Модель чтения с помощью аналитики документов
Внимание
- Выпуски общедоступной предварительной версии Document Intelligence предоставляют ранний доступ к функциям, которые находятся в активной разработке. Функции, подходы и процессы могут изменяться до общедоступной доступности на основе отзывов пользователей.
- Общедоступная предварительная версия клиентских библиотек Аналитики документов по умолчанию использует REST API версии 2024-07-31-preview.
- Общедоступная предварительная версия 2024-07-31-preview в настоящее время доступна только в следующих регионах Azure. Обратите внимание, что пользовательская модель создания (извлечение полей документов) в AI Studio доступна только в регионе "Северная часть США":
- Восточная часть США
- Западная часть США2
- Западная Европа
- Северная часть США
Это содержимое относится к: версии 4.0 (предварительная версия) | Предыдущие версии:![]()
![]() v3.1 (GA) версии 3.0 (GA)
v3.1 (GA) версии 3.0 (GA) ![]()
Это содержимое относится к: версии 4.0 (предварительная версия) | Предыдущие версии:![]()
![]() v3.1 (GA) версии 3.0 (GA)
v3.1 (GA) версии 3.0 (GA) ![]()
Примечание.
Для извлечения текста из внешних изображений, таких как метки, уличные знаки и плакаты, используйте функцию анализа изображений ИИ Azure версии 4.0 , оптимизированную для общих, недокументированных изображений с улучшенным производительностью синхронным API, что упрощает внедрение OCR в сценарии взаимодействия с пользователем.
Модель оптического распознавания символов чтения документов (OCR) выполняется в более высоком разрешении, чем azure AI Vision Read и извлекает печатный и рукописный текст из документов PDF и сканированных изображений. Она также включает поддержку извлечения текста из документов Microsoft Word, Excel, PowerPoint и HTML. Он обнаруживает абзацы, текстовые строки, слова, расположения и языки. Модель чтения — это базовый механизм OCR для других предварительно созданных моделей аналитики документов, таких как макет, общий документ, счет, квитанция, удостоверение (идентификатор), карточка медицинского страхования, W2 в дополнение к пользовательским моделям.
Что такое оптическое распознавание символов?
Оптическое распознавание символов (OCR) для документов оптимизировано для больших текстовых документов в нескольких форматах файлов и глобальных языках. Он включает такие функции, как сканирование изображений документов с более высоким разрешением, чтобы лучше обрабатывать меньший и плотный текст; обнаружение абзаца; и управление заполненными формами. Возможности OCR также включают расширенные сценарии, такие как одинарные поля символов и точное извлечение ключевых полей, часто найденных в счетах, квитанциях и других предварительно созданных сценариях.
Варианты разработки (версия 4)
Аналитика документов версии 4.0 (2024-07-31-preview) поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Чтение модели OCR | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-read |
Требования к входным данным (версия 4)
Поддерживаемые форматы файлов:
Модель PDF Изображение: JPEG/JPG, ,BMPPNGTIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту
8точки в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ не более 10 000 страниц. Для 2024-07-31-preview и более поздних версий общий размер обучающих данных составляет2ГБ с максимальным количеством 10 000 страниц.
Начало работы с моделью чтения (версия 4)
Попробуйте извлечь текст из форм и документов с помощью Document Intelligence Studio. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр аналитики документов в портал Azure. Вы можете использовать ценовую категорию "Бесплатный" (
F0), чтобы поработать со службой. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.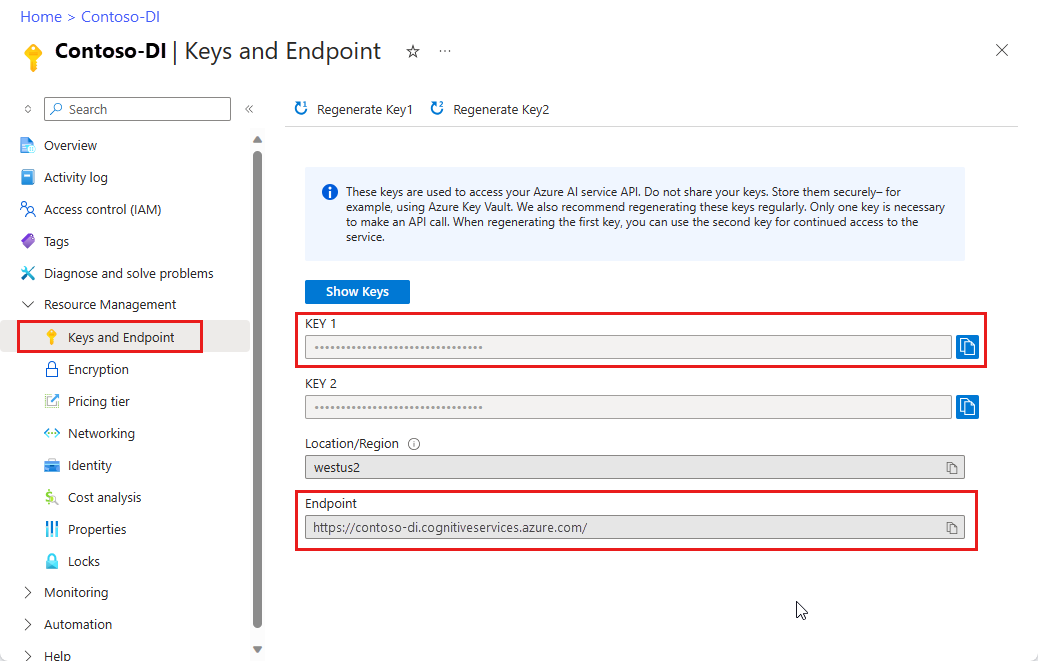
Примечание.
В настоящее время Студия аналитики документов не поддерживает форматы файлов Microsoft Word, Excel, PowerPoint и HTML.
Пример документа, обработанный с помощью Document Intelligence Studio
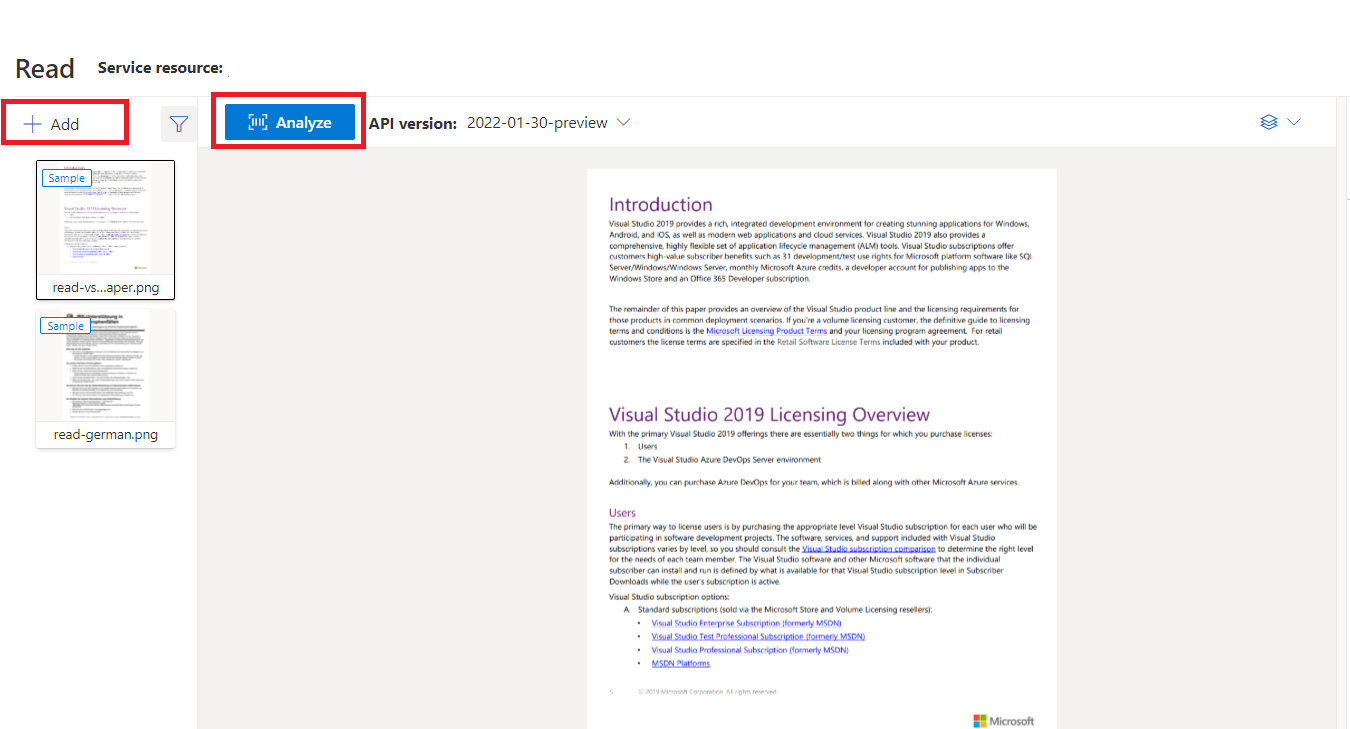
На домашней странице Document Intelligence Studio выберите "Чтение".
Вы можете проанализировать пример документа или отправить собственные файлы.
Нажмите кнопку "Выполнить анализ", а при необходимости настройте параметры анализа:

Поддерживаемые языки и языковые параметры (версия 4)
См. страницу "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Извлечение данных (версия 4)
Примечание.
Microsoft Word и HTML-файл поддерживаются в версии 4.0. По сравнению с PDF и изображениями ниже функции не поддерживаются:
- Для каждого объекта страницы нет угла, ширины и высоты и единицы.
- Для каждого обнаруженного объекта нет ограничивающего многоугольника или ограничивающего региона.
- Диапазон страниц (
pages) не поддерживается в качестве параметра. - Нет
linesобъекта.
Pdf-файлы, доступные для поиска
Возможность PDF с возможностью поиска позволяет преобразовать аналоговый PDF-файл( например, сканированный PDF-файл в PDF-файл с внедренным текстом). Внедренный текст позволяет выполнять поиск глубокого текста в извлеченных содержимом PDF путем перекладывания обнаруженных текстовых сущностей на вершину файлов изображений.
Внимание
- В настоящее время возможность поиска PDF поддерживается только моделью
prebuilt-readчтения OCR. При использовании этой функции укажитеmodelIdзначение asprebuilt-read, так как другие типы моделей возвращают ошибку для этой предварительной версии. - Формат PDF для поиска включен в модель 2024-07-31-preview
prebuilt-readбез дополнительных затрат для создания выходных данных PDF, доступных для поиска.
Использование pdf-файлов, доступных для поиска
Чтобы использовать pdf-файл, доступный POST для поиска, выполните запрос с помощью Analyze операции и укажите выходной формат следующим образом pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Опрос по завершении Analyze операции. После завершения операции отправьте GET запрос на получение формата Analyze PDF результатов операции.
После успешного завершения PDF-файл можно получить и скачать как application/pdf. Эта операция позволяет напрямую загружать внедренную текстовую форму PDF вместо JSON в кодировке Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Параметр Pages
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего страниц до 3000 символов |
| Excel (XLSX) | Каждый лист = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего страниц до 3000 символов |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Использование страниц для извлечения текста
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Извлечение абзаца
Модель OCR чтения в Document Intelligence извлекает все определенные блоки текста в paragraphs коллекции как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет текстовый блок и включает извлеченный текст какcontent и ограничивающие polygon координаты. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content , содержающем полный текст документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Извлечение текста, строк и слов
Модель OCR чтения извлекает печатный и рукописный текст стиля как lines и words. Модель выводит ограничивающие polygon координаты и confidence для извлеченных слов. Коллекция styles включает любой рукописный стиль для строк, если они обнаружены вместе с диапазонами, указывающими на связанный текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML модель чтения документов версии 3.1 и более поздних версий извлекает весь внедренный текст как есть. Тексты экстракированы как слова и абзацы. Внедренные образы не поддерживаются.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Извлечение стиля рукописного ввода
Ответ включает классификацию текста, является ли каждая строка входного текста рукописной или нет, а также оценку достоверности. Дополнительные сведения см. в статье о поддержке рукописного языка. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если вы включили возможность добавления шрифта и стиля, вы также получите результат шрифта или стиля в составе styles объекта.
Дальнейшие действия версии 4.0
Выполните краткое руководство по анализу документов:
Ознакомьтесь с нашим REST API:
Дополнительные примеры на сайте GitHub:
Это содержимое относится к: версия 3.1 (GA) | Последняя версия: ![]()
![]() версия 4.0 (предварительная версия) | Предыдущие версии:
версия 4.0 (предварительная версия) | Предыдущие версии: ![]() v3.0
v3.0
Это содержимое относится к: версии 3.0 (GA) | Последние версии:![]()
![]() версии 4.0 (предварительная версия)
версии 4.0 (предварительная версия)![]() версии 3.1
версии 3.1
Примечание.
Для извлечения текста из внешних изображений, таких как метки, уличные знаки и плакаты, используйте функцию анализа изображений ИИ Azure версии 4.0 , оптимизированную для общих, недокументированных изображений с улучшенным производительностью синхронным API, что упрощает внедрение OCR в сценарии взаимодействия с пользователем.
Модель оптического распознавания символов чтения документов (OCR) выполняется в более высоком разрешении, чем azure AI Vision Read и извлекает печатный и рукописный текст из документов PDF и сканированных изображений. Она также включает поддержку извлечения текста из документов Microsoft Word, Excel, PowerPoint и HTML. Он обнаруживает абзацы, текстовые строки, слова, расположения и языки. Модель чтения — это базовый механизм OCR для других предварительно созданных моделей аналитики документов, таких как макет, общий документ, счет, квитанция, удостоверение (идентификатор), карточка медицинского страхования, W2 в дополнение к пользовательским моделям.
Что такое OCR для документов?
Оптическое распознавание символов (OCR) для документов оптимизировано для больших текстовых документов в нескольких форматах файлов и глобальных языках. Он включает такие функции, как сканирование изображений документов с более высоким разрешением, чтобы лучше обрабатывать меньший и плотный текст; обнаружение абзаца; и управление заполненными формами. Возможности OCR также включают расширенные сценарии, такие как одинарные поля символов и точное извлечение ключевых полей, часто найденных в счетах, квитанциях и других предварительно созданных сценариях.
Варианты разработки
Аналитика документов версии 3.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Чтение модели OCR | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-read |
Аналитика документов версии 3.0 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Model ID |
|---|---|---|
| Чтение модели OCR | • Аналитика документов• REST API • ПАКЕТ SDK для C# • Пакет SDK для Python• Пакет SDK для Java • Пакет SDK java для JavaScript |
prebuilt-read |
Требования к входным данным
Поддерживаемые форматы файлов:
Модель PDF Изображение: JPEG/JPG, ,BMPPNGTIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту
8точки в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ не более 10 000 страниц. Для 2024-07-31-preview и более поздних версий общий размер обучающих данных составляет2ГБ с максимальным количеством 10 000 страниц.
Начало работы с моделью чтения
Попробуйте извлечь текст из форм и документов с помощью Document Intelligence Studio. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр аналитики документов в портал Azure. Вы можете использовать ценовую категорию "Бесплатный" (
F0), чтобы поработать со службой. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.
Примечание.
В настоящее время Студия аналитики документов не поддерживает форматы файлов Microsoft Word, Excel, PowerPoint и HTML.
Пример документа, обработанный с помощью Document Intelligence Studio
На домашней странице Document Intelligence Studio выберите "Чтение".
Вы можете проанализировать пример документа или отправить собственные файлы.
Нажмите кнопку "Выполнить анализ", а при необходимости настройте параметры анализа:
Поддерживаемые языки и языковые стандарты
См. страницу "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Извлечение данных
Примечание.
Microsoft Word и HTML-файл поддерживаются в версиях 3.1 и более поздних версий. По сравнению с PDF и изображениями ниже функции не поддерживаются:
- Для каждого объекта страницы нет угла, ширины и высоты и единицы.
- Для каждого обнаруженного объекта нет ограничивающего многоугольника или ограничивающего региона.
- Диапазон страниц (
pages) не поддерживается в качестве параметра. - Нет
linesобъекта.
Pdf-файл, доступный для поиска
Возможность PDF с возможностью поиска позволяет преобразовать аналоговый PDF-файл( например, сканированный PDF-файл в PDF-файл с внедренным текстом). Внедренный текст позволяет выполнять поиск глубокого текста в извлеченных содержимом PDF путем перекладывания обнаруженных текстовых сущностей на вершину файлов изображений.
Внимание
- В настоящее время возможность поиска PDF поддерживается только моделью
prebuilt-readчтения OCR. При использовании этой функции укажитеmodelIdзначение asprebuilt-read, так как другие типы моделей возвращают ошибку для этой предварительной версии. - Формат PDF для поиска включен в модель 2024-07-31-preview
prebuilt-readбез дополнительных затрат для создания выходных данных PDF, доступных для поиска.- В настоящее время доступный для поиска PDF-файл поддерживает только pdf-файлы в качестве входных данных. Поддержка других типов файлов, таких как файлы изображений, будет доступна позже.
Использование PDF с возможностью поиска
Чтобы использовать pdf-файл, доступный POST для поиска, выполните запрос с помощью Analyze операции и укажите выходной формат следующим образом pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Опрос по завершении Analyze операции. После завершения операции отправьте GET запрос на получение формата Analyze PDF результатов операции.
После успешного завершения PDF-файл можно получить и скачать как application/pdf. Эта операция позволяет напрямую загружать внедренную текстовую форму PDF вместо JSON в кодировке Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Страницы
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего страниц до 3000 символов |
| Excel (XLSX) | Каждый лист = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего страниц до 3000 символов |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Выбор страниц для извлечения текста
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Абзацы
Модель OCR чтения в Document Intelligence извлекает все определенные блоки текста в paragraphs коллекции как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет текстовый блок и включает извлеченный текст какcontent и ограничивающие polygon координаты. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content , содержающем полный текст документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Текст, строки и слова
Модель OCR чтения извлекает печатный и рукописный текст стиля как lines и words. Модель выводит ограничивающие polygon координаты и confidence для извлеченных слов. Коллекция styles включает любой рукописный стиль для строк, если они обнаружены вместе с диапазонами, указывающими на связанный текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML модель чтения документов версии 3.1 и более поздних версий извлекает весь внедренный текст как есть. Тексты экстракированы как слова и абзацы. Внедренные образы не поддерживаются.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Стиль рукописного текста для текстовых строк
Ответ включает классификацию текста, является ли каждая строка входного текста рукописной или нет, а также оценку достоверности. Дополнительные сведения см. в статье о поддержке рукописного языка. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если вы включили возможность добавления шрифта и стиля, вы также получите результат шрифта или стиля в составе styles объекта.
Следующие шаги
Выполните краткое руководство по анализу документов:
Ознакомьтесь с нашим REST API:
Дополнительные примеры на сайте GitHub: