Краткое руководство. пользовательский анализ текста для здоровья
Примечание.
Пользовательский анализ текста для работоспособности (предварительная версия) будет прекращен 10 января 2025 г., перейдя к другим службам обучения пользовательских моделей, таким как распознавание пользовательских именованных сущностей на языке ИИ Azure к этой дате. С 10 января 2025 г. вы можете продолжать использовать пользовательский анализ текста для работоспособности (предварительная версия) в существующих проектах без нарушений. Невозможно создать новые проекты. 10 января 2025 г. рабочие нагрузки, работающие в пользовательской аналитике текста для работоспособности (предварительная версия), будут удалены, а связанные данные проекта будут потеряны.
Используйте эту статью, чтобы приступить к созданию проекта пользовательский анализ текста для здоровья, где можно обучать пользовательские модели поверх Анализ текста для работоспособности для распознавания пользовательских сущностей. Модель представляет собой программный продукт с функциями искусственного интеллекта, обученный для выполнения определенной задачи. Для этой системы модели извлекают связанные с здравоохранением именованные сущности и обучаются путем обучения на основе помеченных данных.
В этой статье мы используем Language Studio для демонстрации ключевых понятий пользовательский анализ текста для здоровья. В качестве примера мы создадим модель пользовательский анализ текста для здоровья для извлечения расположения объекта или лечения из коротких заметок о разгрузке.
Необходимые компоненты
- Подписка Azure — создайте бесплатную учетную запись.
Создание нового ресурса языка ИИ Azure и учетной записи хранения Azure
Прежде чем использовать пользовательский анализ текста для здоровья, необходимо создать ресурс языка искусственного интеллекта Azure, который даст вам учетные данные, необходимые для создания проекта и начала обучения модели. Вам также потребуется учетная запись хранения Azure, где можно отправить набор данных, используемый для сборки модели.
Внимание
Чтобы быстро приступить к работе, рекомендуется создать новый ресурс языка искусственного интеллекта Azure, выполнив действия, описанные в этой статье. Эти действия помогут одновременно создать ресурс службы "Язык" и учетную запись хранения, так как проще сделать это сейчас, чем потом.
Если вы хотите использовать уже существующий ресурс, его нужно подключить к учетной записи хранения. Дополнительные сведения см . в руководстве по использованию уже существующего ресурса.
Создание ресурса на портале Azure
Войдите в портал Azure, чтобы создать новый ресурс языка искусственного интеллекта Azure.
В появившемся окне выберите настраиваемую классификацию текста и распознавание именованных сущностей из пользовательских функций. Нажмите кнопку "Продолжить", чтобы создать ресурс в нижней части экрана.
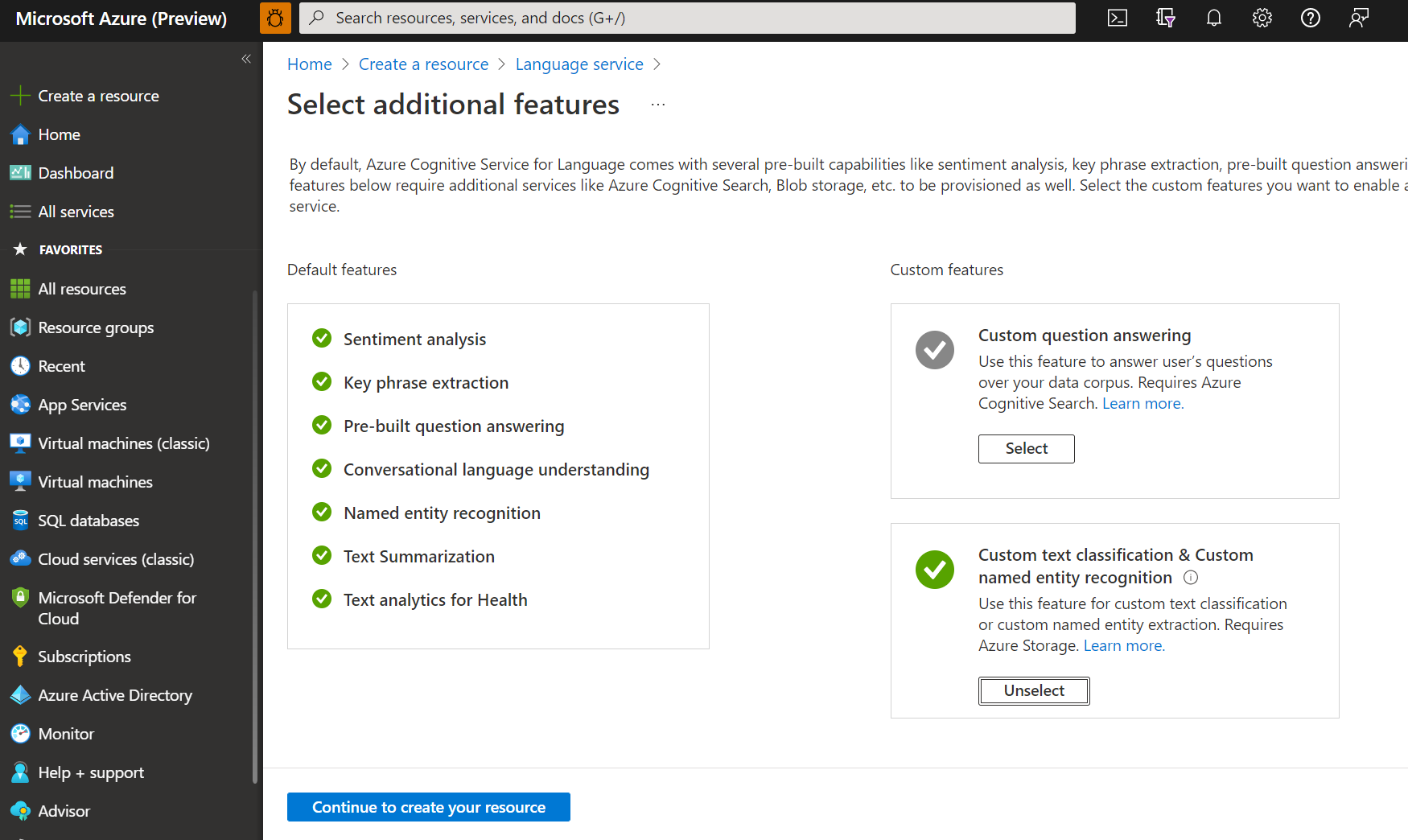
Создайте ресурс службы "Язык" с приведенными ниже сведениями.
Имя Описание Подписка Вашу подписку Azure. Группа ресурсов Группа ресурсов, которая будет содержать ваш ресурс. Можно использовать существующую группу или создать новую. Область/регион Регион для ресурса службы "Язык". Например, "Западная часть США 2". Имя. Имя ресурса. Ценовая категория Ценовая категория ресурса Языка. Вы можете использовать уровень "Бесплатный" (F0), чтобы поработать со службой. Примечание.
Если появится сообщение Ваша учетная запись входа не является владельцем выбранной группы ресурсов учетной записи хранения, значит, ваша учетная запись должна иметь роль владельца, назначенную группе ресурсов, — только тогда вы сможете создать ресурс службы "Язык". Обратитесь за помощью к владельцу подписки Azure.
В разделе "Настраиваемая классификация текста" и "Распознавание именованных сущностей" выберите существующую учетную запись хранения или выберите новую учетную запись хранения. Эти значения для учетной записи хранения помогут вам быстро начать работу, но они не всегда подходят для реальных рабочих сред. Чтобы избежать задержек при создании проекта, подключитесь к учетным записям хранения в том же регионе, что и ресурс Языка.
Значение для учетной записи хранения Рекомендуемое значение Storage account name Любое имя Storage account type Standard LRS Убедитесь, что флажок Уведомление об ответственном применении ИИ установлен. В нижней части страницы щелкните Просмотр и создание, а затем нажмите Создать.

Отправка примера данных в контейнер BLOB-объектов
Когда вы создадите учетную запись хранения Azure и подключите ее к ресурсу службы "Язык", нужно будет отправить документы из примера набора данных в корневой каталог контейнера. Эти документы будут использоваться для обучения модели.
Скачайте пример набора данных с GitHub.
Откройте файл ZIP и извлеките папку с документами.
На портале Azure перейдите к созданной учетной записи хранения и выберите ее.
В учетной записи хранения в меню слева выберите Контейнеры под пунктом Хранилище данных. На появившемся экране нажмите + Контейнер. Присвойте контейнеру имя example-data и оставьте Уровень общего доступа, установленный по умолчанию.
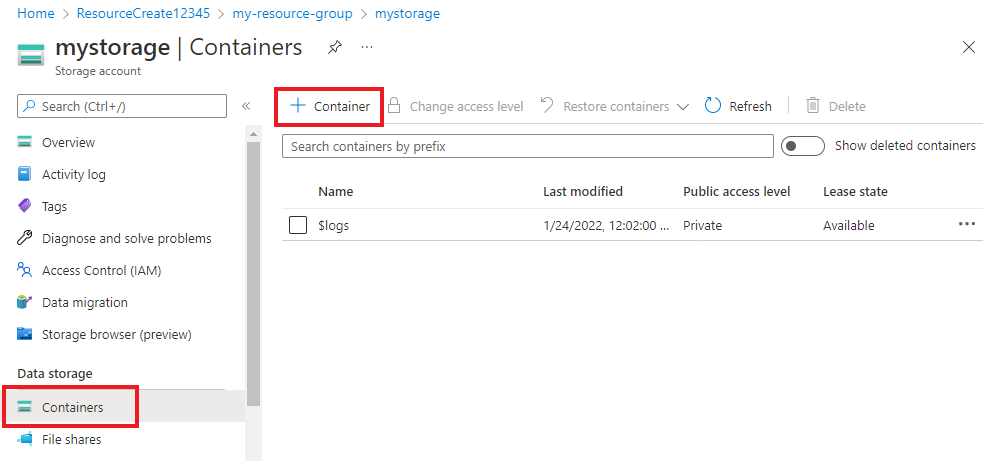
Когда контейнер будет создан, выберите его. Затем нажмите кнопку "Отправить", чтобы выбрать
.txtскачанные ранее файлы..json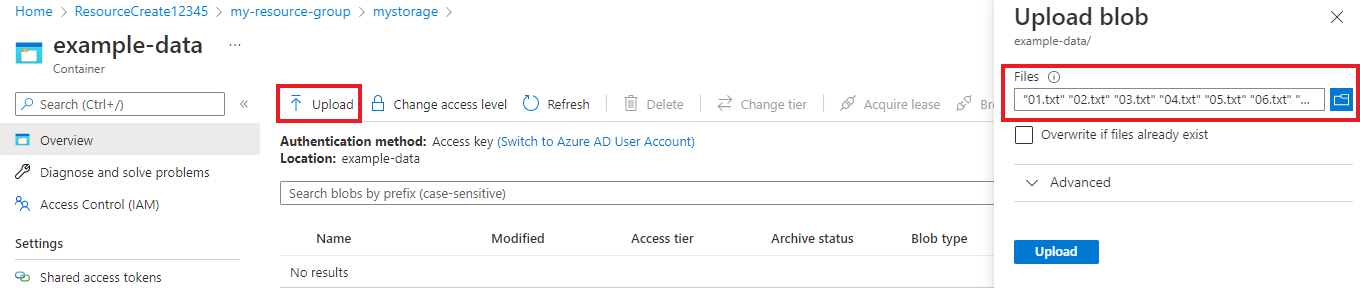


Предоставленный пример набора данных содержит 12 клинических заметок. Каждая клиническая записка включает в себя несколько медицинских организаций и расположение лечения. Мы будем использовать предварительно созданные сущности для извлечения медицинских сущностей и обучения настраиваемой модели для извлечения расположения лечения с помощью изученных и перечисленных компонентов сущности.
Создание проекта пользовательский анализ текста для здоровья
После настройки ресурса и учетной записи хранения создайте проект пользовательский анализ текста для здоровья. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Получить доступ к вашему проекту можете только вы и другие пользователи, у которых есть доступ к используемому ресурсу службы "Язык".
Войдите в Студию Языка. Появится окно, где можно выбрать свою подписку и ресурс служб "Язык". Выберите ресурс службы "Язык", созданный на предыдущем шаге.
В разделе "Извлечение сведений" в Language Studio выберите "Настраиваемые Анализ текста для работоспособности".
Щелкните Create new project (Создать новый проект) в меню в верхней части страницы проектов. Создание проекта позволяет помечать данные, обучать, оценивать, улучшать и развертывать модели.

Введите сведения о проекте, включая имя, описание и язык файлов в проекте. Если вы используете пример набора данных, выберите английский язык. Вы не можете изменить имя проекта позже. Выберите Далее
Совет
Набор данных не обязательно должен быть полностью на одном языке. У вас может быть несколько документов с разными поддерживаемыми языками. Если набор данных содержит документы с разными языками или если во время выполнения предполагается использовать тексты на разных языках, выберите параметр Включить многоязычный набор данных при вводе основных сведений о проекте. Этот параметр можно включить позже на странице Параметры проекта.
После нажатия кнопки "Создать проект" откроется окно, чтобы подключить учетную запись хранения. Если вы уже подключили учетную запись хранения, отобразится подключенная учетная запись хранения. Если нет, выберите учетную запись хранения в раскрывающемся списке и выберите " Подключить учетную запись хранения".Это позволит задать необходимые роли для учетной записи хранения. На этом шаге может появиться ошибка, если вы не назначены в качестве владельца учетной записи хранения.
Примечание.
- Этот шаг нужно выполнить только один раз для каждого нового используемого ресурса.
- Этот процесс необратим. Если учетная запись хранения будет подключена к ресурсу службы "Язык", ее нельзя будет отключить позже.
- Вы можете подключить ресурс службы "Язык" только к одной учетной записи хранения.
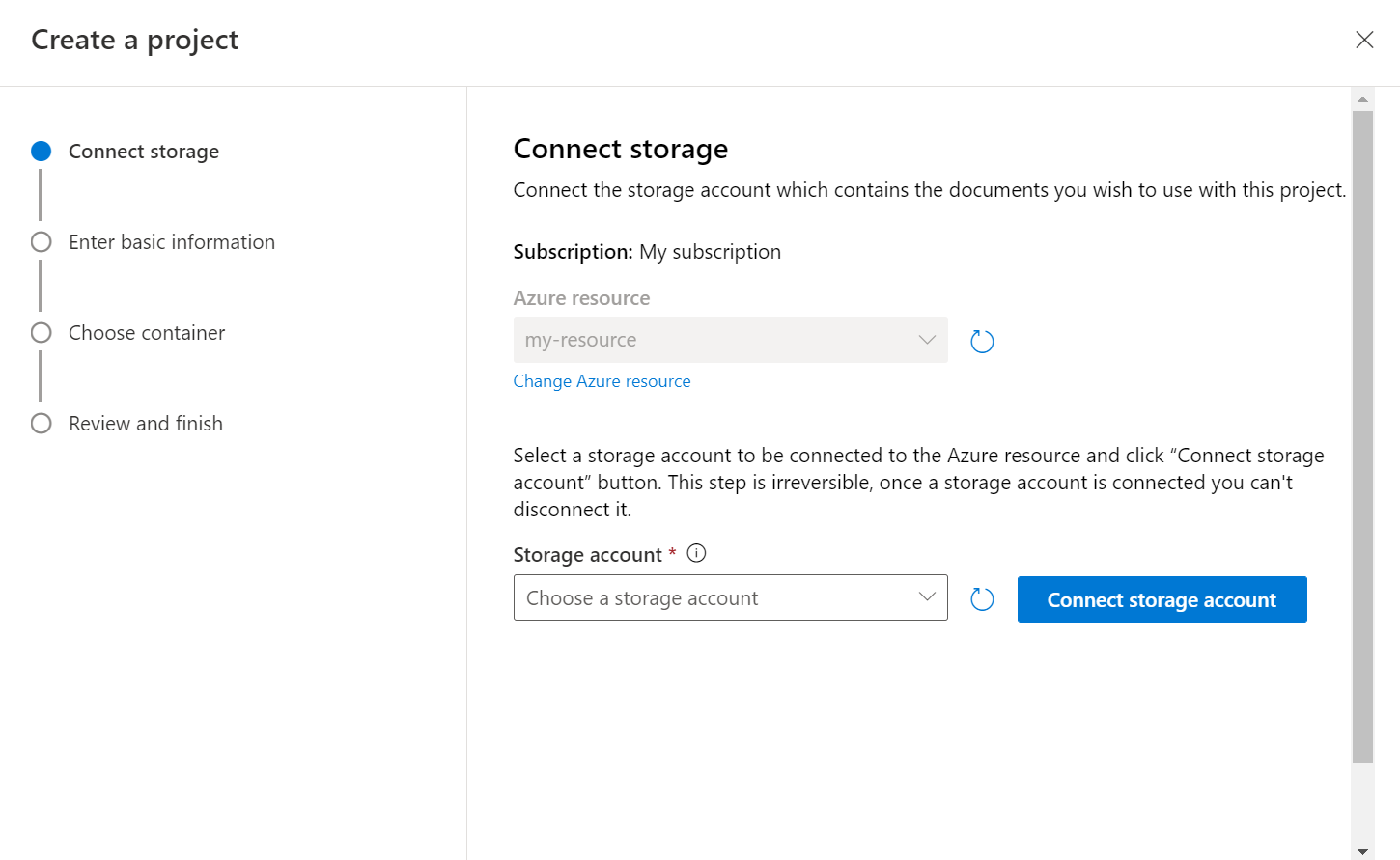
Выберите контейнер, в который отправили набор данных.
Если вы уже помечены данные, убедитесь, что он соответствует поддерживаемму формату и выберите "Да", мои файлы уже помечены, и я отформатировал файл меток JSON и выберите файл меток в раскрывающемся меню. Выберите Далее. Если вы используете набор данных из краткого руководства, нет необходимости просматривать форматирование файла меток JSON.
Проверьте введенные данные и щелкните Create Project (Создать проект).


Обучение модели
Как правило, после создания проекта вы маркируете документы в подключенном к проекту контейнере. В этом кратком руководстве вы импортировали пример помеченного набора данных и инициализировали проект с примером файла меток JSON, чтобы добавить дополнительные метки не нужно.
Чтобы начать обучение модели в студии службы "Язык", сделайте следующее:
Выберите элемент Задания обучения в меню слева.
В верхнем меню выберите Запустить задание на обучение.
Щелкните Train a new model (Обучить новую модель) и введите имя модели в текстовое поле. Можно также перезаписать существующую модель. Для этого выберите соответствующий параметр и укажите модель, которую требуется перезаписать, в раскрывающемся меню. Перезапись обученной модели необратима, но это не повлияет на развернутые модели до тех пор, пока вы не развернете новую модель.
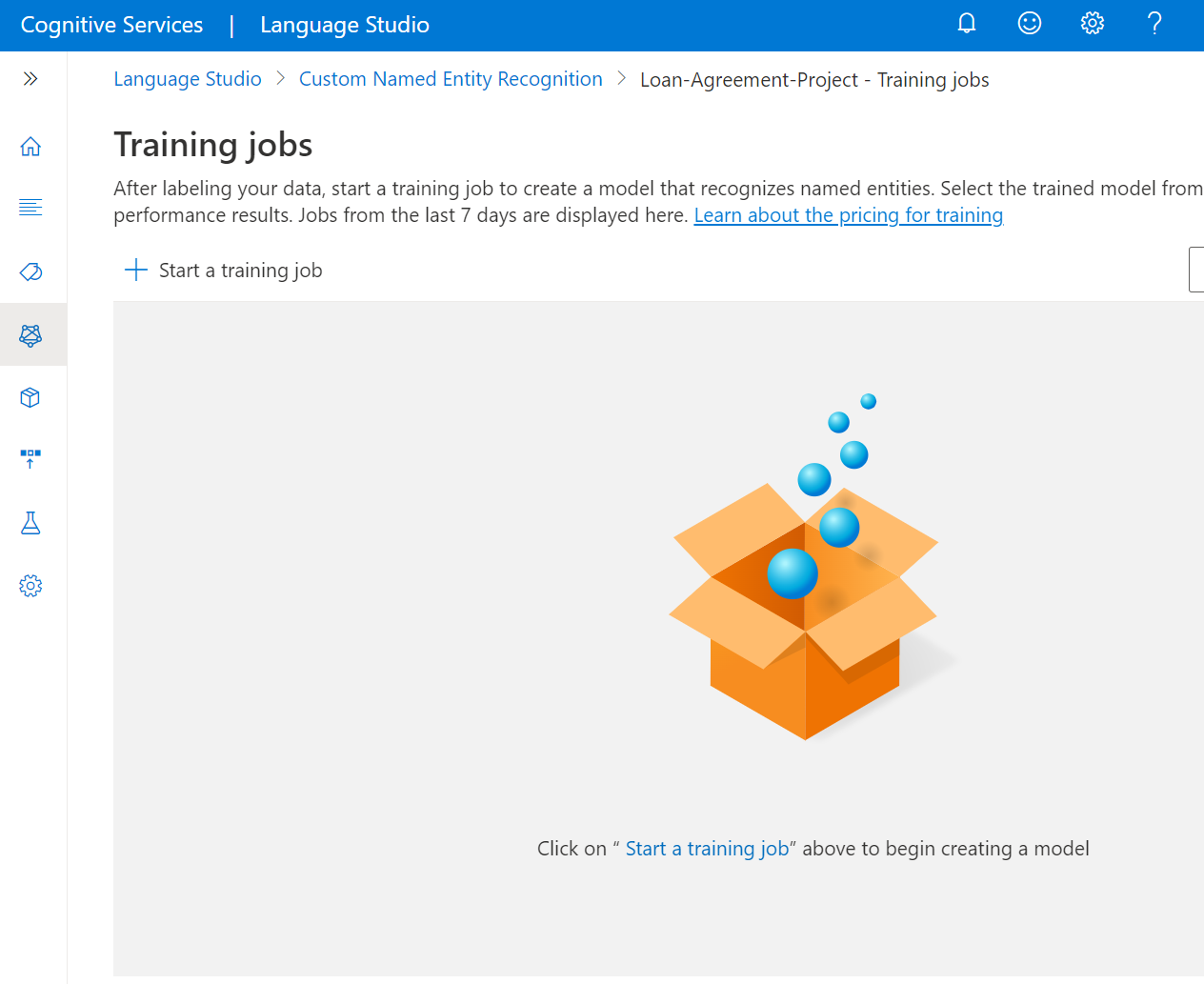
Выберите метод разделения данных. Вы можете выбрать вариант Automatically splitting the testing set from training data (Автоматическое выделение тестового набора из обучающих данных), при котором система разделит данные с метками на обучающий и тестовый наборы в указанной вами пропорции. Или можно использовать разделение данных обучения и тестирования вручную, этот параметр включен только в том случае, если вы добавили документы в набор тестирования. См . метки данных и обучение модели для получения сведений о разбиение данных.
Нажмите кнопку Обучить.
Если выбрать идентификатор задания обучения из списка, на боковой панели появится область, где можно проверить ход обучения, состояние задания и другие сведения для этого задания.
Примечание.
- Модели будут создаваться только с помощью успешно завершенных заданий обучения.
- Обучение может занять от нескольких минут до нескольких часов в зависимости от размера данных с метками.
- В каждый момент времени может выполняться только одно задание на обучение. Нельзя запустить другое задание обучения в том же проекте до тех пор, пока не будет завершено выполнение задания.

Развертывание модели
Обычно после обучения модели изучаются сведения об оценке и вносятся необходимые улучшения. В этом кратком руководстве вы просто развернете модель и предоставите себе к ней доступ в Language Studio. Можно также вызвать API прогнозирования.
Чтобы развернуть модель в студии службы "Язык", выполните следующие действия.
В меню слева выберите Развертывание модели.
Выберите " Добавить развертывание", чтобы запустить новое задание развертывания.
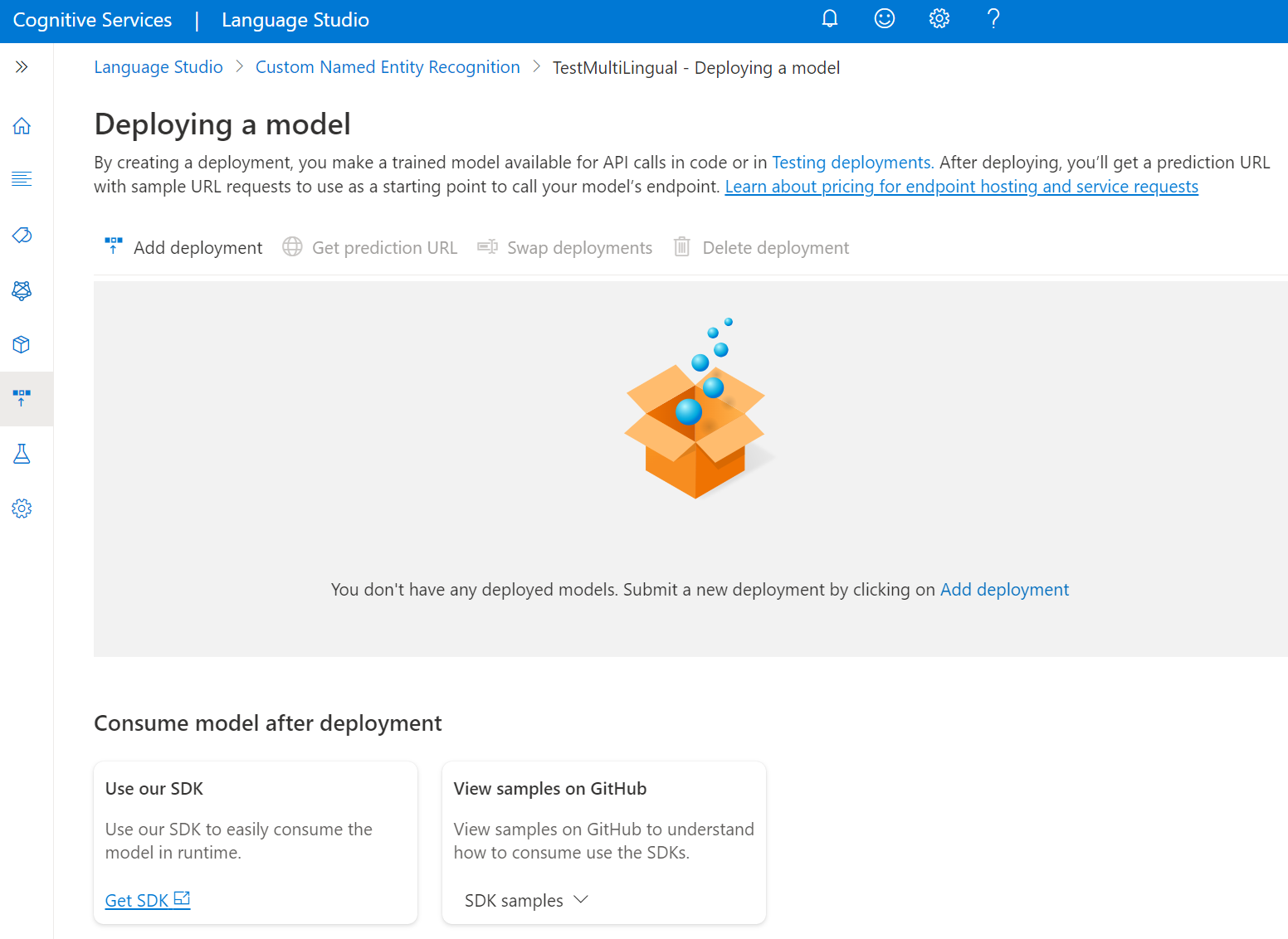
Выберите Создать развертывание, чтобы создать развертывание и назначить обученную модель из раскрывающегося списка ниже. Можно также выбрать вариант Overwrite an existing deployment (Перезаписать существующее развертывание) и выбрать обученную модель, которую требуется назначить развертыванию, в раскрывающемся списке ниже.
Примечание.
Для перезаписи существующего развертывания не требуется вносить изменения в вызов API прогнозирования, но после этого вы будете получать результаты от новой назначенной модели.
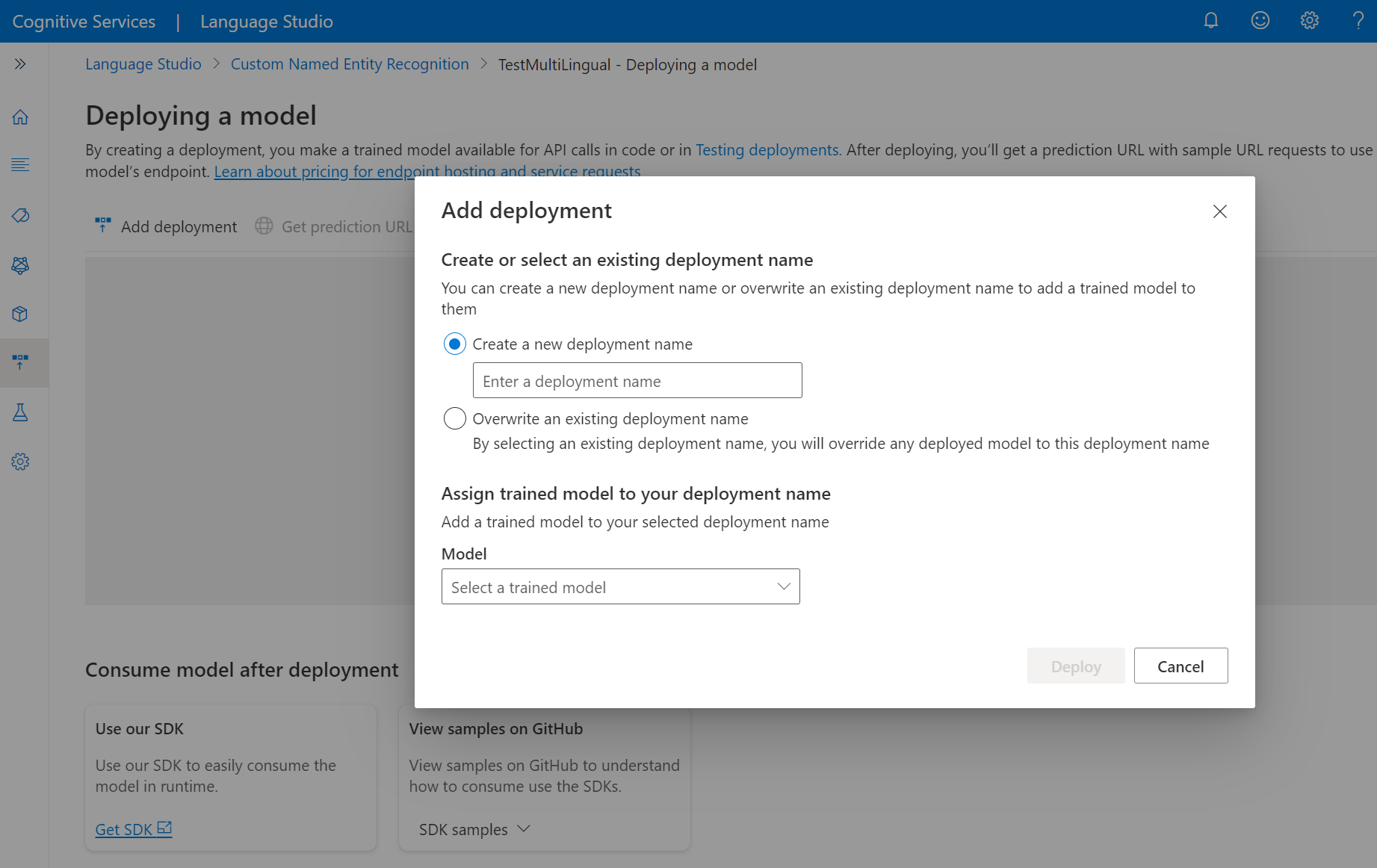
Выберите "Развернуть" , чтобы запустить задание развертывания.
После успешного развертывания рядом с ним появится дата окончания срока действия. Окончание срока действия развертывания означает, что модель становится недоступной для использования в целях прогнозирования, что обычно происходит через двенадцать месяцев после окончания срока действия конфигурации обучения.


Тестирование модели
Развернутую модель можно использовать для извлечения сущностей из текста через API прогнозирования. В этом кратком руководстве вы будете использовать Language Studio для отправки задачи прогнозирования пользовательский анализ текста для здоровья и визуализации результатов. Загруженный ранее пример набора данных содержит некоторые тестовые документы, которые можно использовать на этом шаге.
Чтобы протестировать развернутые модели в Language Studio, выполните следующие действия.
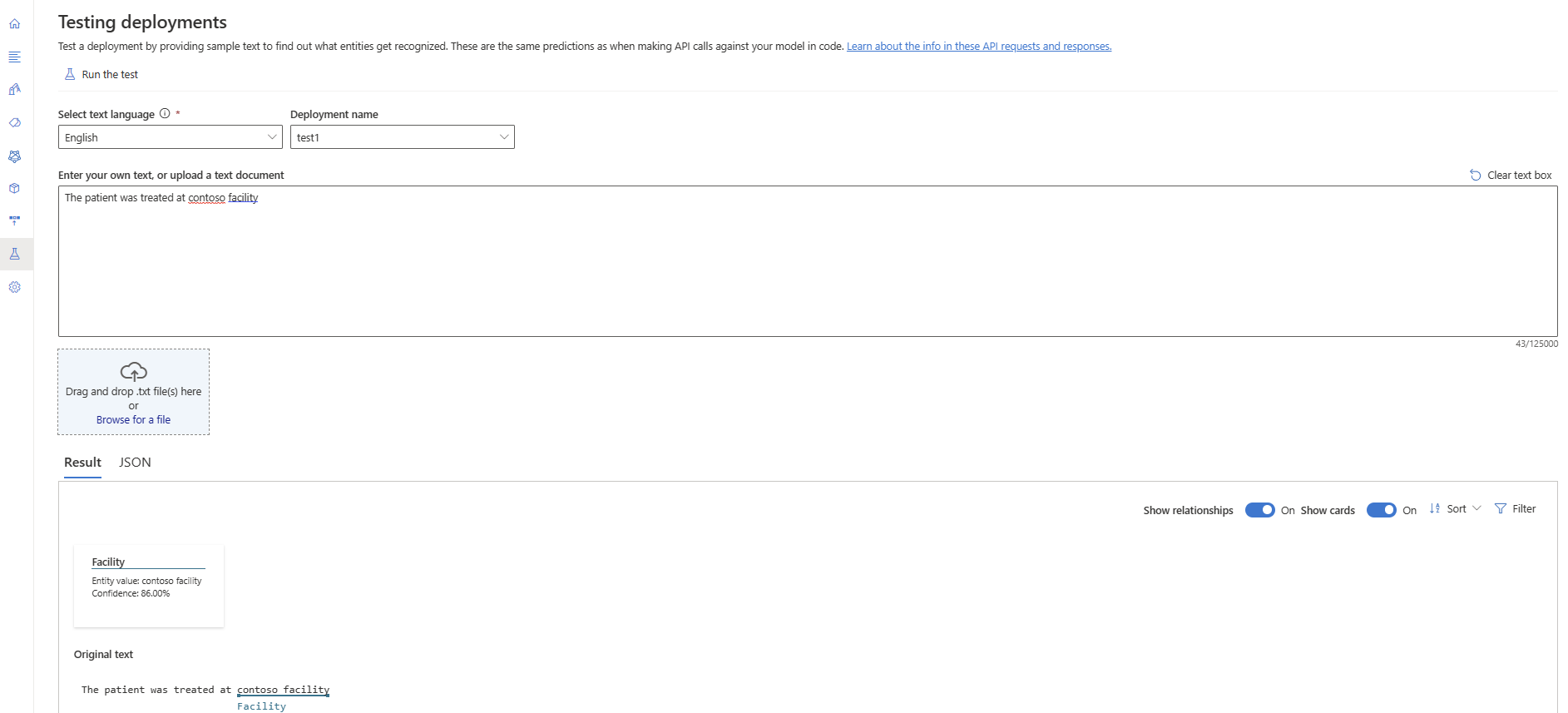
В меню слева выберите Testing deployments (Тестирование развертываний).
Выберите развертывание, которое нужно протестировать. Можно тестировать только модели, назначенные развертываниям.
Выберите развертывание, которое требуется запросить или протестировать, из раскрывающегося списка.
Введите текст, который требуется отправить в запросе, или отправьте файл
.txt, который требуется использовать.Выберите "Запустить тест " в верхнем меню.
На вкладке Result (Результат) можно просмотреть извлеченные из текста сущности и их типы. Вы также можете просмотреть ответ JSON на вкладке JSON .

Очистка ресурсов
Если проект вам больше не нужен, вы можете удалить его с помощью Студии Языка.
- Выберите функцию языковой службы, которую вы используете в верхней части страницы,
- Выберите проект, который требуется удалить
- В верхнем меню выберите Удалить.
Необходимые компоненты
- Подписка Azure — создайте бесплатную учетную запись.
Создание нового ресурса языка ИИ Azure и учетной записи хранения Azure
Прежде чем использовать пользовательский анализ текста для здоровья, необходимо создать ресурс языка искусственного интеллекта Azure, который предоставит учетные данные, необходимые для создания проекта и начала обучения модели. Кроме того, вам потребуется учетная запись хранения Azure, в которую вы отправите набор данных для создания модели.
Внимание
Чтобы быстро приступить к работе, мы рекомендуем создать новый ресурс языка искусственного интеллекта Azure, выполнив действия, описанные в этой статье, что позволит вам создать ресурс языка и создать и /или подключить учетную запись хранения одновременно, что проще, чем позже.
Если вы хотите использовать уже существующий ресурс, его нужно подключить к учетной записи хранения. Дополнительные сведения см. в статье о создании проекта .
Создание ресурса на портале Azure
Войдите в портал Azure, чтобы создать новый ресурс языка искусственного интеллекта Azure.
В появившемся окне выберите настраиваемую классификацию текста и распознавание именованных сущностей из пользовательских функций. Нажмите кнопку "Продолжить", чтобы создать ресурс в нижней части экрана.
Создайте ресурс службы "Язык" с приведенными ниже сведениями.
Имя Описание Подписка Вашу подписку Azure. Группа ресурсов Группа ресурсов, которая будет содержать ваш ресурс. Можно использовать существующую группу или создать новую. Область/регион Регион для ресурса службы "Язык". Например, "Западная часть США 2". Имя. Имя ресурса. Ценовая категория Ценовая категория ресурса Языка. Вы можете использовать уровень "Бесплатный" (F0), чтобы поработать со службой. Примечание.
Если появится сообщение Ваша учетная запись входа не является владельцем выбранной группы ресурсов учетной записи хранения, значит, ваша учетная запись должна иметь роль владельца, назначенную группе ресурсов, — только тогда вы сможете создать ресурс службы "Язык". Обратитесь за помощью к владельцу подписки Azure.
В разделе "Настраиваемая классификация текста" и "Распознавание именованных сущностей" выберите существующую учетную запись хранения или выберите новую учетную запись хранения. Эти значения для учетной записи хранения помогут вам быстро начать работу, но они не всегда подходят для реальных рабочих сред. Чтобы избежать задержек при создании проекта, подключитесь к учетным записям хранения в том же регионе, что и ресурс Языка.
Значение для учетной записи хранения Рекомендуемое значение Storage account name Любое имя Storage account type Standard LRS Убедитесь, что флажок Уведомление об ответственном применении ИИ установлен. В нижней части страницы щелкните Просмотр и создание, а затем нажмите Создать.
Отправка примера данных в контейнер BLOB-объектов
Когда вы создадите учетную запись хранения Azure и подключите ее к ресурсу службы "Язык", нужно будет отправить документы из примера набора данных в корневой каталог контейнера. Эти документы будут использоваться для обучения модели.
Скачайте пример набора данных с GitHub.
Откройте файл ZIP и извлеките папку с документами.
На портале Azure перейдите к созданной учетной записи хранения и выберите ее.
В учетной записи хранения в меню слева выберите Контейнеры под пунктом Хранилище данных. На появившемся экране нажмите + Контейнер. Присвойте контейнеру имя example-data и оставьте Уровень общего доступа, установленный по умолчанию.
Когда контейнер будет создан, выберите его. Затем нажмите кнопку "Отправить", чтобы выбрать
.txtскачанные ранее файлы..json
Предоставленный пример набора данных содержит 12 клинических заметок. Каждая клиническая записка включает в себя несколько медицинских организаций и расположение лечения. Мы будем использовать предварительно созданные сущности для извлечения медицинских сущностей и обучения настраиваемой модели для извлечения расположения лечения с помощью изученных и перечисленных компонентов сущности.
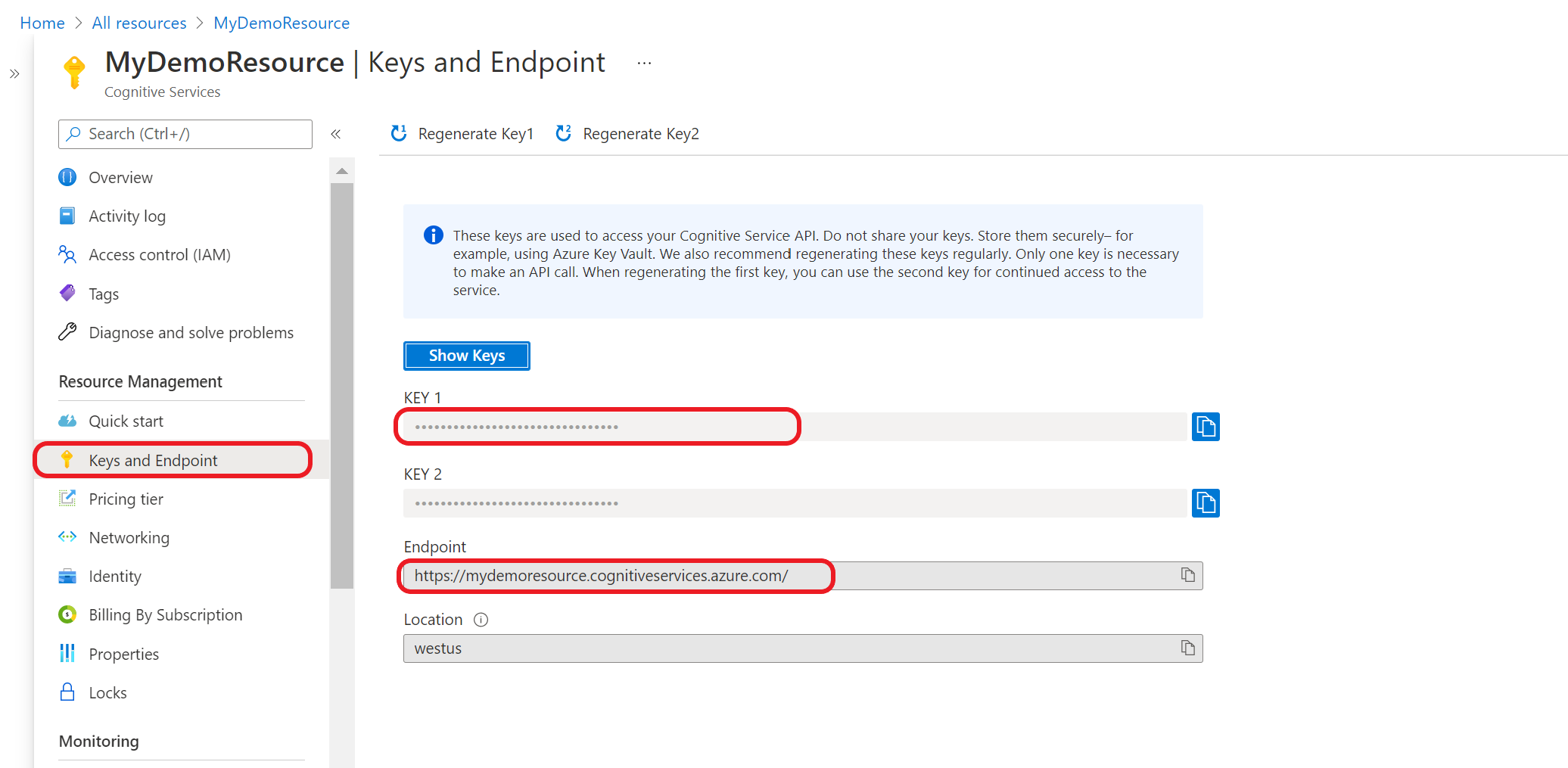
Получение ключей и конечной точки ресурса
Перейдите на страницу обзора ресурса на портале Azure
В меню слева выберите Ключи и конечная точка. Вы будете использовать конечную точку и ключ для запросов API

Создание проекта пользовательский анализ текста для здоровья
После настройки ресурса и учетной записи хранения создайте проект пользовательский анализ текста для здоровья. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Получить доступ к вашему проекту можете только вы и другие пользователи, у которых есть доступ к используемому ресурсу службы "Язык".
Используйте файл меток, скачанный из примера данных на предыдущем шаге, и добавьте его в текст следующего запроса.
Активация задания импорта проектов
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы импортировать файл меток. Убедитесь, что файл меток соответствует допустимому формату.
Если проект с таким именем уже существует, данные этого проекта заменяются.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст
Используйте следующий код JSON в запросе. Замените значения заполнителей ниже собственными значениями.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomHealthcare",
"description": "Trying out custom Text Analytics for health",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomHealthcare",
"entities": [
{
"category": "Entity1",
"compositionSetting": "{COMPOSITION-SETTING}",
"list": {
"sublists": [
{
"listKey": "One",
"synonyms": [
{
"language": "en",
"values": [
"EntityNumberOne",
"FirstEntity"
]
}
]
}
]
}
},
{
"category": "Entity2"
},
{
"category": "MedicationName",
"list": {
"sublists": [
{
"listKey": "research drugs",
"synonyms": [
{
"language": "en",
"values": [
"rdrug a",
"rdrug b"
]
}
]
}
]
}
"prebuilts": "MedicationName"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
multilingual |
true |
Логическое значение, которое позволяет иметь документы на нескольких языках в наборе данных. После развертывания модели вы можете отправить к ней запрос на любом поддерживаемом языке (не обязательно включенном в обучающие документы). См. дополнительные сведения о поддержке нескольких языков. | true |
projectName |
{PROJECT-NAME} |
Имя проекта | myproject |
storageInputContainerName |
{CONTAINER-NAME} |
Имя контейнера | mycontainer |
entities |
Массив, содержащий все типы сущностей в проекте. Это типы сущностей, которые будут извлекаться из документов. | ||
category |
Имя типа сущности, который можно определить для новых определений сущностей или предопределен для предварительно созданных сущностей. | ||
compositionSetting |
{COMPOSITION-SETTING} |
Правило, определяющее, как управлять несколькими компонентами в сущности. Параметры или combineComponents separateComponents. |
combineComponents |
list |
Массив, содержащий все вложенные списки, которые есть в проекте для определенной сущности. Списки можно добавлять в предварительно созданные сущности или новые сущности с помощью наученных компонентов. | ||
sublists |
[] |
Массив, содержащий вложенные списки. Каждый вложенный список является ключом и связанными с ней значениями. | [] |
listKey |
One |
Нормализованное значение списка синонимов для сопоставления с прогнозом. | One |
synonyms |
[] |
Массив со всеми синонимами | синоним |
language |
{LANGUAGE-CODE} |
Строка, указывающая языковой код синонима в подлисте. Если проект является многоязычным проектом и вы хотите поддержать список синонимов для всех языков в проекте, необходимо явно добавить синонимы на каждый язык. Дополнительные сведения о поддерживаемых кодах языков см. в разделе Поддержка языков. | en |
values |
"EntityNumberone", "FirstEntity" |
Список разделенных запятыми строк, которые будут соответствовать точно для извлечения и сопоставления с ключом списка. | "EntityNumberone", "FirstEntity" |
prebuilts |
MedicationName |
Имя предварительно созданного компонента, заполняющего предварительно созданную сущность. Предварительно созданные сущности автоматически загружаются в проект по умолчанию, но их можно расширить с помощью компонентов списка в файле меток. | MedicationName |
documents |
Массив, содержащий все документы в проекте и список сущностей, помеченных в каждом документе. | [] | |
location |
{DOCUMENT-NAME} |
Расположение документов в контейнере хранилища. Так как все документы находятся в корне контейнера, это должно быть имя документа. | doc1.txt |
dataset |
{DATASET} |
Тестовый набор , к которому будет переходить этот файл при разбиение перед обучением. Возможные значения для этого поля: Train и Test. |
Train |
regionOffset |
Позиция символа начала текста (включая сам символ). | 0 |
|
regionLength |
Длина ограничивающего прямоугольника в символах UTF16. При обучении учитываются данные только в этом регионе. | 500 |
|
category |
Тип сущности, связанной с заданным фрагментом текста. | Entity1 |
|
offset |
Начальная позиция текста сущности. | 25 |
|
length |
Длина сущности в символах UTF16. | 20 |
|
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для документа, используемого в проекте. Если проект является многоязычным, выберите код языка большинства документов. Дополнительные сведения о поддерживаемых кодах языков см. в разделе Поддержка языков. | en |
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение operation-location из заголовков ответа. Оно будет иметь следующий формат:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес будет использоваться для получения состояния задания импорта.
Возможные сценарии ошибок для этого запроса:
- выбранный ресурс не имеет необходимых разрешений для учетной записи хранения;
- указанный
storageInputContainerNameне существует; - используется недопустимый код языка или тип кода языка не является строковым;
- Значение
multilingualявляется строкой, а не логическим значением.
Получение сведений о состоянии задания на импорт
Используйте следующий запрос GET, чтобы получить состояние импорта проекта. Замените значения заполнителей ниже собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Значение заголовка location, полученное на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Обучение модели
Как правило, после создания проекта вы маркируете документы в подключенном к проекту контейнере. В этом кратком руководстве вы импортировали пример набора данных с тегами и инициализировали проект, используя пример JSON-файла с тегами.
Запуск задания обучения
После импорта проекта можно начать обучение модели.
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание обучения. Замените значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. Модель получается {MODEL-NAME} после завершения обучения. Только успешные задания обучения создают модели.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Имя модели, назначенное модели после успешного обучения. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Это версия модели, используемая для обучения модели. | 2022-05-01 |
| evaluationOptions | Возможность разделять данные по наборам для обучения и тестирования. | {} |
|
| kind | percentage |
Методы разделения. Возможные значения: percentage или manual. Дополнительные сведения см. в статье об обучении модели. |
percentage |
| trainingSplitPercentage | 80 |
Процент помеченных тегами данных, которые будут включены в набор для обучения. Рекомендуемое значение — 80. |
80 |
| testingSplitPercentage | 20 |
Процент помеченных тегами данных, которые будут включены в набор для тестирования. Рекомендуемое значение — 20. |
20 |
Примечание.
trainingSplitPercentage и testingSplitPercentage требуются только в том случае, если для Kind задано значение percentage, а сумма процентных значений должна быть равна 100.
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение location из заголовков ответа. Форматируется следующим образом:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес позволяет получить текущее состояние обучения.
Получение состояния задания обучения
Обучение может занять от 10 до 30 минут для этого примера набора данных. Следующий запрос можно использовать для регулярного опроса состояния задания обучения, пока оно не будет успешно завершено.
Используйте следующий запрос GET, чтобы получить состояние хода обучения модели. Замените значения заполнителей ниже собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Значение заголовка location, полученное на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Развертывание модели
Обычно после обучения модели изучаются сведения об оценке и вносятся необходимые улучшения. В этом кратком руководстве вы просто развернете модель и предоставите себе к ней доступ в студии службы "Язык". Можно также вызвать API прогнозирования.
Запуск задания развертывания
Отправьте запрос PUT, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание развертывания. Замените значения заполнителей ниже собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | staging |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. Используйте имя модели, назначаемое развертыванию.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Имя модели, которое будет назначено развертыванию. Имена можно назначить только успешно обученным моделям. Это значение учитывает регистр. | myModel |
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение operation-location из заголовков ответа. Оно будет иметь следующий формат:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес можно использовать для получения состояния развертывания.
Получение состояния задания развертывания
Используйте следующий запрос GET для запроса состояния задания развертывания. Используйте URL-адрес, полученный на предыдущем шаге, или замените приведенные ниже значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | staging |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Это значение находится в заголовке location, полученном на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
При отправке запроса вы получите следующий запрос. Продолжайте опрос этой конечной точки до тех пор, пока значение параметра Состояние не изменится на "Выполнено". Необходимо получить код 200, указывающий на успешное выполнение запроса.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Прогнозирование с помощью обученной модели
Развернутую модель можно использовать для извлечения сущностей из текста через API прогнозирования. Загруженный ранее пример набора данных содержит некоторые тестовые документы, которые можно использовать на этом шаге.
Отправка задачи пользовательский анализ текста для здоровья
Используйте этот запрос POST, чтобы запустить пользовательскую Анализ текста для задачи извлечения работоспособности.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Текст
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomHealthcare",
"taskName": "Custom TextAnalytics for Health Test",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
displayName |
{JOB-NAME} |
Имя задания. | MyJobName |
documents |
[{},{}] | Список документов для запуска задач. | [{},{}] |
id |
{DOC-ID} |
Имя или идентификатор документа. | doc1 |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для документа. Если этот ключ не указан, служба будет использовать язык по умолчанию проекта, выбранный во время создания проекта. Список всех поддерживаемых языков см. в статье Поддержка языков. | en-us |
text |
{DOC-TEXT} |
Задача документа, для которого будут выполняться задачи. | Lorem ipsum dolor sit amet |
tasks |
Список задач, которые мы хотим выполнить. | [] |
|
taskName |
Custom Text Analytics for Health Test |
Имя задачи | Custom Text Analytics for Health Test |
kind |
CustomHealthcare |
Тип проекта или задачи, который мы пытаемся выполнить | CustomHealthcare |
parameters |
Список параметров, которые нужно передать задаче. | ||
project-name |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | prod |
Response
Вы получите ответ 202, обозначающий успешную отправку задачи. Извлеките значение operation-location из заголовков ответа.
operation-location имеет следующий формат:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Этот URL-адрес можно использовать для запроса состояния завершения задачи и получения результатов после ее завершения.
Получение результатов выполнения задачи
Используйте следующий запрос GET для запроса состояния или результатов пользовательской задачи распознавания сущностей.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Текст ответа
Ответ — это документ JSON со следующими параметрами.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomHealthcareLROResults",
"taskName": "Custom Text Analytics for Health Test",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1",
"confidenceScore": 0.98
},
{
"entityComponentInformation": [
{
"entityComponentKind": "listComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1.Dictionary",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 16,
"length": 9,
"text": "entity two",
"category": "Entity2",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 37,
"length": 9,
"text": "ibuprofen",
"category": "MedicationName",
"confidenceScore": 1,
"assertion": {
"certainty": "negative"
},
"name": "ibuprofen",
"links": [
{
"dataSource": "UMLS",
"id": "C0020740"
},
{
"dataSource": "AOD",
"id": "0000019879"
},
{
"dataSource": "ATC",
"id": "M01AE01"
},
{
"dataSource": "CCPSS",
"id": "0046165"
},
{
"dataSource": "CHV",
"id": "0000006519"
},
{
"dataSource": "CSP",
"id": "2270-2077"
},
{
"dataSource": "DRUGBANK",
"id": "DB01050"
},
{
"dataSource": "GS",
"id": "1611"
},
{
"dataSource": "LCH_NW",
"id": "sh97005926"
},
{
"dataSource": "LNC",
"id": "LP16165-0"
},
{
"dataSource": "MEDCIN",
"id": "40458"
},
{
"dataSource": "MMSL",
"id": "d00015"
},
{
"dataSource": "MSH",
"id": "D007052"
},
{
"dataSource": "MTHSPL",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI",
"id": "C561"
},
{
"dataSource": "NCI_CTRP",
"id": "C561"
},
{
"dataSource": "NCI_DCP",
"id": "00803"
},
{
"dataSource": "NCI_DTP",
"id": "NSC0256857"
},
{
"dataSource": "NCI_FDA",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI_NCI-GLOSS",
"id": "CDR0000613511"
},
{
"dataSource": "NDDF",
"id": "002377"
},
{
"dataSource": "PDQ",
"id": "CDR0000040475"
},
{
"dataSource": "RCD",
"id": "x02MO"
},
{
"dataSource": "RXNORM",
"id": "5640"
},
{
"dataSource": "SNM",
"id": "E-7772"
},
{
"dataSource": "SNMI",
"id": "C-603C0"
},
{
"dataSource": "SNOMEDCT_US",
"id": "387207008"
},
{
"dataSource": "USP",
"id": "m39860"
},
{
"dataSource": "USPMG",
"id": "MTHU000060"
},
{
"dataSource": "VANDF",
"id": "4017840"
}
]
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 30,
"length": 6,
"text": "100 mg",
"category": "Dosage",
"confidenceScore": 0.98
}
],
"relations": [
{
"confidenceScore": 1,
"relationType": "DosageOfMedication",
"entities": [
{
"ref": "#/documents/0/entities/1",
"role": "Dosage"
},
{
"ref": "#/documents/0/entities/0",
"role": "Medication"
}
]
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
| Ключ | Образец значения | Description |
|---|---|---|
| Объекты | [] | Массив, содержащий все извлеченные сущности. |
| entityComponentKind | prebuiltComponent |
Переменная, указывающая, какой компонент вернул определенную сущность. Возможные значения: prebuiltComponent, learnedComponent, listComponent |
| offset | 0 |
Число, обозначающее начальную точку извлеченной сущности путем индексирования по символам |
| length | 10 |
Число, обозначающее длину извлеченной сущности в количестве символов. |
| text | first entity |
Текст, извлеченный для определенной сущности. |
| Категория | MedicationName |
Имя типа сущности или категории, соответствующей извлеченного текста. |
| confidenceScore | 0.9 |
Число, обозначающее уровень определенности модели извлеченной сущности в диапазоне от 0 до 1 с более высоким числом, обозначающим более высокую уверенность. |
| assertion | certainty |
Утверждения, связанные с извлеченной сущностью. Утверждения поддерживаются только для предварительно созданных Анализ текста для сущностей работоспособности. |
| name | Ibuprofen |
Нормализованное имя для связи сущностей, связанной с извлеченной сущностью. Связывание сущностей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| ссылки | [] | Массив, содержащий все результаты связи сущностей , связанной с извлеченной сущностью. Связывание сущностей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| dataSource | UMLS |
Эталонный стандарт, полученный от связывания сущностей, связанной с извлеченной сущностью. Связывание сущностей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| ID | C0020740 |
Ссылочный код, связанный с извлеченной сущностью, связанной с извлеченным источником данных. Связывание сущностей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| Отношения | [] | Массив, содержащий все извлеченные связи. Извлечение связей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| relationType | DosageOfMedication |
Категория извлеченной связи. Извлечение связей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
| entities | "Dosage", "Medication" |
Сущности, связанные с извлеченной связью. Извлечение связей поддерживается только для предварительно созданных Анализ текста для сущностей работоспособности. |
Очистка ресурсов
Если проект больше не нужен, его можно удалить с помощью следующего запроса DELETE. Замените значения заполнителей собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ к ресурсу. Используется для проверки подлинности запросов API. |
После отправки запроса API вы получите ответ 202, означающий успешное выполнение (развертывание удалено). Ответ будет содержать заголовок Operation-Location, используемый для проверки состояния задания.
Следующие шаги
После создания модели извлечения сущностей можно выполнять следующие действия.
При создании собственных проектов пользовательский анализ текста для здоровья используйте статьи, чтобы узнать больше о метке данных, обучении и использовании модели более подробно: