Как улучшить модель пользовательского визуального распознавания
В этом руководстве вы узнаете, как улучшить качество модели Пользовательское визуальное распознавание. Качество классификатора или детектора объектов зависит от объема, качества и разнообразия предоставленных данных, а также от того, насколько сбалансирован общий набор данных. Хорошая модель имеет сбалансированный набор данных для обучения, который является представителем того, что отправляется в него. Процесс создания такой модели является итеративным. Довольно часто для достижения ожидаемых результатов нужно выполнить несколько циклов обучения.
Ниже приведен общий шаблон, который поможет создать более точную модель:
- Первый сеанс обучения
- Добавьте дополнительные изображения и сбалансируйте данные. Повторите обучение.
- Добавьте изображения с различным фоном, освещением, размером объекта, углом камеры и стилем. Повторите обучение.
- Использование новых образов для тестирования прогнозирования
- Измените существующие обучающие данные в соответствии с результатами прогноза.
Предотвращение лжевзаимосвязи
Иногда модель учится делать прогнозы на основе произвольных характеристик, с которыми имеются изображения. Например, при создании классификатора яблок и цитрусовых для изображений яблок в руках и цитрусовых на белых тарелках классификатор может сосредоточиться на руках и белых тарелках вместо яблок и цитрусовых.
Чтобы устранить эту проблему, используйте изображения с разным ракурсом, разным фоном, разными размерами объекта, сгруппированные фотографии и другие варианты. Эти принципы будут более подробно рассмотрены в следующих разделах.
Обеспечение количества данных
Число обучающих изображений является наиболее важным фактором для вашего набора данных. Мы рекомендуем в качестве отправной точки использовать по меньшей мере 50 изображений на метку. При меньшем числе изображений существует более высокий риск появления лжевзаимосвязей, и хотя показатели производительности могут указывать на хорошее качество модели, она может испытывать трудности при обработке реальных данных.
Обеспечение баланса данных
Важно также учесть относительный объем обучающих данных. Например, использование 500 изображений для одной метки и 50 — для другой приведет к созданию несбалансированного обучающего набора данных. Это приводит к тому, что модель будет более точной в прогнозировании одной метки, чем другая. Если оставить соотношение 1:2 между метками с наименьшим количеством изображений и метками с наибольшим количеством изображений, то скорее всего, вы увидите наилучший результат. Например, если наибольшим числом изображений для какой-либо метки является 500, то наименьшим числом изображений для другой метки должно быть не менее 250.
Обеспечение разнообразия данных
Предоставьте изображения, максимально похожие на конкретное содержимое, которое будет передаваться в классификатор при его использовании. В противном случае модель может научиться создавать прогнозы на основе произвольных характеристик, общих для изображений. Например, при создании классификатора яблок и цитрусовых для изображений яблок в руках и цитрусовых на белых тарелках классификатор может сосредоточиться на руках и белых тарелках вместо яблок и цитрусовых.

Чтобы устранить эту проблему, используйте разнообразные изображения, чтобы модель научилась правильно их обобщать. Некоторые из способов, с помощью которых можно сделать набор для обучения более разнообразным, приведены ниже.
Фон. Предоставьте изображения объекта на разном фоне. Фотографии в естественном окружении лучше, чем фотографии на нейтральном фоне, так как они предоставляют больше информации для классификатора.

Освещение. Предоставьте изображения объекта с различным освещением (например, с использованием вспышки, высокой экспозиции и т. д.), особенно когда на изображениях, используемых для прогнозирования, разнообразное освещение. Полезно также использовать изображения с разнообразной насыщенностью, оттенком и яркостью.

Размер объекта. Предоставьте изображения, на которых объекты отличаются размером и количеством (например, фотографию гроздьев бананов и крупный план одного банана). Различные размеры объектов помогают классификатору делать общие выводы.

Угол камеры. Предоставьте изображения объекта, снятые под разными углами. Кроме того, если все фотографии должны быть сделаны с помощью стационарных камер (например, камер видеонаблюдения), обязательно назначьте постоянным объектам в кадре разные метки. Это позволит избежать формирования лжевзаимосвязей, то есть интерпретации несвязанных объектов (например, фонарных столбов) как ключевого признака.

Стиль. Предоставьте изображения одного и того же класса, но в разных стилях (например, различные варианты одного фрукта). Тем не менее, если присутствуют изображения объектов совершенно разных стилей (например, Микки-Маус и реальная мышь), рекомендуется отметить их как отдельные классы, что позволит лучше представлять их различные признаки.

Используйте отрицательные изображения (только классификаторы)
Если вы используете классификатор изображений, может потребоваться добавить отрицательные образцы , чтобы сделать классификатор более точным. Негативными примерами называются изображения, которые не соответствуют ни одному из других тегов. Отправляя такие изображения, примените к ним специальную метку Negative (Негативные).
Средство обнаружения объектов обрабатывает негативные примеры автоматически, поскольку любые области изображения за пределами ограничивающих прямоугольников считаются отрицательными.
Примечание.
Служба Пользовательское визуальное распознавание поддерживает автоматическую обработку отрицательных изображений. Например, когда вы компилируете классификатор для различения винограда и банана, то для фотографии ботинка он должен предоставить оценку 0 % по обеим категориям.
С другой стороны, в тех случаях, когда отрицательные изображения являются лишь вариацией изображений, используемых в обучении, вполне вероятно, что из-за большого сходства модель будет классифицировать отрицательные изображения как отмеченные классы. Например, если классификатору апельсина и грейпфрута предложить для сравнения изображение клементина, он может оценить его как апельсин, потому что многие черты клементина похожи на апельсины. Если отрицательные изображения имеют такой характер, рекомендуется создать один или несколько дополнительных тегов (например , другие) и пометить отрицательные изображения с этим тегом во время обучения, чтобы позволить модели лучше различать эти классы.
Обработка окклюзии и усечения (только детекторы объектов)
Если необходимо, чтобы средство обнаружения объектов определяло усеченные объекты (объекты, которые частично выходят за пределы изображения) или перекрытые объекты (объекты, которые частично заблокированы другими объектами на изображении), необходимо добавить обучающие изображения для этих случаев.
Примечание.
Проблемы с объектами, которые перекрываются другими объектами, не следует путать с Порогом перекрытия. Этот параметр используется для оценки производительности модели. Ползунок Порога перекрытия на веб-сайте пользовательского визуального распознавания зависит от того, насколько прогнозируемый ограничивающий прямоугольник должен перекрываться настоящим ограничивающим прямоугольником, чтобы это считалось правильным.
Использование прогнозных изображений для дальнейшего обучения
Когда вы используете или тестируете модель, отправляя изображения в конечную точку прогнозирования, служба пользовательского визуального распознавания сохраняет их. Затем их можно использовать для улучшения модели.
Чтобы просмотреть изображения, отправленные в модель, откройте веб-страницу пользовательского визуального распознавания, перейдите к своему проекту и откройте вкладку Прогнозы. По умолчанию на этой вкладке отображаются изображения из текущей итерации. Раскрывающееся меню Iteration (Итерация) позволяет перейти к изображениям, переданным в предыдущих итерациях.
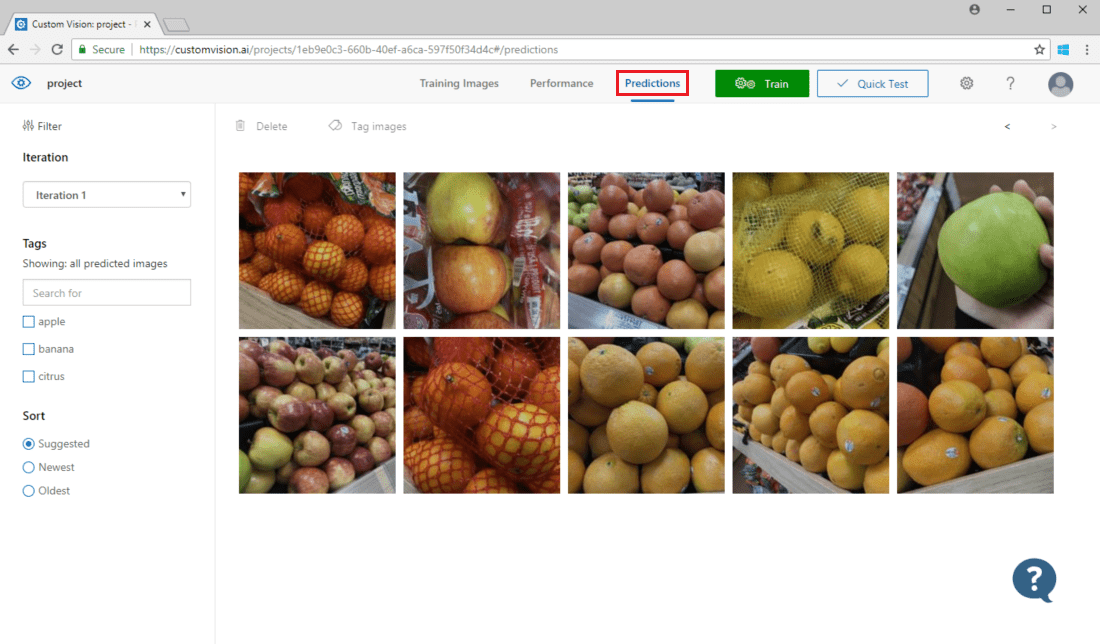
Наведите указатель мыши на изображение, чтобы увидеть спрогнозированные моделью теги. Изображения сортируются таким образом, что сверху указываются те из них, которые могут эффективнее улучшить модель. Чтобы использовать другой метод сортировки, выберите соответствующий параметр в разделе Sort (Сортировка).
Чтобы добавить изображение в существующий обучающий набор данных, выберите изображение, укажите правильные теги и нажмите кнопку Сохранить и закрыть. Изображение удаляется из прогнозов и добавляется в набор обучающих образов . Теперь его можно просмотреть на вкладке Training Images (Изображения для обучения).
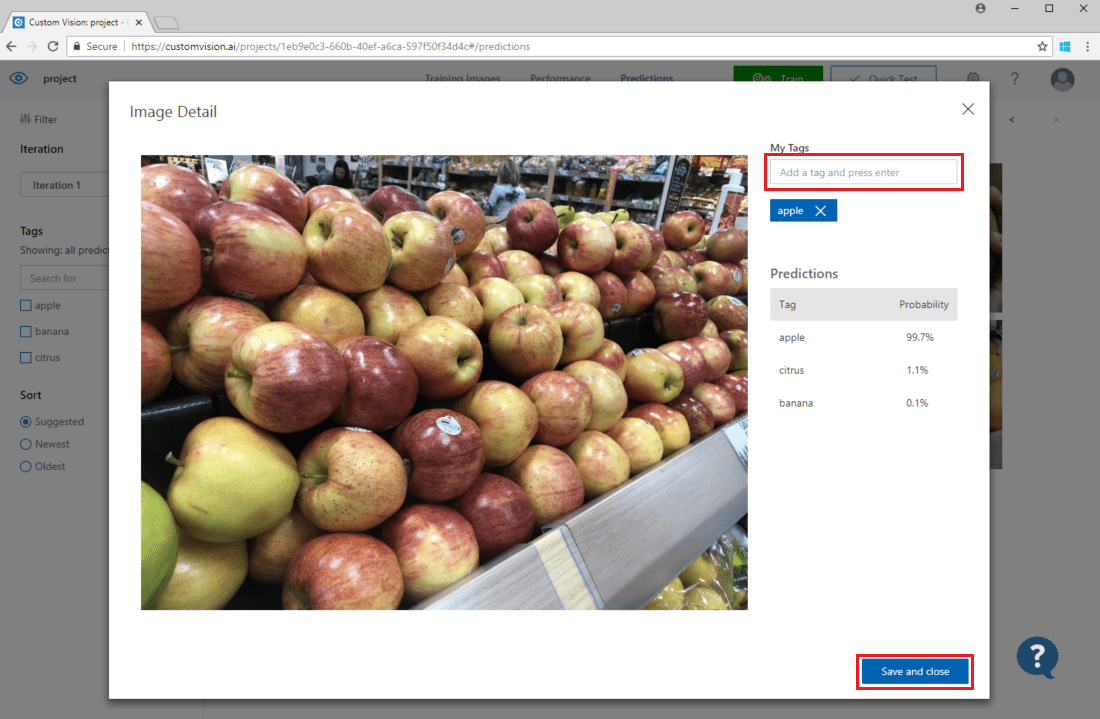
Нажмите кнопку Обучение, чтобы переобучить модель.
Визуальная проверка прогнозов
Чтобы просмотреть прогнозы изображений, перейдите на вкладку Training Images (Обучающие изображения), выберите предыдущую итерацию обучения в раскрывающемся меню Iteration (Итерация) и установите флажок для одного или нескольких тегов в разделе Tags (Теги). Теперь представление должно отобразить красные рамки вокруг каждого изображения, для которого модели не удалось правильно спрогнозировать заданный тег.
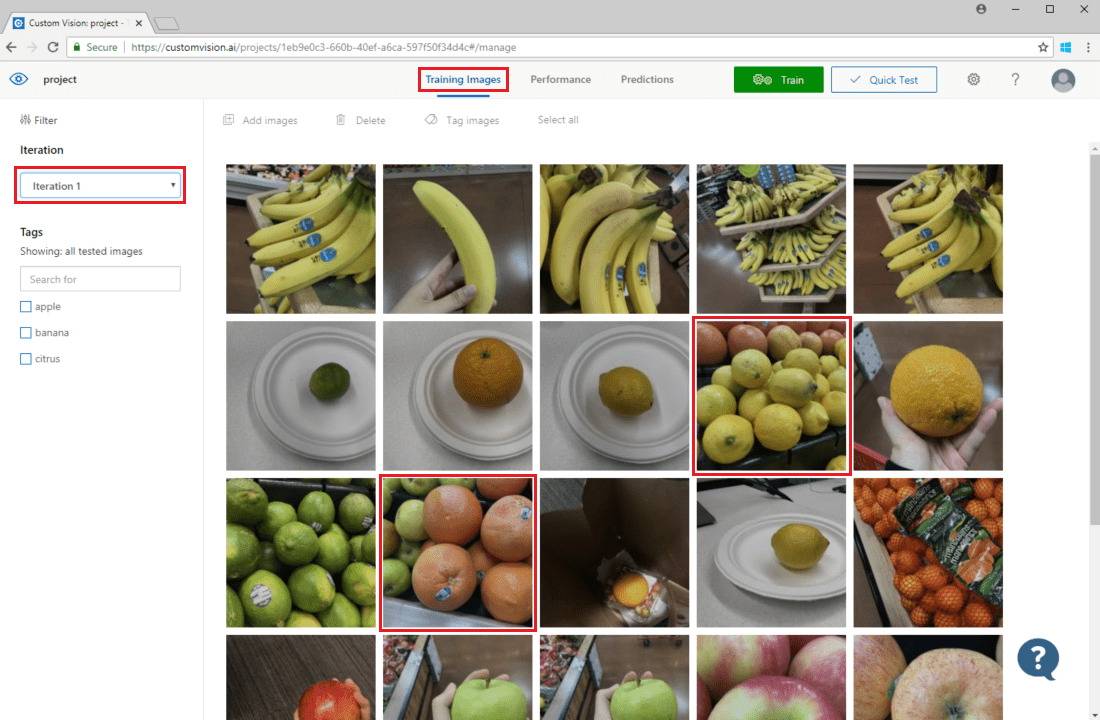
В некоторых случаях визуальная проверка позволяет заметить в этих ошибках закономерность и исправить ее, добавив дополнительные обучающие данные или изменив существующие данные. Например, классификатор яблок и лаймов может неправильно отметить все зеленые яблоки и обозначить их как лаймы. Чтобы устранить эту проблему, следует добавить и применить обучающие данные с отмеченными тегом изображениями зеленых яблок.
Следующий шаг
В этом руководстве вы изучили несколько методик, позволяющих повысить точность моделей классификации изображений или обнаружения объектов. Далее вы можете узнать, как программно тестировать изображения, отправляя их в API прогнозирования.