Оценка Azure OpenAI (предварительная версия)
Оценка крупных языковых моделей является критически важным шагом в измерении их производительности в различных задачах и измерениях. Это особенно важно для точно настроенных моделей, где оценка повышения производительности (или потерь) от обучения имеет решающее значение. Подробные оценки помогут вам понять, как различные версии модели могут повлиять на ваше приложение или сценарий.
Оценка Azure OpenAI позволяет разработчикам создавать тестовые запуски для тестирования ожидаемых пар входных и выходных данных, оценки производительности модели в ключевых метрик, таких как точность, надежность и общая производительность.
Поддержка оценки
Доступность в регионах
- восточная часть США 2
- Центрально-северная часть США
- Центральная Швеция
- Западная Швейцария
Поддерживаемые типы развертывания
- Стандартные
- Глобальный стандарт
- Стандарт зоны данных
- Подготовленный управляемый
- Глобальные подготовленные управляемые
- Управляемая зона данных
Конвейер оценки
Тестирование данных
Необходимо собрать наземный набор данных, на который вы хотите протестировать. Создание набора данных обычно является итеративным процессом, который гарантирует, что оценки остаются актуальными для ваших сценариев с течением времени. Обычно этот набор данных на основе истины используется вручную и представляет ожидаемое поведение модели. Набор данных также помечен и содержит ожидаемые ответы.
Примечание.
Некоторые тесты оценки, такие как тональность и допустимые данные JSON или XML , не требуют данных истины.
Источник данных должен находиться в формате JSONL. Ниже приведены два примера наборов данных оценки JSONL:
Формат оценки
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
При отправке и выборе файла оценки будет возвращен предварительный просмотр первых трех строк:


Вы можете выбрать существующие ранее загруженные наборы данных или отправить новый набор данных.
Создание ответов (необязательно)
Запрос, используемый в оценке, должен соответствовать запросу, который планируется использовать в рабочей среде. Эти запросы предоставляют инструкции для следующей модели. Как и в случае с игровой площадкой, можно создать несколько входных данных, чтобы включить в запрос несколько примеров. Дополнительные сведения см. в статье "Методы разработки запросов" для получения подробных сведений о некоторых передовых методах в области проектирования запросов и разработки запросов.
Вы можете ссылаться на входные данные в запросах с помощью {{input.column_name}} формата, где column_name соответствует именам столбцов в входном файле.
Выходные данные, созданные во время оценки, будут ссылаться на последующие шаги с помощью {{sample.output_text}} формата.
Примечание.
Необходимо использовать двойные фигурные скобки, чтобы убедиться, что вы ссылаетесь на данные правильно.
Развертывание модели
В рамках создания вычислений вы выберете модели, которые следует использовать при создании ответов (необязательно), а также какие модели следует использовать при оценке моделей с определенными критериями тестирования.
В Azure OpenAI вы назначите определенные развертывания моделей для использования в рамках оценки. Можно сравнить несколько развертываний моделей в одном запуске оценки.
Вы можете оценить базовые или точно настроенные развертывания моделей. Развертывания, доступные в списке, зависят от тех, которые вы создали в ресурсе Azure OpenAI. Если вы не можете найти требуемое развертывание, вы можете создать новый из страницы оценки Azure OpenAI.
Критерии тестирования
Критерии тестирования используются для оценки эффективности каждого вывода, созданного целевой моделью. Эти тесты сравнивают входные данные с выходными данными, чтобы обеспечить согласованность. Вы можете настроить различные критерии для тестирования и измерения качества и релевантности выходных данных на разных уровнях.

Начало работы
Выберите оценку Azure OpenAI (предварительная версия) на портале Azure AI Foundry. Чтобы просмотреть это представление в качестве параметра, может потребоваться сначала выбрать существующий ресурс Azure OpenAI в поддерживаемом регионе.
Выбор новой оценки
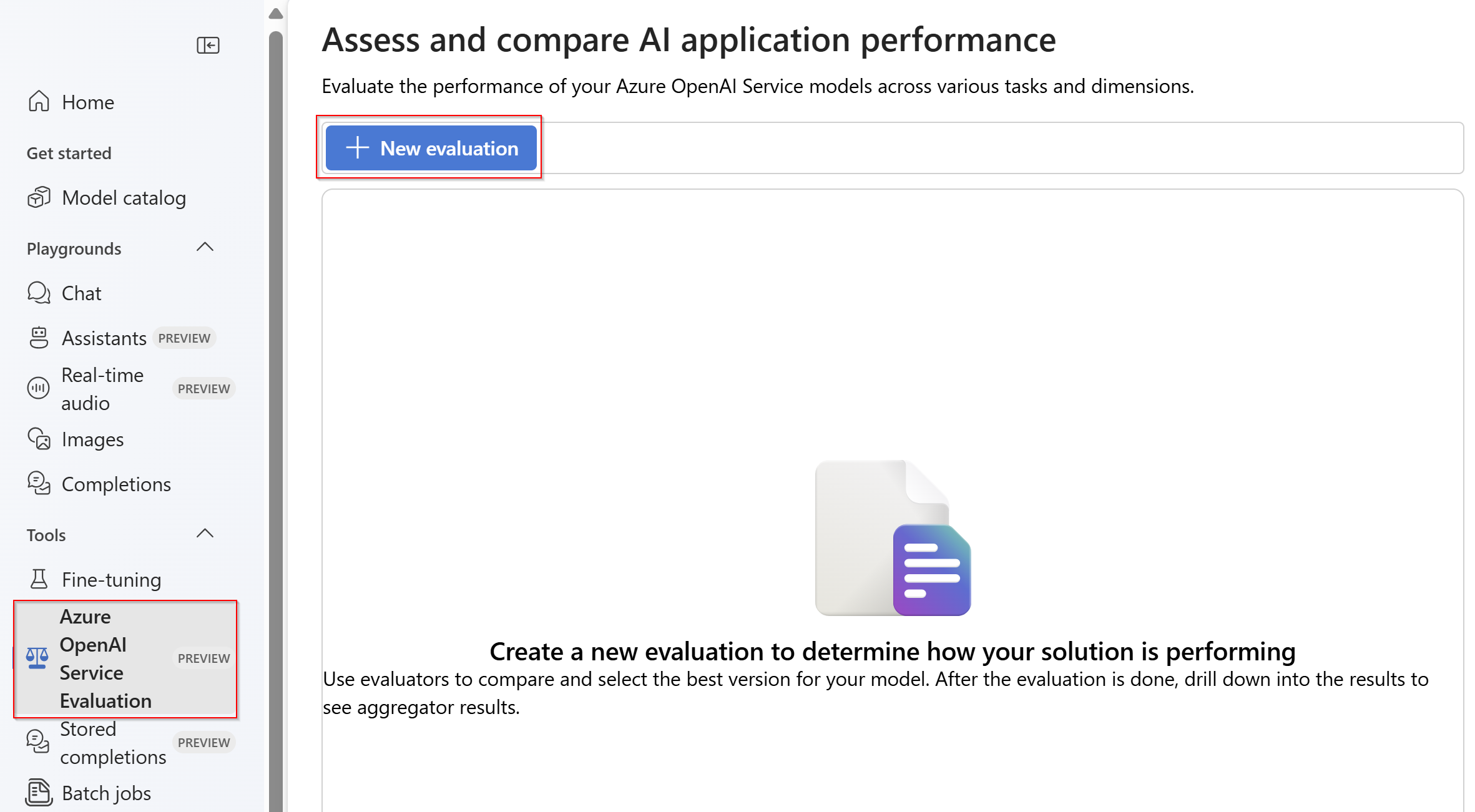
Введите имя оценки. По умолчанию случайное имя создается автоматически, если вы не измените и не замените его. Выберите " Отправить новый набор данных".
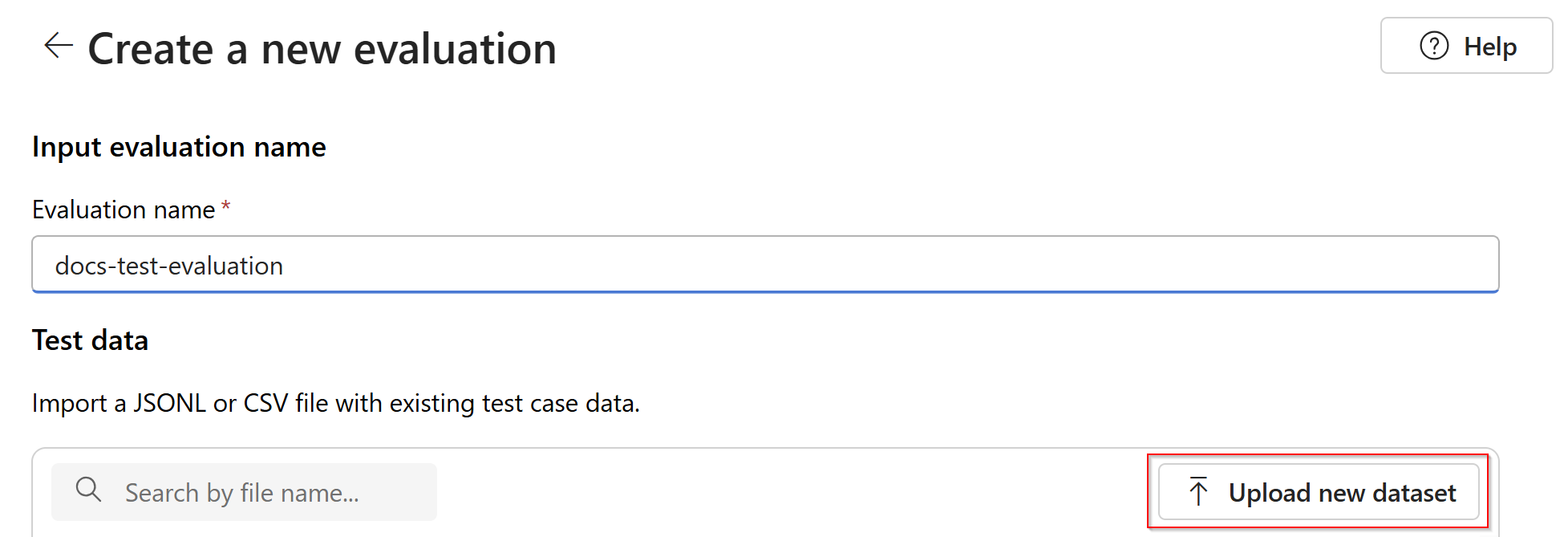
Выберите оценку, которая будет иметь
.jsonlформат. Если вам нужен пример тестового файла, вы можете сохранить эти 10 строк в файл с именемeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Вы увидите первые три строки файла в виде предварительной версии:
В разделе "Ответы" нажмите кнопку "Создать ". Выберите
{{item.input}}из раскрывающегося списка "Создать" с помощью раскрывающегося списка шаблонов . Это приведет к внедрению входных полей из файла оценки в отдельные запросы на выполнение новой модели, которую мы хотим сравнить с нашим набором данных оценки. Модель будет принимать эти входные данные и создавать собственные уникальные выходные данные, которые в этом случае будут храниться в переменной, называемой{{sample.output_text}}. Затем мы будем использовать этот пример выходного текста позже в рамках наших критериев тестирования. Кроме того, можно указать собственные пользовательские системные сообщения и отдельные примеры сообщений вручную.Выберите модель, которую нужно создать на основе оценки. Если у вас нет модели, ее можно создать. В этом примере мы используем стандартное развертывание
gpt-4o-mini.
Параметры или символ спокетирования управляют основными параметрами, передаваемыми в модель. В настоящее время поддерживаются только следующие параметры:




- Температура
- Максимальная длина
- Верхний P
Максимальная длина в настоящее время ограничена в 2048 году независимо от выбранной модели.
Выберите " Добавить критерии тестирования" нажмите кнопку "Добавить".
Выберите семантическое сходство> в разделе "Сравнение
{{item.output}}" в разделе "Добавление{{sample.output_text}}". При этом исходные справочные выходные данные из файла оценки.jsonlбудут сравниваться с выходными данными, которые будут созданы путем предоставления запроса модели на основе ваших{{item.input}}данных.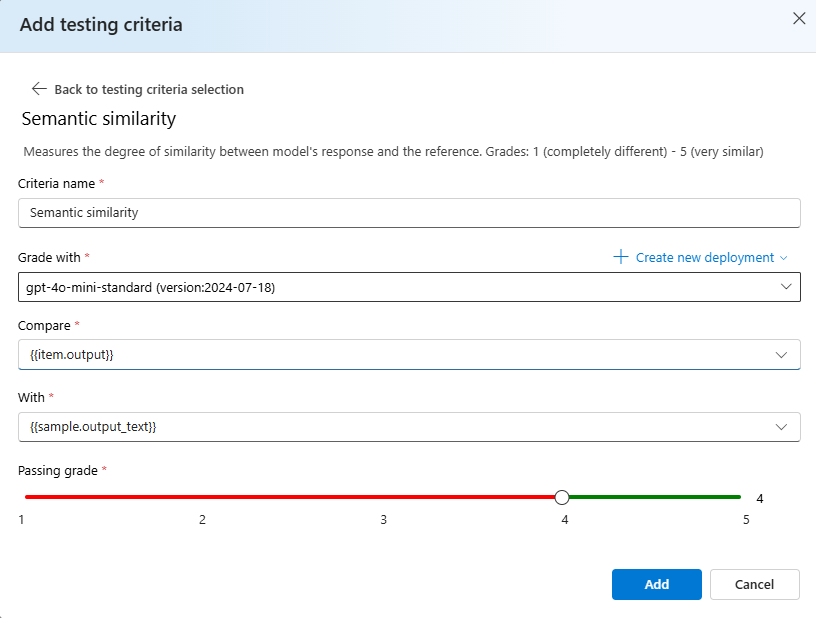
Выберите " Добавить"> на этом этапе можно добавить дополнительные критерии тестирования или выбрать "Создать", чтобы инициировать выполнение задания оценки.
После нажатия кнопки "Создать" вы перейдете на страницу состояния для задания оценки.
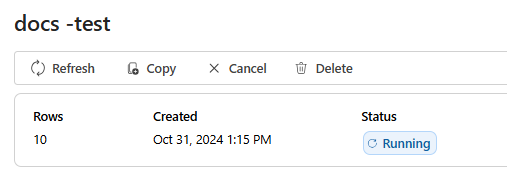
После создания задания оценки можно выбрать задание, чтобы просмотреть полные сведения о задании:
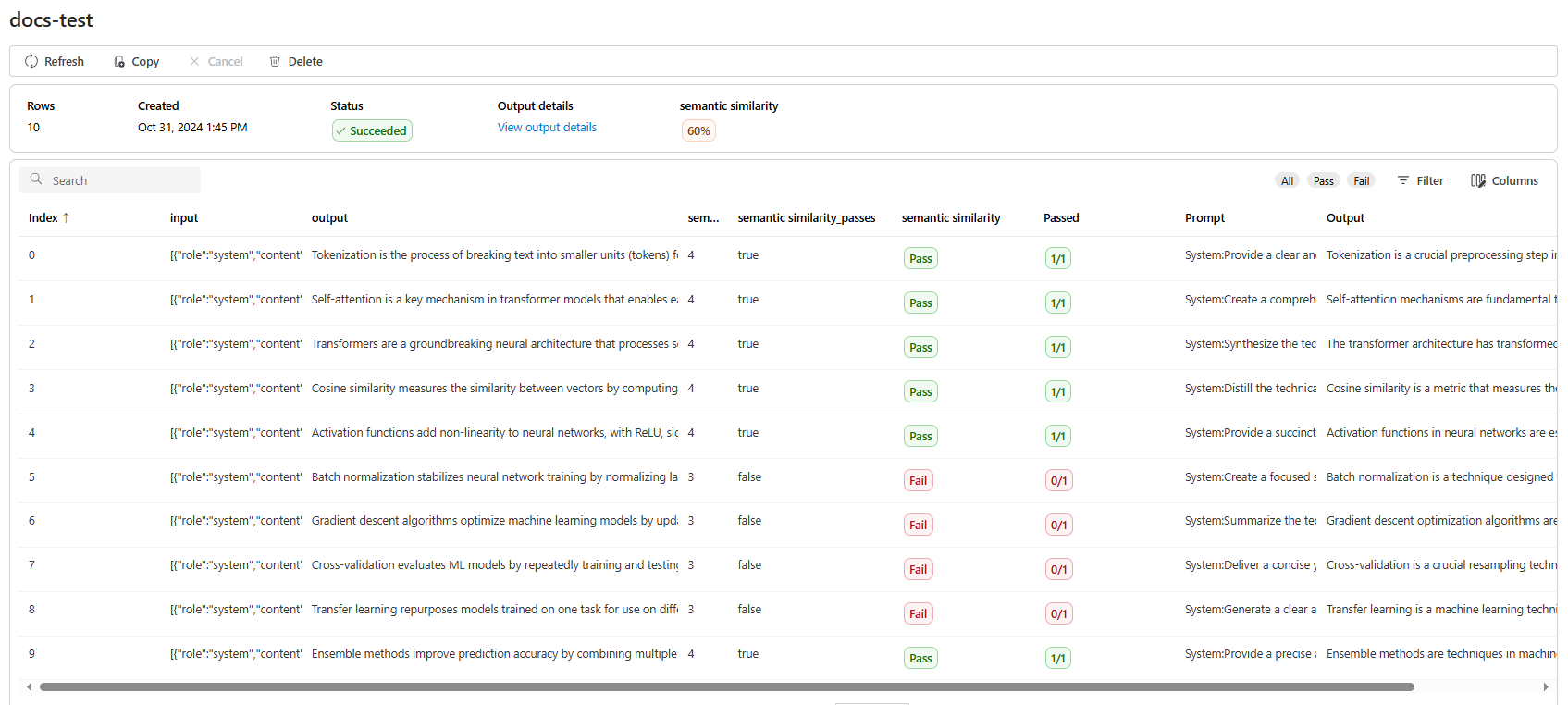
Сведения о выходных данных представления семантического сходства содержат представление JSON, которое можно скопировать или вставить в тесты.
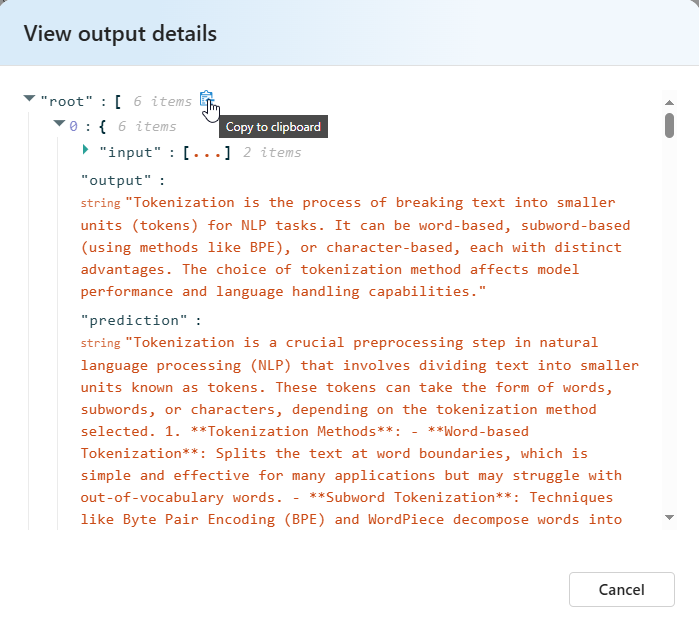




Сведения о критериях тестирования
Оценка OpenAI Azure предлагает несколько вариантов критериев тестирования. В приведенном ниже разделе приведены дополнительные сведения о каждом параметре.
Фактуальность
Оценивает фактическую точность отправленного ответа, сравнивая его с экспертным ответом.
Фактуальность оценивает фактическую точность отправленного ответа, сравнивая его с ответом эксперта. Использование подробной цепочки мысли (CoT) запроса, классировщик определяет, соответствует ли отправленный ответ, подмножество, супермножество или конфликт с ответом эксперта. Он игнорирует различия в стиле, грамматике или препинания, фокусируясь исключительно на фактическом содержимом. Фактуальность может оказаться полезной во многих сценариях, включая, но не ограничивается проверкой содержимого и средствами обучения, обеспечивая точность ответов, предоставляемых ИИ.

Вы можете просмотреть текст запроса, используемый в рамках этого критерия тестирования, выбрав раскрывающийся список рядом с запросом. Текущий текст запроса:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Семантическое сходство
Измеряет степень сходства между ответом модели и ссылкой.
Grades: 1 (completely different) - 5 (very similar).

Тональность
Пытается определить эмоциональный тон выходных данных.

Вы можете просмотреть текст запроса, используемый в рамках этого критерия тестирования, выбрав раскрывающийся список рядом с запросом. Текущий текст запроса:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Проверка строки
Проверяет, соответствует ли выходные данные ожидаемой строке точно.

Проверка строки выполняет различные двоичные операции с двумя строковыми переменными, позволяющими использовать различные критерии оценки. Он помогает проверить различные связи строк, включая равенство, сдерживание и конкретные шаблоны. Этот вычислитель позволяет сравнивать регистр или нечувствительные регистры. Он также предоставляет указанные оценки для истинных или ложных результатов, позволяя настраиваемые результаты оценки на основе результата сравнения. Ниже приведен тип поддерживаемых операций.
-
equals: проверяет, равна ли выходная строка строке вычисления. -
contains: проверяет, является ли строка оценки подстрокой выходной строки. -
starts-with: проверяет, начинается ли выходная строка со строкой оценки. -
ends-with: проверяет, заканчивается ли выходная строка строкой оценки.
Примечание.
При настройке определенных параметров в критериях тестирования можно выбрать переменную и шаблон. Выберите переменную , если вы хотите ссылаться на столбец во входных данных. Выберите шаблон , если требуется предоставить фиксированную строку.
Допустимый КОД JSON или XML
Проверяет допустимость выходных данных JSON или XML.

Сопоставление схемы
Гарантирует, что выходные данные соответствуют указанной структуре.

Соответствие условий
Оцените, соответствует ли ответ модели вашим критериям. Оценка: передача или сбой.

Вы можете просмотреть текст запроса, используемый в рамках этого критерия тестирования, выбрав раскрывающийся список рядом с запросом. Текущий текст запроса:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Качество текста
Оцените качество текста по сравнению с ссылочным текстом.

Сводка:
- Оценка BLEU: оценивает качество созданного текста, сравнивая его с одним или несколькими высококачественными ссылочными переводами с помощью оценки BLEU.
- Оценка ROUGE: оценивает качество созданного текста, сравнивая его со ссылками на сводки с использованием показателей ROUGE.
- Cosine: также называется косинус сходства измеряет, насколько тесно две вставки текста ( например, выходные данные модели и ссылочные тексты) выравниваются в значении, помогая оценить семантику сходства между ними. Это делается путем измерения расстояния в векторном пространстве.
Сведения:
Оценка blEU (двулингвальная оценка недоумения) часто используется в обработке естественного языка (NLP) и машинном переводе. Он широко используется в вариантах использования сводных данных и создания текста. Он оценивает, насколько тесно сформированный текст соответствует ссылочного текста. Оценка BLEU варьируется от 0 до 1, с более высокими оценками, указывающими на лучшее качество.
ROUGE (Roustudy understudy for Gisting Evaluation) — это набор метрик, используемых для оценки автоматической суммирования и машинного перевода. Он измеряет перекрытие между созданными текстовыми и справочными сводами. ROUGE фокусируется на мерах, ориентированных на отзыв, чтобы оценить, насколько хорошо созданный текст охватывает ссылочный текст. Оценка ROUGE предоставляет различные метрики, включая: • ROUGE-1: перекрытие юниграмм (одиночных слов) между созданным и ссылочным текстом. • ROUGE-2: перекрытие bigrams (два последовательных слова) между созданным и ссылочным текстом. • ROUGE-3: перекрытие триграмм (три последовательных слова) между созданным и ссылочным текстом. • ROUGE-4: перекрытие четырехграммов (четыре последовательных слова) между созданным и ссылочным текстом. • ROUGE-5: перекрытие пятиграммов (пять последовательных слов) между созданным и справочным текстом. • ROUGE-L: перекрытие L-граммов (L последовательных слов) между созданным и ссылочным текстом. Сводка текста и сравнение документов являются одними из оптимальных вариантов использования ROUGE, особенно в сценариях, когда согласованность текста и релевантность являются критически важными.
Cosine подобие измеряет, насколько тесно две вставки текста , такие как выходные данные модели и ссылочные тексты, выравниваются в значении, помогая оценить семантику сходства между ними. Аналогично другим вычислителям на основе моделей, необходимо предоставить развертывание модели, используемое для оценки.
Внимание
Для этого вычислителя поддерживаются только модели внедрения:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Настраиваемый запрос
Использует модель для классификации выходных данных в набор указанных меток. Этот вычислитель использует настраиваемый запрос, который необходимо определить.
