Что такое модель макета аналитики документов?
Это содержимое относится к:![]() версии 4.0 (GA) | Предыдущие версии:
версии 4.0 (GA) | Предыдущие версии:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Модель макета аналитики документов — это расширенный API анализа документов на основе машинного обучения, доступный в облаке Аналитики документов. Это позволяет принимать документы в различных форматах и возвращать структурированные представления данных документов. Она сочетает в себе возможности улучшенной версии мощного оптического распознавания символов (OCR) с моделями глубокого обучения для извлечения текста, таблиц, меток выделения и структуры документа.
Анализ макета структуры документа
Анализ макета структуры документов — это процесс анализа документа для извлечения интересующих регионов и их взаимодействия. Цель состоит в том, чтобы извлечь текст и структурные элементы со страницы, чтобы создать более семантические модели. В макете документа есть два типа ролей:
- Геометрические роли: текст, таблицы, цифры и знаки выделения являются примерами геометрических ролей.
- Логические роли: заголовки, заголовки и нижние колонтитулы являются примерами логических ролей текста.
На следующем рисунке показаны типичные компоненты на изображении примера страницы.

Варианты разработки
Аналитика документов версии 4.0: 2024-11-30 (GA) поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы | Идентификатор модели |
|---|---|---|
| Модель макета | • Студия интеллектуальной обработки документов • REST API • Пакет SDK для C# • Пакет SDK для Python • Пакет SDK для Java • Пакет SDK для JavaScript |
предварительно-созданный макет |
Поддерживаемые языки
См . статью "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Поддерживаемые типы файлов
Модель макета аналитики документов версии 4.0: 2024-11-30 (GA) поддерживает следующие форматы файлов:
| Модель | Изображение: JPEG/JPG, , PNGBMPTIFFHEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Макет | ✔ | ✔ | ✔ |
Требования к входным данным
Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту размером
8пунктов при разрешении 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ и с максимальным количеством 10 000 страниц. Для2024-11-30(GA) общий размер тренировочных данных составляет2ГБ при максимуме 10 000 страниц.
Дополнительные сведения об использовании модели, квотах и ограничениях служб см. в разделеоб ограничениях служб.
Начало работы с моделью макета
Узнайте, как данные, включая текст, таблицы, заголовки таблиц, метки выделения и сведения о структуре, извлекаются из документов с помощью аналитики документов. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр Document Intelligence на портале Azure. Вы можете использовать бесплатный тариф (
F0), чтобы попробовать сервис. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.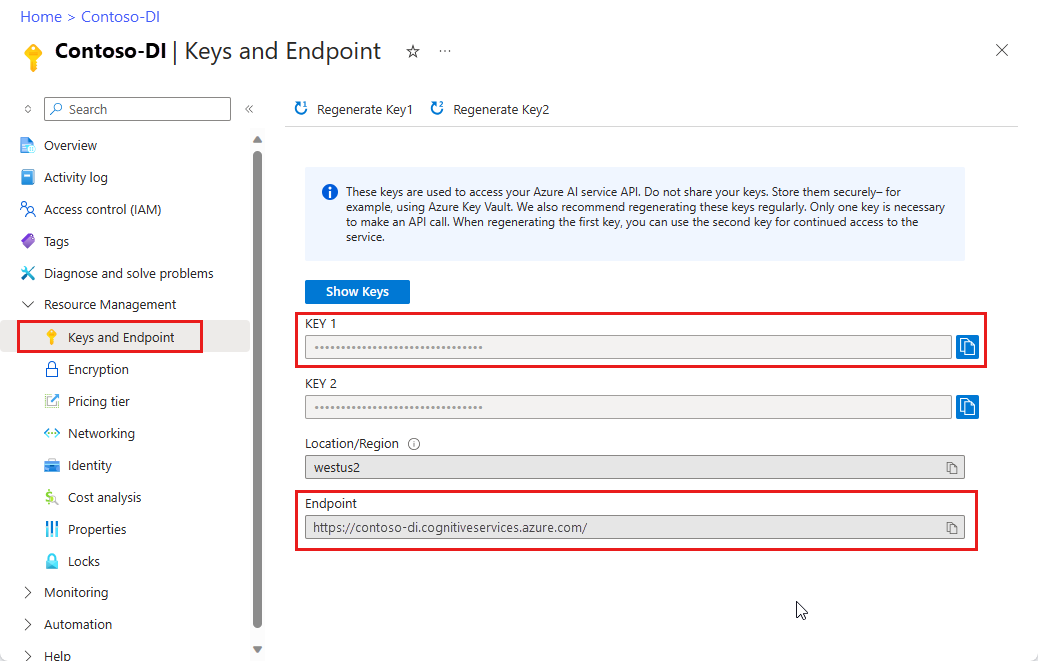
После получения ключа и конечной точки используйте следующие параметры разработки для создания и развертывания приложений аналитики документов:
Извлечение данных
Модель макета извлекает структурные элементы из документов. Ниже приведены описания этих структурных элементов с рекомендациями по их извлечению из входных данных документа:
- Страницы
- Абзацы
- Текст, строки и слова
- Метки выделения
- Таблицы
- Результат в формате markdown
- Цифра
- Разделы
Запустите анализ документа образца макета в Document Intelligence Studio, а затем перейдите на вкладку результатов, чтобы получить доступ к полным выходным данным JSON.

Страницы
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая из которых содержит до 3000 символов |
| Excel (XLSX) | Каждая таблица = 1 единица страницы, встроенные или связанные изображения не поддерживаются. | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая до 3000 символов |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Извлечение выбранных страниц
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Абзацы
Модель макета извлекает все идентифицированные блоки текста в коллекции paragraphs как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет текстовый блок и .. /включает извлеченный текст какcontentи ограничивающие polygon координаты. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content, содержащем весь текст из документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Роли абзаца
Новое обнаружение объектов на основе машинного обучения извлекает логические роли, такие как заголовки, заголовки разделов, заголовки страницы, нижние колонтитулы страницы и многое другое. Модель макета аналитики документов назначает определенные текстовые блоки в paragraphs коллекции с их специализированной ролью или типом, прогнозируемым моделью. Рекомендуется использовать роли для абзацев с неструктурированными документами, чтобы понять структуру извлеченного контента для более глубокого семантического анализа. Поддерживаются следующие роли абзаца:
| Прогнозируемая роль | Description | Поддерживаемые типы файлов |
|---|---|---|
title |
Основные заголовки на странице | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Одно или несколько подзаголовок на странице | pdf, image, docx, xlsx, html |
footnote |
Текст в нижней части страницы | pdf, изображение |
pageHeader |
Текст по верхнему краю страницы | pdf, image, docx |
pageFooter |
Текст по нижнему краю страницы | pdf, image, docx, pptx, html |
pageNumber |
Номер страницы | pdf, изображение |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Текст, строки и слова
Модель макета документа в Аналитике документов извлекает печатный и рукописный текст стиля как lines и words. Коллекция styles включает любые рукописные стили для линий, если они обнаружены вместе с диапазонами, указывающими на связанный текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML макетная модель Document Intelligence версии 4.0 2024-11-30 (GA) извлекает весь внедренный текст как есть. Тексты извлекаются как слова и абзацы. Внедренные образы не поддерживаются.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Стиль рукописного текста для текстовых строк
Ответ .. /включает классификацию того, является ли каждая текстовая строка стилем рукописного ввода или нет, а также оценка достоверности. Дополнительные сведения. См. Поддержка рукописного ввода. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если включить возможность добавления шрифта и стиля, вы также получите результат шрифта и стиля в составе styles объекта.
Отметки выбора
Модель макета также извлекает метки выбора из документов. Извлеченные метки выделения отображаются в коллекции pages для каждой страницы. Сюда входят ограничивающие метки polygon, confidence и метки выделения state (selected/unselected). Текстовое представление (то есть :selected: и :unselected) также включается в качестве начального индекса (offset) и length ссылается на свойство верхнего уровня content , содержащее полный текст документа.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Таблицы
Извлечение таблиц является ключевым требованием для обработки документов, содержащих большие объемы данных, обычно отформатированных в виде таблиц. Модель макета извлекает таблицы в pageResults разделе результатов JSON. Извлеченные сведения о таблице .. /включает количество столбцов и строк, диапазона строк и диапазона столбцов. Каждая ячейка с ограничивающим многоугольником выводится вместе с информацией о том, распознается ли область как columnHeader или нет. Модель поддерживает извлечение таблиц, которые поворачиваются. Каждая ячейка таблицы содержит индекс строки и столбца и координаты ограничивающего многоугольника. Для текста ячейки модель выводит сведения span, содержащие начальный индекс (offset). Модель также выводит length в содержимое верхнего уровня, которое содержит полный текст документа.
Ниже приведены некоторые факторы, которые следует учитывать при использовании функции извлечения данных аналитики документов:
Являются ли данные, которые вы хотите извлечь, представленными в виде таблицы, и является ли структура таблицы значимой?
Может ли данные помещаться в двухмерную сетку, если данные не в формате таблицы?
Охватывают ли таблицы несколько страниц? Если это так, чтобы избежать необходимости пометить все страницы, разделите PDF на страницы, прежде чем отправлять его в аналитику документов. После анализа обработайте страницы так, чтобы они оказались в одной таблице.
Если вы создаете пользовательские модели, обратитесь к табличным полям . Динамические таблицы имеют переменное количество строк для каждого столбца. Фиксированные таблицы имеют постоянное количество строк для каждого столбца.
Примечание.
- Анализ таблиц не поддерживается, если входной файл — XLSX.
- Для
2024-11-30(GA) ограничивающие области для фигур и таблиц охватывают только основное содержимое и исключают связанные субтитры и сноски.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Вывести ответ в формате markdown
API макета может выводить извлеченный текст в формате markdown. Используйте outputContentFormat=markdown, чтобы указать формат выходных данных в markdown. Содержимое markdown выводится как часть раздела content.
Примечание.
Для версии 4.0 2024-11-30 (GA) представление таблиц изменяется на HTML-таблицы, чтобы обеспечить отрисовку объединенных ячеек, заголовков с несколькими строками и т. д. Другое связанное изменение заключается в использовании символов флажков Юникода ☒ и ☐ для обозначения выбора вместо :selected: и :unselected:. Это обновление означает, что содержимое полей меток выделения содержит :selected: , хотя их диапазоны относятся к символам Юникода в диапазоне верхнего уровня.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Числа
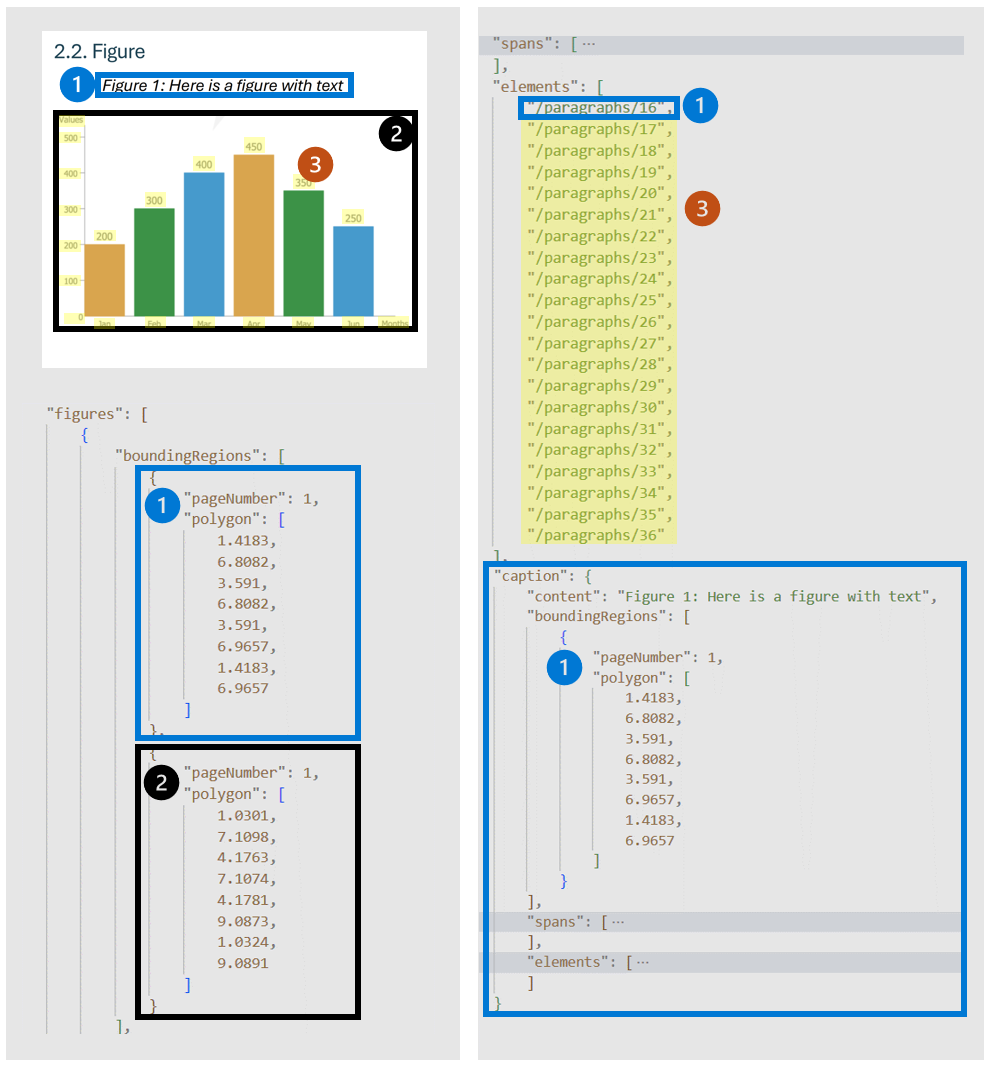
Цифры (диаграммы, изображения) в документах играют важную роль в дополнении и улучшении текстового содержимого, предоставляя визуальные представления, которые помогают понять сложную информацию. Объект фигуры, обнаруженный моделью макета, имеет такие ключевые свойства, как boundingRegions (пространственные местоположения фигуры на страницах документа, включая номер страницы и координаты многоугольника, которые очерчивают границу фигуры), spans (сведения о диапазонах текста, связанных с фигурой, указывая их смещение и длину в тексте документа. Это соединение помогает в связывании фигуры с соответствующим текстовым контекстом), elements (идентификаторы текстовых элементов или абзацев в документе, связанных с ним или описывающих фигуру), и caption, если таковые имеются.
Если выходные данные указываются во время начальной операции анализа, служба создает обрезанные изображения для всех обнаруженных цифр, к которым можно получить доступ./analyeResults/{resultId}/figures/{figureId}
FigureId включается в каждый объект фигуры, следуя незадокументированному соглашению о {pageNumber}.{figureIndex}, где figureIndex сбрасывается до одного на страницу.
Примечание.
Для версии 4.0 2024-11-30 (GA) ограничивающие области для цифр и таблиц охватывают только основное содержимое и исключают связанные субтитры и сноски.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Разделы
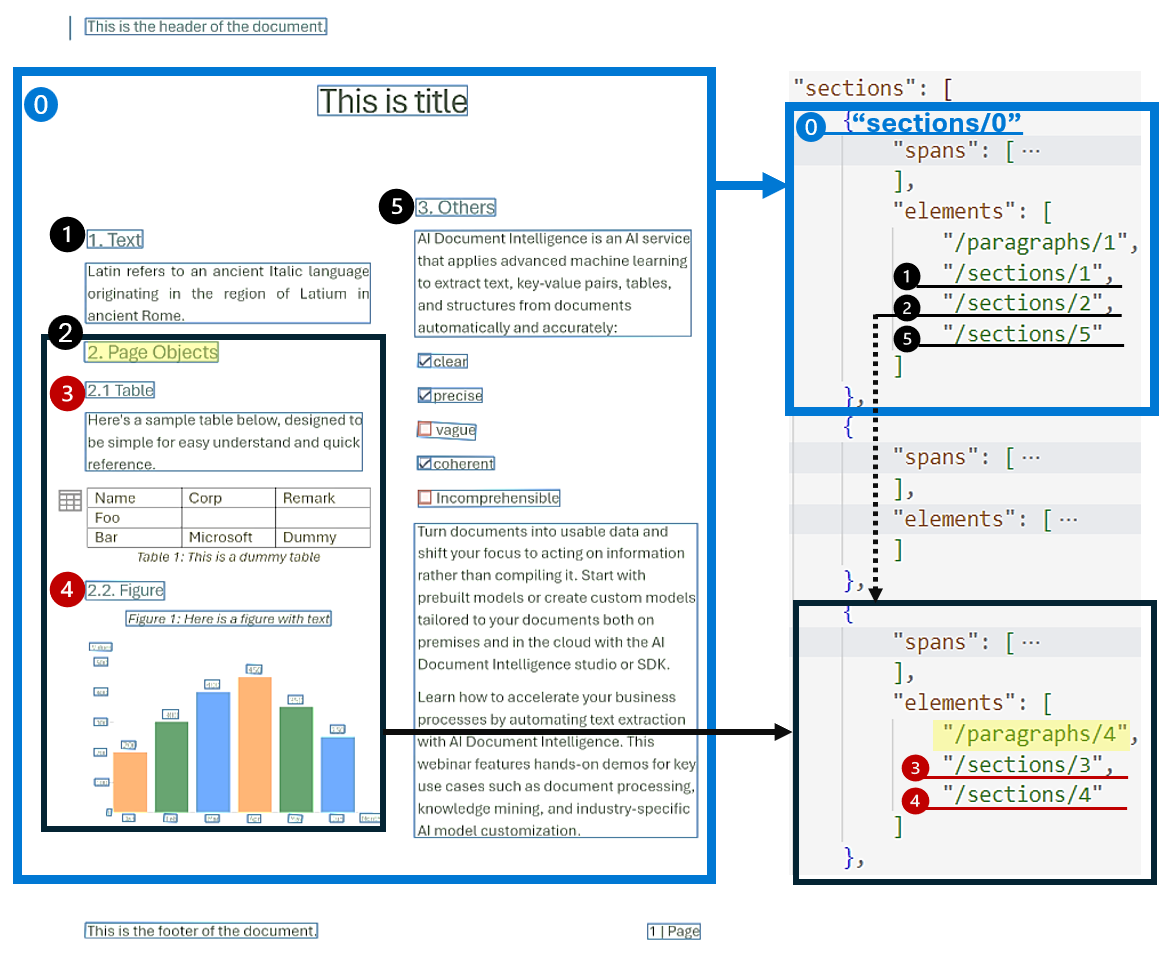
Анализ иерархической структуры документов является ключевым в организации, понимании и обработке обширных документов. Этот подход жизненно важен для семантического сегментирования длинных документов для повышения понимания, упрощения навигации и улучшения получения информации.
Появление получения дополненного поколения (RAG) в генерируемом документе ИИ подчеркивает важность иерархического анализа структуры документов. Модель макета поддерживает разделы и подразделы в выходных данных, определяющие связь разделов и объектов в каждом разделе. Иерархическая структура поддерживается в каждом разделе elements. Вы можете использовать ответ в формате вывода в markdown, чтобы легко получать разделы и подразделы в этом формате.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Это содержимое относится к:![]() версия 3.1 (GA) | Последняя версия:
версия 3.1 (GA) | Последняя версия:![]() версия 4.0 (GA) | Предыдущие версии:
версия 4.0 (GA) | Предыдущие версии:![]() версия 3.0
версия 3.0![]() версия 2.1
версия 2.1
Это содержимое применимо к: ![]() версия 3.0 (GA) | Последние версии:
версия 3.0 (GA) | Последние версии:![]() версия 4.0 (GA)
версия 4.0 (GA)![]() версия 3.1 | Предыдущая версия:
версия 3.1 | Предыдущая версия:![]() версия 2.1
версия 2.1
Это содержимое относится к:![]() v2.1 | Последняя версия:
v2.1 | Последняя версия:![]() версия 4.0 (GA)
версия 4.0 (GA)
Модель макета аналитики документов — это расширенный API анализа документов на основе машинного обучения, доступный в облаке Аналитики документов. Это позволяет принимать документы в различных форматах и возвращать структурированные представления данных документов. В этом сочетается усовершенствованная версия наших мощных возможностей оптического распознавания символов (OCR) с моделями глубокого обучения для извлечения текста, таблиц, меток выделения и структуры документа.
Анализ макета документа
Анализ макета структуры документов — это процесс анализа документа для извлечения интересующих регионов и их взаимодействия. Цель состоит в том, чтобы извлечь текст и структурные элементы со страницы, чтобы создать более семантические модели. В макете документа есть два типа ролей:
- Геометрические роли: текст, таблицы, цифры и знаки выделения являются примерами геометрических ролей.
- Логические роли: заголовки, заголовки и нижние колонтитулы являются примерами логических ролей текста.
На следующем рисунке показаны типичные компоненты на изображении примера страницы.
Поддерживаемые языки и локали
См. страницу "Поддержка языка" — модели анализа документов для полного списка поддерживаемых языков.
Аналитика документов версии 2.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы |
|---|---|
| Модель макета | • Инструмент для разметки аналитики документов • REST API • Клиентская библиотека SDK • Контейнер Docker для аналитики документов |
Руководство по входным данным
Поддерживаемые форматы файлов:
| Модель | Изображение: JPEG/JPG, , PNGBMPTIFFHEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Читать | ✔ | ✔ | ✔ |
| Макет | ✔ | ✔ | |
| Документ общего назначения | ✔ | ✔ | |
| Готовое | ✔ | ✔ | |
| Настраиваемая функция извлечения | ✔ | ✔ | |
| Настраиваемая классификация | ✔ | ✔ | ✔ |
Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Для PDF и TIFF можно обрабатывать до 2000 страниц (с подпиской на бесплатный уровень только первые две страницы обрабатываются).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и
4МБ для бесплатного уровня (F0).Размеры изображения должны составлять от 50 пикселей до 50 пикселей и 10 000 пикселей x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует размеру текста приблизительно
8пунктов при разрешении 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и
1ГБ для нейронной модели.Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1ГБ при максимальном количестве 10 000 страниц. Для2024-11-30(GA) общий размер обучающих данных составляет2ГБ не более 10 000 страниц.
Руководство по входным данным
- Поддерживаемые форматы файлов: JPEG, PNG, PDF и TIFF.
- Поддерживаемо количество страниц: для PDF и TIFF обрабатываются до 2000 страниц. Для подписчиков уровня "Бесплатный" обрабатываются только две первые страницы.
- Поддерживаемый размер файла: размер файла должен быть меньше 50 МБ и размер по крайней мере 50 x 50 пикселей и не более 10 000 x 10 000 пикселей.
Начало работы
Узнайте, как данные, включая текст, таблицы, заголовки таблиц, метки выделения и сведения о структуре, извлекаются из документов с помощью аналитики документов. Вам потребуются следующие ресурсы:
Подписка Azure — ее можно создать бесплатно.
Экземпляр Document Intelligence в портале Azure. Вы можете использовать бесплатный тарифный план (
F0), чтобы попробовать сервис. После развертывания ресурса выберите Перейти к ресурсу, чтобы получить ключ и конечную точку.
После получения ключа и конечной точки можно использовать следующие параметры разработки для создания и развертывания приложений аналитики документов:
Примечание.
Document Intelligence Studio доступна с API версии 3.0 и более поздними версиями.
REST API
Инструмент маркировки образцов для интеллектуальной обработки документов
Перейдите к примеру средства аналитики документов.
На домашней странице примера средства выберите Use Layout to get text, tables and selection marks (Использовать макет для получения текста, таблиц и отметок выбора).
В поле конечная точка службы Document Intelligence вставьте конечную точку, полученную в подписке на Document Intelligence.
В поле ключа вставьте ключ, полученный из ресурса аналитики документов.
В поле Источник выберите URL-адрес из раскрывающегося меню. Вы можете использовать наш пример документа:
Нажмите кнопку "Получить ".
Выберите Выполнить макет. Инструмент разметки образцов аналитики документов обращается к
Analyze LayoutAPI для анализа документа.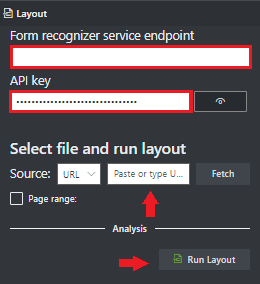
Просмотрите результаты: см. выделенный извлеченный текст, обнаруженные знаки выделения и обнаруженные таблицы.
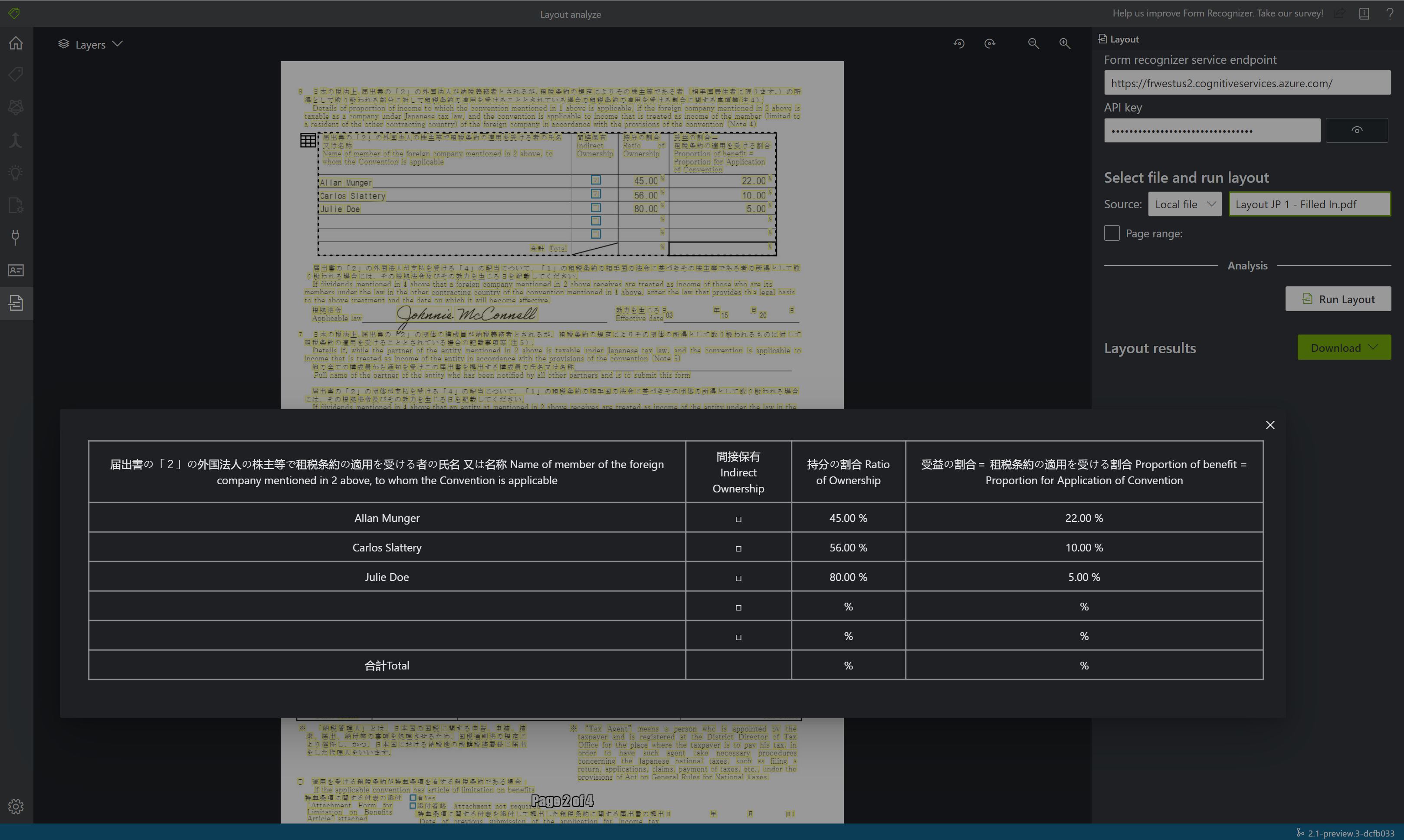
{kind=link}
Аналитика документов версии 2.1 поддерживает следующие средства, приложения и библиотеки:
| Функция | Ресурсы |
|---|---|
| API макета | • Инструмент для разметки Интеллекта документов • REST API • SDK клиентской библиотеки • Контейнер Docker Интеллекта документов |
Извлечение данных
Модель макета извлекает структурные элементы из документов. Ниже приведены описания этих структурных элементов с рекомендациями по их извлечению из входных данных документа:
Извлечение данных
Модель макета извлекает структурные элементы из документов. Ниже приведены описания этих структурных элементов с рекомендациями по их извлечению из входных данных документа:
Стр.
Коллекция страниц — это список страниц в документе. Каждая страница представлена последовательно в документе и .. /включает угол ориентации, указывающий, поворачивается ли страница и ширина и высота (измерения в пикселях). Единицы страниц в выходных данных модели подсчитываются следующим образом:
| Формат файлов | Вычисленная единица страницы | Всего страниц |
|---|---|---|
| Изображения (JPEG/JPG, PNG, BMP, HEIF) | Каждое изображение = 1 единица страницы | Всего изображений |
| Каждая страница PDF = 1 единица страницы | Всего страниц в PDF | |
| TIFF | Каждое изображение в TIFF = 1 единица страницы | Общее количество изображений в TIFF |
| Документ Word (DOCX) | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего страниц, каждая объемом до 3000 символов |
| Excel (XLSX) | Каждый лист = 1 страница; встроенные или связанные изображения не поддерживаются. | Всего листов |
| PowerPoint (PPTX) | Каждый слайд = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Всего слайдов |
| HTML | До 3000 символов = 1 единица страницы, внедренные или связанные изображения не поддерживаются | Общее количество страниц, каждая из которых до 3000 символов |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Извлечение выбранных страниц из документов
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста.
Абзац
Модель макета извлекает все идентифицированные блоки текста в коллекции paragraphs как объект верхнего уровня в разделе analyzeResults. Каждая запись в этой коллекции представляет текстовый блок и включает извлеченный текст в виде content и ограничивающие polygon координаты. Сведения span указывают на фрагмент текста в свойстве верхнего уровня content, содержащем весь текст из документа.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Роль абзаца
Новое обнаружение объектов на основе машинного обучения извлекает логические роли, такие как заголовки, заголовки разделов, заголовки страницы, нижние колонтитулы страницы и многое другое. Модель макета аналитики документов назначает определенные текстовые блоки в paragraphs коллекции с их специализированной ролью или типом, прогнозируемым моделью. Рекомендуется использовать роли для абзацев в неструктурированных документах, чтобы лучше понять структуру извлеченного содержания для более углубленного семантического анализа. Поддерживаются следующие роли абзаца:
| Прогнозируемая роль | Description | Поддерживаемые типы файлов |
|---|---|---|
title |
Основные заголовки на странице | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Одно или несколько подзаголовок на странице | pdf, image, docx, xlsx, html |
footnote |
Текст в нижней части страницы | pdf, изображение |
pageHeader |
Текст по верхнему краю страницы | pdf, image, docx |
pageFooter |
Текст по нижнему краю страницы | pdf, image, docx, pptx, html |
pageNumber |
Номер страницы | pdf, изображение |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Текст, строка и слово
Модель макета документа в Аналитике документов извлекает печатный и рукописный текст стиля как lines и words. Коллекция styles включает любой рукописный стиль для строк, если он обнаружен, а также диапазоны, указывающие на связанный текст. Эта функция применяется к поддерживаемым языкам рукописного ввода.
Для Microsoft Word, Excel, PowerPoint и HTML модель макета анализа документов версии 4.0 2024-11-30 (GA) извлекает весь встроенный текст без изменений. Тексты извлекаются как слова и абзацы. Внедренные образы не поддерживаются.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Рукописный стиль
Ответ .. /включает классификацию того, является ли каждая текстовая строка стилем рукописного ввода или нет, а также оценка достоверности. Дополнительные сведения. См. поддержка рукописного ввода. В следующем примере показан пример фрагмента КОДА JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Если включить возможность добавления шрифта и стиля, вы также получите результат шрифта и стиля в составе styles объекта.
Знак выделения
Модель макета также извлекает метки выбора из документов. Извлеченные метки выделения отображаются в коллекции pages для каждой страницы. Сюда входят ограничивающие метки polygon, confidence и метки выделения state (selected/unselected). Текстовое представление (то есть :selected: и :unselected) также включается в качестве начального индекса (offset) и length ссылается на свойство верхнего уровня content , содержащее полный текст документа.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Таблица
Извлечение таблиц является ключевым требованием для обработки документов, содержащих большие объемы данных, обычно отформатированных в виде таблиц. Модель макета извлекает таблицы в pageResults разделе выходных данных JSON. Извлеченные сведения о таблице .. /включает количество столбцов и строк, диапазона строк и диапазона столбцов. Каждая ячейка с ограничивающим многоугольником выводится вместе с информацией о том, распознается ли область как columnHeader или нет. Модель поддерживает извлечение таблиц, которые поворачиваются. Каждая ячейка таблицы содержит индекс строки и столбца и координаты ограничивающего многоугольника. Для текста ячейки модель выводит сведения span, содержащие начальный индекс (offset). Модель также выводит содержимое на верхнем уровне length, которое содержит полный текст из документа.
Ниже приведены некоторые факторы для рассмотрения при использовании возможности извлечения документов с помощью интеллектуального анализа:
Представлены ли данные, которые вы хотите извлечь, в виде таблицы, и имеет ли структура таблицы смысл?
Может ли данные помещаться в двухмерную сетку, если данные не в формате таблицы?
Охватывают ли таблицы несколько страниц? Если это так, чтобы избежать необходимости пометить все страницы, разделите PDF на страницы, прежде чем отправлять его в аналитику документов. После анализа выполните постобработку страниц в одну таблицу.
Если вы создаете пользовательские модели, обратитесь к табличным полям . Динамические таблицы имеют переменное количество строк для каждого столбца. Фиксированные таблицы имеют постоянное количество строк для каждого столбца.
Примечание.
- Анализ таблиц не поддерживается, если входной файл — XLSX.
- Аналитика документов версии 4.0
2024-11-30(GA) поддерживает ограничивающие области для иллюстраций и таблиц, которые охватывают только основное содержимое, исключая связанные заголовки и сноски.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Заметки
Модель макета извлекает аннотации в документах, такие как галочки и крестики. Ответ ../включает тип аннотации, а также оценку достоверности и ограничивающий многоугольник.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Естественный порядок чтения для выводимых данных (только для языков на основе латиницы)
Используя параметр запроса readingOrder, можно указать порядок, в котором будут выводиться текстовые строки. Для более удобного человеку порядка чтения используйте natural, как показано в следующем примере. Эта функция поддерживается только для языков, использующих латинский алфавит.

Выбор номера страницы или диапазона для извлечения текста
Для больших многостраничных документов используйте параметр запроса pages, чтобы указать конкретные номера страниц или диапазоны страниц для извлечения текста. В следующем примере представлен документ в 10 страниц с текстом, извлеченным в двух вариантах — все страницы (1–10) и выбранные страницы (3–6).
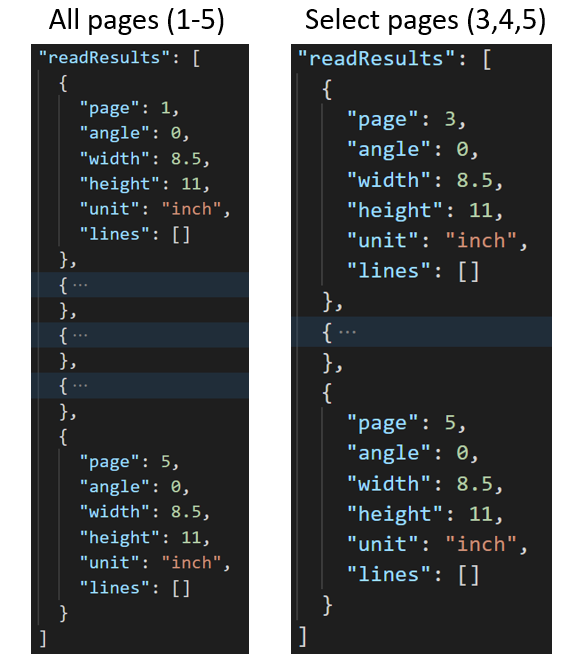
Операция получения результата анализа макета
Второй шаг — вызов операции Получить результат анализа макета. Эта операция принимает в качестве входных данных идентификатор результата созданной Analyze Layout операции. Она возвращает ответ в формате JSON, содержащий поле Состояние со следующими возможными значениями.
| Поле | Тип | Возможные значения |
|---|---|---|
| статус | строка |
notStarted: операция анализа не запущена.running: операция анализа выполняется.failed: операция анализа завершилась ошибкой.succeeded: операция анализа завершилась успешно. |
Вызывайте эту операцию итеративно до возвращения значения succeeded. Чтобы избежать превышения частоты запросов в секунду (RPS), используйте интервал от 3 до 5 секунд.
Если поле состояния имеет succeeded значение, ответ JSON .. /включает извлеченный макет, текст, таблицы и знаки выделения. Извлеченные данные ../включают извлеченные текстовые строки и слова, ограничивающие рамки, внешний вид текста с указанием на рукописный текст, таблицы и метки выбора с указанием выбор/невыбор.
Рукописная классификация текстовых строк (только для латинских языков)
Ответ .. /включает классификацию того, является ли каждая текстовая строка стилем рукописного ввода или нет, а также оценка достоверности. Эта функция поддерживается только для латинских языков. В следующем примере представлена рукописная классификация для текста в изображении.

Пример выходного JSON-файла
Ответ на операцию получения результата анализа макета — это структурированное представление документа, в котором содержится вся извлеченная информация. См. здесь пример файла документа и его структурированный вывод в примере выходных данных макета.
Выходные данные JSON имеют две части.
-
readResultsузел содержит весь распознаваемый текст и маркер выбора. Иерархия представления текста — страница, а затем строка, а затем отдельные слова. -
pageResultsузел содержит таблицы и ячейки, извлеченные с ограничивающими прямоугольниками, достоверность и ссылку на строки и слова в поле readResults.
Пример выходных данных
Текст
API для работы с макетами извлекает текст из документов и изображений с различными углами и цветами текста. Программа принимает фотографии документов, факсов, напечатанный и/или рукописный текст (только на английском языке), а также их различные комбинации. Текст извлекается, и предоставляется информация о строках, словах, ограничивающих прямоугольниках, показателях достоверности и стиле (рукописный или иной). Вся текстовая информация включена в раздел readResults выходных данных JSON.
Таблицы с заголовками
API разметки извлекает таблицы в секции pageResults JSON выхода. Документы могут быть отсканированными, сфотографированными или оцифрованными. Таблицы могут быть сложными с объединенными ячейками или столбцами, с границами или без них, а также с неровными углами. Извлеченные сведения о таблице .. /включает количество столбцов и строк, диапазона строк и диапазона столбцов. Каждая ячейка с ограничивающей рамкой выводится вместе с информацией о том, распознается ли эта область как часть заголовка или нет. Ячейки заголовка, которые распознала модель, могут охватывать несколько строк и необязательно быть первыми строками в таблице. Они также работают с повёрнутыми таблицами. Каждая ячейка таблицы также .. /включает полный текст со ссылками на отдельные слова в readResults разделе.
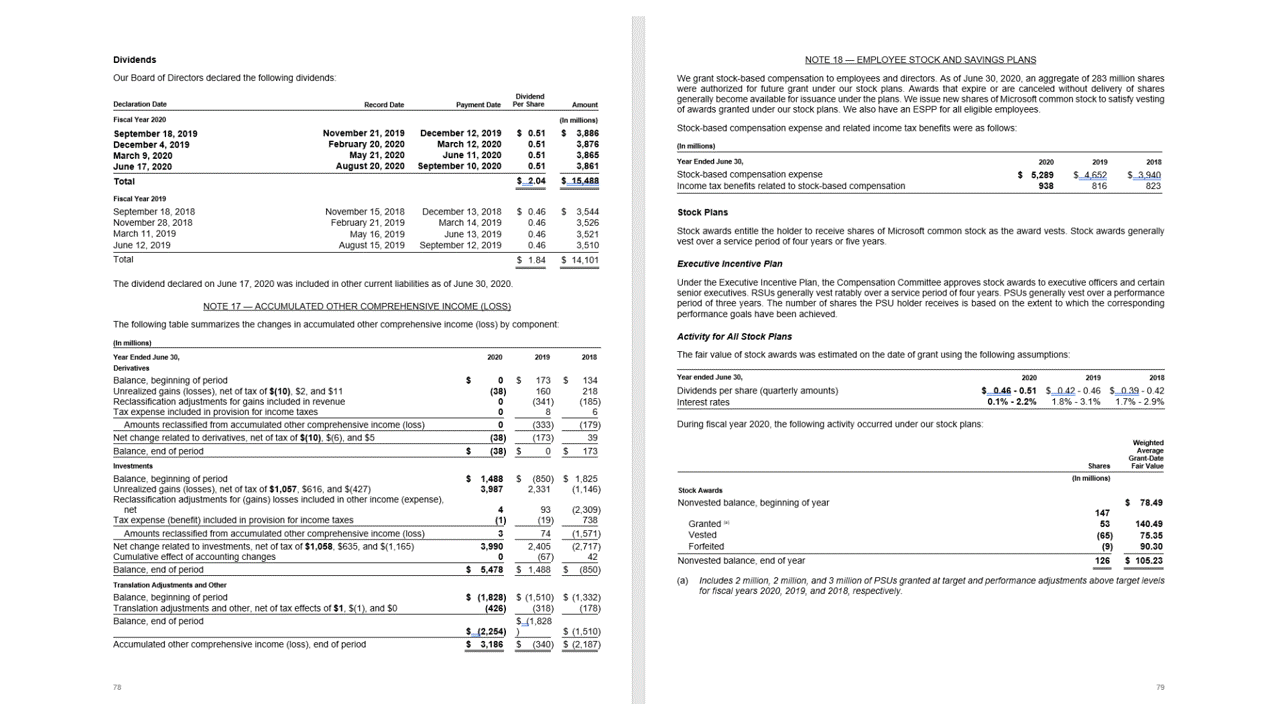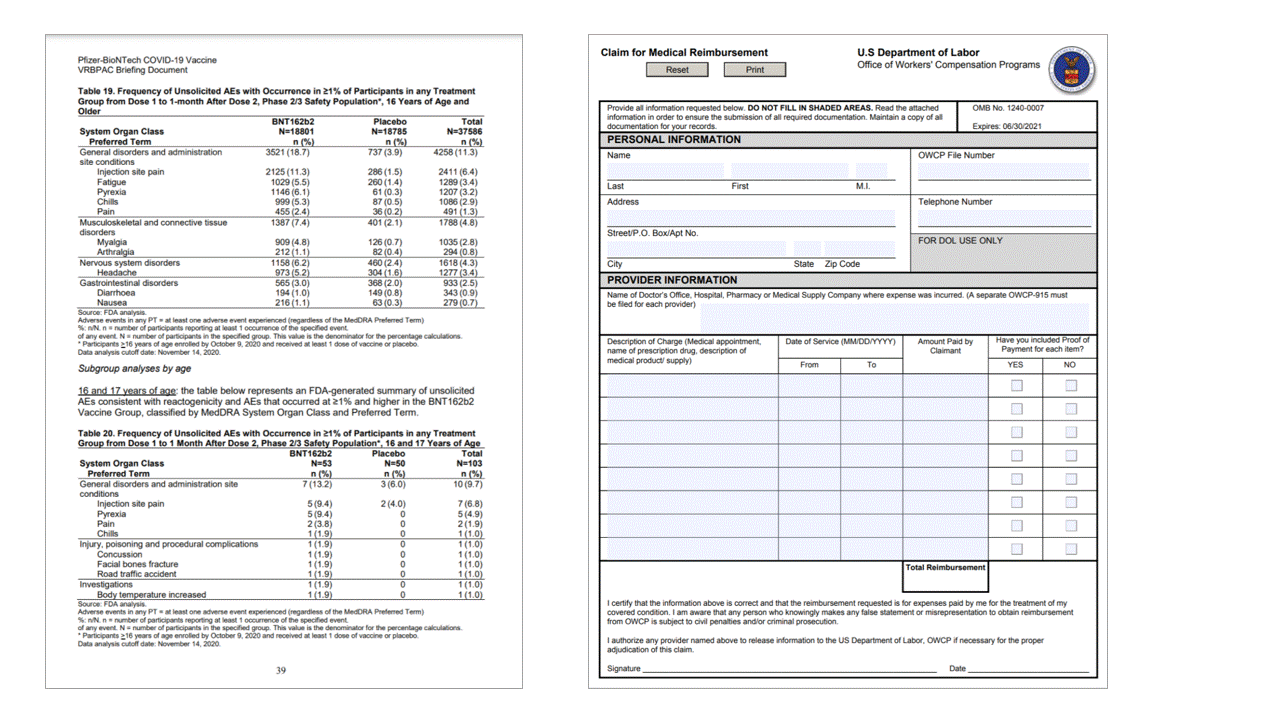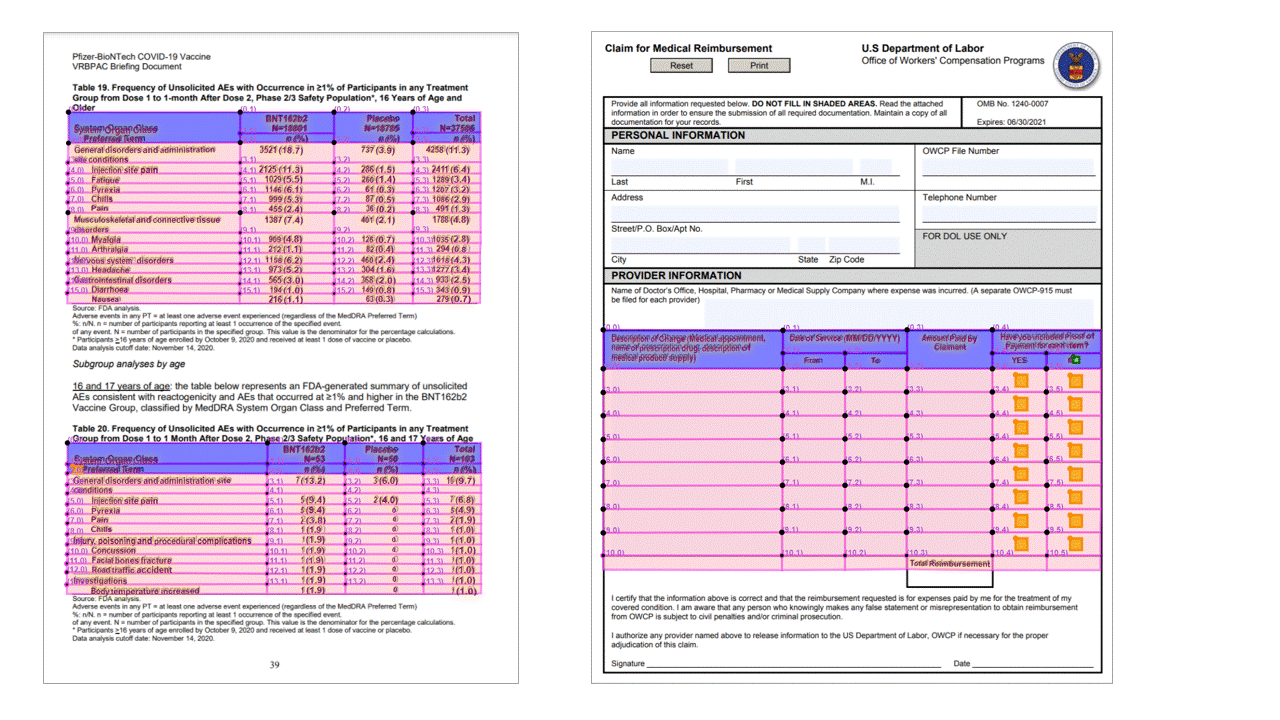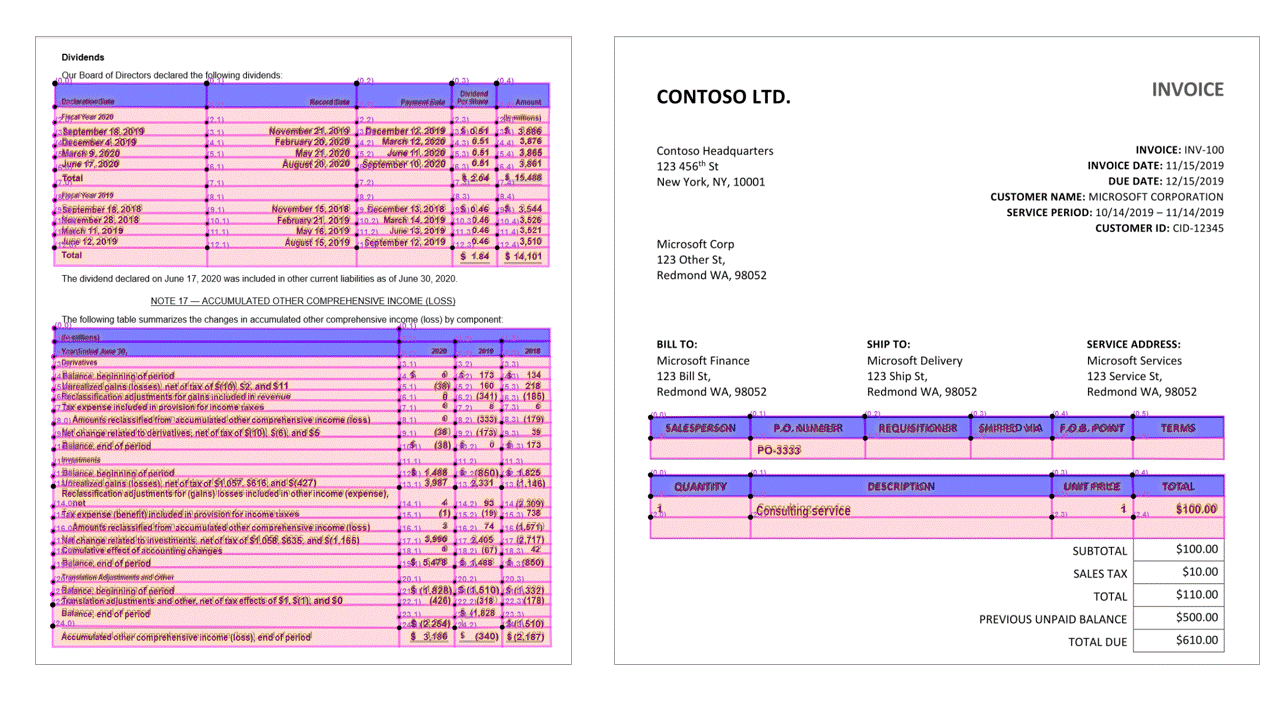
Метки выделения (документы)
Layout API также извлекает метки выделения из документов. У извлеченных меток выделения указаны ограничивающий прямоугольник, достоверность и состояние (выбрана/не выбрана). В разделе readResults выходных данных JSON извлекаются сведения о метках выделения.
Руководство по миграции
- Следуйте руководству по миграции с помощью аналитики документов версии 3.1, чтобы узнать, как использовать версию 3.1 в приложениях и рабочих процессах.
Следующие шаги
Узнайте, как обрабатывать собственные формы и документы с помощью Document Intelligence Studio.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.
Узнайте, как обрабатывать собственные формы и документы с помощью инструмента разметки образцов документов.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.