Краткое руководство. Начало работы с созданием звука Azure OpenAI
gpt-4o-mini-audio-preview Модели gpt-4o-audio-preview вводят модальность звука в существующий /chat/completions API. Звуковая модель расширяет потенциал для приложений ИИ в взаимодействии с текстом и голосовой связи и анализе звука. Модальности, поддерживаемые в gpt-4o-audio-preview и gpt-4o-mini-audio-preview моделях, включают: текст, звук и текст + звук.
Ниже приведена таблица поддерживаемых модальностей с примерами вариантов использования:
| Входные данные модальности | Выходные данные модальности | Примеры использования |
|---|---|---|
| Текст | Текст и звук | Текст для речи, создание аудиокниги |
| Аудио | Текст и звук | Транскрибирование звука, создание аудиокниги |
| Аудио | Текст | Транскрибирование звука |
| Текст и звук | Текст и звук | Создание аудиокниги |
| Текст и звук | Текст | Транскрибирование звука |
С помощью возможностей создания звука можно добиться более динамических и интерактивных приложений ИИ. Модели, поддерживающие входные и выходные данные звука, позволяют создавать голосовые ответы на запросы и использовать звуковые входные данные для запроса модели.
Поддерживаемые модели
В настоящее время поддерживается только gpt-4o-audio-preview и gpt-4o-mini-audio-preview версия: 2024-12-17 поддерживается создание звука.
Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
В настоящее время для аудиозаписи поддерживаются следующие голоса: сплав, эхо и мерцание.
Максимальный размер аудиофайла составляет 20 МБ.
Примечание.
API Реального времени использует ту же базовую модель звука GPT-4o, что и API завершения, но оптимизирован для низкой задержки, взаимодействия звука в режиме реального времени.
поддержка API
Поддержка завершения звука впервые добавлена в версию 2025-01-01-previewAPI.
Развертывание модели для создания звука
Чтобы развернуть модель на портале Azure AI Foundry, выполните следующие действия gpt-4o-mini-audio-preview .
- Перейдите на страницу службы Azure OpenAI на портале Azure AI Foundry. Убедитесь, что вы вошли в подписку Azure с ресурсом Azure OpenAI Service и развернутой
gpt-4o-mini-audio-previewмоделью. - Выберите игровую площадку чата в разделе "Игровые площадки" в левой области.
- Выберите и создайте новое развертывание>из базовых моделей, чтобы открыть окно развертывания.
- Найдите и выберите
gpt-4o-mini-audio-previewмодель, а затем выберите "Развернуть" для выбранного ресурса. - В мастере развертывания выберите версию
2024-12-17модели. - Следуйте инструкциям мастера, чтобы завершить развертывание модели.
Теперь, когда у вас есть развертывание gpt-4o-mini-audio-preview модели, вы можете взаимодействовать с ней в api завершения чата портала Azure AI Foundry или API завершения чата.
Использование аудиогенерации GPT-4o
Чтобы общаться с развернутой gpt-4o-mini-audio-preview моделью на портале Azure AI Foundry, выполните следующие действия.
Перейдите на страницу службы Azure OpenAI на портале Azure AI Foundry. Убедитесь, что вы вошли в подписку Azure с ресурсом Azure OpenAI Service и развернутой
gpt-4o-mini-audio-previewмоделью.Выберите игровую площадку чата в разделе "Ресурсная площадка" в левой области.
Выберите развернутую
gpt-4o-mini-audio-previewмодель в раскрывающемся списке развертывания .Начните чат с моделью и прослушивайте звуковые ответы.
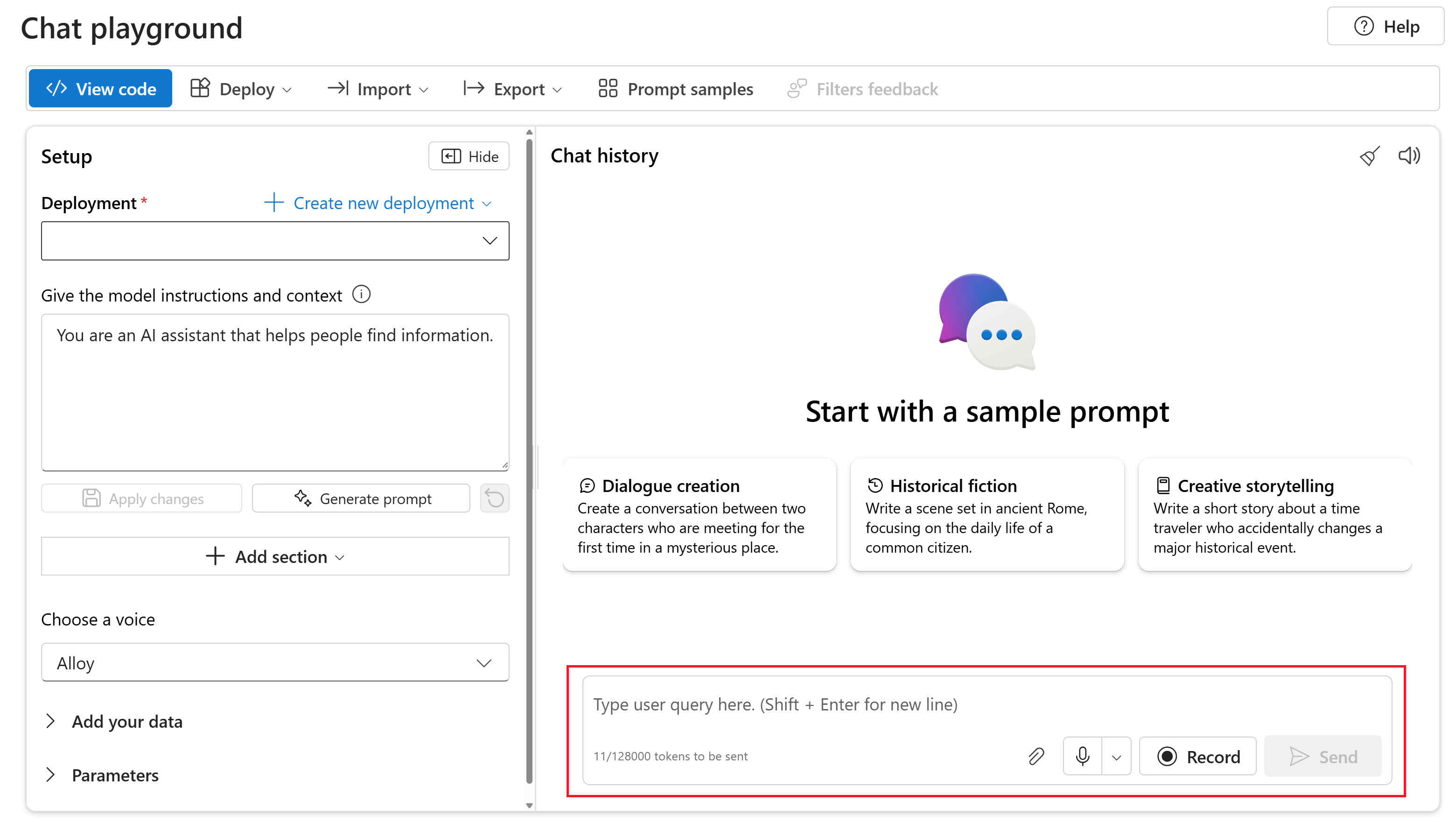
Вы можете:
- Запись звуковых запросов.
- Вложите аудиофайлы в чат.
- Введите текстовые запросы.

Справочная документация | Исходный код библиотеки | Пакет (npm) | Примеры
gpt-4o-mini-audio-preview Модели gpt-4o-audio-preview вводят модальность звука в существующий /chat/completions API. Звуковая модель расширяет потенциал для приложений ИИ в взаимодействии с текстом и голосовой связи и анализе звука. Модальности, поддерживаемые в gpt-4o-audio-preview и gpt-4o-mini-audio-preview моделях, включают: текст, звук и текст + звук.
Ниже приведена таблица поддерживаемых модальностей с примерами вариантов использования:
| Входные данные модальности | Выходные данные модальности | Примеры использования |
|---|---|---|
| Текст | Текст и звук | Текст для речи, создание аудиокниги |
| Аудио | Текст и звук | Транскрибирование звука, создание аудиокниги |
| Аудио | Текст | Транскрибирование звука |
| Текст и звук | Текст и звук | Создание аудиокниги |
| Текст и звук | Текст | Транскрибирование звука |
С помощью возможностей создания звука можно добиться более динамических и интерактивных приложений ИИ. Модели, поддерживающие входные и выходные данные звука, позволяют создавать голосовые ответы на запросы и использовать звуковые входные данные для запроса модели.
Поддерживаемые модели
В настоящее время поддерживается только gpt-4o-audio-preview и gpt-4o-mini-audio-preview версия: 2024-12-17 поддерживается создание звука.
Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
В настоящее время для аудиозаписи поддерживаются следующие голоса: сплав, эхо и мерцание.
Максимальный размер аудиофайла составляет 20 МБ.
Примечание.
API Реального времени использует ту же базовую модель звука GPT-4o, что и API завершения, но оптимизирован для низкой задержки, взаимодействия звука в режиме реального времени.
поддержка API
Поддержка завершения звука впервые добавлена в версию 2025-01-01-previewAPI.
Необходимые компоненты
- подписка Azure — создайте бесплатную учетную запись.
- Node.js поддержка LTS или ESM.
- Ресурс Azure OpenAI, созданный в одном из поддерживаемых регионов. Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
- Затем необходимо развернуть модель с ресурсом
gpt-4o-mini-audio-previewAzure OpenAI. Дополнительные сведения см. в статье "Создание ресурса" и развертывание модели с помощью Azure OpenAI.
Предварительные требования для идентификатора Microsoft Entra
Для рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra необходимо:
- Установите Azure CLI, используемый для проверки подлинности без ключа с помощью идентификатора Microsoft Entra.
- Назначьте роль учетной
Cognitive Services Userзаписи пользователя. Роли можно назначить в портал Azure в разделе управления доступом (IAM)>Добавить назначение ролей.
Настройка
Создайте новую папку
audio-completions-quickstartдля хранения приложения и откройте Visual Studio Code в этой папке с помощью следующей команды:mkdir audio-completions-quickstart && code audio-completions-quickstartСоздайте следующую
package.jsonкоманду:npm init -yОбновите ECMAScript с помощью следующей
package.jsonкоманды:npm pkg set type=moduleУстановите клиентскую библиотеку OpenAI для JavaScript с помощью:
npm install openaiДля рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra установите
@azure/identityпакет с помощью:npm install @azure/identity
Получение сведений о ресурсе
Чтобы проверить подлинность приложения с помощью ресурса Azure OpenAI, необходимо получить следующие сведения:
| Имя переменной | Значение |
|---|---|
AZURE_OPENAI_ENDPOINT |
Это значение можно найти в разделе "Ключи и конечная точка" при изучении ресурса из портал Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Это значение будет соответствовать пользовательскому имени, которое вы выбрали для развертывания при развертывании модели. Это значение можно найти в разделе "Развертывания модели управления>ресурсами" в портал Azure. |
OPENAI_API_VERSION |
Дополнительные сведения о версиях API. |
Дополнительные сведения о бессерверной проверке подлинности и настройке переменных среды.
Внимание
Чтобы использовать рекомендуемую проверку подлинности без ключа с пакетом SDK, убедитесь, что AZURE_OPENAI_API_KEY переменная среды не задана.
Создание звука из текстового ввода
to-audio.jsСоздайте файл со следующим кодом:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Войдите в Azure с помощью следующей команды:
az loginЗапустите файл JavaScript.
node to-audio.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука из текстового ввода
Скрипт создает звуковой файл с именем dog.wav в том же каталоге, что и скрипт. Звуковой файл содержит речной ответ на запрос: "Является ли золотой извлекатель хорошей семейной собакой?"
Создание звука и текста из входных данных звука
from-audio.jsСоздайте файл со следующим кодом:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Войдите в Azure с помощью следующей команды:
az loginЗапустите файл JavaScript.
node from-audio.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука и текста из звукового ввода
Скрипт создает расшифровку сводки голосовых входных данных. Он также создает звуковой файл с именем analysis.wav в том же каталоге, что и сценарий. Звуковой файл содержит речной ответ на запрос.
Создание звука и использование завершения чата с несколькими поворотами
multi-turn.jsСоздайте файл со следующим кодом:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-mini-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Войдите в Azure с помощью следующей команды:
az loginЗапустите файл JavaScript.
node multi-turn.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для завершения чата с несколькими поворотами
Скрипт создает расшифровку сводки голосовых входных данных. Затем он делает завершение чата с несколькими поворотами, чтобы кратко суммировать голосовой ввод.
Исходный код библиотеки | Пакет | Примеры
gpt-4o-mini-audio-preview Модели gpt-4o-audio-preview вводят модальность звука в существующий /chat/completions API. Звуковая модель расширяет потенциал для приложений ИИ в взаимодействии с текстом и голосовой связи и анализе звука. Модальности, поддерживаемые в gpt-4o-audio-preview и gpt-4o-mini-audio-preview моделях, включают: текст, звук и текст + звук.
Ниже приведена таблица поддерживаемых модальностей с примерами вариантов использования:
| Входные данные модальности | Выходные данные модальности | Примеры использования |
|---|---|---|
| Текст | Текст и звук | Текст для речи, создание аудиокниги |
| Аудио | Текст и звук | Транскрибирование звука, создание аудиокниги |
| Аудио | Текст | Транскрибирование звука |
| Текст и звук | Текст и звук | Создание аудиокниги |
| Текст и звук | Текст | Транскрибирование звука |
С помощью возможностей создания звука можно добиться более динамических и интерактивных приложений ИИ. Модели, поддерживающие входные и выходные данные звука, позволяют создавать голосовые ответы на запросы и использовать звуковые входные данные для запроса модели.
Поддерживаемые модели
В настоящее время поддерживается только gpt-4o-audio-preview и gpt-4o-mini-audio-preview версия: 2024-12-17 поддерживается создание звука.
Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
В настоящее время для аудиозаписи поддерживаются следующие голоса: сплав, эхо и мерцание.
Максимальный размер аудиофайла составляет 20 МБ.
Примечание.
API Реального времени использует ту же базовую модель звука GPT-4o, что и API завершения, но оптимизирован для низкой задержки, взаимодействия звука в режиме реального времени.
поддержка API
Поддержка завершения звука впервые добавлена в версию 2025-01-01-previewAPI.
В этом руководстве описано, как приступить к созданию звука с помощью пакета SDK OpenAI для Azure для Python.
Необходимые компоненты
- Подписка Azure. Создайте ее бесплатно.
- Python 3.8 или более поздней версии. Рекомендуется использовать Python 3.10 или более поздней версии, но требуется по крайней мере Python 3.8. Если у вас нет подходящей версии Python, вы можете следовать инструкциям в руководстве по Python VS Code для простого способа установки Python в операционной системе.
- Ресурс Azure OpenAI, созданный в одном из поддерживаемых регионов. Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
- Затем необходимо развернуть модель с ресурсом
gpt-4o-mini-audio-previewAzure OpenAI. Дополнительные сведения см. в статье "Создание ресурса" и развертывание модели с помощью Azure OpenAI.
Предварительные требования для идентификатора Microsoft Entra
Для рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra необходимо:
- Установите Azure CLI, используемый для проверки подлинности без ключа с помощью идентификатора Microsoft Entra.
- Назначьте роль учетной
Cognitive Services Userзаписи пользователя. Роли можно назначить в портал Azure в разделе управления доступом (IAM)>Добавить назначение ролей.
Настройка
Создайте новую папку
audio-completions-quickstartдля хранения приложения и откройте Visual Studio Code в этой папке с помощью следующей команды:mkdir audio-completions-quickstart && code audio-completions-quickstartСоздайте виртуальную среду. Если у вас уже установлен Python 3.10 или более поздней версии, можно создать виртуальную среду с помощью следующих команд:
Активация среды Python означает, что при запуске
pythonилиpipиз командной строки используется интерпретатор Python, содержащийся в.venvпапке приложения. Вы можете использоватьdeactivateкоманду для выхода из виртуальной среды Python, а затем повторно активировать ее при необходимости.Совет
Рекомендуется создать и активировать новую среду Python для установки пакетов, необходимых для этого руководства. Не устанавливайте пакеты в глобальную установку Python. При установке пакетов Python всегда следует использовать виртуальную или конда-среду, в противном случае можно разорвать глобальную установку Python.
Установите клиентская библиотека OpenAI для Python с помощью следующих компонентов:
pip install openaiДля рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra установите
azure-identityпакет с помощью:pip install azure-identity
Получение сведений о ресурсе
Чтобы проверить подлинность приложения с помощью ресурса Azure OpenAI, необходимо получить следующие сведения:
| Имя переменной | Значение |
|---|---|
AZURE_OPENAI_ENDPOINT |
Это значение можно найти в разделе "Ключи и конечная точка" при изучении ресурса из портал Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Это значение будет соответствовать пользовательскому имени, которое вы выбрали для развертывания при развертывании модели. Это значение можно найти в разделе "Развертывания модели управления>ресурсами" в портал Azure. |
OPENAI_API_VERSION |
Дополнительные сведения о версиях API. |
Дополнительные сведения о бессерверной проверке подлинности и настройке переменных среды.
Создание звука из текстового ввода
to-audio.pyСоздайте файл со следующим кодом:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Запустите файл Python.
python to-audio.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука из текстового ввода
Скрипт создает звуковой файл с именем dog.wav в том же каталоге, что и скрипт. Звуковой файл содержит речной ответ на запрос: "Является ли золотой извлекатель хорошей семейной собакой?"
Создание звука и текста из входных данных звука
from-audio.pyСоздайте файл со следующим кодом:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Запустите файл Python.
python from-audio.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука и текста из звукового ввода
Скрипт создает расшифровку сводки голосовых входных данных. Он также создает звуковой файл с именем analysis.wav в том же каталоге, что и сценарий. Звуковой файл содержит речной ответ на запрос.
Создание звука и использование завершения чата с несколькими поворотами
multi-turn.pyСоздайте файл со следующим кодом:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-mini-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Запустите файл Python.
python multi-turn.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для завершения чата с несколькими поворотами
Скрипт создает расшифровку сводки голосовых входных данных. Затем он делает завершение чата с несколькими поворотами, чтобы кратко суммировать голосовой ввод.
gpt-4o-mini-audio-preview Модели gpt-4o-audio-preview вводят модальность звука в существующий /chat/completions API. Звуковая модель расширяет потенциал для приложений ИИ в взаимодействии с текстом и голосовой связи и анализе звука. Модальности, поддерживаемые в gpt-4o-audio-preview и gpt-4o-mini-audio-preview моделях, включают: текст, звук и текст + звук.
Ниже приведена таблица поддерживаемых модальностей с примерами вариантов использования:
| Входные данные модальности | Выходные данные модальности | Примеры использования |
|---|---|---|
| Текст | Текст и звук | Текст для речи, создание аудиокниги |
| Аудио | Текст и звук | Транскрибирование звука, создание аудиокниги |
| Аудио | Текст | Транскрибирование звука |
| Текст и звук | Текст и звук | Создание аудиокниги |
| Текст и звук | Текст | Транскрибирование звука |
С помощью возможностей создания звука можно добиться более динамических и интерактивных приложений ИИ. Модели, поддерживающие входные и выходные данные звука, позволяют создавать голосовые ответы на запросы и использовать звуковые входные данные для запроса модели.
Поддерживаемые модели
В настоящее время поддерживается только gpt-4o-audio-preview и gpt-4o-mini-audio-preview версия: 2024-12-17 поддерживается создание звука.
Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
В настоящее время для аудиозаписи поддерживаются следующие голоса: сплав, эхо и мерцание.
Максимальный размер аудиофайла составляет 20 МБ.
Примечание.
API Реального времени использует ту же базовую модель звука GPT-4o, что и API завершения, но оптимизирован для низкой задержки, взаимодействия звука в режиме реального времени.
поддержка API
Поддержка завершения звука впервые добавлена в версию 2025-01-01-previewAPI.
Необходимые компоненты
- Подписка Azure. Создайте ее бесплатно.
- Python 3.8 или более поздней версии. Рекомендуется использовать Python 3.10 или более поздней версии, но требуется по крайней мере Python 3.8. Если у вас нет подходящей версии Python, вы можете следовать инструкциям в руководстве по Python VS Code для простого способа установки Python в операционной системе.
- Ресурс Azure OpenAI, созданный в одном из поддерживаемых регионов. Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
- Затем необходимо развернуть модель с ресурсом
gpt-4o-mini-audio-previewAzure OpenAI. Дополнительные сведения см. в статье "Создание ресурса" и развертывание модели с помощью Azure OpenAI.
Предварительные требования для идентификатора Microsoft Entra
Для рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra необходимо:
- Установите Azure CLI, используемый для проверки подлинности без ключа с помощью идентификатора Microsoft Entra.
- Назначьте роль учетной
Cognitive Services Userзаписи пользователя. Роли можно назначить в портал Azure в разделе управления доступом (IAM)>Добавить назначение ролей.
Настройка
Создайте новую папку
audio-completions-quickstartдля хранения приложения и откройте Visual Studio Code в этой папке с помощью следующей команды:mkdir audio-completions-quickstart && code audio-completions-quickstartСоздайте виртуальную среду. Если у вас уже установлен Python 3.10 или более поздней версии, можно создать виртуальную среду с помощью следующих команд:
Активация среды Python означает, что при запуске
pythonилиpipиз командной строки используется интерпретатор Python, содержащийся в.venvпапке приложения. Вы можете использоватьdeactivateкоманду для выхода из виртуальной среды Python, а затем повторно активировать ее при необходимости.Совет
Рекомендуется создать и активировать новую среду Python для установки пакетов, необходимых для этого руководства. Не устанавливайте пакеты в глобальную установку Python. При установке пакетов Python всегда следует использовать виртуальную или конда-среду, в противном случае можно разорвать глобальную установку Python.
Установите клиентская библиотека OpenAI для Python с помощью следующих компонентов:
pip install openaiДля рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra установите
azure-identityпакет с помощью:pip install azure-identity
Получение сведений о ресурсе
Чтобы проверить подлинность приложения с помощью ресурса Azure OpenAI, необходимо получить следующие сведения:
| Имя переменной | Значение |
|---|---|
AZURE_OPENAI_ENDPOINT |
Это значение можно найти в разделе "Ключи и конечная точка" при изучении ресурса из портал Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Это значение будет соответствовать пользовательскому имени, которое вы выбрали для развертывания при развертывании модели. Это значение можно найти в разделе "Развертывания модели управления>ресурсами" в портал Azure. |
OPENAI_API_VERSION |
Дополнительные сведения о версиях API. |
Дополнительные сведения о бессерверной проверке подлинности и настройке переменных среды.
Создание звука из текстового ввода
to-audio.pyСоздайте файл со следующим кодом:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Запустите файл Python.
python to-audio.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука из текстового ввода
Скрипт создает звуковой файл с именем dog.wav в том же каталоге, что и скрипт. Звуковой файл содержит речной ответ на запрос: "Является ли золотой извлекатель хорошей семейной собакой?"
Создание звука и текста из входных данных звука
from-audio.pyСоздайте файл со следующим кодом:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Запустите файл Python.
python from-audio.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука и текста из звукового ввода
Скрипт создает расшифровку сводки голосовых входных данных. Он также создает звуковой файл с именем analysis.wav в том же каталоге, что и сценарий. Звуковой файл содержит речной ответ на запрос.
Создание звука и использование завершения чата с несколькими поворотами
multi-turn.pyСоздайте файл со следующим кодом:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-mini-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-mini-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-mini-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Запустите файл Python.
python multi-turn.py
Подождите несколько минут, чтобы получить ответ.
Выходные данные для завершения чата с несколькими поворотами
Скрипт создает расшифровку сводки голосовых входных данных. Затем он делает завершение чата с несколькими поворотами, чтобы кратко суммировать голосовой ввод.
Справочная документация | Исходный код библиотеки | Пакет (npm) | Примеры
gpt-4o-mini-audio-preview Модели gpt-4o-audio-preview вводят модальность звука в существующий /chat/completions API. Звуковая модель расширяет потенциал для приложений ИИ в взаимодействии с текстом и голосовой связи и анализе звука. Модальности, поддерживаемые в gpt-4o-audio-preview и gpt-4o-mini-audio-preview моделях, включают: текст, звук и текст + звук.
Ниже приведена таблица поддерживаемых модальностей с примерами вариантов использования:
| Входные данные модальности | Выходные данные модальности | Примеры использования |
|---|---|---|
| Текст | Текст и звук | Текст для речи, создание аудиокниги |
| Аудио | Текст и звук | Транскрибирование звука, создание аудиокниги |
| Аудио | Текст | Транскрибирование звука |
| Текст и звук | Текст и звук | Создание аудиокниги |
| Текст и звук | Текст | Транскрибирование звука |
С помощью возможностей создания звука можно добиться более динамических и интерактивных приложений ИИ. Модели, поддерживающие входные и выходные данные звука, позволяют создавать голосовые ответы на запросы и использовать звуковые входные данные для запроса модели.
Поддерживаемые модели
В настоящее время поддерживается только gpt-4o-audio-preview и gpt-4o-mini-audio-preview версия: 2024-12-17 поддерживается создание звука.
Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
В настоящее время для аудиозаписи поддерживаются следующие голоса: сплав, эхо и мерцание.
Максимальный размер аудиофайла составляет 20 МБ.
Примечание.
API Реального времени использует ту же базовую модель звука GPT-4o, что и API завершения, но оптимизирован для низкой задержки, взаимодействия звука в режиме реального времени.
поддержка API
Поддержка завершения звука впервые добавлена в версию 2025-01-01-previewAPI.
Необходимые компоненты
- подписка Azure — создайте бесплатную учетную запись.
- Node.js поддержка LTS или ESM.
- TypeScript , установленный глобально.
- Ресурс Azure OpenAI, созданный в одном из поддерживаемых регионов. Дополнительные сведения о доступности регионов см. в документации по моделям и версиям.
- Затем необходимо развернуть модель с ресурсом
gpt-4o-mini-audio-previewAzure OpenAI. Дополнительные сведения см. в статье "Создание ресурса" и развертывание модели с помощью Azure OpenAI.
Предварительные требования для идентификатора Microsoft Entra
Для рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra необходимо:
- Установите Azure CLI, используемый для проверки подлинности без ключа с помощью идентификатора Microsoft Entra.
- Назначьте роль учетной
Cognitive Services Userзаписи пользователя. Роли можно назначить в портал Azure в разделе управления доступом (IAM)>Добавить назначение ролей.
Настройка
Создайте новую папку
audio-completions-quickstartдля хранения приложения и откройте Visual Studio Code в этой папке с помощью следующей команды:mkdir audio-completions-quickstart && code audio-completions-quickstartСоздайте следующую
package.jsonкоманду:npm init -yОбновите ECMAScript с помощью следующей
package.jsonкоманды:npm pkg set type=moduleУстановите клиентскую библиотеку OpenAI для JavaScript с помощью:
npm install openaiДля рекомендуемой проверки подлинности без ключа с помощью идентификатора Microsoft Entra установите
@azure/identityпакет с помощью:npm install @azure/identity
Получение сведений о ресурсе
Чтобы проверить подлинность приложения с помощью ресурса Azure OpenAI, необходимо получить следующие сведения:
| Имя переменной | Значение |
|---|---|
AZURE_OPENAI_ENDPOINT |
Это значение можно найти в разделе "Ключи и конечная точка" при изучении ресурса из портал Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Это значение будет соответствовать пользовательскому имени, которое вы выбрали для развертывания при развертывании модели. Это значение можно найти в разделе "Развертывания модели управления>ресурсами" в портал Azure. |
OPENAI_API_VERSION |
Дополнительные сведения о версиях API. |
Дополнительные сведения о бессерверной проверке подлинности и настройке переменных среды.
Внимание
Чтобы использовать рекомендуемую проверку подлинности без ключа с пакетом SDK, убедитесь, что AZURE_OPENAI_API_KEY переменная среды не задана.
Создание звука из текстового ввода
to-audio.tsСоздайте файл со следующим кодом:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonСоздайте файл для транспиля кода TypeScript и скопируйте следующий код для ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Транспилировать из TypeScript в JavaScript.
tscВойдите в Azure с помощью следующей команды:
az loginВыполните следующую команду, чтобы запустить код:
node to-audio.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука из текстового ввода
Скрипт создает звуковой файл с именем dog.wav в том же каталоге, что и скрипт. Звуковой файл содержит речной ответ на запрос: "Является ли золотой извлекатель хорошей семейной собакой?"
Создание звука и текста из входных данных звука
from-audio.tsСоздайте файл со следующим кодом:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonСоздайте файл для транспиля кода TypeScript и скопируйте следующий код для ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Транспилировать из TypeScript в JavaScript.
tscВойдите в Azure с помощью следующей команды:
az loginВыполните следующую команду, чтобы запустить код:
node from-audio.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для создания звука и текста из звукового ввода
Скрипт создает расшифровку сводки голосовых входных данных. Он также создает звуковой файл с именем analysis.wav в том же каталоге, что и сценарий. Звуковой файл содержит речной ответ на запрос.
Создание звука и использование завершения чата с несколькими поворотами
multi-turn.tsСоздайте файл со следующим кодом:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-mini-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-mini-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };tsconfig.jsonСоздайте файл для транспиля кода TypeScript и скопируйте следующий код для ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Транспилировать из TypeScript в JavaScript.
tscВойдите в Azure с помощью следующей команды:
az loginВыполните следующую команду, чтобы запустить код:
node multi-turn.js
Подождите несколько минут, чтобы получить ответ.
Выходные данные для завершения чата с несколькими поворотами
Скрипт создает расшифровку сводки голосовых входных данных. Затем он делает завершение чата с несколькими поворотами, чтобы кратко суммировать голосовой ввод.
Очистка ресурсов
Если вы хотите очистить и удалить ресурс Azure OpenAI, его можно удалить. Перед удалением ресурса необходимо сначала удалить все развернутые модели.
Связанный контент
- Дополнительные сведения о типах развертывания Azure OpenAI.
- Дополнительные сведения о квотах и ограничениях Azure OpenAI.