Запуск n-уровневого приложения в нескольких регионах Azure Stack Hub для обеспечения высокой доступности
Эта эталонная архитектура демонстрирует набор проверенных рекомендаций по работе с n-уровневыми приложениями в нескольких регионах Azure Stack Hub, благодаря которым можно достигнуть высокой доступности и получить надежную инфраструктуру аварийного восстановления. В этом документе для обеспечения высокой доступности используется диспетчер трафика, но если он не является предпочтительным вариантом для вашей среды, то можно заменить его парой высокодоступных подсистем балансировки нагрузки.
Примечание
Обратите внимание, что в Azure необходимо настроить диспетчер трафика, используемый в архитектуре, а конечные точки, используемые для настройки профиля диспетчера трафика, должны быть общедоступными маршрутизируемыми IP-адресами.
Архитектура
Эта архитектура создана на основе архитектуры, описанной в статье N-уровневое приложение с SQL Server.
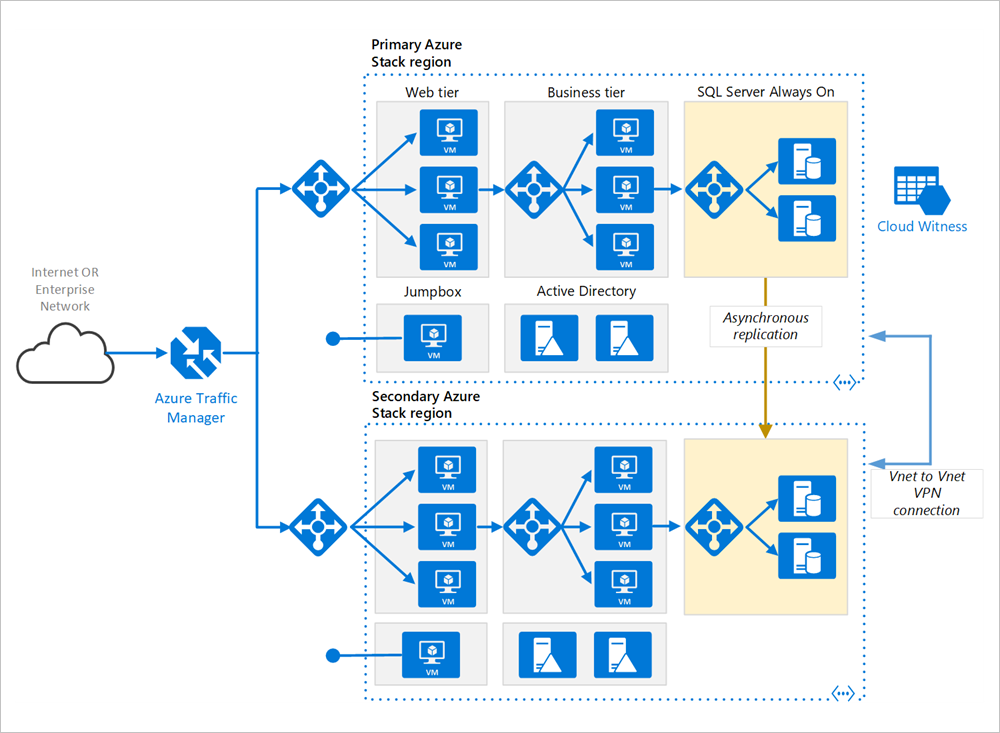
Основной и дополнительный регионы. Чтобы достичь более высокого уровня доступности, используйте два региона Azure, один из которых является основным, а второй предназначен для отработки отказа.
Диспетчер трафика Azure. Диспетчер трафика направляет входящие запросы к одному из регионов. При обычной работе он направляет запросы в основной регион. Если этот регион становится недоступным, диспетчер трафика выполняет отработку отказа в дополнительный регион. Дополнительные сведения см. в разделе Конфигурация диспетчера трафика.
Группы ресурсов. Создайте отдельные группы ресурсов для основного и дополнительного регионов. Так вы получите возможность управлять каждым регионом как одной коллекцией ресурсов. Например, можно повторно развернуть один регион, не отключая другой. Свяжите группы ресурсов, чтобы запустить запрос на перечисление всех ресурсов приложения.
Виртуальные сети. Создайте отдельные виртуальные сети для каждого региона. Убедитесь, что указанные пространства адресов не перекрываются.
SQL Server Always On группы доступности. При использовании SQL Server рекомендуется использовать группы доступности SQL Always On для обеспечения высокого уровня доступности. Создайте одну группу доступности, которая включает экземпляры SQL Server в обоих регионах.
VPN-подключение типа "виртуальная сеть — виртуальная сеть". Так как Пиринг виртуальных сетей еще недоступен в Azure Stack Hub, используйте VPN-подключение типа "виртуальная сеть — виртуальная сеть" для подключения двух виртуальных сетей. Дополнительные сведения см. в статье Инструкции по подключению двух виртуальных сетей через пиринг.
Рекомендации
Архитектура с несколькими регионами может обеспечить более высокий уровень доступности, чем развертывание в одном регионе. Если региональный сбой влияет на основной регион, можно использовать диспетчер трафика для выполнения отработки отказа в дополнительный регион. Эта архитектура также помогает при сбое отдельной подсистемы или приложения.
Есть несколько общих подходов к достижению высокого уровня доступности в регионах:
Активный и пассивный режим с горячим резервированием. Трафик отправляется в один регион, в то время как другой ожидает в режиме "горячего" резерва. "Горячий" резерв применяется, когда виртуальные машины в дополнительном регионе выделены и выполняются постоянно.
Активный и пассивный режим с холодным режимом ожидания. Трафик отправляется в один регион, в то время как другой ожидает в режиме "холодного" резерва. "Холодный" резерв предполагает, что виртуальные машины в дополнительном регионе выделяются, только когда они требуются для отработки отказа. Этот подход экономичнее, однако при сбое для выхода в динамический режим требуется больше времени.
Активный /активный. Оба региона активны, нагрузка запросов балансируется между ними. Если один регион отключается, он изымается из ротации.
В этой эталонной архитектуре уделяется внимание режиму "активный — пассивный" с "горячим" резервом, а также использованию диспетчера трафика для отработки отказа. Вы можете развернуть несколько виртуальных машин в качестве "горячего" резерва, а затем масштабировать их при необходимости.
Конфигурация диспетчера трафика
При настройке диспетчера трафика необходимо учитывать следующее:
Маршрутизация. Диспетчер трафика поддерживает несколько алгоритмов маршрутизации. Для сценария, описанного в этой статье, используется маршрутизация по приоритету (ранее называлась маршрутизацией отработки отказа). С помощью этой функции диспетчер трафика отправляет все запросы в основной регион, если дополнительный регион не станет недоступным. В этот момент он автоматически выполняет отработку отказа в дополнительный регион. Дополнительные сведения см. в статье о настройке метода маршрутизации с отработкой отказа.
Проба работоспособности. Диспетчер трафика использует проверку HTTP (или HTTPS) для мониторинга доступности каждого региона. При этом проверяется код ответа HTTP 200 в заданном пути URL-адреса. Рекомендуется создать конечную точку, которая сообщает о работоспособности приложения, и использовать ее для проверки работоспособности. В противном случае при проверке может быть сообщено о работоспособной конечной точке, тогда как критические части приложения фактически не будут работать. Дополнительные сведения см. в статье Шаблон мониторинга конечных точек работоспособности.
При выполнении отработки отказа диспетчера трафика в течение определенного времени клиенты не могут связаться с приложением. Этот период зависит от следующих факторов:
При проверке работоспособности определяется, что с основным регионом невозможно связаться.
DNS-серверы должны обновить кэшированные записи DNS для IP-адресов, которые зависят от срока существования DNS. Срок существования по умолчанию — 300 секунд (5 минут), однако это значение можно настроить при создании профиля диспетчера трафика.
Дополнительные сведения см. в статье о мониторинге в диспетчере трафика.
При отработке отказа диспетчера трафика ее рекомендуется выполнять вручную, а не внедрять автоматическую отработку отказа. В противном случае могут возникнуть ситуации, в которых приложение будет переходить между регионами. Убедитесь, что все подсистемы приложения полностью работоспособны, и лишь затем выполните восстановление размещения.
Обратите внимание, что диспетчер трафика по умолчанию автоматически восстанавливает размещение. Чтобы избежать этого, вручную понизьте приоритет основного региона после отработки отказа. Например, предположим, что основной регион имеет приоритет 1, а дополнительные — приоритет 2. После отработки отказа задайте основному региону приоритет 3, чтобы избежать автоматического восстановления размещения. Когда вы будете готовы переключиться, измените приоритет на 1.
Следующая команда Azure CLI обновляет приоритет:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Другой подход заключается во временном отключении конечной точки, пока не появится возможность восстановить размещение:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
В зависимости от причины отработки отказа может потребоваться повторное развертывание ресурсов в пределах региона. До восстановления размещения выполните тест готовности к работе. При этом проверяется следующее:
правильная настройка виртуальных машин (все необходимое программное обеспечение установлено, IIS выполняются и т. д.);
работоспособность подсистем приложения;
функциональное тестирование (например, доступен ли уровень базы данных с веб-уровня).
Настройка группы доступности AlwaysOn SQL Server
До Windows Server 2016 для групп доступности SQL Server Always On требовался контроллер домена, а все узлы в группе доступности должны были находиться в одном домене Active Directory (AD).
Чтобы настроить группу доступности, сделайте следующее:
Поместите как минимум два контроллера домена в каждом регионе.
Предоставьте каждому контроллеру домена статический IP-адрес.
Создайте VPN-подключение, чтобы обеспечить обмен данными между двумя виртуальными сетями.
Для каждой виртуальной сети добавьте IP-адреса контроллеров доменов (из обоих регионов) в список DNS-серверов. Вы можете использовать следующую команду интерфейса командной строки. Дополнительные сведения см. в разделе Изменение DNS-серверов.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Создайте отказоустойчивый кластер Windows Server (WSFC), включающий экземпляры SQL Server в обоих регионах.
Создайте группу доступности Always On SQL Server, в которую включены экземпляры SQL Server в основном и дополнительном регионах. Дополнительные сведения о шагах см. в статье Extending AlwaysOn Availability Group to Remote Azure Datacenter (PowerShell) (Расширение групп доступности Always On на удаленный центр обработки данных Azure (PowerShell)).
Поместите первичную реплику в основной регион.
Поместите одну или несколько вторичных реплик в основной регион. Настройте для них использование синхронного фиксирования с автоматическим переходом на другой ресурс.
Поместите одну или несколько вторичных реплик в дополнительный регион. Настройте для них использование асинхронного фиксирования для повышения производительности (иначе все транзакции T-SQL должны ожидать кругового перехода по сети до дополнительного региона).
Примечание
Реплики асинхронной фиксации не поддерживают автоматический переход на другой ресурс.
Вопросы доступности
С помощью сложного n-уровневого приложения можно не реплицировать все приложение в дополнительном регионе. Вместо этого вы можете просто реплицировать критическую подсистему, необходимую для обеспечения непрерывной работы бизнеса.
Диспетчер трафика — это точка возможного сбоя в системе. Если происходит сбой диспетчера трафика, клиенты не смогут получить доступ к приложению во время простоя. Просмотрите соглашение об уровне обслуживания диспетчера трафика и подумайте, достаточно ли диспетчера трафика в соответствии с требованиями к высокой доступности в вашей организации. Если это не так, добавьте резервное решение для управления трафиком. Если в службе диспетчера трафика Azure произошел сбой, измените записи CNAME в службе доменных имен, чтобы они указывали на резервную службу управления трафиком. (Этот шаг нужно выполнить вручную, приложение будет отключено, пока изменения DNS не распространятся.)
В кластере SQL Server необходимо учитывать два сценария отработки отказа:
Происходит сбой всех реплик базы данных SQL Server в основном регионе. Например, это может произойти при региональном сбое. В этом случае необходимо вручную переключить группу доступности, несмотря на то, что диспетчер трафика автоматически переключается на внешнем интерфейсе. Выполните шаги в статье Perform a Forced Manual Failover of a SQL Server Availability Group (Выполнение принудительного перехода на другой ресурс вручную для группы доступности (SQL Server)), в которой описано, как выполнять принудительный переход на другой ресурс с помощью SQL Server Management Studio, Transact-SQL или PowerShell в SQL Server 2016.
Предупреждение
При принудительном переходе на другой ресурс есть риск потери данных. Когда основной регион будет восстановлен, сделайте моментальный снимок базы данных и используйте tablediff, чтобы найти отличия.
Диспетчер трафика выполняет отработку отказа в дополнительный регион, однако основная реплика базы данных SQL Server все еще доступна. Например, сбой внешнего уровня может не затронуть виртуальные машины SQL Server. В этом случае интернет-трафик направляется в дополнительный регион, а этот регион может все еще подключиться к основной реплике. Тем не менее будет увеличена задержка, так как подключения SQL Server пересекают регионы. В этом случае следует выполнить отработку отказа вручную следующим образом:
Временно переключите базу данных SQL Server в дополнительный регион для синхронной фиксации. Это гарантирует, что при отработке отказа не будет потери данных.
Выполните отработку отказа с переходом к этой реплике.
При восстановлении размещения в основном регионе восстановите параметр асинхронной фиксации.
Вопросы управляемости
При обновлении развертывания обновляйте один регион за раз, чтобы уменьшить вероятность глобального сбоя из-за неправильной конфигурации или ошибки в приложении.
Проверьте устойчивость системы к сбоям. Ниже приведены некоторые распространенные сценарии сбоев для тестирования:
завершение работы экземпляров виртуальной машины;
нехватка ресурсов, таких как ЦП и память;
отключение или задержка сети;
прекращение работы процессов;
завершение срока действия сертификатов;
моделирование сбоев оборудования;
завершение работы службы DNS на контроллерах домена.
Измерьте время восстановления и убедитесь, что оно соответствует вашим бизнес-требованиям. Следует также протестировать комбинации режимов отказа.
Дальнейшие действия
- Дополнительные сведения о шаблонах для облака Azure см. в статье Конструктивные шаблоны облачных решений.