы. Важно отметить, что любые предположения, сделанные для согласованности сведений об использовании маркеров в запросах и томе запроса, влияют на оценку пропускной способности системы. Выходные данные об использовании маркеров можно найти в ответе API для заданного запроса на завершение чата OpenAI Azure.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
Предполагая, что все запросы для данной рабочей нагрузки являются универсальными, маркеры запроса и маркеры завершения из данных ответа API могут быть умножены на предполагаемый rpm для определения входных и выходных TPM для данной рабочей нагрузки.
Использование оценки пропускной способности на уровне системы
После оценки пропускной способности уровня системы для данной рабочей нагрузки эти оценки можно использовать для размера развертываний уровня "Стандартный" и "Подготовленный". Для развертываний уровня "Стандартный" значения входных и выходных TPM можно объединить, чтобы оценить общее число назначенных доверенному платформенного модуля заданному развертыванию. Для подготовленных развертываний данные об использовании маркера запроса или значения входных и выходных TPM можно использовать для оценки количества ПТП, необходимых для поддержки определенной рабочей нагрузки с помощью калькулятора емкости развертывания.
Ниже приведены несколько примеров для мини-модели GPT-4o:
| Размер запроса (токены) | Размер поколения (токены) | Число запросов в минуту | Входной TPM | Выходной TPM | Всего доверенного платформенного модуля | Обязательные PTUs |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4 500 | 28,500 | 15 |
| 5,000 | 50 | 1,000 | 5 000 000 | 50,000 | 5,050,000 | 140 |
| 1,000 | 300 | 500 | 500,000 | 150 000 | 650,000 | 30 |
Число ПТП масштабируется примерно линейно с частотой вызовов, когда распределение рабочей нагрузки остается постоянным.
Задержка: время ответа на вызов
Определение высокой задержки в этом контексте — это время, необходимое для получения ответа от модели. Для запросов завершения и завершения чата задержка в значительной степени зависит от типа модели, количества маркеров в запросе и количества созданных маркеров. Как правило, каждый маркер запроса добавляет мало времени по сравнению с каждым добавочным маркером, созданным.
Оценка ожидаемой задержки для каждого вызова может быть сложной задачей с этими моделями. Задержка запроса на завершение может отличаться в зависимости от четырех основных факторов: (1) модель, (2) количество маркеров в запросе, (3) количество маркеров, созданных, и (4) общая нагрузка на развертывание и систему. Один и три часто являются основными участниками общего времени. Следующий раздел содержит дополнительные сведения об анатомии вызова крупной языковой модели вывода.
Повышение производительности
Существует несколько факторов, которые можно контролировать для улучшения задержки каждого вызова приложения.
выбор модели;
Задержка зависит от используемой модели. Для идентичного запроса ожидается, что разные модели имеют разные задержки для вызова завершения чата. Если для вашего варианта использования требуется наименьшая задержка моделей с самым быстрым временем отклика, мы рекомендуем последнюю модель GPT-4o mini.
Размер поколения и максимальные маркеры
При отправке запроса на завершение в конечную точку Azure OpenAI входной текст преобразуется в маркеры, которые затем отправляются в развернутую модель. Модель получает входные маркеры, а затем начинает создавать ответ. Это итеративный последовательный процесс, один маркер за раз. Другой способ думать об этом как цикл с n tokens = n iterations. Для большинства моделей создание ответа является самым медленным шагом процесса.
Во время запроса запрошенный размер поколения (параметр max_tokens) используется в качестве начальной оценки размера создания. Время вычислений для создания полного размера зарезервировано моделью по мере обработки запроса. После завершения создания оставшаяся квота освобождается. Способы уменьшения количества маркеров:
max_tokensЗадайте параметр для каждого вызова как можно меньше.- Включите последовательности остановки, чтобы предотвратить создание дополнительного содержимого.
- Создание меньшего количества ответов: параметры best_of и n могут значительно увеличить задержку, так как они создают несколько выходных данных. Для самого быстрого ответа не указывайте эти значения или не устанавливайте их значение 1.
В итоге сокращение числа маркеров, созданных на каждый запрос, уменьшает задержку каждого запроса.
Потоковая передача
Установка stream: true в запросе делает маркеры возврата службы сразу после их доступности, а не ожидая создания полной последовательности маркеров. Это не изменяет время получения всех маркеров, но сокращает время первого ответа. Такой подход обеспечивает лучший пользовательский интерфейс, так как конечные пользователи могут читать ответ по мере его создания.
Потоковая передача также ценна с большими вызовами, которые занимают много времени для обработки. Многие клиенты и промежуточные слои имеют время ожидания для отдельных вызовов. Вызовы длительного поколения могут быть отменены из-за времени ожидания на стороне клиента. Потоковая передача данных обратно обеспечивает получение добавочных данных.
Примеры использования потоковой передачи:
Боты чата и диалоговые интерфейсы.
Потоковая передача влияет на воспринимаемую задержку. С поддержкой потоковой передачи вы получите маркеры обратно в блоках, как только они будут доступны. Для конечных пользователей такой подход часто чувствует, что модель реагирует быстрее, хотя общее время завершения запроса остается неизменным.
Примеры, когда потоковая передача менее важна:
Анализ тональности, перевод языка, создание контента.
Существует множество вариантов использования, когда выполняется некоторая массовая задача, в которой вы заботитесь только о готовом результате, а не ответе в режиме реального времени. Если потоковая передача отключена, вы не получите маркеры, пока модель не завершит весь ответ.
Фильтрация содержимого
Azure OpenAI включает систему фильтрации содержимого, которая работает вместе с основными моделями. Эта система работает, выполняя запрос и завершение с помощью ансамбля моделей классификации, направленных на обнаружение и предотвращение вывода вредного содержимого.
Система фильтрации содержимого обнаруживает и принимает меры по определенным категориям потенциально вредного содержимого как в запросах ввода, так и в завершении выходных данных.
Добавление фильтрации содержимого связано с увеличением безопасности, но и задержкой. Существует множество приложений, где этот компромисс в производительности необходим, однако существуют некоторые более низкие варианты использования рисков, в которых отключение фильтров содержимого для повышения производительности может потребоваться изучить.
Дополнительные сведения о запросе изменений в политиках фильтрации содержимого по умолчанию.
Разделение рабочих нагрузок
Сочетание разных рабочих нагрузок в одной конечной точке может отрицательно повлиять на задержку. Это связано с тем, что (1) они пакетируются вместе во время вывода и коротких вызовов могут ожидать более длительных завершения и (2) смешивания вызовов могут снизить скорость попадания кэша, так как они оба конкурируют за одно и то же пространство. По возможности рекомендуется иметь отдельные развертывания для каждой рабочей нагрузки.
Размер запроса
Хотя размер запроса имеет меньшее влияние на задержку, чем размер создания, он влияет на общее время, особенно если размер увеличивается.
Пакетная обработка
Если вы отправляете несколько запросов в одну конечную точку, вы можете пакетировать запросы в один вызов. Это сокращает количество запросов, которые необходимо сделать, и в зависимости от сценария, который может улучшить общее время отклика. Мы рекомендуем протестировать этот метод, чтобы узнать, помогает ли он.
Как измерить пропускную способность
Рекомендуется измерять общую пропускную способность развертывания с помощью двух мер:
- Вызовы в минуту: количество вызовов вывода API, которые вы делаете в минуту. Это можно измерить в Azure Monitor с помощью метрики запросов OpenAI Azure и разделения по имени ModelDeploymentName
- Общее количество маркеров в минуту: общее количество маркеров, обрабатываемых в минуту при развертывании. Сюда входят запросы и созданные маркеры. Это часто разделяется на измерение как для более глубокого понимания производительности развертывания. Это можно измерить в Azure-Monitor с помощью метрики обработанных маркеров вывода.
Дополнительные сведения о мониторинге службы Azure OpenAI.
Как измерять задержку на вызов
Время, необходимое для каждого вызова, зависит от времени, необходимого для чтения модели, создания выходных данных и применения фильтров содержимого. Способ измерения времени будет отличаться, если вы используете потоковую передачу или нет. Мы предлагаем различные наборы мер для каждого случая.
Дополнительные сведения о мониторинге службы Azure OpenAI.
Непотоковые:
- Время сквозного запроса: общее время, затраченное на создание всего ответа для непотоковых запросов, как измеряется шлюзом API. Это число увеличивается по мере увеличения размера запроса и создания.
Потоковая передача.
- Время отклика: рекомендуемая мера задержки (скорость отклика) для потоковых запросов. Применяется к развертываниям, управляемым PTU и PTU. Вычисляется как время, затраченное на первый ответ после отправки пользователем запроса, как измеряется шлюзом API. Это число увеличивается по мере увеличения размера запроса и (или) уменьшения размера попадания.
- Среднее время создания маркеров от первого маркера до последнего маркера, разделенное на количество созданных маркеров, как измеряется шлюзом API. Это измеряет скорость создания ответов и увеличивается по мере увеличения нагрузки системы. Рекомендуемая мера задержки для потоковых запросов.
Итоги
Задержка модели. Если для вас важна задержка модели, рекомендуется попробовать мини-модель GPT-4o.
Более низкие максимальные токены: OpenAI обнаружил, что даже в тех случаях, когда общее количество созданных маркеров аналогично запросу с более высоким значением, заданным для параметра максимального токена, будет иметь большую задержку.
Более низкий общий объем созданных маркеров: меньше маркеров, созданных быстрее, чем общий ответ. Помните, что это похоже на цикл с
n tokens = n iterations. Снизьте число создаваемых токенов, чтобы сократить общее время отклика.Потоковая передача. Включение потоковой передачи может быть полезно для управления ожиданиями пользователей в определенных ситуациях, позволяя пользователю видеть ответ модели по мере создания, а не ждать, пока последний маркер не будет готов.
Фильтрация содержимого повышает безопасность, но также влияет на задержку. Оцените, будет ли какая-либо из рабочих нагрузок воспользоваться измененными политиками фильтрации содержимого.