Передовые практики для хранения данных с SQL Server 2008 (ru-RU)

Передовые практики для хранения данных с SQL Server 2008
SQL Server Технические статьи
** **
Писатели: Марк Уайтхорн, твердых качество наставников
Кейт Бернс, Microsoft
Технический рецензент: Эрик н. Хансон, Microsoft
** **
Опубликовано: Май 2008 г.
Относится К: SQL Server 2008
Предложенная статья является машинным переводом оригинала.
** **
Резюме: есть веские основания считать, что успешные данных проектов часто производят очень высокую отдачу от инвестиций. С годами было собрано много информации о факторах, способствующих успешной реализации против одной неудачной. Здесь они инкапсулируются в набор наилучших видов практики, которые представляются с уделением особого внимания возможности в SQL Server 2008. Применения передовой практики для проекта хранилища данных является одним из лучших инвестиций можно сделать по созданию успешных инфраструктуры бизнес-аналитики.
Авторское право
Это предварительный документ и может быть значительно изменён до окончательного коммерческого выпуска программного обеспечения, описанные здесь.
Информация, содержащаяся в настоящем документе представляет текущее представление корпорации Майкрософт по обсуждаемым на дату публикации. Поскольку корпорация Майкрософт должна реагировать на меняющиеся условия рынка, он не должен толковаться как обязательство корпорации Майкрософт, и корпорация Майкрософт не может гарантировать точность представленных сведений после даты публикации.
Этот документ является только в информационных целях. Корпорация Майкрософт не дает никаких гарантий, Экспресс, подразумеваемых или установленных законом, В отношении информации В НАСТОЯЩЕМ ДОКУМЕНТЕ.
Ответственность за соблюдение всех авторских прав и прав на интеллектуальную собственность целиком и полностью несет пользователь. Без ограничения авторских прав ни одна из частей этого документа не может быть воспроизведена, сохранена или использована в системах поиска либо передана в любой форме, любыми способами (электронными, механическими, в виде фотоко��ии, в виде записи или любыми другими) и для любых целей без письменного разрешения корпорации Майкрософт.
Корпорация Майкрософт может иметь патенты, патентные заявки, охраняемые товарные знаки, авторские или другие права на интеллектуальную собственность применительно к содержимому этого документа. За исключением, явно указанных в письменном лицензионном соглашении корпорации Майкрософт, предоставление данного документа не дает вам какой-либо лицензии на эти патенты, товарные знаки, авторские права или других видов интеллектуальной свойство.
** **
ÓКорпорация Майкрософт, 2008. Все права защищены.
** **
Microsoft Excel, PerformancePoint Server, SharePoint Server, SQL Server 2008, Visual Basic.Net, Visual C#, Visual C++ и Visual Studio являются товарными знаками или зарегистрированными товарными знаками корпорации Майкрософт в США и других странах.
** **
Названия реальных компаний и продуктов, упомянутые здесь могут быть торговыми марками их соответствующих владельцев.
Введение
Microsoft® SQL Server™ 2008 является превосходным выбором для строительства и эксплуатации хранилищ данных в предприятий любых размеров.
Термин, Business Intelligence (BI) описывает процесс извлечения информации из данных. Оперативные данные в большинстве предприятий проводится в системах на базе транзакций с конкретными функциями (HR, продаж, финансов и т.д.). Часто информация, испрошенная лиц, принимающих решения, в пределах предприятия требует данные из нескольких операционных систем. Действительно, более общего вопроса, такие, как «Что такое Наша текущая прибыль?» более операционных систем могут быть вовлечены в предоставлении данных.
Неотъемлемой частью любой системы BI является хранилище данных — центрального хранилища данных, которая регулярно обновляется из источник систем. Новые данные передаются через регулярные интервалы (часто ночные) путем извлечения, преобразования и загрузки (ETL) процессов.
Обычно данные в хранилище данных структурированы как звезда схема[1] хотя это также могут быть построены как нормализованных реляционных данных[2] или как гибрид между двумя. Не важно, какая структура будет выбран, после загрузки новых данных в хранилище данных, многие BI системы копирования подмножеств данных функция-витринах конкретных данных, где данные обычно структурировано как многомерный OLAP- куб как показано на рисунке 1.

Рисунок 1: Общий план хранилища данных
** **
На протяжении более 20 лет в той или иной форме были построены хранилища данных. В начале своей истории стало очевидным, что создание хранилища данных успешным является не является тривиальной задачей. Отчет IDC с 1996 года[3] представляет собой классический исследование состояния данных время. Как ни парадоксально он использовался как сторонников, так и противники хранения данных.
Сторонники утверждали, что он доказал эффективность данных хранилищ сославшись на что для 62 проектов, учился, означает возврат на инвестиции (ROI) за три года составил чуть более 400. Пятнадцать из этих проектов (25 процентов) показали ROI более чем на 600 процентов.
Недоброжелатели утверждает, что доклад был жгучая обвинительное заключение текущей практики хранилища данных из 45 проектов (с резко отклоняющихся значений со скидкой) 34% не вернуться даже стоимость инвестиций после пяти лет. Склад, который показал возврата не в том, что время не является хорошим вложением.
Оба набора цифры являются точными и, принятые вместе, отражать общие выводы самого документа, который говорит "один из наиболее интересных историй находится в диапазон от результатов. То же время 45 организаций, включенных в краткий анализ сообщили о результатах РУА между 3% и % 1 838, полный диапазон варьировала от всего – 1,857% до достигает 16 000%! "
Тревожит, тенденция к провал для проектов хранилища данных продолжается и сегодня: некоторые хранилищ данных показывают огромное ROI, другие явно не. В отчете около девяти лет позднее (2005), Gartner предсказал, что "более чем на 50 процентов проектов хранилища данных будет иметь ограниченное признание или будет неудачи до конца 2007 года" (Gartner пресс-релиз[4]).
Означает ли это, что мы узнали ничего в время? Нет, мы узнали многое о том, как для создания хранилищ данных успешно и набор наилучшей практики развивалась. Проблема, как представляется, что не все в поле известно об этой практики.
В настоящем документе мы рассмотрим некоторые из наиболее важных функций в SQL Server 2008 и наброски наилучшей практики для их эффективного использования хранения данных. Кроме того мы рассмотрим некоторые из более общие рекомендации по созданию проекта хранилища успешно данных. После передового опыта только не может конечно же, гарантировать успеха проекта хранилища данных; но он будет совершенствовать свои шансы неизмеримо. И это несомненно верно, что применение наилучшей практи��и является наиболее экономически эффективных инвестиций, вы можете сделать в хранилище данных.
Сопутствующий документ[5] описывает наращивать хранилищем данных с SQL Server 2008. Этот документ сосредоточен на планирование, проектирование, моделирование, и функционального развития ваших данных складской инфраструктуры. Обратитесь к документу компаньон для более подробно на производительность и масштаба проблем, связанных с хранилища данных конфигурация, запросов и управления.
Преимущества использования продуктов корпорации Майкрософт для хранения данных и бизнес-аналитики
BI системы являются, по необходимости, сложные. источник данных проводится в массив разрозненных оперативных приложений и баз данных. Системы BI должны превратить эти неоднородных наборы в сплоченной, точной и своевременной набор полезной информации.
Несколько различных архитектур может успешно применяться для хранилищ данных; Однако большинство включают следующее:
- Извлечение данных из источник систем, превращая его и последующей загрузки в хранилище данных
- Структурирование данных в хранилище как третья нормальная форма таблицы или в звезда/снежинка, не нормируется
- Перемещение данных в витринах данных, где она часто управляется многомерные двигателя
- Отчетности в его самом широком смысле, которая проводится из данных в хранилище и/или витринах данных: отчетности может осуществляться в форме все от вывода на печать и Microsoft Office Excel® электронные таблицы путем быстрого многомерного анализа для интеллектуального анализа данных.
SQL Server 2008 предоставляет все средства, необходимые для выполнения этих задач[6].
- SQL Server Integration Services (SSIS) позволяет создание и обслуживание подпрограмм ETL.
- Если используется SQL Server как источникданных, измененных данных функция значительно упрощает процесс извлечения.
- SQL Server database engine содержит и управляет таблиц, составляющих вашего хранилища данных.
- SQL Server Analysis Services (SSAS) управляет форму расширенной многомерных данных, оптимизированный для быстрого отчетности и простота понимания.
- SQL Server Reporting Services (SSRS) имеет широкий диапазон отчетности способностей, включая прекрасную интеграцию с Microsoft Excel и Microsoft Office Word. PerformancePoint Server™ позволяет легко визуализировать многомерные данные.
Кроме того Microsoft Office SharePoint Server® (MOSS) 2007 и Microsoft Office 2007 обеспечивают комплексный, easy-to-use, конечного пользователя окружающей среды, что позволяет вас распространить анализ и докладов, полученных от ваших данных хранилища данных в рамках всей Организации. SharePoint можно использовать для построения BI portal и панели мониторинга решений. Например можно создать карточки приложений на основе SharePoint, что позволяет сотрудникам получить настройки отображения метрик и ключевые индикаторы производительности (KPI) в зависимости от их роли задание .
Как вы ожидаете от законченное решение end-to-end, уровень интеграции между компонентами чрезвычайно высока. Microsoft Visual Studio® обеспечивает последовательного пользовательского Интерфейса с которого водить как SQL Server и служб Analysis Services и, конечно, она может использоваться для разработки приложений BI в широком диапазон языков (Visual C#®, Visual C++®, Visual Basic.Net®, и так далее).
SQL Server является легендарный для его низкая совокупная стоимость владения (TCO) в BI решения. Одной из причин является, что инструменты вы должны прийти в поле в нет бесплатно — другие продавцы обвинение (и значительно) для инструментов ETL, многомерные двигателей и так далее. Еще одним фактором является Microsoft известных акцент на простоту использования которого, в сочетании с интегрированной среды разработки Visual Studio приносит, значительно сокращает время обучения и затраты на разработку.
Рекомендации: Создание значение для вашего бизнеса
Основное внимание в настоящем документе уделяется техническим рекомендациям. Однако опыт показал, что многие хранилищ данных и BI проекты не не по техническим причинам, но из-за трех Ps — личностей, борьба за власть и политика.
Найти спонсора
Ваш спонсор должен быть кто-то на самом высоком уровень в рамках Организации, кто-то с волей и полномочиями давать проекта сильной политической поддержкой, она понадобится. Почему?
Некоторые деловые люди поняли, что контроля информации означает власть. Они видно склад как активную угрозу их власти, потому что он делает информацию доступной. По политическим причинам эти люди могут исповедовать полная поддержка системы BI, но на практике быть эффективно хронической.
Команда BI может не имеют необходимого влияния, для преодоления подобных препятствий или инерции, которая может исходить от высших эшелонах управления: то есть задание спонсора.
Получить право архитектуры в начале
Общую архитектуру всей системы BI должна быть тщательно спланирована на ранних стадиях. В качестве примера частью этого процесса ходатайством для выравнивания структуры с принципы построения Ральф Кимбалл или Билл Inmon (см. ссылки).
Разработка эксперимента
Решаем доказательство концепции проект является отличным способом получить поддержку и влиять на людей. Это может включать создание куб OLAP и использование программного обеспечения визуализации для одной (или нескольких) бизнес-единиц. Этот проект может использоваться для отображения деловых людей, что они могут ожидать от новой системы, а также для подготовки команды BI. Выберите проект с небольшой и четко определенной область , сравнительно легко достичь. Выполн��ние доказательство концепции требует вложения времени, усилий и денег, но, ограничивая область, ограничить расходы и обеспечить быстрый возврат на инвестиции.
Выберите доказательство концепции проектов на основе быстрое ROI
При выборе доказательство концепции проекта, это может быть полезным мероприятием для обсудите их потребности с 10 или около того бизнес-единиц. Оценка их потребностей, трудности и рентабельность инвестиций. Опыт свидетельствует о том, что часто существует мало корреляция между стоимость разработки куб и ROI, он может генерировать, так что это мероприятие следует определить несколько low усилий, высокодоходные проектов, каждый из которых должен быть превосходных кандидатов для подтверждения концепции проектов.
Постепенно доставить большое значение проектов
Создавая наиболее прибыльных решений во-первых, хорошая Рентабельность может быть обеспечена для проекта хранилища данных после начальных этапов. Если первый шаг расходы, скажем $250000 и рентабельность инвестиций составляет $1 млн в год, после первых трех месяцев работы первоначальные затраты будут были возвращены.
Простота использования и высокий уровень интеграции между компонентами Microsoft BI ценные активы, которые помогут вам достичь результатов своевременно; Это поможет вам быстро мобилизовать поддержку от вашего бизнес-пользователей и спонсоров. Значение остается очевидным, как развить доказательство концепции проекта и начать с выгодой по всей Организации.
Проектирование вашего хранилища данных/BI решения
В этом разделе обсуждаются две области передового опыта. К первому относятся общий дизайн руководящие принципы, которые должны быть рассмотрены на старте проекта. Они следуют указания об указании оборудования.
Лучшие практики: Первоначальный дизайн
Держите дизайн в соответствии с аналитических потребностей пользователей
Как только мы начинаем обсуждать качественных данных хранилища дизайн мы должны ввести оба законопроекта Inmon[7] и Ральф Кимбалл[8]. Оба внесли чрезвычайно для нашего понимания хранилищ данных и как писать многие аспекты проектирования склада. Их мнения часто характеризуются следующими способами:
- Inmon отдает предпочтение хранилище нормализованных данных.
- Kimball отдает предпочтение хранилище трехмерных данных.
Склады с этими структурами, часто называются Inmon склады или Кимбалл склады. Корпорация Майкрософт имеет не предвзятости в любом случае, и SQL Server вполне способен поддерживать любой дизайн. Мы отмечаем, что большинство наших клиентов пользу мерных склад. В ответ мы ввели оптимизации схемы "звезда", чтобы ускорить запросы таблиц фактов и измерений.
Компьютерной индустрии понял, как оформить транзакционных систем начиная с 1970-х. Начнем с требований пользователя, которые мы можем описать как модель пользователей. Оформить их в логическую модель пользователи могут согласовать и утвердить. Добавьте технических деталей и превратить это в физическая модель. После этого это просто вопрос воплощению…
Проектирование хранилища данных должны следовать принципам и быть процесс проектирования на требования пользователей. Единственное отличие состоит, что для хранилища данных, эти требования не функционирует, но аналитической.
На крупном предприятии пользователи, как правило, разбит на множество групп, каждая с различных аналитических потребностей. Часто пользователи в каждой группе сформулировать анализа они нуждаются (пользователя модель анализа) с точки зрения графики, сетки данных (листов) и печатных отчетов. Это визуально очень разные, но все по существу настоящего числовые меры фильтровать и группировать члены одного или нескольких измерений.
Таким образом мы может захватить аналитических потребностей группы просто путем закрепления мер и измерений, которые они используют. Как показано на рисунке 2, они могут быть захвачены вместе с соответствующим иерархические данные в модели sun, которая является логической модели аналитических потребностей.
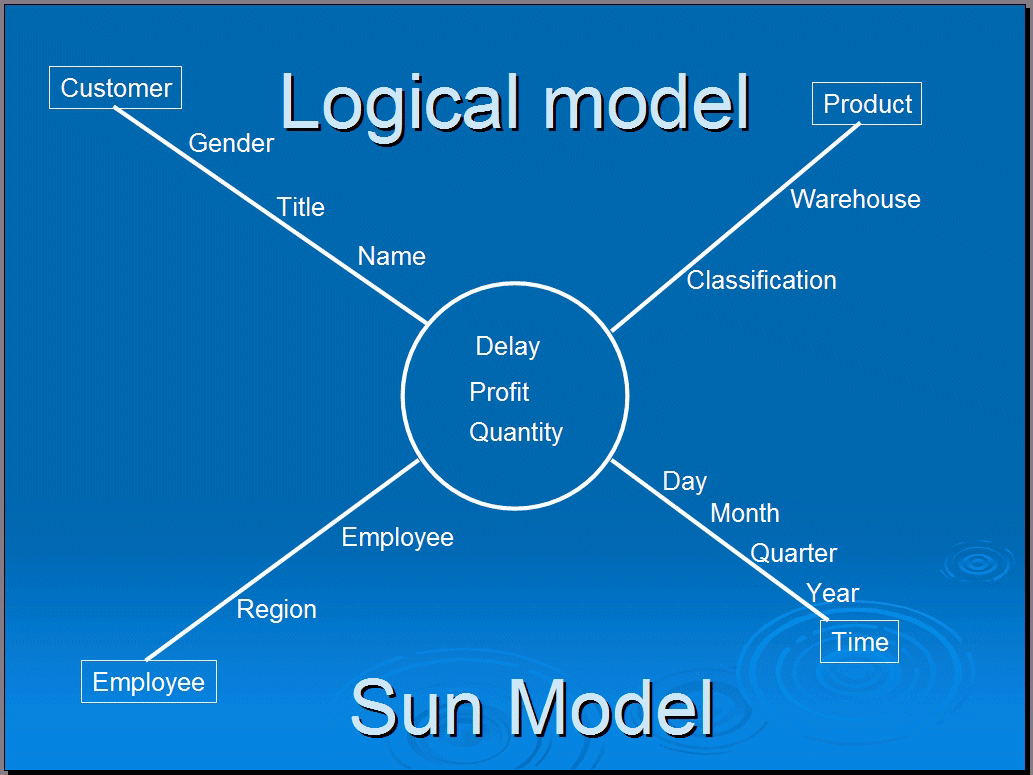
Рисунок 2: Sun модель, используемая для сбора аналитических потребностей пользователей с точки зрения мер, измерения и иерархическую структуру. Это логическая модель, производных от модели пользователя.
После того, как были успешно захватили эти аналитические потребности, мы можем добавить технические детали. Это превращает логических моделей в один физический, схемы "звезда", показано на рисунке 3.

Рисунок 3: Представление или звезда схему, которая является примером физической модели аналитических потребностей
Схемах "звезда" в конечном счете могут быть реализованы как набор мерных и таблицы фактов в хранилище данных и/или как Кубы (ROLAP, HOLAP или MOLAP), которые могут быть размещены в нескольких витринах данных.
Для разработки системы ETL для доставки данных для этой структуры, мы должны понять характер данных в источник систем.
Чтобы доставить аналитики, которые пользователи содержащимися в их требованиях, мы должны найти соответствующие данные в источник систем и превратить его надлежащим образом. В идеальном мире источник систем поставляются с отличной документацией, которая включает в себя значимые имена таблица и столбец . Кроме того источник приложения прекрасно спроектированы и разрешить только данные, которые входят в соответствующий домен должен быть заключен. Назад на планете Земля источник систем редко соответствуют эти требовательным стандартам.
Вы можете знать, что пользователи должны анализировать продажи, Пол клиента. К сожалению совершенно не источник системы, но вы найдете столбец с именем Gen в таблица под названием CUS_WeX4. Дальнейшее расследование показывает, что столбец можно хранить данные, касающиеся Пол клиента. Предположим, что можно определить, что он содержит 682370 строк и что распространение данных является:
** **
M |
234543 |
F |
342322 |
Почта |
5 |
Femal |
9 |
Жен. |
4345 |
Да |
43456 |
No |
54232 |
Муж. |
3454 |
Девочка |
4 |
** **
Теперь у вас больше доказательств того, что это правильный столбец и у вас также есть представление о стоящих перед нами в разработке процесса ETL.
Другими словами знание распределения данных имеет важное значение во многих случаях не только определить соответствующие столбцы, но и для того, чтобы понять (и в конечном итоге дизайн) процесс преобразование .
Использование данных профилирования для изучения распределения данных в источник систем
В прошлом обретения понимания распределения данных в источник систем означает выполнения нескольких запросов (часто группа BYs) источник системных таблиц определить домен значений в каждом столбец. Эту информацию можно было сравнить с информация, представленная эксперты домен и определенных преобразований.
Службы Integration Services имеет новую задачу «Профилирование данных», что делает намного проще с первой частью этого задание . Можно использовать собранные сведения, с помощью данных профилировщика для определения правила преобразование соответствующих данных для обеспечения ваше хранилище данных содержит "чистых" данные после ETL, что приводит к более точных и надежных результатов анализа. Профилировщик данных — задачи потока данных, в котором можно определить нужную информацию профиля.
Восемь данных профили доступны; пять из них анализа отдельных столбцов:
- Соотношение Null столбцов
- Распределения значений столбцов
- Распределение длины столбцов
- Статистика по столбцам
- Столбец шаблона
Три анализировать несколько столбцов или отношения между таблицами и столбцами:
- Потенциальный ключ
- Функциональная зависимость
- Включение значений
Несколько профилей данных для нескольких столбцов или сочетаний столбец может быть вычислен с одной задачи «Профилирование данных» и выходны�� данные могут быть направлены на XML-файла или пакет переменной. Первый является лучшим вариантом для ETL проектные работы. Средство просмотра профиля данных, показанный на рисунке 4, предоставляется как исполняемый, который может использоваться для изучения XML-файла и следовательно профиля данных.
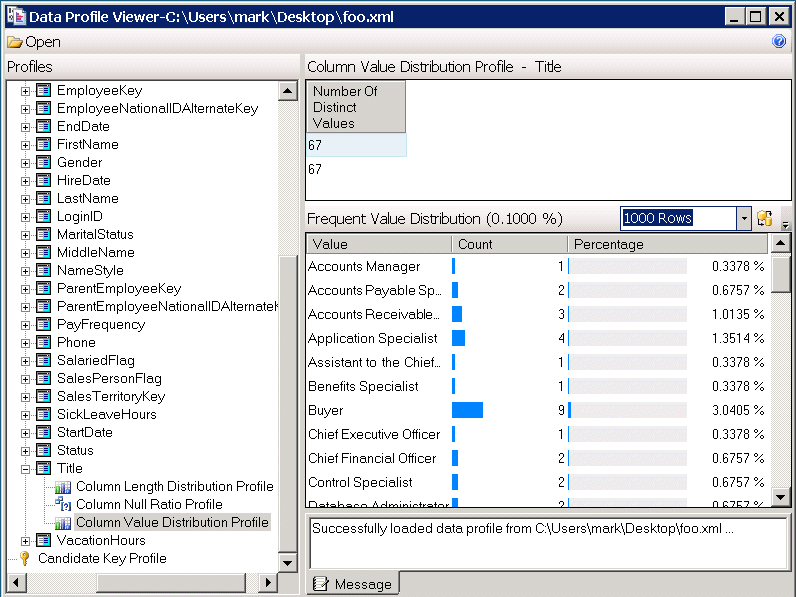
Рисунок 4: Просмотр профиля данных
Дизайн с самого начала для разделения больших таблиц, таблиц особенно большое фактов
Независимо от того, насколько хорошо индексации и как быстро аппаратное обеспечение, больших таблиц может привести к длительным системы управления операций, таких, как создание индекса и удаления старых данных. Это может быть особенно очевидны для больших факт таблиц. Таким образом секционирование таблиц, если они велики. В целом, если в таблица больше чем 50 ГБ, решили вам следует его (см. Склад Настройка реляционных данных, запрос и управления позже в этом документе).
План по возрасту из старых данных справа от начала
Одна из основных функций хранилища данных является проследить историю бизнеса предприятия — то, что системы- источник обычно делать особенно сильно. Отслеживание истории означает, что хранилище данных приобретут огромное количество данных с течением времени. Как данных возрастов, менее часто, а также по-разному осуществляется (как правило, агрегаты, а не детали). В конечном итоге становится необходимым для лечения старых данных по-разному, возможно с помощью медленнее, дешевле хранения, возможно хранение только агрегаты, удалив его, или другой план. Это имеет жизненно важное значение для планирования этого права с самого начала. Секционирование делает это намного проще (см. Склад Настройка реляционных данных, запрос и управления позже в этом документе).
Наиболее оптимальные методы: Определение оборудования
Дизайн для поддержания эксплуатационные характеристики, не только производительность запрос
Определение оборудования никогда не легко, но это общий (и хорошо) практика при принятии решений оборудования сосредоточить основное внимание на производительность запрос по той простой причине, что производительность запрос имеет жизненно важное значение. Однако важно также не упускать из виду другие соображения.
Подумайте о производительности запрос . Очень упрощенно считает, что он масштабируется линейно с размером данных. Поколения DBA научились нелегкий путь, что она часто не масштаб таким образом — удвоить размер данных и запрос может занять десять раз для запуска — так что они могут соответственно план требования к оборудованию. Но это несколько упрощенный подход.
Например, рассмотрим запрос , который выполняется 1‑терабайт таблица. Ее производительность ограничивается многих факторов — индексации, памяти, количество строк сканирования, количество возвращенных строк и так далее. Представьте себе, что запрос эффективно использует индексы, проверяет некоторые фиксированное количество строк и возвращает только несколько строк. Если мы этот же запрос запустить 2 терабайт данных в той же таблица и взять на себя индексирование был применен эффективно и что количество отсканированных и возвращенных строк не значительно отличается, время реакции составляет примерно такая же. Конечно это будет ничего подобного двойной время. Другими словами производительность запрос иногда можно масштабировать в нелинейных способ наше преимущество. Однако другие факторы, такие как время резервного копирования, линейно масштабировать ожидаемым образом. Резервное копирование дважды данных занимает два раза ресурсы (например, Процессорного времени и пропускной способности ввода/вывода), которые могут также повлиять на технические характеристики оборудования, необходимого для удовлетворения ваших потребностей.
Другими словами когда мы разрабатываем крупных BI системы мы должны быть тщательно рассмотреть все соответствующие факторы. Это не означает, что производительность запрос важна; Это по-прежнему наиболее важным соображением. Но это также ошибкой сосредоточиться исключительно на этом вопросе. Другие факторы, такие как поддержание системы BI (как реляционных и многомерных компонентов) должны рассматриваться тщательно, а.
** **
Укажите достаточно основной памяти, так что большинство запросов никогда не делать ввода/вывода
По словам Microsoft SQL Server клиента Консультативная группа инженеров, в большинстве хранилищ данных данные весьма неравномерно доступны. На сегодняшний день большинство запросов доступа к некоторым доля же 20% от общей суммы; Иными словами около 80% от данных редко осуществляется. Это означает, что диск ввода/вывода для склада общей резко уменьшает если есть достаточно основной памяти для хранения около 20% от общего объема данных.
ETL
поле ETL (извлечения, преобразования и загрузки) является наиболее сложной области хранения данных[9]. Сами данные часто является сложным и требует целый диапазон методов и процессов применяться перед загрузкой в хранилище. Они включают в себя слияния, время/Дата тиснения, устраняющие и наследования, преобразования типов данных, нормализации и/или Денормализация, суррогатного ключ вставки и общей чистки.
Рекомендации: Упростить процесс ETL и повышения производительности
Использовать службы SSIS для упрощения программирования ETL
SSIS был разработан с нуля до для упрощения процесса разработки вашего
кода ETL. Ее автоматизированных инструментов и стандартных преобразований и разъемы значительно уменьшить количество строк кода ETL, что вам нужно писать по сравнению с программирование в языкуровень традиционных высоко - или язык сценариев. Рекомендуется использовать службы SSIS, вместо того, чтобы эти методы, если сокращения количество кода для ETL и упрощения обслуживания задание ETL важно для вас.
SSIS предоставляет всеобъемлющий набор функций для построения хранилищ данных, в том числе:
- Масштабируемая трубопровода архитектура, обеспечивающая многопоточных 64‑битную платформу для преобразования растущих объемов данных в более узком пакет windows,
- Подключение к non-SQL Server СУБД, ЭВМ, ERP систем и других разнородных источников данных.
- Большое количество сложных преобразований для консолидации данных из многочисленных систем.
- Расширенные данные чистки преобразований для сокращения дублирования данных и грязные данных.
- Осознание хранилища данных, предоставляя возможность out-of--box управления медленно меняющихся измерений.
- Бесшовная интеграция с SQL Server BI платформой для непосредственного построения кубов служб Analysis Services и загрузить в разделы служб Analysis Services.
- Расширяемость с властью.Чистая путем включения пользовательских сценариев и подключаемых компонентов непосредственно в потоке интеграции данных.
** **
Упростить процесс преобразование с помощью задачи «Профилирование данных»
Новые задачи профилирования данных в службах Integration Services может использоваться для первоначально понять характер источник данных для проектирования целей (см. Проектирование Your данных хранилища/BI решение). Однако она производит профили могут также использоваться для применять бизнес-правила к данным в рамках процесса преобразование . Предположим, например, бизнес-правило говорит, что данные из определенного источник является приемлемым только если количество значения NULL не превышает 1%. Профили, производимые задачу «Профилирование данных» может использоваться для применения этого правила.
Обратите внимание, что задачи «Профилирование данных» профиль таблицы SQL Server; данные в других местах должны быть загружены в промежуточной таблицы до того, как можно выполнить профилирование.
Упростить с помощью СЛИЯНИЯ и INSERT INTO
Ли вы извлечение из источник систем в хранилище оперативных данных (ODS) или из СОД в таблицы фактов или измерений, необходимо управлять движением (дельты) произошедших изменений. На этом этапе часто требуется несколько запросов языка обработки данных (язык DML) для выполнения одной логической движение «дельты» в соответствующие таблица. Это особенно верно, когда вам придется иметь дело с медленно изменяющихся измерений (и кто не?).
SQL Server 2008 позволяет объединить эти несколько запросов в одной инструкции MERGE.
MERGE
Инструкция MERGE выполняет вставки, обновления или удаления операций для целевой таблица на основе результатов соединение с источник таблица.
Инструкция MERGE предоставляет три вида положений, когда:
- КОГДА MATCHED позволяет обновлять или удалять заданной строки в целевой таблица , когда источник и целевой строки соответствуют некоторые критерии или критерий.
- КОГДА не соответствует [BY TARGET] позволяет вставить строку в цель, когда он существует в источник , но не в целевом объекте.
- КОГДА не соответствует от ИСТОЧНИКА позволяет обновлять или удалять заданной строки в целевой таблица , если она существует в целевом объекте, но не в источник.
С каждым из предложений WHEN для выберите тип операции язык DML следует выполнять на строке можно указать условие поиска.
предложение OUTPUT для инструкции MERGE включает в себя новый виртуальный столбец под названием $действие который можно использовать для идентификации язык DMLдействие , выполненных в каждой строке.
Чтобы проиллюстрировать использование инструкции MERGE, представьте, что у вас есть таблица сотрудников:
** **
EmpID |
Название |
Название |
IsCurrent |
1 |
Джонс |
Ms |
Да |
2 |
Смит |
Проф |
Да |
3 |
Коричневый |
Г-Н |
Да |
4 |
Уилсон |
Д-Р |
Да |
5 |
Карлтон |
Д-Р |
Да |
** **
и таблица изменений:
** **
EmpID |
Название |
Название |
IsCurrent |
1 |
Джонс |
Проф |
Да |
6 |
Цапля |
Г-Н |
Да |
** **
Медленно изменяющегося измерения типа 1
Предположим, что первое что таблица является тип 1, медленно изменяющегося измерения, означает, что изменение в название поле разрешено просто перезаписать существующее значение и история не поддерживается изменение ни предыдущее значение. Далее предполагается, что новые строки в источник должны быть вставлены в сотрудники таблица а. Вы можете управлять этой простой вариант с инструкции MERGE:
Слияние работника как ТРГ
ИСПОЛЬЗОВАНИЕ EmployeeDelta SRC
НА (SRC.EmpID = ТРГ.EmpID)
КОГДА НЕ СООТВЕТСТВУЕТ ЗАТЕМ
ВСТАВИТЬ ЗНАЧЕНИЯ (SRC.EmpID, SRC.Имя, SRC.Название, 'Да')
ПРИ СОПОСТАВЛЕНИИ ЗАТЕМ
ОБНОВЛЕНИЕ НАБОРА ТРГ.Название = SRC.Название
Если мы добавим OUTPUT предложение следующим образом:
ВЫВОД $действие, SRC.EmpID, SRC.Имя, SRC.Название;
Мы получим следующий результат строк в дополнение к эффекту на таблицаEmployee:
** **
$action |
EmpID |
Название |
Название |
ВСТАВКА |
6 |
Цапля |
Г-Н |
ОБНОВЛЕНИЕ |
1 |
Джонс |
Проф |
** **
Это может быть очень полезно при отладке, но она также оказывается весьма полезным в решении медленно изменяющегося измерения типа 2.
Введите 2 медленно меняющихся измерений
Напомним, что в типа 2, медленно изменяющегося измерения, которое добавляется новая запись в измерение Employee таблица независимо от работника запись уже существует. Например мы хотим сохранить существующую строку для Джонс, но набор значение IsCurrent в этой строке значение 'No'. После этого мы хотим вставить обе строки из delta таблица ( источник) в цель.
** **
Слияние работника как ТРГ
ИСПОЛЬЗОВАНИЕ EmployeeDelta SRC
НА (SRC.EmpID = ТРГ.EmpID И ТРГ.IsCurrent = 'Yes')
КОГДА НЕ СООТВЕТСТВУЕТ ЗАТЕМ
ВСТАВИТЬ ЗНАЧЕНИЯ (SRC.EmpID, SRC.Имя, SRC.Название, 'Да')
ПРИ СОПОСТАВЛЕНИИ ЗАТЕМ
ОБНОВЛЕНИЕ НАБОРА ТРГ.IsCurrent = «No»
ВЫВОД $действие, SRC.EmpID, SRC.Имя, SRC.Название;
Это заявление задает значение IsCurrent значение «No» в существующей строке для Джонс и вставляет строку для цапля из delta таблица в таблица. Однако, она не вставить новую строку для Джонс. Это не представляют собой проблему, потому что мы можем решать что с новой функциональностью INSERT, описано далее. Кроме того у нас есть выход, который в данном вариант является:
** **
$action |
EmpID |
Название |
Название |
ВСТАВКА |
6 |
Цапля |
Г-Н |
ОБНОВЛЕНИЕ |
1 |
Джонс |
Проф |
** **
Новые функциональные возможности для вставки
Мы можно объединить возможность вывода данных с новой возможности в SQL Server 2008 имеют инструкции INSERT использовать результаты инструкций язык DML . Эта возможность потреблять вывода конечно же, можно весьма эффективно (и просто) следующим:
INSERT INTO сотрудник (EmpID, имя, название)
Выберите EmpID, имя, название от EmployeeDelta
Если мы объединим эта новая возможность мощностью выше, у нас есть синергических возможность извлечения строки, которая была обновлена (Джонс) и вставить их в таблица Employees для достижения желаемого эффекта в контексте медленно изменяющегося измерения типа 2:
Вставьте работника (EMPID, имя, название, IsCurrent)
Выберите «Да» EMPID, имя, название,
От
(
Слияние работника как ТРГ
ИСПОЛЬЗОВАНИЕ EmployeeDelta SRC
НА (SRC.EmpID = ТРГ.EmpID И ТРГ.IsCurrent = 'Yes')
КОГДА ЦЕЛЬ НЕ СООТВЕТСТВИЕ ЗАТЕМ
ВСТАВИТЬ ЗНАЧЕНИЯ (SRC.EmpID, SRC.Имя, SRC.Название, 'Да')
ПРИ СОПОСТАВЛЕНИИ ЗАТЕМ
ОБНОВЛЕНИЕ НАБОРА ТРГ.IsCurrent = «No»
ВЫВОД $действие, SRC.EmpID, SRC.Имя, SRC.Название
)
Как изменения (действие, EmpID, имя, название)
ГДЕ действие = 'Обновление';
Слияние в SQL Server 2008 был реализован для полного соответствия стандарту SQL-2006. Основной причиной является введение СЛИЯНИЯ в стандарте SQL и в SQL Server 2008 свою полезность в деле управления медленно изменяющимися измерениями, но следует помнить, что оба СЛИЯНИЯ и вставить с выходом имеют много других применений как внутри хранилищ данных конкретно и в базах данных в целом.
Прекратить все инструкции SQL с запятой в SQL Server 2008
До SQL Server 2005 Transact-SQL относительно расслабленной о символами точки с запятой; Некоторые операторы (включая СЛИЯНИЯ) в настоящее время требуют этого Терминатор. Если вы прекратить все инструкции SQL точкой с запятой, вам избежать проблем, если использование запятой является обязательным.
Если вы не допускает простоя, рассмотрите возможность использования разделов «пинг-понг»
Представьте себе, что у вас есть таблица фактов, разбитого на секции по месяцам. В настоящее время это август. Вам нужно загрузить сегодняшние данные в августе раздела, но ваши пользователи не может терпеть снижение производительности и потенциальных конфликтов блокировки, понесенных как вы загрузить его. Скопируйте августа раздела в другую таблица (рабочий таблица), загрузки данных в таблица, индекс при необходимости и затем просто переключение секций между таблицами.
Для загрузки данных, точно где вы хотите его как можно быстрее использовать минимальное протоколирование
Запись данных в базу данных обычно включает в себя два разных процесса записи на диск, после записи в базу данных и один раз в журнал (так транзакции может быть выполнен откат или Джесси). При вставке данных в существующей таблица это, на самом деле, можно написать только один раз в некоторых случаях, используя функцию протоколированием INSERT.
Минимальное ведение журнала позволяет транзакции, откат, но не поддерживает восстановление точка в время. Она доступна также только с неполным протоколированием и модели восстановления simple. В SQL Server 2008 можно использовать минимальное протоколирование с INSERT INTO…ВЫБРАТЬ из инструкций Transact-SQL при вставке большое количество строк в существующей таблица , если они вставляются в пустую таблица с кластеризованного индекса и некластеризованными индексами или на куче, пустые или нет, без индексов. (Для подробной информации и все последние изменения, см SQL Server 2008 электронной документации).
Это расширяет поддержку минимальное протоколирование, который 2005 включены навалом SQL Server импорта SELECT INTO, создание индекса и выполнении операций перестроения.
Одно из огромных преимуществ минимальное протоколирование — это ускоряет загрузку пустые разделы или таблицы, которые находятся на конкретных файловых групп. В SQL Server 2005 можно добиться эффективного тот же эффект с помощью работы вокруг изменить файловую группу по умолчанию и выполнение инструкции SELECT INTO для получения минимальное протоколирование. Затем файловая группа по умолчанию будет возвращаться в исходное состояние. Теперь вы можете просто создать таблица на filegroup(s), вы хотите, чтобы она находилась в, определить его схемы секционирование и затем загрузить его с INSERT INTO ТБП WITH(NOLOCK) SELECT FROM и вы добиться миним��льное протоколирование.
Минимальное протоколирование делает его намного проще поместить данные просто, где вы хотите его и записать его на диск только один раз. В качестве дополнительного бонуса производительность нагрузки увеличивается и уменьшается количество пространства журнала.
Упростить извлечение данных с использованием измененных данных висточник SQL Serverсистем
SQL Server 2008 имеет новые данные отслеживания особенность, которая особенно полезна в хранилище данных. Процесс отслеживания изменений в данных отслеживает изменения пользовательских таблиц и собирает их в реляционном формате. Типичное применение будет отслеживать изменения в оперативной базе данных для более поздних включения на складе.
Собирает процесса захвата об изменениях из журнала транзакций базы данных и вставляет его в таблицаизменений. Метаданные о каждой транзакции также вставляется втаблица метаданныетаким образом, чтобы изменения могут быть заказаны в связи с продолжительностью. Это позволяет идентифицировать, экземпляр, тип изменения, внесенного в каждую строку, и какой столбец или столбцы, изменилось в обновленной строки. Это также возможность запросить все строки, которые были изменены между датами время. Измененных данных представляет собой большой шаг к улучшению извлечения производительность, и делает программирование изменение захватить часть заданий ETL гораздо проще.
Упростить и ускорить процесс ETL с улучшение поиска
Производительность поиска компонент значительно улучшилась производительность в SQL Server 2008 Integration Services и намного проще для программирования.
Уточняющий запрос проверяет, имеет ли каждая строка в потоке строк совпадающие строки в набор справочных данных. Это часто используется в процесс ETL для проверки, например, ProductID столбец в факт таблица (действующим в качестве источникданных) против измерения таблица , содержащей полный набор продуктов (ссылка набор).
В SQL Server 2008, преобразование поддерживает два типа связи при подключении к эталонному набору данных: Диспетчер соединений с кэшем и диспетчер соединений OLE DB. Эталонным набором данных может быть файл кэша, существующая таблица или представление, новая таблица или результат SQL-запроса.
Справочные данные обычно кэшируется для эффективности и теперь поток данных может использоваться для заполнения кэша. Многие потенциальные источники могут быть использованы как справочные данные: Excel, XML, текст, веб-служб — что-либо в пределах досягаемости ADO.Чистый поставщик. В SQL Server 2005 кэш может заполняться только SQL- запрос и поиска может иметь только данные из определенных подключений OLE /DB. Новый компонент Преобразование кэша заполняет кэш определяется диспетчера соединений с кэшем.
Кэш больше не требуется повторно каждый раз, когда он используется: это устраняет скорость наказания путем перегрузки из реляционного источник. Если эталонный набор данных используется два конвейера в одном пакет, кэш могут быть сохранены для хранения постоянных файлов, а также виртуальной памяти, так что он доступен для нескольких поиска в пределах одного пакет. Кроме того, формат файла кэша оптимизирована по скорости, и его размер не ограничено.
Также Мисс cache особенность является новинкой. При запуске непосредственно против набора данных, компонент поиска можно добавить в кэш значения ключ из источник где есть не совпадающее значение в эталонном наборе данных. Так что если подстановки после определения, что ссылка набор не содержит, например, значение 885, он не тратит время осмотра ссылку набор для этого значения, если он снова появляется в источник данных. При определенных условиях эта функция может производить повышение производительности на 40%.
Наконец появилась ' поиска выход несовпадающих ' для «Мисс кэша» строк могут быть направлены вместо того, чтобы идти в вывод ошибок.
Настройка склада реляционных данных, запросов и управления
Реляционной базы данных является сердцем любой системы BI. Здесь лучшие практики затрагивают не только производительность всей системы, но также его гибкость и значение для предприятия. Для более глубокого обсуждения о том, как получить максимальную производительность от хранилищем данных SQL Server 2008 для крупномасштабных данных складов, обратитесь к документу компаньон[10].
Наилучшая практика: общие
Использование регулятора ресурсов для резервирования ресурсов для важной работы, такие как загрузка данных и для предотвращения бесконтрольного запросов
Нагрузку на хранилище данных может рассматриваться как серия запросов, которые бороться за имеющиеся ресурсы. В SQL Server 2005 существует один пул ресурсов и запросы соревновались в равной степени для тех. Регулятор ресурсов в SQL Server 2008 позволяет имеющиеся ресурсы должны выделяться на несколько (до 20) бассейны. Запросы классифицируются таким образом, чтобы они попадают в конкретных групп, и эти группы выделяются в пулы ресурсов — много запросов для каждого пула ресурсов. Процессы, которые должны быть завершены быстро (например, загрузки данных) могут быть выделены высокой ресурсов, когда они кончатся. Кроме того, важные доклады могут выделяться достаточно ресурсов, чтобы обеспечить прохождение они быстро[11].
Многие пользователи обнаруживают непредсказуемость производительности весьма разочаровывает. Если это произойдет, это выгодно использовать регулятор ресурсов для выделения ресурсов таким образом, что обеспечивает более предсказуемой производительности. Со временем по мере накопления опыта с регулятора ресурсов мы ожидаем это превратиться в наилучшей практики.
Предположим, как это часто вариант, что хранилище данных используется для обоих отчетности и ETL процессов и настроен для нуля или минимальное время простоя во время нагрузок. В некоторых предприятий (несмотря на то, что предпочтут команды BI) генерация отчетов на время рассматривается как более важной, чем завершение ежедневные нагрузки. В этом вариант отчетности группы рабочей нагрузки будут выделяться высокий приоритет.
Или, напротив, процесс загрузки может быть высокий приоритет с тем чтобы гарантировать минимальный простой, который требует бизнес.
И наконец следует отметить, что регулятор ресурсов также позволяет контролировать потребление ресурсов каждой группы, что означает, что использование ресурсов можно лучше понять, что в свою очередь позволяет более эффективного управления.
Тщательно планировать когда восстановить статистические данные и индексы
Оптимизатор запрос использует информацию из базы данных статистики (количество строк, распространение данных и т. д.) с тем, чтобы помочь определить план оптимального запрос . Если статистические данные являются неточными, может быть выбран менее оптимальный план, который снижает производительность запрос .
Если вы можете позволить себе время в течение вашего процесса ETL, перестройте статистики после каждой загрузки хранилища данных. Это гарантирует, что статистические данные всегда точны. Тем не менее восстановление статистики требует времени и ресурсов. Кроме того время между перестроение является менее важным, чем изменение распределения данных, имевшей место.
Когда хранилище данных является новой и развивающейся, а также относительно небольшой, имеет смысл для обновления статистики часто, возможно после каждой загрузки. Как склад созревает, иногда можно уменьшить частоту восстановления без ухудшения производительности запрос значительно. Если это важно для снижения стоимости обновления статистики, можно определить частоты обновления соответствующих статистика, мониторинг производительности запрос , как уменьшить частоту обновления. Имейте в виду, что если основная часть ваших запросов направлены только наиболее недавно загруженных данных, вам не будет иметь статистические данные для этих данных если обновить статистику после каждой загрузки. Это довольно распространенная ситуация, вот почему мы рекомендуем произвести обновление статистики после каждой загрузки хранилища данных по умолчанию.
Лучшие практики: Дата/время
Использование типа данных правильное время/Дата
SQL Server 2008 имеет шесть типов данных даты и времени:
- Дата
- datetime2
- DateTime
- DateTimeOffset
- smalldatetime
- время
Эти хранения временной информации с различной степенью точности. Выбор права одного позволяет поддерживать точное время и дата информацию таким образом, который лучше всего подходит для вашего приложения, экономит пространство хранения и улучшает производительность выполнения запрос . Например, многие более старые приложения SQL Server использовать datetime для дат, но пустым часть времени. Это занимает больше места, чем это необходимо. Теперь, вы можете использовать новый Дата типа для этих столбцов, которая принимает только три байта, по сравнению с восемью байтами для datetime.
Рассмотрите возможность использования datetime2 в некоторых портах база данных
datetime2 может считаться расширение существующих datetime тип — он сочетает в себе дату со временем, основанный на 24-часовом формате. Однако datetime2 имеет больший Дата диапазон, большую дробная точность по умолчанию и Дополнительные определяемые пользователем точностью. Точность такова, что он может хранить доли секунды до семи цифр — иными словами от в пределах одного десяти миллионную долю секунды. Эта новая функция может влиять на перенос некоторых приложений с хранилищами данных.
Например тип данных DB2 TimeStamp имеет точность миллионной доли секунды. В приложении хранилища данных, написанные на DB2 если логика приложения создается для обеспечения новых записей создана по крайней мере один микросекунд друг от друга, (который не является особенно обременительным ограничение), время/дата может использоваться как уникальный идентификатор. Мы можем обсудить ли это рекомендуется разработать приложение базы данных таким образом, но тот факт, что иногда это делается с базой данных DB2.
До появления datatime2, если такое ходатайство были перенесены в SQL Server, логика приложения необходимо переписать потому что datetime обеспечивает точность только одной тысячной доли секунды. Потому что datetime2 десять раз более точными, чем DB2 TimeStamp, приложение теперь может быть перенесен без изменения логики.
Лучшие практики: Сжатие и шифрование
Использовать сжатие страниц для уменьшения объема данных и ускорит выполнение запросов
Полномасштабные данных возможность сжатия была добавлена к SQL Server 2008; улучшения бывают двух типов — строк и страниц.
Сжатие ROW хранит все поля в формате переменной ширины. Если данные со сжатием, сжатие row уменьшает количество байтов, необходимое для их хранения.
Сжатие Page делает то же самое, но сжатие происходит между строк в пределах каждой страницы. Страница -уровень словарь используется для хранения общих ценностей, которые являются затем ссылки из сами строки вместо хранимых избыточностью. Кроме того общие префиксы значений столбец хранятся только один раз на странице. В качестве иллюстрации того, как можно помочь сжатия префикса рассмотрим коды продукции, где часто сходны префиксы.
** **
Код |
Количество |
A-F234-10-1234 |
1834 |
A-F234-10-1235 |
1435 |
A-F234-10-1236 |
1237 |
A-F234-10-1237 |
1546 |
A-F234-10-1238 |
1545 |
A-F234-10-1239 |
1543 |
A-F234-10-1240 |
1756 |
A-F234-10-1241 |
1435 |
A-F234-10-1242 |
1544 |
** **
Это могут быть сжаты до:
** **
A-F234-10-12 |
1000 |
** **
Код |
Количество |
34 |
834 |
35 |
435 |
36 |
237 |
37 |
546 |
38 |
545 |
39 |
543 |
40 |
756 |
41 |
435 |
42 |
544 |
** **
Даже столбец как количество могут выиграть от сжатия. Более подробную информацию о методах сжатия строк и страниц в SQL Server 2008 см SQL Server 2008 электронной документации.
Сжатие страниц и строк может применяться к таблицам и индексам.
Очевидным преимуществом является, конечно, что вы должны меньше дискового пространства. В ходе испытаний мы стали свидетелями сжатия от двух-для семикратном, причем триединое типичный. Это сокращает Ваши требования диска, примерно две трети.
Менее очевидной, но потенциально более ценные выгоды встречается в скорость запрос . Выигрыш здесь происходит от двух факторов. Дискового ввода-вывода значительно снижается, поскольку меньшее число прочтений обязаны приобрести такое же количество данных. Во-вторых как функция от коэффициента сжатия увеличивается количество данных, которые могут быть проведены в основной памяти.
Основной памяти преимуществом является повышение производительности, включаемые сжатия и помпаж размеров основной памяти.
Производительность обработки запросов может возрасти десять раз или больше, если вы можете получить все данные которые вы когда-либо запрос в основной памяти и держать его там. Ваши результаты зависят от относительной скорости системы ввода/вывода, памяти и ЦП. Хранилище умеренно большими данных можно совпадение полностью в основной памяти на сервере 4 процессорных сырьевых товаров, который может вместить до 128 ГБ оперативной памяти — ОЗУ, что является более доступным. Это может вместить объемом ОЗУ все типичный 400‑ГБ хранилища данных, сжатие. Больших серверах с до 2 терабайт памяти доступны, которые могут совпадение всего 6‑терабайт хранилища данных в оперативной памяти.
Есть, конечно, процессор затраты, связанные с сжатия. Это рассматривается главным образом во время процесса загрузки. Когда используются сжатие страницы мы видели ЦП вырастет приблизительно 2,5 раза. Некоторые конкретные показатели для сжатия страниц, записаны во время испытания на обоих 600‑ГБ и 6‑хранилище терабайт данных с рабочей нагрузки в течение ста различных запросов, являются 30-40%, увеличение запрос .
Таким образом в хранилищах данных, которые не являются в настоящее время ЦП, вы должны увидеть значительные улучшения в производительности запрос определенной небольшой ценой CPU. Записи имеют более CPU нагрузку чем гласит.
Это описание характеристики сжатия позволят вам определить вашу стратегию оптимального сжатия для таблиц и индексов на складе. Не может быть также просто, как применение сжатия для каждой таблица и индекса.
Например Предположим, что вы вашего факт разделов таблица со временем, например, квартал 1, квартал 2, и так далее. Текущий раздел является квартал 4. 4 Квартал обновляется каждую ночь, квартал 3 гораздо реже и кварталов 1 и 2, никогда не обновляются. Однако все получат широко.
После тестирования вы можете обнаружить, что лучше всего применять как строки и сжатие страниц для четверти 1 и 2, сжатие row 3 квартал и ни квартал 4.
Ваш пробег будет конечно же, меняться и тестирование является жизненно важным для внедрению наилучшей практики для ваших конкретных требований. Однако большинство хранилищ данных должен получить значительные выгоды от реализации стратегии сжатия. Начните с помощью сжатия страниц на всех таблиц фактов и факт таблица индексов. Если это вызывает проблемы с производительностью для загрузки или запросов, рассмотрим обратно падение сжатие row или сжатие не используется на некоторых или всех разделов.
Если вы используете, сжатия и шифрование, сделать это в этом порядке
SQL Server 2008 позволяет шифрования данных таблица . Наилучшей практики для использования это зависит от обстоятельств (см. над), но имейте в виду, что значительная часть сжатия, описанных в предыдущих наилучшей практики зависит поиск повторяющихся шаблонов в данных. Шифрования активно и значительно уменьшает рисунка в данных. Таким образом если вы намерены использовать оба, это неразумно сначала шифрования и затем сжать.
Использовать сжатие резервных копий для уменьшения хранения след
Сжатие резервных копий теперь доступен и должен использоваться, если вы найдете хорошие причины не делать этого. Преимущества такие же, как другие методы сжатия — есть скорость и объем прибыли. Мы ожидаем, что для большинства хранилищ данных основной прирост сжатие резервных копий находится в сокращение хранения след, и вторичные выгоды этой резервной копии завершает более быстрыми темпами. Кроме того, восстановление работает быстрее, потому что резервного копирования меньше.
Наилучшая практика: секционирование
Большой факт таблицы разделов
Секционирование таблица означает разделение его горизонтально на меньшие компоненты (под названием разделы). Секционирование обеспечивает несколько преимуществ. По сути секционирование позволяет данные отдельно в наборы. Это только имеет огромные преимущества с точки зрения управляемости. Разделы могут помещаться в разные файловые группы таким образом, чтобы они могут архивироваться независимо друг от друга. Это означает, что мы можно разместить данные о различных шпиндели для повышения производительности. В хранилищах данных, это также означает, что мы можем изолировать строк, которые могут изменить и выполните обновляет, удаляет и вставляет на этих строках только.
Обработка запросов могут быть улучшены путем секционирование , потому, что он иногда позволяет планы запрос для ликвидации всего разделов из рассмотрения. Например таблицы фактов часто разделены по дате, например по месяцам. Когда отчет выполняется и июле персонажи, вместо того, чтобы доступ к 1 миллиарда строк, он может только у для доступа к 20 млн.
Индексы, а также таблицы может быть (и часто являются) секционирована, который увеличивает преимущества.
Представьте себе фактов таблица 1 миллиарда строк, не секционирована. Каждый нагрузки (обычно ночью) означает вставки, удаления и обновления всей этой огромной таблица. Это может понести огромные затраты на обслуживание, до точки, где может оказаться возможным делать обновления во время ETL окно.
Если же таблица секционирована по времени, как правило только самых последних раздела должны быть затронуты, что означает, что большинство из таблица (и индексы) остаются нетронутыми. Вы можете удалить все индексы до загрузки и перестроить их впоследствии для того, чтобы избежать издержек обслуживания индекса. Это может значительно улучшить время загрузки.
Раздел align индексированных представлений
SQL Server 2008 позволяет создавать индексированные представления, которые приведены в соответствие с вашим таблиц секционированного фактов и переключение секций из таблиц фактов в и из. Это работает, если индексированные представления и таблица фактов секционированных с помощью же функция. Как правило таблицами фактов и индексированных представлений секционированных суррогатный ключ ссылки на Дата измерения таблица. Когда вы включите в новый раздел, или переключиться из старого, вам не нужно удалить индексированное рассматривает первый, а затем re‑после их создания. Это может сэкономить огромное количество времени в ходе процесса ETL. В самом деле он может сделать возможным использовать индексированные представления для ускорения запросов, когда он был не возможно до из-за влияния на ваш ежедневный цикл нагрузки.
И в первую очередь разработать схему секционирование для удобства управления
В SQL Server 2008 не стоит создавать разделы для получения параллелизма, равно как и в некоторые конкурирующие продукты. SQL Server 2008 поддерживает несколько потоков на секцию для обработки, запрос , который значительно упрощает разработку и управления. При разработке стратегии секционирование выберите ваш раздел ширина для удобства ваших данных ETL и управления жизненным циклом. К примеру не стоит раздел в день, чтобы получить больше разделов, (которые могут быть необходимыми в SQL Server 2005 или других СУБД) Если секционирование на неделю более удобна для управления системой.
Для наилучшей производительности параллелизма включать предикат явного Дата диапазон для таблица фактов в запросах, а не соединение с измерения даты
SQL Server обычно делает хорошую задание по обработке запросов как показано ниже, где предикат диапазон даты задается с помощью соединение между таблица фактов и измерения Дата:
** **
Выберите top 10 p.ProductKey, sum(f.SalesAmount)
от FactInternetSales f, DimProduct p, DimDate d
где f.ProductKey=p.ProductKey и p.ProductAlternateKey, как N'BK-%'
и f.OrderDateKey = d.DateKey
и d.MonthNumberOfYear = 1
и d.CalendarYear = 2008
и d.DayNumberOfMonth от 1 до 7
Группировка p.ProductKey
Order by sum(f.SalesAmount) desc
** **
Тем не менее, запрос как это обычно использует вложенного цикла соединение между измерения даты и фактов таблица, к��торая может ограничить параллелизма и общую производительность запрос , потому что, самое большее, один поток используется для каждого квалификационного строку измерения даты. Вместо этого за наилучшие показатели, положить предикат явного Дата диапазон на Дата измерения ключ столбец из таблицафактов и убедитесь что ключи измерения даты в возрастающем порядке по дате. Ниже приведен пример запрос с предикат диапазон явного Дата:
** **
Выберите top 10 p.ProductKey, d.CalendarYear, d.EnglishMonthName,
sum(f.SalesAmount)
от FactInternetSales f, DimProduct p, DimDate d
где f.ProductKey=p.ProductKey и p.ProductAlternateKey, как N'BK-%'
и OrderDateKey между 20030101 и 20030107
и f.OrderDateKey=d.DateKey
Группировка по p.ProductKey, d.CalendarYear, d.EnglishMonthName
order by sum(f.SalesAmount) desc
** **
Этот тип запрос обычно получает хэш планазапрос соединениеи будет полностью параллелизации.
Наилучшая практика: Единообразно управлять несколькими серверами
Использовать управление на основе политик для обеспечения надлежащей практики на нескольких серверах
SQL Server 2008 представляет Управление на основе политики, которая делает возможным объявить политики (например, "все файлы журналов должны храниться на диске помимо диск данных)" в одном месте и затем применить их к нескольким серверам. Таким образом (несколько рекурсивного) рекомендуется набор наилучшей практики на одном сервере и применить их ко всем серверам. Например вы могли бы построить три витрин данных, извлекающие данные из хранилища основных данных и позволяет применить те же правила для всех витрин данных управления на основе политики.
Дополнительные ресурсы
Вы можете найти дополнительные советы, в основном связаны с получение лучших масштабируемости и производительности с SQL Server 2008 в "Белой книге" компаньон[12]. Эти советы охватывают диапазон вопросов, включая конфигурацияхранения данных, формулирование запрос , индексирование, агрегатов и многое другое.
Анализ
Есть несколько отличные технические документы о передовой практике для анализа такие как OLAP дизайна передового опыта для служб Analysis Services 2005, Analysis Services обработка наилучшей практики , и Анализа служб запросов производительность Top 10 наилучшей практики. Вместо того, чтобы повторять их содержание, в настоящем документе мы сосредоточены более конкретно на наилучшей практики для анализа в SQL Server 2008.
Наилучшая практика: анализ
Серьезно рассмотреть рекомендации относительно оптимальной практики, предоставляемые АМО предупреждений
Хороший дизайн имеет основополагающее значение для надежной, высокопроизводительных систем, и распространение руководства по наилучшей практике поощряет good design. Совершенно новый способ указания, где наилучшей практики может помочь является частью SQL Server 2008 Analysis Services.
SQL Server 2008 Analysis Services показывает в реальном времени предложения и предупреждений о дизайне и наилучшей практики, как вам работы. Они реализуются в анализ управления объектов AMO и отображаются в Интерфейсе пользователя как голубой волнистые подчеркивает: парящей над подчеркиванием объекта отображает предупреждение. Для экземпляр, имя куб может подчеркнуть и предупреждение можно сказать:
«salesprofit» и "Прибыль" группы мер имеют одинаковой размерностью и гранулярностью. Рассмотреть вопрос об объединении их для повышения производительности. Избегайте Кубы с одного измерения.
Более 40 различных предупреждения указывают, где не соблюдается наилучшей практики. Предупреждения могут быть уволены индивидуально или выключен во всем мире, но наша рекомендация заключается в том, чтобы следовать за ними, если у вас нет активных причины не делать этого.
Использовать MOLAP обратной записи вместо ROLAP обратной записи
Для некоторых классов бизнес-приложений (прогнозирования, составления бюджета, что делать, если и так далее) способности записи данных обратно в куб может быть весьма выгодным.
Он некоторое время удалось записать обратно значения ячейка в куб, как на уровне листьев и агрегат . Секция специальных обратной записи используется для хранения разница (дельты) между первоначальной и новое значение. Этот механизм означает, что исходное значение по-прежнему присутствует в куб; Если запрос Многомерных выражений запрашивает новое значение, он хитов обоих разделов и возвращает статистическое значени�� оригинала и дельты.
Однако во многих случаях, несмотря на бизнес соображения производительности ограничили использование обратной записи.
В предыдущей реализации секцию обратной записи пришлось использовать режим хранения ROLAP и это часто является причиной низкой производительности. Для извлечения данных, было необходимо запрос реляционных данных источник и что может быть медленным. В SQL Server 2008 Analysis Services обратной записи в секции могут храниться как MOLAP, который удаляет это узкое место.
Хотя это правда, что данная конфигурация может замедлить операции обратной записи фиксации fractionally (как в таблица обратной записи и секцию MOLAP должны обновляться), значительно улучшает производительность запрос в большинстве случаев. Один внутренний тест 2 миллиона ячейка обновления пятикратное улучшилось в производительности.
Использовать резервную копию, а не файл копию SQL Server 2008 Analysis Services
В SQL Server 2008 Analysis Services подсистема резервного хранения был переписан и его производительность резко улучшилось как показано на рисунке 5.
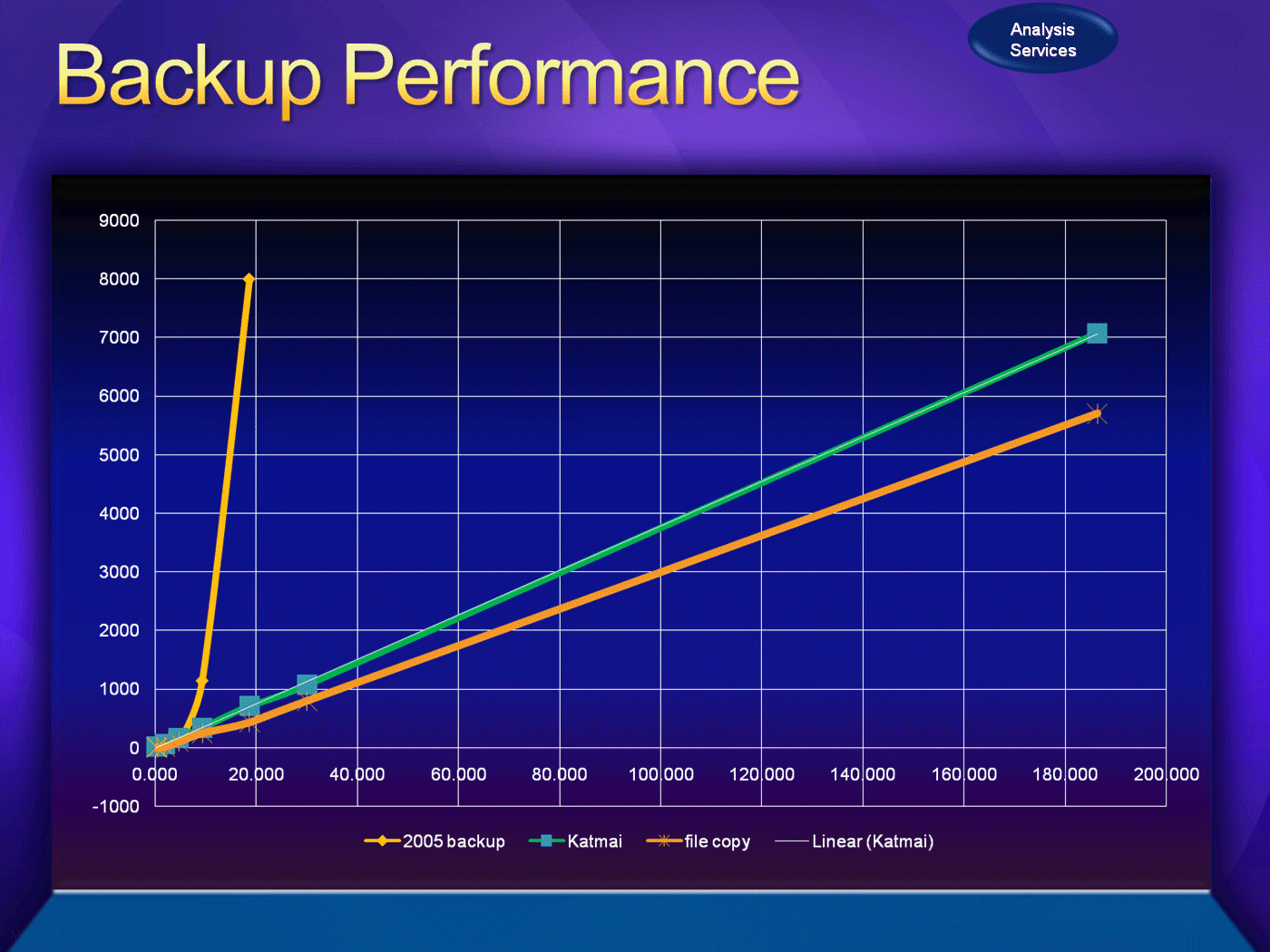
Рисунок 5: Производительности резервного копирования в SQL Server 2005 Analysis Services против SQL Server 2008 Analysis Services. X = время Y = объем данных
Резервное копирование теперь линейно масштабируется и может обрабатывать более чем терабайт база данных служб Analysis Services. Кроме того были устранены ограничения на размер и метаданные файлов резервных копий. Систем, обработки больших объемов данных могут теперь принять системы резервного копирования и отказаться от копирования raw файлов системы и пользоваться преимуществами интеграции с транзакционной системы и выполнения резервного копирования параллельно с другими операциями.
Хотя расширение файла является неизменным, изменился формат файла резервной копии. Это полностью указания совместимо с прежний формат, так что можно восстановление резервное копирование базы данных в службах Analysis Services SQL Server 2005 для SQL Server 2005 Analysis Services. Это не, однако, возможность сохранения файлов в старом формате.
Написать проще многомерных Выражений не беспокоясь о производительности
Новая функция, блок вычислений (также известный как подпространство вычислений), был реализован в SQL Server 2008 Analysis Services и одно из основных преимуществ, она приносит улучшение производительности запрос многомерных Выражений. В SQL Server 2005 сложные обходные пути возможны в некоторых случаях; Теперь MDX может быть написан намного проще.
Кубы обычно содержат разреженных данных: в обширной морской значения NULL часто существует относительно небольшое число значений. В SQL Server 2005 Analysis Services запросы, которые затронули большое количество значений NULL может плохо выполняют по той простой причине, что даже если логически бессмысленно выполнять вычисления на значение null, запрос будет тем не менее процесс все значения null таким же образом, как не NULL.
Блок вычисления рассматривает этот вопрос и значительно повышает производительность этих запросов. Внутренняя структура куб является весьма сложным и ниже описание того, как работает блок вычислений является упрощенной версия полный рассказ. Он однако, дать представление о каким образом достигается скорость выгоды.
Этот расчет MDX вычисляет промежуточную сумму за два года подряд:
СОЗДАЙТЕ ЧЛЕН CURRENTCUBE.[Меры].RM
AS ([Дата заказа]. [Иерархия].PrevMember, [Measures].[Количество])+Меры
. [Заказать количество],
FORMAT_STRING = "Standard",
ВИДИМЫХ = 2;
Эти таблицы показывают ордена небольшое подмножество продуктов и показывают, что существует очень мало значения для большинства продуктов в 2003 и 2004 годах:
** **
|
2003 |
|
2004 |
Product 1 |
|
|
|
Product 2 |
2 |
|
|
Product 3 |
|
|
|
Product 4 |
|
|
5 |
Product 5 |
|
|
|
Product 6 |
|
|
|
Product 7 |
3 |
|
1 |
Product 8 |
|
|
|
Product 9 |
|
|
|
** **
Этот запрос:
Выберите [ДатаРазмещения].[Иерархия].[все].[2004] на столбцы,
[Dim Product]. [Ключ продукта].[Все] .children на строк
От Foo
Где Measures.RM
Возвращает вычисляемую меру RM для всех продуктов, заказанных в 2004 году.
В SQL Server 2005 Analysis Services результат снимков берется значение из ячейка за 2004 год (текущего года), нахождения значения в соответствующей ячейка за предыдущий год и суммирования значений. Каждая ячейка обрабатывается таким образом.
Этот подход содержит два процесса, которые не спешат выполнять. Во-первых для каждой ячейка, обработчик запрос переходит за предыдущий период, чтобы увидеть, если значение присутствует. В наиболее иерархические структуры мы знаем, что если данные на одну ячейка в 2003 году, он будет там для всех ячеек в 2003 году. Путешествие, чтобы увидеть, если есть данные за предыдущий период только должны осуществляться один раз, что то, что происходит в SQL Server 2008 Analysis Services. Этот аспект блок вычислений ускоряет запросы независимо от доля значений null в куб.
Во-вторых вычисляется сумма каждой пары значений. С разреженным кубзначительная часть результат вычислений в значение null и время расходуется впустую, сделать эти расчеты. Если мы смотрим на предыдущих таблиц, это легко увидеть, что только расчеты для продуктов, 2, 4 и 7 будет доставлять что-нибыдь которое не имеет значение null. Так в SQL Server 2008 Analysis Services, прежде чем любые вычисления выполняются, null строки удаляются из данных за каждый год:
** **
|
2003 |
Product 2 |
2 |
Product 7 |
3 |
** **
** **
|
2004 |
Product 4 |
5 |
Product 7 |
1 |
** **
Результаты сравниваются:
** **
|
2003 |
|
2004 |
Product 2 |
2 |
|
|
Product 4 |
|
|
5 |
Product 7 |
3 |
|
1 |
** **
и расчеты выполнены только для строк, которые будут генерировать значимого результата.
Прирост скорости может быть впечатляющим: под тестирования запрос , который занимает две минуты и 16 секунд в SQL Server 2005 Analysis Services занимает всего лишь восемь секунд в SQL Server 2008 Analysis Services.
Масштабировать, если вам нужно больше мощности оборудования и оборудования цена имеет важное значение
Чтобы ��овысить производительность при нагрузке, можно наращивать или масштабировать. Масштабов несомненно проста: положить куб на большой высокопроизводительный сервер. Это отличное решение — это быстро и легко и правильное решение во многих случаях. Однако это также дорогих потому что эти серверы стоить больше одного процессора, чем несколько небольших серверов.
Предыдущие версия служб Analysis Services предлагают масштабное решение, которое используется несколько экономичных серверов. Репликация данных между серверами и решения балансировки нагрузки как Microsoft Балансировка сетевой нагрузки () была установлена между клиентами и серверами. Это работает, но понесла дополнительные расходы на набор и текущего обслуживания.
SQL Server 2008 Analysis Services имеет новое масштабное решение под названием масштабируемой общей базы данных (SSD). Его работы очень похож на функцию SSD в реляционной СУБД SQL Server 2005. Она состоит из трех компонентов:
- База данных только для чтения – позволяет базе данных должен быть определен только для чтения
- Место хранения базы данных – включает базы данных проживать за пределами папке данных сервера
- / Отсоединения база данных - база данных может присоединена или отсоединяется от любого UNC-путь
Все вместе эти компоненты облегчают для создания масштабного решения для кубов служб Analysis Services только для чтения. Например можно подключить четыре блейд-серверов в общей, доступного только для чтения базу данных на SAN и прямых запросов служб SSAS для любой из четырех, тем самым улучшая вашу общая пропускная способность раза четыре с недорогим оборудованием. Лучший время отклика запрос по-прежнему сдерживается возможностями отдельного сервера, так как каждый запросвыполняется только на одном сервере.
Отчетность
Этот раздел предлагает передовые практики для различных аспектов отчетности такие, как повышение производительности.
Лучшие практики: Представление данных
Позволяют ему и бизнес-пользователей для создания простых и сложных отчетов
Сообщения всегда упали между двух мнений — должны ИТ или деловых людей их дизайн? Проблема заключается, что бизнес-пользователи понимают бизнес-контекста, в котором данные используется (значение данных), тогда как IT люди понимают основную структуру данных.
Чтобы помочь бизнес-пользователей, в SQL Server 2005, корпорация Майкрософт представила концепцию модели отчета. Это была построена ИТ людей для бизнес-пользователей, которые затем писал сообщения против него, используя средство под названием построитель отчетов. построитель отчетов будет поставляться в поле SQL Server 2008 и будет работать как раньше.
Дополнительный средство, построитель отчетов, непосредственно направленных на продвинутых пользователей, была усовершенствована в SQL Server 2008. Это самостоятельное приложение, полный с помощью Office 12 системы интерфейсможет похвастаться полный макет возможности конструктора отчетов и доступен для загрузки Web.
ИТ-специалистов в SQL Server 2005 обслуживались хорошо средство под названием конструктор отчетов в Visual Studio, которое позволяет им создавать очень подробные отчеты. Расширенная версия конструктора отчетов поставляется с SQL Server 2008 и показано на рисунке 6.

Рисунок 6: Конструктор отчетов в среде Visual Studio
Представление данных в наиболее доступным способом
Традиционно были представлены данные сетки для пользователей как таблицы, матрицы и списки. Каждый имеет свои сильные стороны, которая является еще одним способом сказать, что каждый имеет свои слабости. SQL Server 2008 Reporting Services объединяет все три в новой области данных под названием табликс.
На рисунке 7 в таблица на левой стороне показывает процент роста и матрица справа показывает фактические данные.
** **
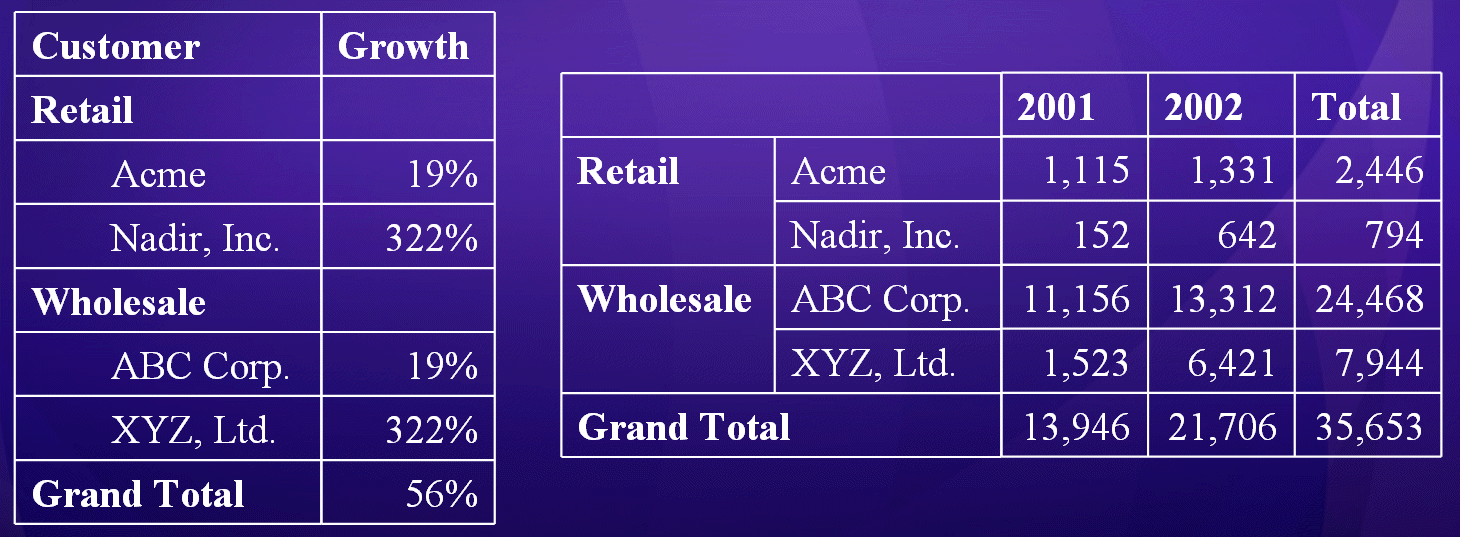
Рисунок 7: таблица и матрицы
Для табликс показано на рисунке 8 объединяет эти и добавляет некоторые итоги.

Рисунок 8: Область данных табликс объединения таблица и матрицы функции
Область данных табликс предоставляет пользователям гораздо больше управления разметкой, чем таблицы, списки и матрицы. Она также дает им возможность добавить группы столбец , укажите произвольное вложение на каждой ось, при необходимости опустить строк и заголовков столбец и имеет несколько параллельных строки /столбец членов на каждом уровень.
Представление данных в отчеты, можно легко понять
Для генерации отчетов причина для преобразования данных в информацию для бизнес-пользователя. Многие люди находят графики легче понять, чем номера. SQL Server 2008 Reporting Services представляет датчика, Новая форма визуального вывода. Датчик отображает одно значение из данных. Как показано на рисунке 9, датчики являются особенно полезными для создания-дисплей отображает для сравнения нескольких значений.
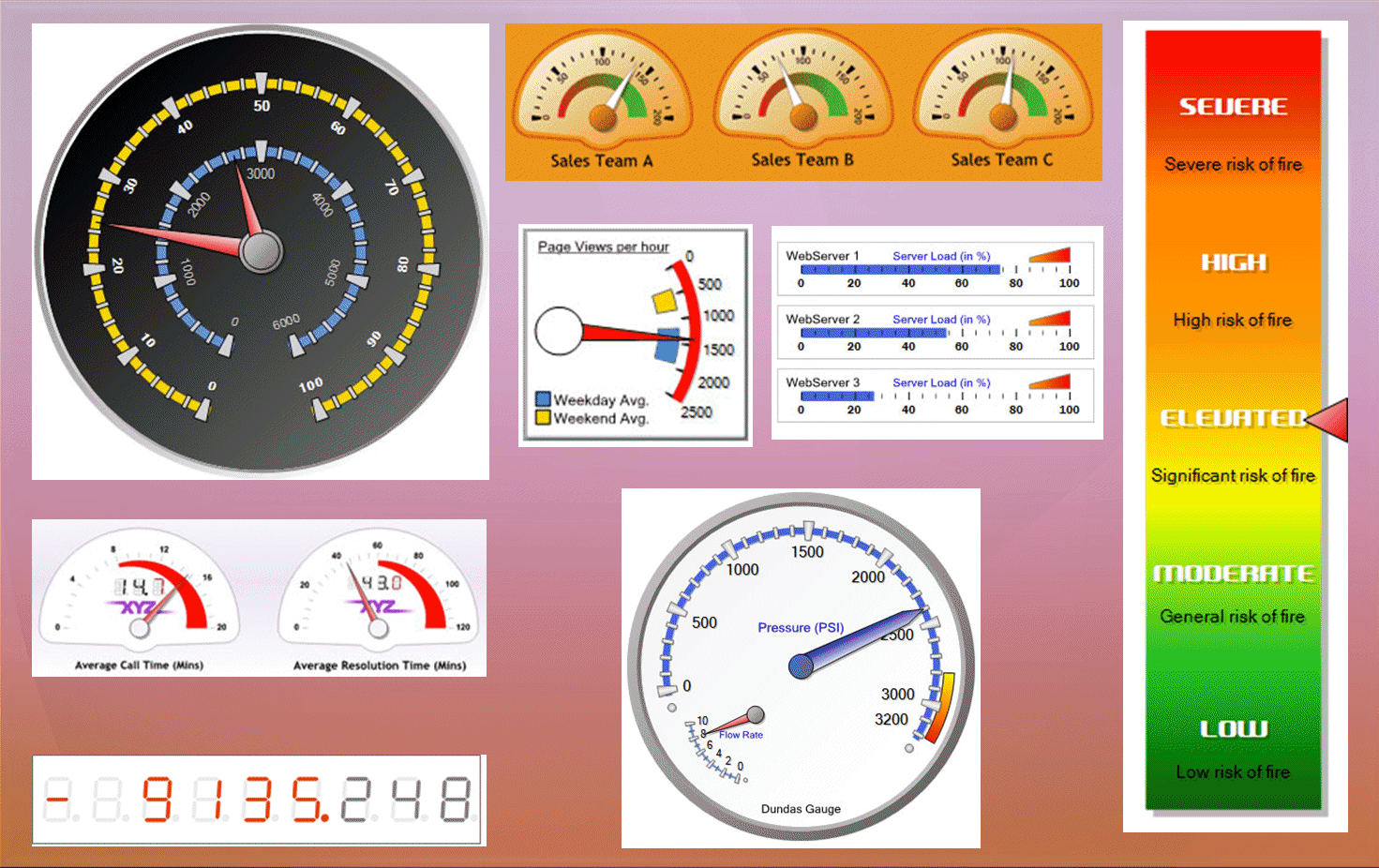
Рисунок 9: Примеры из датчиков, которые могут быть созданы в SSRS
Диаграммы также была распространена ��а полярные, диапазони форму. На рисунке 10 показано только подмножество, доступных.
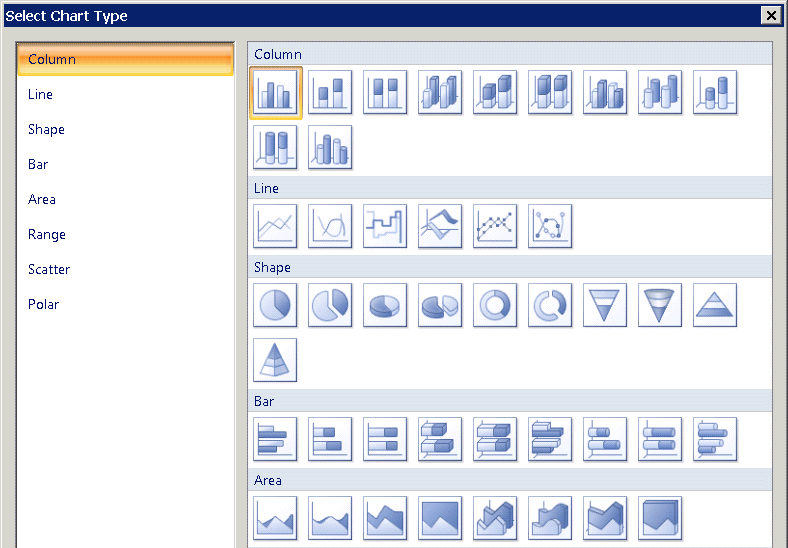
Рисунок 10: Большое количество диаграмм доступны в SQL Server 2008 Reporting Services
Несколько рядов данных теперь могут быть отображены на более чем одной ось, пользователь имеет контроль над разрывов шкалы на ось, и есть поддержка формул run-time.
Представление данных для пользователей в знакомой среде
Отчеты теперь могут отрисовываться в виде документов Word, совместим с версиями Word обратно до и включая Word 2000. Кроме того существующий модуль подготовки отчетов Excel была усовершенствована и теперь поддерживает такие функции как вложенные области данных, Объединенные ячейки и вложенные отчеты.
Наилучшая практика: производительность
Структура ваш запрос для возврата только уровень детализации, отображаемыми в отчете
Используйте доклад -уровень агрегат , только для промежуточных итогов в докладе, не для строк детализации. Помните, что наиболее часто используемые агрегат, сумма, можно кратко изложить в любом порядке и до сих пор получить тот же результат. В то время как другие часто используемые агрегаты не могут, они часто может быть разбита на более простые, многократно используемых компонентов.
Например если вы хотите показать среднем на нескольких уровнях группирование и также хотят промежуточные итоги, а не возвращения строк детализации и кувейтских все, что в докладе, может разлагаться расчет сумм и количества. Затем можно восстановить в среднем в отчет с помощью такого рода отдела:
** **
Сумма (поля!Sum.Value)/Sum (поля!Count.Value)
** **
тем самым избежать необходимости передачи строк подробностей в отчет. Пусть база данных ду основная реферирования и агрегати использовать SSRS для монтажа и формат результатов для отображения.
Фильтрация с использованием параметров, передаваемых в запрос
Как правило это лучше фильтров в запрос , а не в докладе (выберите * от xyz где поле = @ param). Однако если вы делаете это исторический снимок отчета нельзя создать без блокировки вниз значение параметра. Если пользователям требуется изменить значение параметра в моментальном снимке, рекомендуется вместо этого следует возвращать все данные для отчета и фильтра внутри отчета.
Сортировка в запрос
SSRS использует сортировки stable операций внутри страны, так что порядок данных, возвращаемых из запрос не изменяется в пределах каждой группы экземплярпозволяя сортировки в запрос.
Однако, то есть сортировка на основе агрегат значений гораздо более удобным (и обычно более эффективно) для выполнения в самом докладе.
Избегайте использования вложенных отчетов внутри группирование
Каждый вложенный отчет экземпляр является выполнения отдельного запрос и обработки отдельный шаг для SSRS. Для отчетов master-detail он гораздо более эффективно будет просто соединение мастер и детализации данных в запрос и затем группировка главный ключ в докладе, за исключением, в тех случаях, когда количество мастер записей является небольшим (в котором пользование вариант вложенный отчет не является это проблемой производительности).
Существует два случая, когда вложенные отчеты могут потребоваться:
- Когда мастер и детализации данных находятся в различных источников данных. В этом вариантрекомендуется потянув данных в хранилище данных. Если это не представляется возможным, следует рассматривать связанный сервер SQL Server или возможности открытый набор строк.
- Когда есть несколько независимых наборов записей для каждой главной записи. Одним из примеров должно отображать подробный перечень продаж и прибыли для каждого клиента. В данном вариант детализация отчеты рекомендуется вместо встроенный отчеты если подается небольшое количество мастер записи.
Ограничить данные в диаграммах для того, что пользователь может видеть
Хотя это может быть заманчивым включить большое количество подробных данных в диаграммах для повышения точности, лучше pre-group данные в запрос или в докладе, ограничивая количество точек данных. Рисование сотни точек в пространстве, которое только занимает несколько пикселей снижает производительность и делает ничего, чтобы повысить визуальном представлении диаграммы.
Набору и pre-group данные в запрос
Как правило, можно повысить производительность, группирование и сортировка данных в запрос в соответствии с порядком сортировки, предусмотренных в докладе.
Использование детализация , а не углубленной детализации при больших объемов данных подробно
В то время как SQL Server 2008 по требованию обработки двигателя оптимизирует прочь большинство вычислений для элементов, которые не отобра��аются, имейте в виду, что все данные извлекаются для каждой строки детализации, даже если ваш первоначальный углубленной детализации государство имеет все рухнул до высокого уровень агрегат. Кроме того, все группирование, сортировки и фильтрации должны выполняться вне зависимости от состояния видимости или углубленной детализации. Так что если пользователь обычно заинтересована только в том лишь незначительное количество подробных данных, ассоциированных детализация отчет является лучшим выбором.
Избегайте сложных выражений в верхний колонтитул страницы и нижний колонтитул
Если верхний колонтитул страницы или нижний колонтитул содержит сложные выражения (ничего иного, чем простая ссылка поле или параметра), SSRS должны взять на себя, он может включать в себя ссылку на общее количество страниц. В результате весь отчет должны разбиваться перед отрисовкой первой страницы. В противном случае, первый может быть и отображении страницы возвращается пользователю сразу же кто не придется подождать для всего отчета для разбиваться сначала.
Отключить CanGrow на текстовые поля и свойства AutoSize изображений, если это возможно
Некоторые модули подготовки отчетов являются более эффективными, если размеры всех объектов в докладе известны будет исправлено.
Не возвращает столбцы, которые вы не собираетесь использовать из запрос
Так как все данные в запрос должны быть получены (и хранятся) сервером отчетов, это более эффективно для возвращения только столбцы, которые будут использоваться в докладе. Если результирующий набор не могут контролироваться (например, когда результаты возвращаются из хранимой процедуры), достаточно удалить определения поле из набора данных. В то время как дополнительные столбцы будут восстановлены, это будет по крайней мере запретить их сохранение.
Лучшие практики: Архитектура системы и производительность
Держите каталога сервера отчетов на том же компьютере, что и сервер отчетов
Службы Reporting Services создает и использует базу данных, которая по существу является каталогом. Это используется при обработке для целого ряда задач отчета, включая управление данными вернулся из запросов. Хотя это можно хранить эту базу данных на сервере, отличном от сервера отчетов, это требует толкаемых через сеть излишне, данные отчета который замедляет выполнение отчета. Это гораздо лучше, для хранения базы данных каталога на сервере отчетов, чтобы избежать такой сетевой трафик и связанных с ними задержек.
Рассмотреть вопрос о размещении служб Reporting Services на другом сервере с хранилищем данных
Хотя получение данных из запросов по сети замедлить вещи, это выгодно чтобы не ваши хранилища данных и служб SSRS, конкурирующих за память и время обработки.
Заключение
Проектирование и строительство хранилища данных предприятия может быть значительные усилия с значительные затраты. Хранилищ данных строятся не как дисплеи технического совершенства; они являются инвестиции предприятия и предназначен для обеспечивают высокую отдачу. Как показывают документы IDC и Gartner, слишком часто эти проекты имеют больше характеристик авантюра чем проницательный инвестиции — потенциально высокую отдачу, но одновременно высокий риск неудачи и потери.
Много узнала о факторах, которые связаны с успешных проектов. Они были дистиллированной в ряд передовых методов, многие из которых описаны здесь, охватывающих бизнес-процессов, дизайн и техническая реализация с помощью SQL Server 2008. Действительно многие из новых возможностей в SQL Server 2008 были специально разработаны чтобы позволить этим рекомендациям легко осуществить.
Как доля от общего объема усилий, необходимых для создания хранилища данных применяя эти рекомендации недорогой, и тем не менее это так может иметь существенное влияние на успех (и, следовательно, ROI) проекта в целом.
** **
Для получения дополнительной информации:
Ссылки
- Борис Барышников, SQL Server 2008 регулятора, работа в прогресс, 2008 г.
- Мэтт Кэрролл, лучших методов проектирования OLAP для анализа услуг 2005 года, 2007.
- Более чем 50% от данных хранилища проектов будет иметь ограниченное признание или будет быть сбоев 2007: бизнес-разведки саммит Gartner, Чикаго, март 2005 года (http://www.gartner.com/it/page.jsp?id=492112).
- Эрик н. ХАНСОН et al., введение к новым данным складские возможности масштабируемости в SQL Server 2008, Декабрь 2007.
- Эрик н. ХАНСОН et al., масштабирование вверх ваше хранилище данных с SQL Server 2008, работа, 2008.
- Уильям х. Inmon, строительство хранилища данных: 4й Эд. Джон Увальне & Сыновья, 2005 года.
- Основы мудрости: исследование финансовых последствий создания хранилищ данных. Международная корпорация данных (МЦД), 1996
- Ральф Кимбалл et al., данных хранилища жизненного цикла Инструментарий: практические методы для создания хранилища данных и бизнес-аналитики систем, 2d Эд. Джон Увальне & Сыновья, 2008.
- Денни ли, Николас Dristas, Карл Rabeler, обработки наилучшей практики в SQL Server службы Analysis Services, 2007.
- Грэм Малькольм, бизнес-аналитики в SQL Server 2008, 2007 г.
- Уильям Макнайт Выбор Microsoft SQL Server 2008 для хранения данных, 2007.
- Analysis Services запроса производительности Топ 10 наилучшей практики, 2007 г.
- Камаль Hathi, введение в SQL Server 2008 Integration Services, 2007 г.
- Мишель Dumler Microsoft SQL Server 2008 продукт обзор, 2007 г.
** **
[1]Ральф Кимбалл et al., данных хранилища жизненного цикла Инструментарий: практические методы для создания хранилища данных и бизнес-аналитики систем, 2d Эд. Джон Увальне & Сыновья, 2008.
[2]Уильям х. Inmon, строительство хранилища данных: 4й Эд. Джон Увальне & Сыновья, 2005 года.
[3] Основы мудрости: исследование финансовых последствий создания хранилищ данных. Международная корпорация данных (МЦД), 1996
[4] Более чем 50% от данных хранилища проектов будет иметь ограниченное признание или будет быть сбоев 2007: бизнес-разведки саммит Gartner, Чикаго, март 2005 года (http://www.gartner.com/it/page.jsp?id=492112).
[5]Эрик н. ХАНСОН et al., масштабирование вверх ваше хранилище данных с SQL Server 2008, работа, 2008.
[6]Уильям Макнайт выбор Microsoft SQL Server 2008 для хранения данных, 2007.
Грэм Малькольм, бизнес-аналитики в SQL Server 2008, 2007 г.
Мишель Dumler Microsoft SQL Server 2008 продукт обзор, 2007.
[7]Уильям х. Inmon, строительство хранилища данных: 4й Эд. Джон Увальне & Сыновья, 2005 года.
[8]Ральф Кимбалл et al., данных хранилища жизненного цикла Инструментарий: практические методы для создания хранилища данных и бизнес-аналитики систем, 2d Эд. Джон Увальне & Сыновья, 2008.
[9]Камаль Hathi, введение в SQL Server 2008 Integration Services, 2007 г.
[10]Эрик н. ХАНСОН et al., масштабирование вверх ваше хранилище данных с SQL Server 2008, работа, 2008.
[11]Борис Барышников, SQL Server 2008 регулятора, работа в прогресс, 2008 г.
[12]Эрик н. ХАНСОН et al., масштабирование вверх ваше хранилище данных с SQL Server 2008, работа, 2008.