Использование рекомендаций по индексу, созданных с помощью настройки индекса в База данных Azure для PostgreSQL — гибкий сервер
Настройка индекса сохраняет рекомендации, которые он делает в наборе таблиц, расположенных под схемой intelligentperformance в azure_sys базе данных.
В настоящее время эти сведения можно считывать с помощью сборки страницы портал Azure для этой цели или путем выполнения запросов для получения данных из двух представлений, доступных в intelligent performance azure_sys базе данных.
Использование рекомендаций по индексу с помощью портал Azure
Войдите в портал Azure и выберите экземпляр гибкого сервера База данных Azure для PostgreSQL.
Выберите параметр "Настройка индекса" в разделе "Интеллектуальная производительность " в меню.
Если функция включена, но рекомендации еще не созданы, экран выглядит следующим образом:
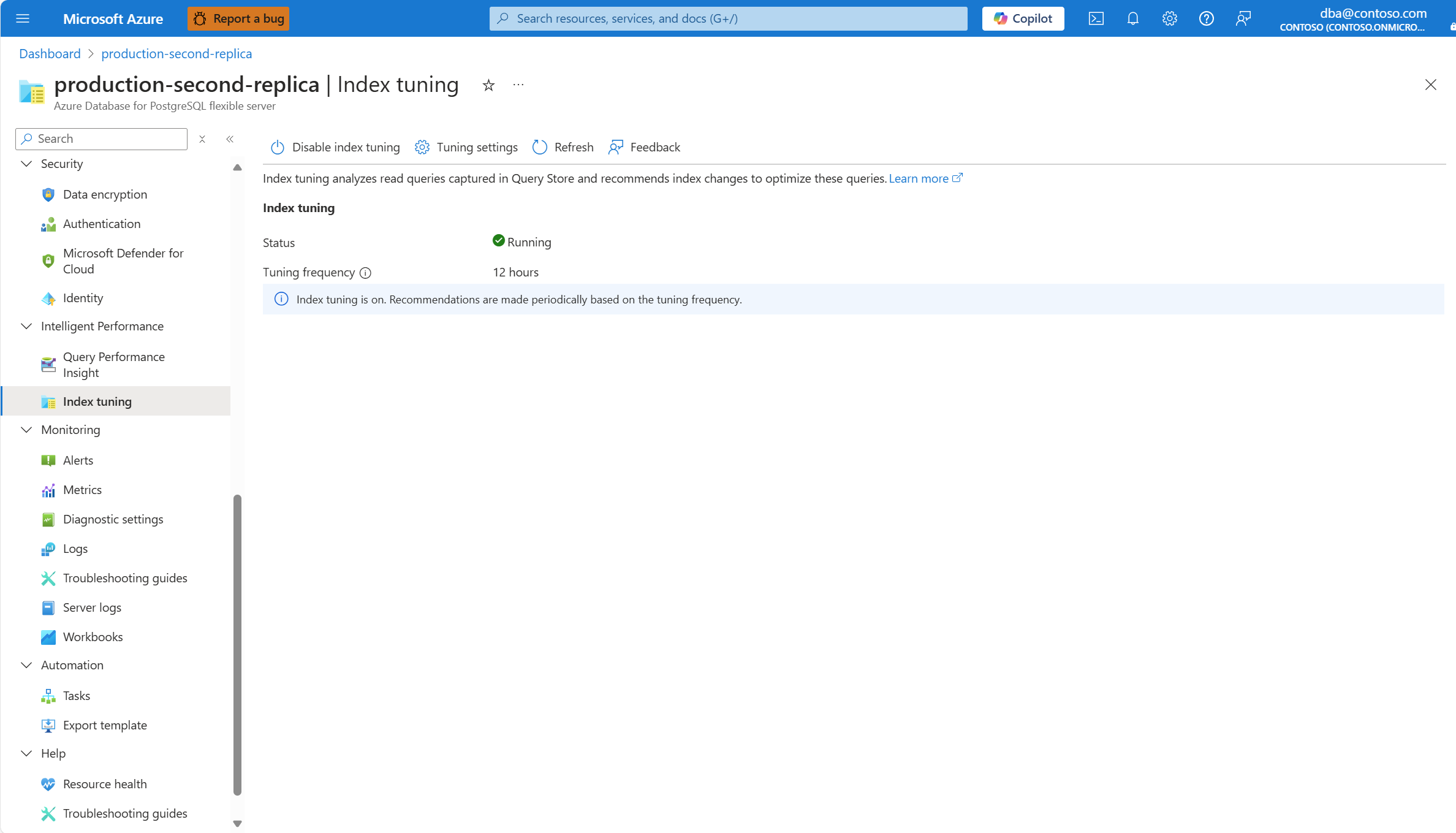
Если функция в настоящее время отключена, и она никогда не создавала рекомендации в прошлом, экран выглядит следующим образом:
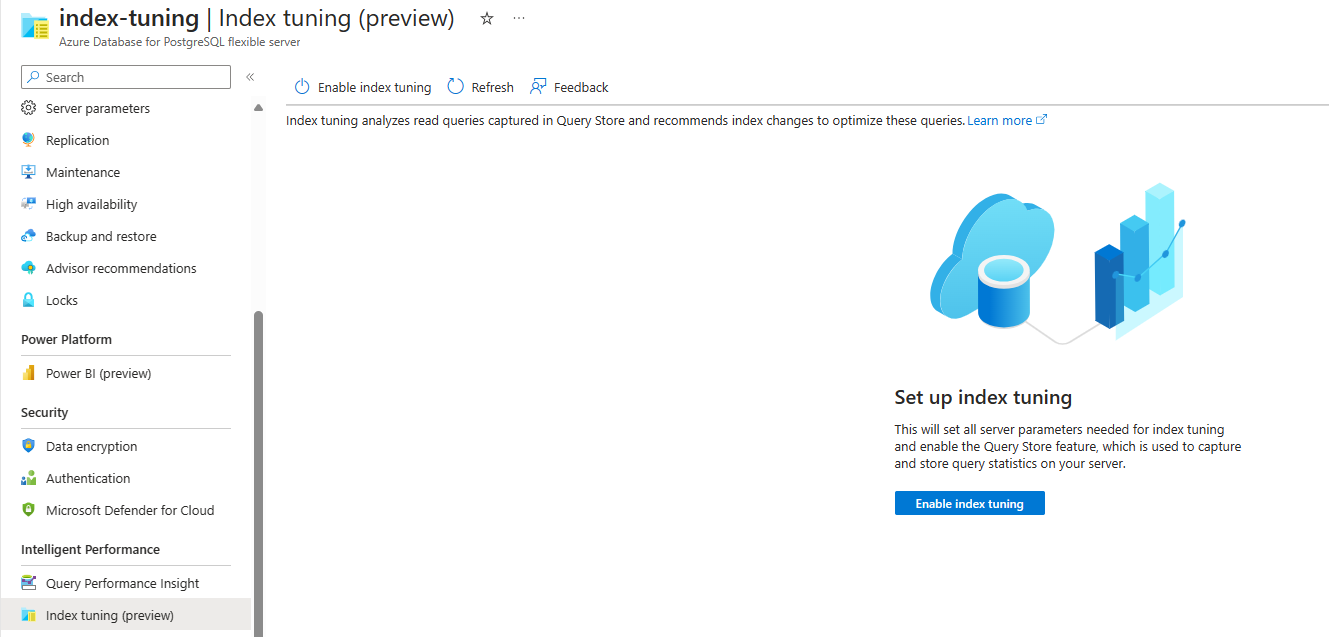
Если функция включена и рекомендации еще не созданы, экран выглядит следующим образом:
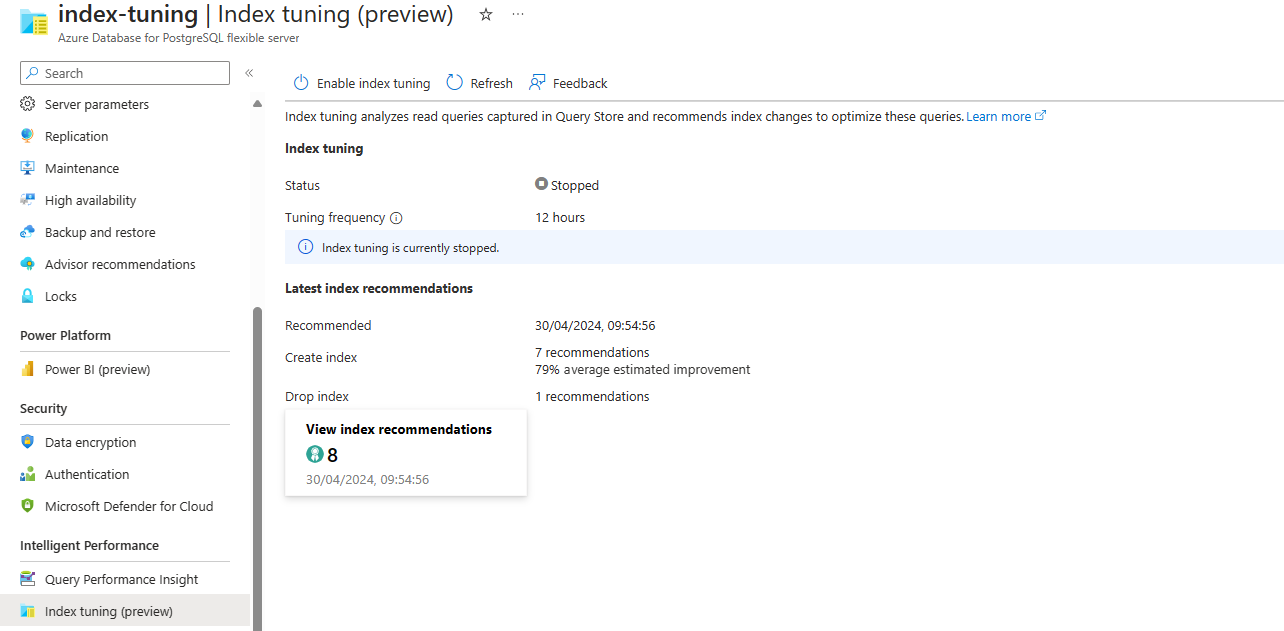
Если функция отключена, но она когда-либо создавала рекомендации, экран выглядит следующим образом:
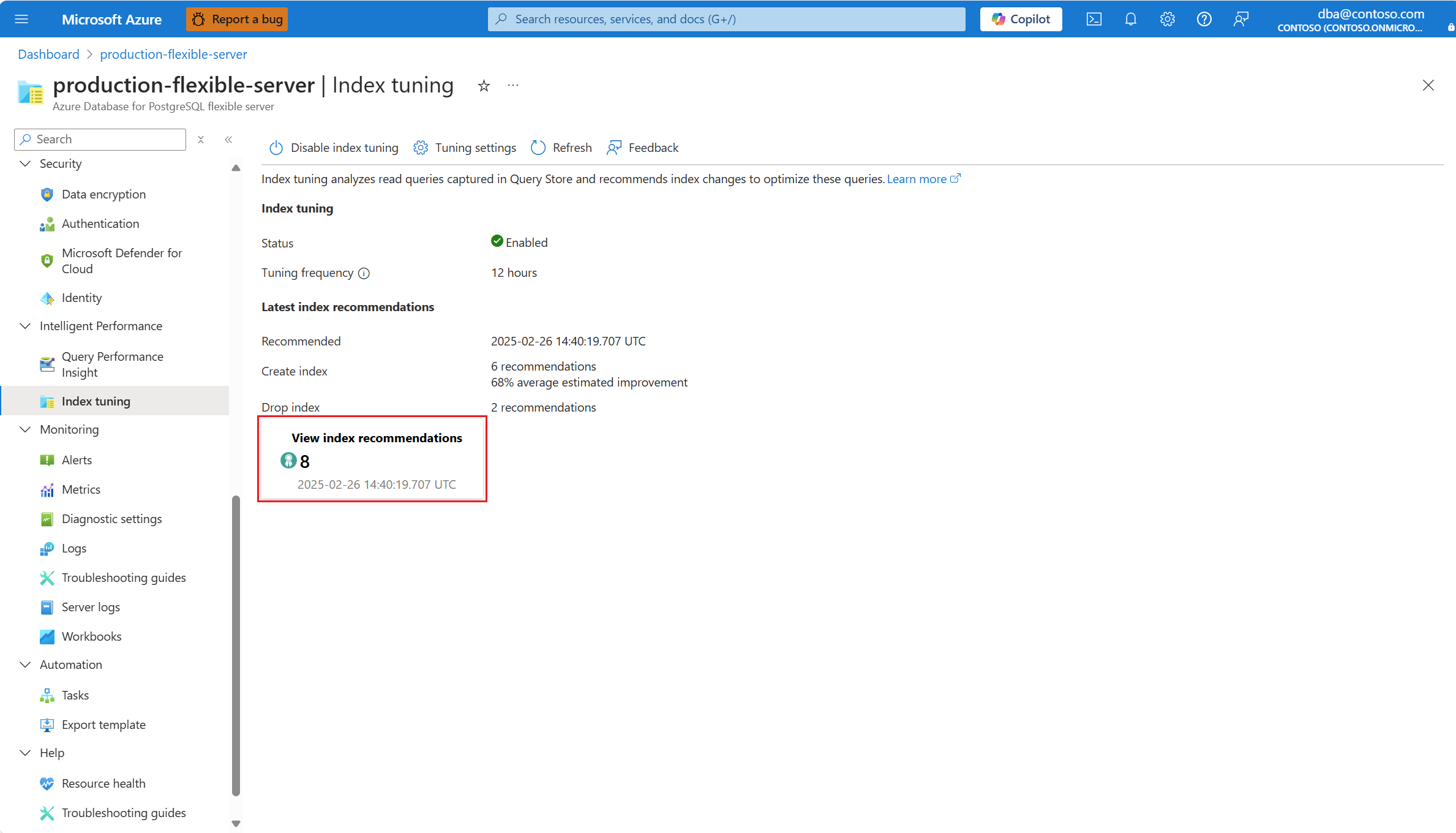
Если доступны рекомендации, выберите сводку рекомендаций по индексу представления, чтобы получить доступ к полному списку:
В списке показаны все доступные рекомендации с некоторыми сведениями для каждого из них. По умолчанию список отсортирован по last рекомендуется в порядке убывания, где отображаются самые последние рекомендации в верхней части. Однако можно сортировать по любому другому столбцу и использовать поле фильтрации для уменьшения списка элементов, отображаемых для этих элементов, имена базы данных, схемы или таблицы которых содержат указанный текст:
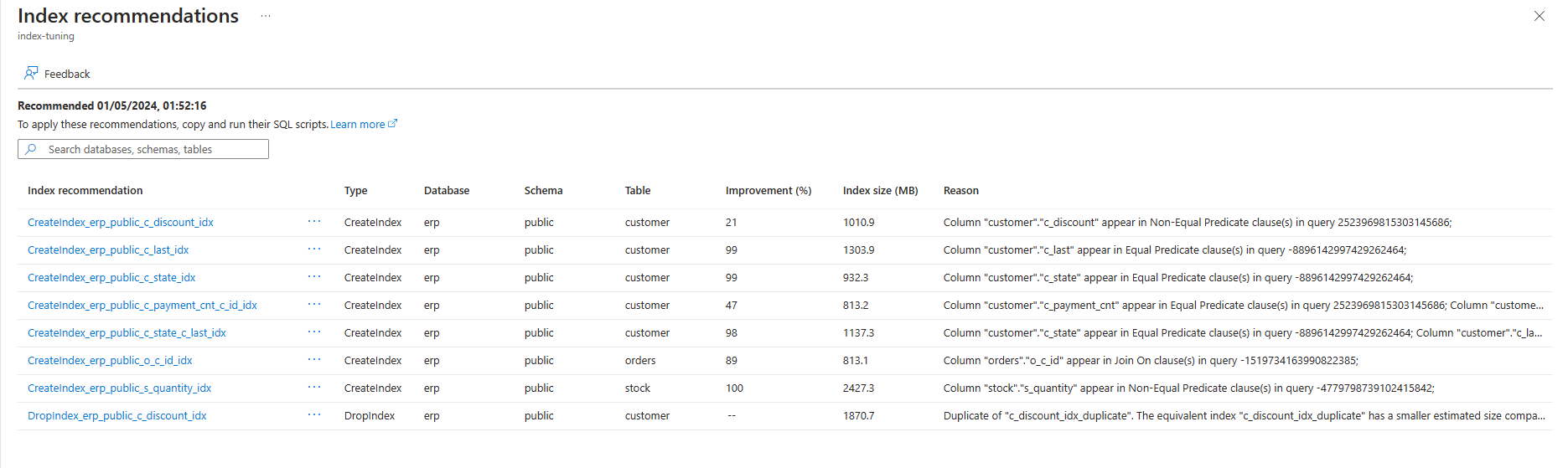
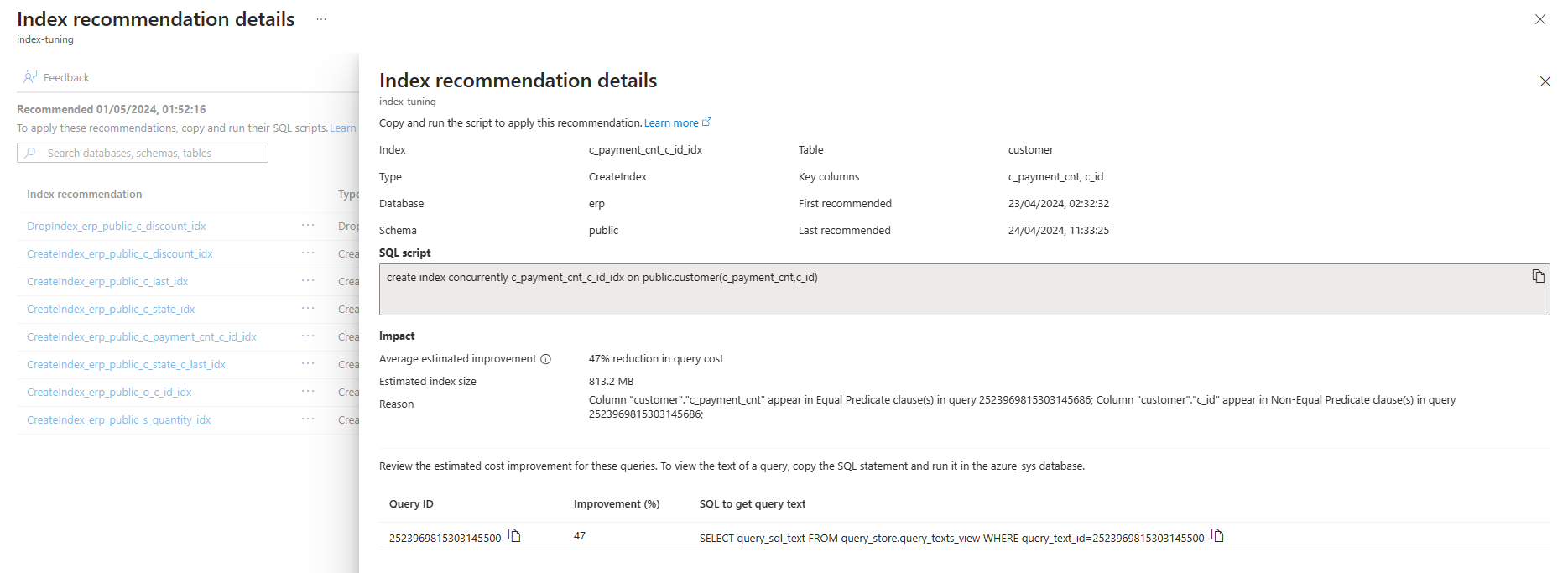
Чтобы просмотреть дополнительные сведения о любой конкретной рекомендации, выберите имя этой рекомендации, а в правой части экрана откроется область сведений об индексе, чтобы получить все доступные сведения о рекомендации:






Использование рекомендаций по индексу с помощью представлений, доступных в базе данных azure_sys
- Подключитесь к базе данных, доступной на сервере
azure_sys, с любой ролью, имеющей разрешение на подключение к экземпляру. Члены роли могут читаться из этих представленийpublic. - Выполните запросы в представлении
sessions, чтобы получить сведения о сеансах рекомендаций. - Выполните запросы в
recommendationsпредставлении, чтобы получить рекомендации, созданные с помощью настройки индекса для CREATE INDEX и DROP INDEX.
Представления
Представления в azure_sys базе данных предоставляют удобный способ доступа к рекомендациям по индексу, созданным при настройке индекса. В частности, представления содержат dropindexrecommendations подробные createindexrecommendations сведения о рекомендациях CREATE INDEX и DROP INDEX соответственно. Эти представления предоставляют такие данные, как идентификатор сеанса, имя базы данных, тип помощника, время начала и остановки сеанса настройки, идентификатор рекомендации, тип рекомендации, причина рекомендации и другие важные сведения. Запросив эти представления, пользователи могут легко получать доступ к рекомендациям по индексу и анализировать их, созданные с помощью настройки индекса.
intelligentperformance.session
Представление sessions предоставляет все сведения для всех сеансов настройки индекса.
| Имя столбца | тип данных | Description |
|---|---|---|
| session_id | uuid | Глобальный уникальный идентификатор, назначенный каждому новому сеансу настройки, инициируемого. |
| database_name | varchar(64) | Имя базы данных, в контексте которой был выполнен сеанс настройки индекса. |
| session_type | intelligentperformance.recommendation_type | Указывает типы рекомендаций, которые может создавать этот сеанс настройки индекса. Возможные значения: CreateIndex, DropIndex. CreateIndex Сеансы типа могут создавать рекомендации типаCreateIndex. DropIndex Сеансы типа могут создавать рекомендации или DropIndex ReIndex типы. |
| run_type | intelligentperformance.recommendation_run_type | Указывает способ, в котором был инициирован этот сеанс. Возможные значения: Scheduled. Сеансы автоматически выполняются согласно значению index_tuning.analysis_interval, назначаются тип Scheduledвыполнения. |
| state | intelligentperformance.recommendation_state | Указывает текущее состояние сеанса. Допустимые значения: Error, Success, InProgress. Сеансы, выполнение которых завершилось ошибкой, задано как Error. Сеансы, которые правильно выполнили выполнение, независимо от того, создаются ли они рекомендации, задаются как Success. Сеансы, которые по-прежнему выполняются, задаются как InProgress. |
| start_time | метка времени без часового пояса | Метка времени запуска сеанса настройки, создавшего эту рекомендацию. |
| stop_time | метка времени без часового пояса | Метка времени запуска сеанса настройки, создавшего эту рекомендацию. ЗНАЧЕНИЕ NULL, если сеанс выполняется или был прерван из-за некоторого сбоя. |
| recommendations_count | integer | Общее количество рекомендаций, созданных в этом сеансе. |
intelligentperformance.recommendations
Представление recommendations предоставляет все сведения обо всех рекомендациях, созданных в любом сеансе настройки, данные которого по-прежнему доступны в базовых таблицах.
| Имя столбца | тип данных | Description |
|---|---|---|
| recommendation_id | integer | Число, однозначно определяющее рекомендацию на всем сервере. |
| last_known_session_id | uuid | Каждый сеанс настройки индекса назначается глобально уникальным идентификатором. Значение в этом столбце представляет собой сеанс, который недавно создал эту рекомендацию. |
| database_name | varchar(64) | Имя базы данных, в контексте которой была создана рекомендация. |
| recommendation_type | intelligentperformance.recommendation_type | Указывает тип создаваемой рекомендации. Допустимые значения: CreateIndex, DropIndex, ReIndex. |
| initial_recommended_time | метка времени без часового пояса | Метка времени запуска сеанса настройки, создавшего эту рекомендацию. |
| last_recommended_time | метка времени без часового пояса | Метка времени запуска сеанса настройки, создавшего эту рекомендацию. |
| times_recommended | integer | Метка времени запуска сеанса настройки, создавшего эту рекомендацию. |
| reason | text | Причина, по которой объясняется, почему эта рекомендация была создана. |
| recommendation_context | json | Содержит список идентификаторов запросов для запросов, затронутых рекомендацией, тип рекомендуемого индекса, имя схемы и имя таблицы, в которой рекомендуется использовать индекс, столбцы индекса, имя индекса и предполагаемый размер в байтах рекомендуемого индекса. |
Причины создания рекомендаций по индексу
При настройке индекса рекомендуется создать индекс, он добавляет по крайней мере одну из следующих причин:
| Причина |
|---|
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Причины удаления рекомендаций по индексу
Когда настройка индекса определяет любые индексы, помеченные как недопустимые, он предлагает удалить его со следующей причиной:
The index is invalid and the recommended recovery method is to reindex.
Дополнительные сведения о том, почему и когда индексы помечены как недопустимые, см . в официальной документации по REINDEX в PostgreSQL.
Причины удаления рекомендаций по индексу
Если настройка индекса обнаруживает индекс, который не используется по крайней мере, количество дней, заданных в index_tuning.unused_min_period, оно предлагает удалить его со следующей причиной:
The index is unused in the past <days_unused> days.
Когда настройка индекса обнаруживает повторяющиеся индексы, один из повторяющихся выживает, и он предлагает удалить оставшиеся. Причина, указанная всегда имеет следующий начальный текст:
Duplicate of <surviving_duplicate>.
За другим текстом, объясняющим причину того, почему для удаления выбран каждый из дубликатов:
| Причина |
|---|
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Если индекс не только является съемным из-за дублирования, но и не используется в течение, по крайней мере, количества дней, заданного в index_tuning.unused_min_period, следующий текст добавляется к причине:
Also, the index is unused in the past <days_unused> days.
Применение рекомендаций по индексу
Рекомендации по индексу содержат инструкцию SQL, которую можно выполнить для реализации рекомендации.
В следующих разделах показано, как можно получить эту инструкцию для конкретной рекомендации.
После получения инструкции можно использовать любой клиент PostgreSQL вашего предпочтения для подключения к серверу и применить рекомендацию.
Получение инструкции SQL с помощью страницы настройки индекса в портал Azure
Войдите в портал Azure и выберите экземпляр гибкого сервера База данных Azure для PostgreSQL.
Выберите параметр "Настройка индекса" в разделе "Интеллектуальная производительность " в меню.
Если настройка индекса уже создана, выберите сводку рекомендаций по индексу представления, чтобы получить доступ к списку доступных рекомендаций.
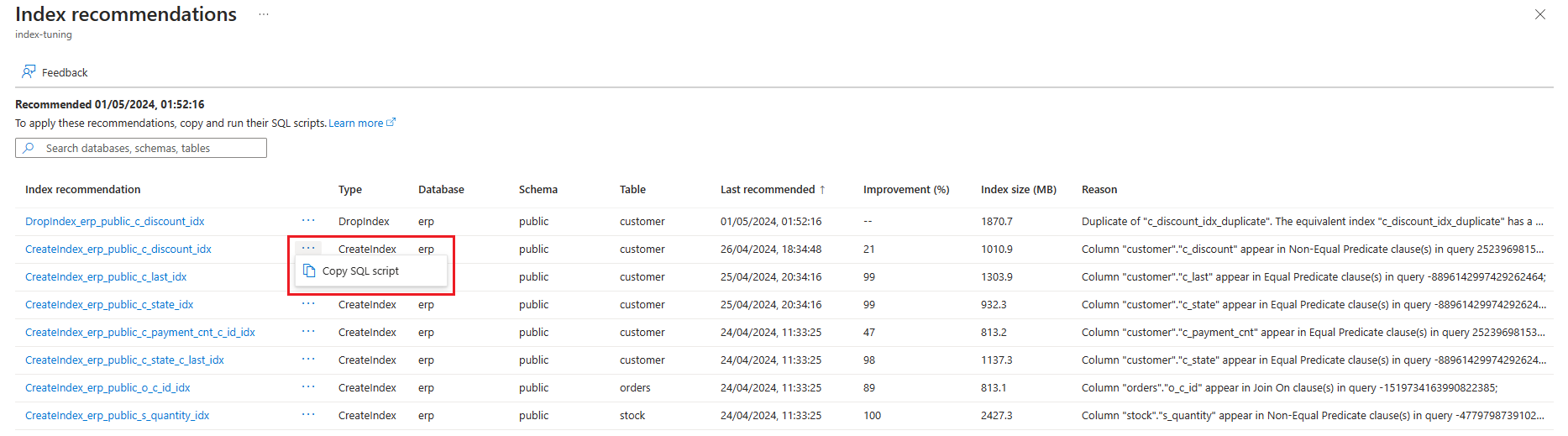
В списке рекомендаций либо:
Выберите многоточие справа от рекомендации, для которой требуется получить инструкцию SQL, и выберите "Копировать скрипт SQL".
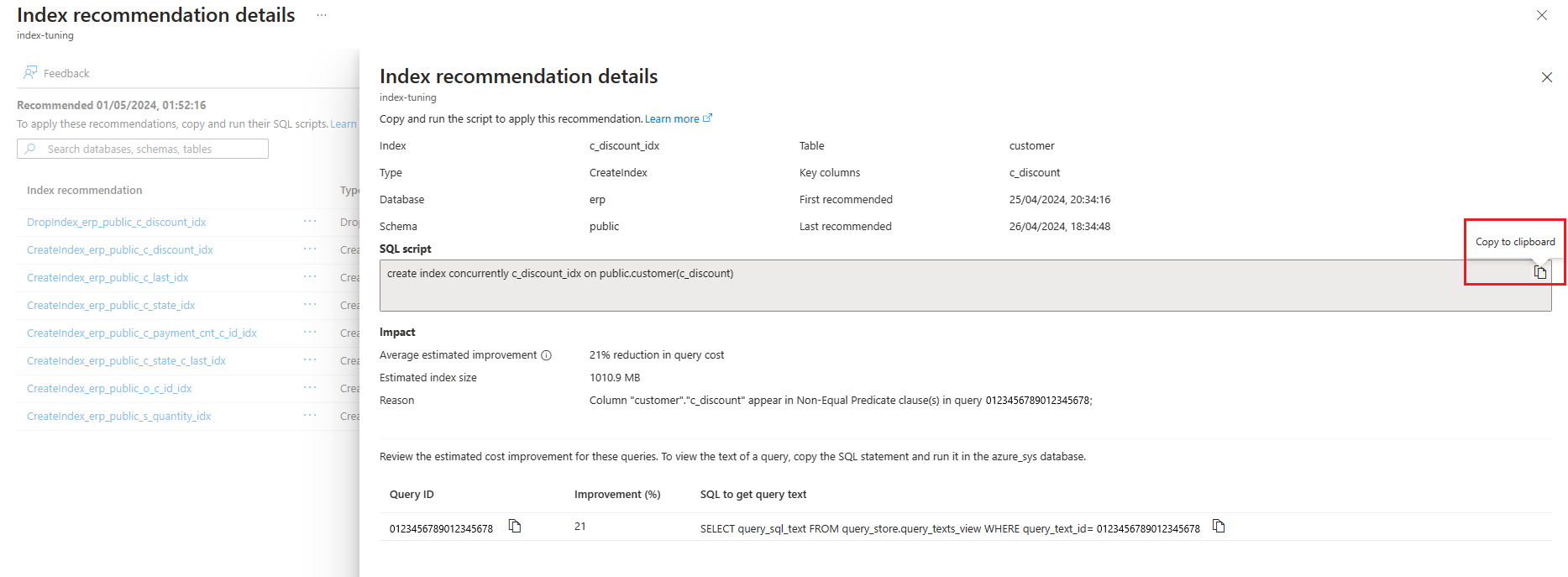
Или выберите имя рекомендации, чтобы отобразить сведения о рекомендации индекса, и щелкните значок копирования в буфер обмена в текстовом поле скрипта SQL, чтобы скопировать инструкцию SQL.

Связанный контент
- Настройка индекса в База данных Azure для PostgreSQL — гибкий сервер.
- Настройте настройку индекса в База данных Azure для PostgreSQL — гибкий сервер.
- Мониторинг производительности с помощью хранилище запросов.
- Сценарии использования для хранилище запросов — База данных Azure для PostgreSQL — гибкий сервер.
- Рекомендации по хранилище запросов — База данных Azure для PostgreSQL — гибкий сервер.
- Анализ производительности запросов для База данных Azure для PostgreSQL — гибкий сервер.