Использование Анализа текста для здравоохранения
Внимание
Анализ текста для здравоохранения предоставляется на условиях "как есть" и "со всеми недостатками". Анализ текста для здравоохранения не предназначен для использования в контексте медицинских устройств, клинической поддержки, диагностических средств или других технологий, предназначенных для диагностики, лечения, облегчения симптомов или предотвращения заболеваний или других состояний, и ни одна из лицензий или прав не предоставляется корпорацией Майкрософт для использования этой возможности в таких целях. Эта возможность не предназначена для реализации или развертывания в качестве замены профессиональных медицинских консультаций или врачебного мнения, диагностики, лечения или клинической оценки, проводимых специалистами в сфере здравоохранения, и не должна использоваться таким образом. Клиент несет полную ответственность за использование Анализ текста для здравоохранения. Клиент должен отдельно лицензировать все исходные словари, которые клиент намеревается использовать, в соответствии с условиями, установленными для этого Приложения к лицензионному соглашению метатезауруса унифицированного языка медицинских систем (UMLS) или любой эквивалентной ссылки в дальнейшем. Клиент несет ответственность за соблюдение этих условий лицензии, включая любые географические или другие применимые ограничения.
Анализ текста для здоровья теперь позволяет извлекать социальные детерминанты здоровья (SDOH) и этнические упоминания в тексте. Эта возможность может не охватывать все потенциальные SDOH и не является производным выводов на основе SDOH или этнической принадлежности (например, информация об использовании веществ возникает, но злоупотребление веществами не выводится). Все решения, использующие выходные данные Анализ текста для здравоохранения, которые влияют на выделение отдельных лиц или ресурсов (включая, но не ограничивается, теми, которые связаны с выставлением счетов, человеческими ресурсами или управлением лечением) должны приниматься с помощью человеческого надзора и не основаны исключительно на результатах модели. Цель возможности извлечения SDOH и этнической принадлежности заключается в том, чтобы помочь поставщикам улучшить результаты здравоохранения, и не следует использовать для стигмы или рисования отрицательных выводов о пользователях или потребителей данных SDOH, или популяции пациентов за пределами указанной цели помочь поставщикам улучшить результаты здравоохранения.
Анализ текста для здоровья можно использовать для извлечения и маркировки соответствующих медицинских сведений из неструктурированных текстов, таких как заметки врачей, сводки, клинические документы и электронные медицинские записи. Служба выполняет распознавание именованных сущностей, извлечение реляционных данных, связывание сущностей и обнаружение утверждений для обнаружения аналитических сведений из входного текста. Сведения о возвращаемых оценках достоверности см. в заметке о прозрачности.
Совет
Если вы хотите протестировать эту функцию без написания кода, используйте Language Studio.
Существует два способа вызова службы:
- Контейнер Docker (синхронно)
- Использование веб-API и клиентских библиотек (асинхронный)
Варианты разработки
Чтобы использовать Анализ текста для работоспособности, вы отправляете необработанный неструктурированный текст для анализа и обрабатываете выходные данные API в приложении. Анализ выполняется на условиях "как есть", без дополнительной настройки используемой модели для ваших данных. Существует два способа использования Анализ текста для работоспособности:
| Вариант разработки | Description |
|---|---|
| Azure AI Foundry | Azure AI Foundry — это веб-платформа, которая позволяет использовать связывание сущностей с текстовыми примерами с собственными данными при регистрации. Дополнительные сведения см. на веб-сайте Azure AI Foundry или документации по Azure AI Foundry. |
| REST API или клиентская библиотека (пакет SDK для Azure) | Интегрируйте службу Анализа текста для здравоохранения в приложения с помощью REST API или клиентской библиотеки, доступной на разных языках. Дополнительные сведения см. в кратком руководстве по Анализ текста работоспособности. |
| Контейнер Docker | Используйте доступный контейнер Docker, чтобы развернуть эту функцию локально. Эти контейнеры Docker позволяют разместить службу ближе к данным, чтобы обеспечивать безопасность, соответствие требованиям и пользоваться другими операционными преимуществами. |
Языки ввода
Анализ текста для работоспособности поддерживает английский язык в дополнение к нескольким языкам, которые в настоящее время находятся в предварительной версии. Вы можете использовать размещенный API или развернуть API в контейнере, как описано в разделе Анализ текста поддержки языков работоспособности.
Отправка данных
Чтобы отправить запрос API, потребуется конечная точка и ключ ресурса языка.
Примечание.
Ключ и конечную точку для языкового ресурса можно найти на портале Azure. Они находятся на странице ресурса Ключ и конечная точка в разделе Управление ресурсами.
Анализ выполняется при получении запроса. Если отправить запрос с помощью REST API или клиентской библиотеки, результаты будут возвращены асинхронно. Если вы используете контейнер Docker, они будут возвращены синхронно.
При асинхронном использовании этой функции результаты API доступны в течение 24 часов с момента приема запроса и указываются в ответе. По истечении этого периода результаты очищаются и больше не будут доступны для извлечения.
Отправка запроса на быстрое взаимодействие с здравоохранением (FHIR)
Ресурсы быстрого взаимодействия со здравоохранением (FHIR) — это стандарт связи отрасли здравоохранения, разработанный организацией «Уровень здоровья семь» (HL7). Стандарт определяет форматы данных (ресурсы) и структуру API для обмена электронными данными здравоохранения. Чтобы получить результат с помощью структуры FHIR, необходимо отправить версию FHIR в тексте запроса API.
| имени параметра | Тип | значение |
|---|---|---|
| fhirVersion | строка | 4.0.1 |
Получение результатов из функции
В зависимости от вашего запроса API и данных, отправляемых в "Анализ текста для здравоохранения", вы получите следующее:
Распознавание именованных сущностей используется для выполнения семантического извлечения слов и фраз, упомянутых из неструктурированного текста, связанных с любым из поддерживаемых типов сущностей, таких как диагностика, имя лекарства, симптом или знак или возраст.

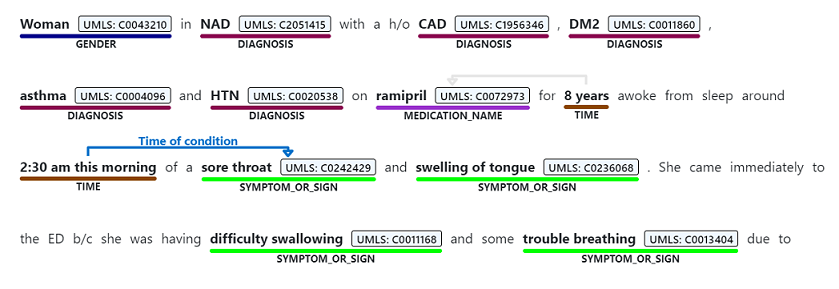
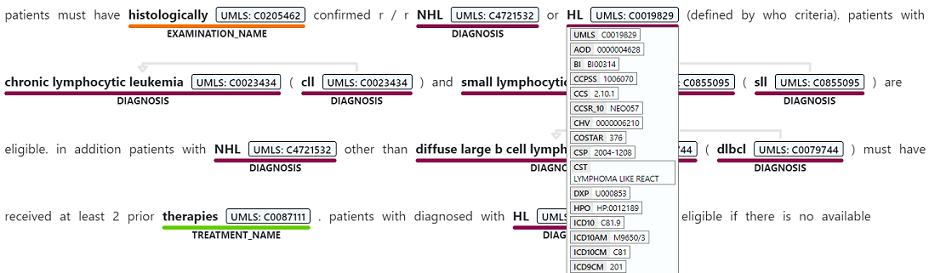
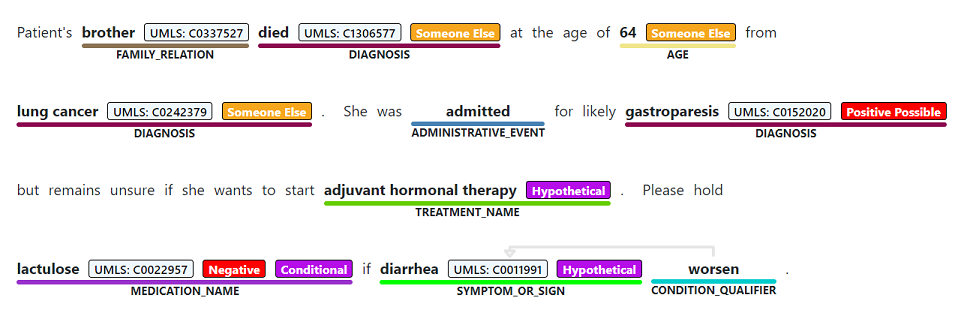
Ограничения службы и данных
Сведения о размере и числе запросов, которые можно отправлять в минуту и секунду, см. в статье об ограничениях службы.