Автоматизация интеллектуального анализа данных с помощью интеграции Services_files(ru-RU)

***Предложенная статья является машинным переводом оригинала.
SQL Server Технические статьи
Автор: Takaki Джинни
Технический рецензент: Раман Айер
Опубликовано: июля 2011
Предложенная статья является машинным переводом оригинала.
Применимо к: SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
Резюме: эта статья является пример, иллюстрирующий строить несколько связанных данных модели, используя инструменты, которые организуются с Microsoft SQL Server Integration Services. В этом пошаговом руководстве вы узнаете, как автоматически строить процесс несколько моделей интеллектуального анализа данных, основанный на структуре интеллектуального анализа данных, создавать прогнозы от всех связанных с ней моделей и сохранить результаты в реляционной базе данных для дальнейшего анализа. И наконец просматривать и сравнивать прогнозов, исторических тенденций и статистики модели в SQL Server отчетов службы отчетов.
Авторское право
Данный документ предоставляется «как есть». Информация и мнения, высказанные в этом документе, включая URL-адреса и другие ссылки на Интернет- веб-сайт , могут изменяться без уведомления. Вы принимаете на себя риск, связанный с пользованием этим документом.
Некоторые примеры, приведенные здесь предоставляются только для иллюстрации и являются вымышленными. Никакой реальной ассоциации или связи предназначен или следует рассматривать как случайное.
Настоящий документ не предоставляет пользователям права на интеллектуальную собственность продуктов Майкрософт. Разрешается копирование и использование настоящего документа только в справочных целях. ****
© Корпорация Майкрософт (Microsoft Corporation), 2011. Все права защищены
Введение
Эта статья является пример, демонстрирующий использование средств интеллектуального анализа данных, которые предоставляются с Microsoft SQL Server Integration Services. Если вы являетесь опытным данных рудничные, вы вероятно уже использовать средства, предоставляемые в среде Business Intelligence Development Studio или клиента интеллектуального анализа данных Add-in для Microsoft Excel для создания или просмотра моделей интеллектуа��ьного анализа данных. Однако службы Integration Services поможет вам автоматизировать многие процессы.
Это р��шение также вводит понятие ансамбль модели интеллектуального анализа данных, которые являются наборами нескольких связанных моделей. Для большинства проектов интеллектуального анализа данных необходимо создать несколько моделей, анализировать различия и сравнения вариантов, прежде чем выбрать лучшие модели для оперативного использования. Службы Integration Services обеспечивает рамки, в течение которого вы сможете легко создавать и управлять ансамбль модели.
В этой серии, вы узнаете, как:
• Настройка компоненты служб Integration Services, которые предоставляются для интеллектуального анализа данных.
• Автоматически создавать и обновлять модели интеллектуального анализа данных с помощью служб Integration Services.
• Хранить параметры модели интеллектуального анализа данных и результатов прогноза в компоненте database engine.
• Интегрируйте требования к отчетности в рабочий процесс разработки модели.
Обратите внимание, что это лишь некоторые из путей, что вы можете использовать службы Integration Services для включения интеллектуального анализа в аналитических данных и процессов обработки данных. Надеюсь эти примеры помогут вам получить больше пробег из существующей установки служб Integration Services и SQL Server служб Analysis Services.
Автоматизация создания моделей интеллектуального анализа данных
Этот сценарий позиции вам как один аналитик, который было поручено создание некоторые прогнозы, основанные на последних данных о продажах. Вы не знаете о том, как настроить алгоритм временных рядов для достижения наилучших результатов (ARIMA? ARTXP? Что намекает предоставлять?). Кроме того вы знаете, что процесс моделирования обычно включает несколько моделей создания и тестирования различных сценариев.
Вместо того, чтобы построить вариации на модель ad hoc, вы решили автоматически генерировать несколько связанных с ней моделей, различные параметры систематически для каждой модели. Таким образом, вы можете легко создать многие модели, каждый из которых использует другую комбинацию подсказок периодичности и алгоритм типа. После того, как вы создали и обработка всех моделей, вы поставите исторических данных и прогнозов для каждой модели в серии докладов, чтобы узнать, какие модели обеспечивают хорошие результаты.
В этом пошаговом руководстве демонстрируются эти возможности:
• Автоматическая сборка нескольких моделей интеллектуального анализа данных с помощью параметров, хранящихся на SQL Server
• Создание массовые прогнозы для каждой модели и хранение их в SQL Server
• Сравнение тенденций от моделей, поместив их бок о бок в докладах
Решение пошагового руководства
Этот раздел описывает полное решение, строит несколько моделей и создает запросы, возвращающие прогнозы от каждой модели. Он содержит следующие компоненты:
[1] Проект служб analysis Services: для создания этого проекта, следуйте инструкциям в учебник интеллектуального анализа данных на MSDN (http://msdn.microsoft.com/en-us/library/ms169846.aspx) для создания структуры интеллектуального анализа данных Forecasting и по умолчанию время серии интеллектуального анализа данных модели.
[2] Проект служб integration Services: вы создадите новый проект, содержащий несколько пакетов:
- пакет , который строит несколько моделей, с помощью задачи «Выполнение инструкции DDL служб Analysis Services»
- пакет , который обрабатывает несколько моделей, использовать задачу «Обработка средствами Analysis Services»
- пакет , который создает прогнозы из всех моделей, с помощью задачи « запрос интеллектуального анализа данных»
Сфера
В этом пошаговом руководстве используются следующие задачи служб Integration Services и компонентов. Для получения дополнительных сведений из SQL Server электронной документации, нажмите на ссылку в решении задачи или компонент столбец.
Задача или компонент |
Используется для |
Получает значения переменных и создает таблицы для хранения результатов |
|
Создает отдельные модели |
|
Заполняет модели с данными |
|
Создает и обрабатывает несколько моделей интеллектуального анализа данных |
|
Строит необходимые команды XMLA |
|
Создает прогнозы от каждой модели |
|
Управляет и объединяет результаты прогноза |
|
Получает данные из временного прогноза таблица |
|
Записывает предсказания постоянной таблица |
|
Добавляет метаданные о прогнозы |
Хотя следу��щие компоненты служб Integration Services также являются весьма полезными для интеллектуального анализа данных, они не используются в данном пошаговом руководстве — найти примеры в одном из более поздних документов:
- Задачи профилирования данных
- Условное разбиение преобразование
- преобразование «Процентная выборка»
- преобразованиеНечеткий уточняющий запрос и поиска
- Обучение интеллектуального анализа данных назначение
Примечание: проекта SQL Server служб Reporting Services, содержащие отчеты, сравнивать модели не включается здесь, хотя этот проект генерирует все данные, необходимые для подготовки докладов. Это потому, что процесс создания отчета несколько продолжительных описать, особенно если вы не знакомы со службами Reporting Services. Кроме того поскольку все предсказания данные хранятся в реляционной базе данных, есть другие отчетности клиентов, которые можно использовать, включая Microsoft PowerPivot для Excel и Полумесяца проекта. Однако, мы надеемся, для описания процесса в отдельной статье позже TechNet вики (http://social.technet.microsoft.com/wiki/contents/articles/default.aspx).
Общий процесс
Этап 1 - подготовка: определение модели, вы хотите создать хранится в SQL Server как набор параметров, значения и имена моделей.
Этап 2 — создание модели: службы Integration Services извлекает определения моделей и передает значения параметров в цикл Foreach, который строит и затем выполняет XML для аналитики (XMLA) заявление для каждой модели.
Этап 3 – модель обработки: службы Integration Services получает список доступных моделей, а затем он обрабатывает каждой модели путем заполнения его данными.
Этап 4 - предсказание: службы Integration Services выдает прогнозирующий запрос для каждой обработки модели. Каждый набор прогнозов сохраняется на SQL Server таблица.
Этап 5 – отчетности и анализа: предсказания тенденций для каждой модели сравниваются с помощью докладов (созданная путем служб Reporting Services, PowerPivotили ваш любимый отчетности клиент) с использованием данных в реляционной таблица.
Этап 1 - подготовка
В этой фазе, набор структуры, образцы данных и параметры будут использовать ваши пакеты. Прежде чем создавать рабочие пакеты, вам необходимо выполнить следующие задачи:
- Создание структуры интеллектуального анализа данных Forecasting, используемые всех моделей интеллектуального анализа данных.
- Создание образца XML для Аналитики, который представляет по умолчанию модели временных рядов интеллектуального анализа данных, чтобы использовать в качестве шаблона.
- Создайте таблица , хранит параметры замены для новых моделей, а затем вставить значения параметров.
Следующем разделе описывается, как выполнять эти задачи.
Создайте прогнозирования структуры интеллектуального анализа данных и модель интеллектуального анализа данных серии времени по умолчанию
Чтобы создать несколько моделей, основанных на структуре интеллектуального анализа данных, необходимо сначала создать структуру интеллектуального анализа данных Forecasting. Основано на том, что структуры интеллектуального анализа данных, также необходимо создать модель временных рядов, который может использоваться как шаблон для генерации других моделей. Если структура интеллектуального анализа данных, поддерживающие модель временных рядов не уже, можно построить один, выполнив шаги, описанные в временных рядов Майкрософт Учебник (http://msdn.microsoft.com/en-us/library/ms169846.aspx) в SQL Server электронной документации.
Извлечение и изменение инструкции XML для Аналитики
Затем используйте модель временных рядов из предыдущего шага д��я извлечения XML для Аналитики заявление, которое будет использоваться как шаблон для всех моделей.
Вы можете получить инструкции XML для Аналитики для любой модели или структуры с помощью параметры создания сценариев в среде Management Studio SQL Server :
- В SQL Server Management Studio щелкните правой кнопкой мыши модели временных рядов.
- Нажмите кнопку модель интеллектуального анализа данных сценария как.
- Сохраните XML для Аналитики в текстовом файле.
- Откройте текстовый файл в Блокнот или другой текстовый редактор.
После того, как вы генерировать XML для Аналитики для модели временных рядов по умолчанию с использованием параметра сценарий, он выглядит как следующий код. (Заявление XMLA для моделей может быть длительным, только выдержка показан здесь.) Заявление XMLA всегда включает в себя базу данных, структуры интеллектуального анализа данных, метаданные , например имя модели и алгоритма, используемого для анализа. При необходимости он может включать несколько параметров.
<ParentObject>
Модели прогнозирования <DatabaseID> </DatabaseID>
<MiningStructureID> прогнозирование </MiningStructureID>
</ParentObject>
<ObjectDefinition>
<MiningModel>
<ID> ARIMA_1-10-30 </ID>
<Name> ARIMA_1-10-30 </Name>
<Algorithm> Microsoft_Time_Series </Algorithm>
<AlgorithmParameters>
<AlgorithmParameter>
<Name> FORECAST_METHOD </Name>
< значение xsi: Type = "xsd:строка" > ARIMA </Value>
</AlgorithmParameter>
<AlgorithmParameter>
<Name> PERIODICITY_HINT </Name>
< значение xsi: Type = "xsd:строка" > {1,10,30} </Value>
</AlgorithmParameter>
</AlgorithmParameters>
<Columns>
</MiningModel>
</ObjectDefinition>
Далее внесите следующие изменения в тексте команды, в который были извлечены:
- Добавьте параметры, которые вы хотите изменить, если они уже не в модели. Параметры по умолчанию являются частью XMLA выход, так что если ваш базовая модель не содержит каких-либо параметров, вам понадобится добавить раздел XML для Аналитики, который содержит параметры.
- Удалите ненужные пробелы и все разрывы. В данном пошаговом руководстве XMLA хранится в виде строка в переменной, которая не может содержать разрывы. Если вы оставите в любой разрывы, проблема не обнаружен на проверки пакет , но во время выполнения, ядро служб Analysis Services пытается выполнить XMLA и происходит сбой с сообщением об ошибке.
Чтобы очистить файл, используйте ваш любимый текстовый редактор. Пробельные символы, такие как символы табуляции и несколько символов пробела являются хорошо, но вы можете уда��ить их, если вам нравится, чтобы сократить строка переменную. Существует не предел на размер строка переменных, но существует ограничение в 4 000 символов в редакторе выражение .
- Если ваша модель не не уже содержат параметры FORECAST_METHOD и PERIODICITY_HINT, используйте код, представленный выше и скопируйте XML-узел, который начинается с <AlgorithmParameters> и заканчивается с </AlgorithmParameters>. Вставьте его в текстовый файл, содержащий команды XMLA, непосредственно ниже строку, которая определяет алгоритм и до того раздела, который определяет столбцы.
- Измените инструкцию весь XMLA для удалять переносы. Можно использовать любой текстовый редактор, который вам нравится, до тех пор, пока вы убедитесь, что результат является однострочного текста.
Подготовить параметры замены
Для создания новых моделей, необходимо обновить основные команды XMLA, который вы только что создали, включив различные значения для параметров. Среди параметров, которые необходимо обновить являются имена модель и модель код. Прежде чем вы сделаете это, вы можете найти его полезным пересмотреть формат параметров, которые вам предстоит изменить:
- FORECAST_METHOD – может иметь значения СМЕШАННЫХ (по умолчанию), ARIMA и ARTXP.
- PERIODICITY_HINT – может иметь любое сочетание значений в виде строка , заключенные в скобки.
- MODEL_ID – должны быть уникальными для каждой модели, вы создаете или ошибка будет создаваться.
- MODEL_NAME – должен соответствовать MODEL_ID; Факультативный характер, но их соответствия делает процесс более понятным.
Службы Integration Services является чрезвычайно гибкой, так что есть много разных способов для хранения параметров и вставки их в модели XML для Аналитики. К примеру вы можете:
- Сохранить параметры как текст в SQL Server таблица, а затем вставить их в XML для Аналитики в цикле Foreach с помощью ADO.NET итератор.
- Сохранить команды XMLA в виде текстового файла и прочитать его с помощью соединений с плоскими файлами. Сохраните переменные в файле конфигурация и применять их во время выполнения.
- Сохранить команды XMLA как XML-файл, а затем прочитать его в пакет с использованием XML-источника. Вставьте переменные в XML с помощью свойства и методы из задачи «XML».
- Создайте несколько файлов XML для Аналитики заранее и затем прочитать файлы с сочетанием цикл Foreach и подключение к XML-источник.
Однако для этого сценария, необходимо иметь возможность легко добавить новые наборы параметров и просматривать и обновлять полный список моделей и параметров.
Таким образом, вы будете использовать первый метод: создать пары значение параметра как записи в базе данных SQL Server и затем чтения новых значений во время выполнения с помощью контейнера цикла Foreach. Таким образом, можно легко просмотреть или обновить параметры с помощью SQL-запросов.
Выполните следующую инструкцию для создания параметров таблица.
ИСПОЛЬЗОВАНИЕ [DMReporting]--замените Ваше имя базы данных
GO
/ ****** Объект: таблицы [dbo].[ModelParameters] Сценарий Дата: 11/09/2010 10: 56: 26 ****** /
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[ModelParameters](
[RecordID] [int] IDENTITY(1,1) НЕ NULL,
[RecordDate] [datetime] ЗНАЧЕНИЕ NULL,
[ModelID] [nvarchar](50) NULL,
[ModelName] [nvarchar](50) NULL,
[ForecastMethod] [nvarchar](50) NULL,
[PeriodicityHint] [nvarchar](50) NULL
) ON [ПЕРВИЧНОЙ]
GO
В следующей таблица перечислены параметры, которые используются для построения моделей в данном пошаговом руководстве. Вставьте эти значения параметров таблица , созданный с использованием сценария.
ModelID |
ForecastMethod |
PeriodicityHint |
ARIMA_1-7-10 |
ARIMA |
{1,7,10} |
ARIMA_1-10-30 |
ARIMA |
{1,10,30} |
ARIMA_nohints |
ARIMA |
{1} |
MIXED_1-7-10 |
MIXED |
{1,7,10} |
MIXED_1-10-30 |
MIXED |
{1,10,30} |
MIXED_nohints |
MIXED |
{1} |
ARTXP_1-7-10 |
ARTXP |
{1,7,10} |
ARTXP_1-10-30 |
ARTXP |
{1,10,30} |
ARTXP_nohints |
ARTXP |
{1} |
Этот сценарий использует параметры FORECAST_METHOD и PERIODICITY_HINT потому, что они относятся к числу самых важных параметров для модели временных рядов (также потому, что они представляют собой строка значения и легко изменить!).
Однако параметры, изменяемые будет полностью различны для других алгоритмов. Например если вы строите модель кластеризация , можно изменить параметр CLUSTERING_METHOD и построить модели с помощью каждого из четырех кластеризация методы, такие как K-Means. Вы также можете попробовать, изменяя MINIMUM_SUPPORT параметра, или же попробовать различные семена кластера. Список параметров различных алгоритмов, алгоритм технические справочные разделы (http://msdn.microsoft.com/en-us/library/cc280427.aspx) в библиотеке MSDN.
Важное примечание для данных шахтеров: изменяя значения параметров может сильно повлиять на результаты моделирования. Таким образом вы должны иметь своего рода план для анализа результатов и прополка плохо совпадение модели.
Например потому что алгоритм временных рядов очень чувствителен к подсказок периодичности, он может привести плохие результаты, если вы предоставите неправильно указание. Если указать, что данные содержат загрузок циклов и он на самом деле содержит ежемесячных циклов, алгоритм пытается совпадение данные для предлагаемых недельного цикла и (как правило) приводит к странным результатам. Некоторые из моделей, созданных этим процессом автоматизации свидетельствуют этот результат.
Есть много способов вы можете проверить обоснованность моделей:
- Используйте описательные статистические данные и метаданные для отдельных моделей для ликвидации моделей, которые имеют характеристики overfitting или бедных совпадение.
- Проверка наборов данных и модели с помощью перекрестной проверки или один из других мер точности, предоставляемый SQL Server. Для получения дополнительной информации, смотрите проверка моделей интеллектуального анализа данных (http://technet.microsoft.com/en-us/library/ms174493.aspx) в SQL Server книг Online.
- Выбрать только параметры и значения, которые нужны для бизнес-задачи; Используйте бизнес-правила для вашего моделирования.
Это завершает подготовку, и теперь можно построить три пакета.
Инструкции для каждого пакет начинаются с диаграмма, иллюстрирует потока операций пакет и краткое описание компонентов пакет .
Диаграмма следуют шаги, которые можно выполнить для настройки каждой задачи или назначение.
Этап 2 - создание модели
В ходе этапа 2 вы построить пакет , который создает много моделей интеллектуального анализа данных, с помощью шаблонов и параметров, подготовленную на этапе 1. Из числа этих моделей вы можете выбрать анализ наилучшим образом соответствует вашим потребностям. Этот пакет включает следующие задачи:
- Первоначальная задача Выполнение SQL, который получает имена моделей и параметров моделей из реляционной базы данных и затем сохраняет результаты запрос в ADO.Чистый строк переменной
- Контейнер цикл Foreach, который выполняет итерацию значения, хранящиеся в ADO.Чистый строк переменной и затем передает новые модели имена и параметры модели, по одному за раз, для задачи «Сценарий» и выполнение DDL служб анализа задачи внутри цикла Foreach
- Задача «Сценарий», которая загружает базовый XML для Аналитики заявление из переменной, вставляет новые параметры, а затем записывает из новой XMLA в другую переменную
- Задача Выполнение инструкции DDL служб Analysis Services, который выполняет обновленный XML для Аналитики заявление, содержащееся в переменной

Создание пакета и переменных (CreateParameterizedModels.dtsx)
- Создать новый пакет служб Integration Services и назовите его CreateParameterizedModels.dtsx.
- Настроить переменную, которая хранит параметры модели. Имя переменной должно быть пользователя: objAllModelParameters, и переменная должна иметь тип объекта. Убедитесь, что переменная имеет пакет область, потому что он передает значения из результатов запрос , возвращаемых параметров модели получить («выполнение SQL»), чтобы цикл Foreach.
- Добавьте задачу «Выполнение SQL» для пакет , который вы только что создали и назовите его получить параметры модели.
- В редактор задачи «Выполнение SQL», укажите базу данных, которая хранит параметры модели. В этом пошаговом руководстве используется диспетчер соединений OLE DB.
- Для SQLSourceType свойство, укажите прямой вводи вставьте следующий запрос.
Настройка выполнения SQL задачи (Get модель параметров)
Выберите MODEL_ID ModelID AS,
ModelID AS MODEL_NAME,
ForecastMethod AS FORECAST_METHOD,
PeriodicityHint AS PERIODICITY_HINT
ОТ dbo.ModelParameters
- Для ResultSet свойство, выберите полной строки, набор. Это позволяет хранить Многорядные результат в переменной.
- В результирующий набор панели, для имя результата, введите 0 (ноль) и затем присвоить переменной пользователя: objAllModelParameters.
Настройка контейнера «цикл по каждому элементу» (определение модели Foreach)
Теперь, загружены, набор параметров в объектную переменную, передайте переменную в контейнере цикл Foreach, который затем выполняет операцию для каждой строки данных:
- Создание контейнера цикла Foreach и назовите ее определения модели Foreach.
- Выберите контейнер цикл и откройте переменных окно, чтобы создать следующие переменные с данных заданы типы, ограничена в контейнере цикл:
User::strBaseXMLA Строка
User::strModelID Строка
User::strModelName Строка
User::strForecastMethod Строка
User::strPeriodicityHint Строка
User::strModelXMLA Строка
- Открытый Редактор циклов Foreach. Для коллекции, выбрать ADO.NET перечислителя.
- В Редактор циклов Foreach, настроить, выбрав переменные пользователя: objAllModelParameters в переменная источник объекта ADO раскрывающегося списка. Не изменяйте режим перечисления по умолчанию — только вы передаете в одной таблица, так что настройка по умолчанию, строк в первой таблица, является правильным.
- Нажмите кнопку сопоставления переменной, а затем назначить столбцы из параметров индексы столбцов в переменных данных следующим:
User::strModelID 0
User::strModelName 1
User::strForecastMethod 2
User::strPeriodicityHint 3
- Добавьте задачу «Сценарий» в контейнере цикл и назовите его обновление модели XML для Аналитики.
- В редактор задачи сценария, укажите свойства переменных следующим:
User::strBaseXMLA Только для чтения
User::strModelID Только для чтения
User::strModelName Только для чтения
User::strForecastMethod Только для чтения
User::strPeriodicityHint Только для чтения
User::strModelXMLA чтение и запись
- Нажмите кнопку изменить сценарий добавить код, который заменит строка для каждого значения переменной.
Примечание: код для выполнения этой задачи включен в приложение. Задача «Сценарий» выполняет операцию простой: он находит по умолчанию значения в основных XMLA и вставляет новые значения параметров, выполнив строка замены. Вы также могли бы сделать это с использованием регулярных выражений или методы XML, конечно.
- Добавьте задачу «Обработка средствами Analysis Services» в контейнере цикл и назов��те его выполнить XMLA модель.
10. Для связь свойство, укажите экземпляр служб Analysis Services, где хранятся ваши модели.
11. На DDL вкладка, для SourceType, выбрать переменнойи затем выберите переменную User::strModelXMLA.
Это завершает пакет , который создает модели. Теперь можно выполнить только этот пакет , щелкните правой кнопкой мыши пакет в обозревателе решений и выбрав выполнение сейчас.
После запуска пакет , если нет ошибок, можно подключиться к базе данных служб Analysis Services с помощью среды Management Studio SQL Server и посмотреть список новых моделей, которые были созданы. Однако нельзя просматривать модели или пока создавать прогнозирующие запросы. Это потому, что эти модели являются просто метаданные до тех пор, пока они обрабатываются, и они не содержат никаких данных или шаблонов. В очередной пакетбудет обрабатывать модели.
Этап 3 - процесс модели
Этот пакет получает список допустимых моделей с сервера служб Analysis Services, а затем обрабатывает модели, использовать задачу «Обработка средствами Analysis Services».
До обработки, модель, созданную с помощью XML для Аналитики представляет собой лишь определение: коллекция метаданные , который определяет параметры и источник привязки данных. Обработки получает данные из данных Forecasting источник, и затем он генерирует моделей, основанных на алгоритме, указанное. (Для получения дополнительных сведений о структуре модели интеллектуального анализа данных и обработки, см. структуры интеллектуального анализа данных (http://msdn.microsoft.com/en-us/library/ms174757.aspx) в библиотеке MSDN.)
В целом это как пакет обрабатывает обработки:
- Первая задача выполнить запрос интеллектуального анализа данных выдает запрос для получения списка допустимых моделей. Этот перечень записывается временной таблица в СУБД.
- Следующая задача «Выполнение SQL», извлекает имена моделей из этой таблица и затем помещает их в ADO.Чистый строк переменная.
- Контейнер цикл занимает ADO.Чистая переменной содержимое строк в качестве вклада, а затем он обрабатывает каждой модели серийно, с помощью встроенного обработка средствами Analysis Services задачи.
- Наконец вы обновить статус модели.

Создание пакета и переменных (ProcessEmptyModels.dtsx)
- Создать новый пакет служб Integration Services и назовите его ProcessEmptyModels.dtsx.
- С фоном пакет выбран, Добавление пользовательской переменной, objModelsList. Эта переменная будет иметь пакет область и будет использоваться для хранения списка моделей, доступных на сервере.
- Создание новой задачи Запрос интеллектуального анализа данных и назовите его выполнить DMX-запрос.
- В редактор задач запросов интеллектуального анализа данных, модель интеллектуального анализа данных tab, укажите базу данных служб Analysis Services, содержащую модели интеллектуального анализа временных рядов.
- Для структуры интеллектуального анализа данных, выбрать прогнозирование.
- Нажмите кнопку запроса вкладку. Здесь, вместо того, чтобы создать прогнозирующий запрос, вставьте в него следующий текст из содержимого запрос. Содержание запрос возвращает метаданные о модели и данные, уже хранятся в модели в виде суммарной статистики.
Добавьте задачу «запрос интеллектуального анализа данных» (выполнить DMX-запрос)
ВЫБЕРИТЕ MODEL_NAME, IS_POPULATED, LAST_PROCESSED, TRAINING_SET_SIZE
ОТ $системы.DM_SCHEMA_MINING_MODELS
Не все из этих столбцов требуются для обработки, но можно добавить столбцы в ��астоящее время и обновить информацию, которая позже.
- На вывода вкладка, для связь, выберите реляционной базы данных, где хранятся результаты. Для этого решения, это < имя локального сервера >/DM_Reporting.
- Для выходной таблица, введите имя временной таблица (в это решение, tmpProcessingStatus) и затем выберите параметр падение и восстановления выходную таблица.
- Добавить новую задачу выполнить SQL и назовите ее списка необработанных модели*.* Подключите его к предыдущей задаче.
- В редактор задачи «Выполнение SQL», для связь, используйте соединений OLE DB, а затем выберите имя сервера: к примеру, < имя локального сервера >/DM_Reporting.
- Для привести набор, выберите полный результирующий набор.
- Для SQLSourceType, выберите прямой ввод.
- Для инструкции SQL, введите следующий текст запрос .
Создание выполнения задачи SQL (перечень необработанных модели)
Выберите MODEL_NAME от tmpProcessingStatus
- На результирующий набор tab, назначить переменных столбцов в результирующий набор . Существует только один столбец в результирующий набор, так что присвоить переменную, User::objModelList, чтобы ResultSet 0 (ноль).
Создайте цикл Foreach контейнер (модель Foreach в переменной)
К настоящему времени вы должны быть очень комфортно с использованием сочетание «выполнение SQL» и контейнер.
- Создайте новый контейнер цикл и назовите его модель Foreach в переменной. Подключите его к предыдущей задаче.
- С помощью контейнера цикл выбран, откройте переменных окнои затем добавьте три переменные, ограничена в контейнере цикл. Последние две переменные работать вместе: Сохраните шаблон команды обработки в одной переменной, а затем используется служб Integration Services выражение изменять текст и сохранить изменения для второй переменной:
strModelName1 Строка
strXMLAProcess1 Строка
strXMLAProcess2 Строка
- В Редактор циклов Foreach, набор тип перечислителя перечислитель ADO по каждой СТРОКЕ.
- В конфигурацияперечислителя панель, набор переменная источник объекта ADO для User::objModelList.
- Задать режим перечисления для строк в первой таблица только.
- В переменных отображение панели, присвоить переменной, User::strModelName1, индекс 1. Это означает, что каждая строка одно -столбец таблица , возвращаемой функцией запрос будет заполняться в переменную.
Добавление служб Analysis Services обработка задачи цикла Foreach (процесс текущей модели)
Редактор для этой задачи требует что вы сначала подключиться к базе данных служб Analysis Services и затем выбрать из списка объектов, которые могут быть обработаны. Однако потому что вам нужно автоматизировать эту задачу, нельзя использовать интерфейс для выбора объектов для обработки. Так как вы итерацию списка объектов для обработки?
Решение заключается в том, чтобы использовать выражение изменить содержимое свойство ProcessingCommand. Вы использовать переменную, strXMLAProcess1, который набор вверх ранее, для хранения базовых XML для Аналитики для обработки модели, но вы вставьте местозаполнитель, который можно изменить позже, когда вы читаете переменной. Изменить команду, используя выражение и записи новых XMLA на вторую переменную, strXMLAProcess2.
- Перетащите новую задачу Обработка средствами Analysis Services в контейнере цикл, который вы только что создали. Назовите его текущей модели процесса.
- С ��ыбранного цикла Foreach, откройте переменных окно, а затем выберите переменную User::strXMLAProcess2.
- В свойства панели, выберите оценивать как выражение и набор его действительно.
- Для значения переменной введите или построить это выражение.
ЗАМЕНИТЬ (@ [User::strXMLAProcess1], "modelnamehere" @ [User::strModelName1])
- В редактор задачи обработки служб анализа, нажмите кнопку выражения, а затем разверните список выражений.
- Выберите ProcessingCommand и затем введите имя переменной следующим:
@ [User::strXMLAProcess2]
Еще один способ для обучения модели можно было бы добавить задачи обработки внутри же цикл Foreach, который использовался для создания модели. Однако есть веские причины для создания и обработки моделей в отдельных пакетах. К примеру:
- Обработка может занять много времени, и это зависит от соединения с источник данных.
- Это упрощает отладку проблем, когда модель создания и обработки находятся в отдельных пакетах.
Кроме того задача запрос интеллектуального анализа данных, которая приводится в поток управления может использоваться для выполнения различных типов запросов вместо источникданных служб Analysis Services. Можно использовать запросы наборов строк схемы в рамках этой задачи для получения сведений о других объектов служб Analysis Services, включая кубов и табличной модели, или даже запустить инструкции DDL расширений интеллектуального анализа данных (DMX). (В отличие от этого, компонент преобразования запросов интеллектуального анализа данных, доступных в поток данных, может использоваться только для создания прогнозов к существующей модели интеллектуального анализа данных.)
Последний шаг на этом этапе заключается в том, чтобы добавить задачу, которая обновляет статус вашей модели интеллектуального анализа данных. Теперь можно выполнить этот пакет как раньше.
Добавьте задачу «запрос интеллектуального анализа данных» после цикла Foreach (обновление обработки статус)
Эта задача использует задачи «Запрос интеллектуального анализа данных», чтобы получить обновленный статус модели интеллектуального анализа данных и записи, реляционных данных таблица.
- Щелкните правой кнопкой мыши задачу запрос интеллектуального анализа данных, созданный ранее, потому что он имеет все права соединения и текста правильный запрос и нажмите кнопку копию.
- Вставьте задачи после цикла Foreach контейнера и подключите его в ближайший внешний цикл.
- Переименуйте задачу обновление обработки статуса.
- Открытый редактор задач запросов интеллектуального анализа данных, нажмите кнопку вывода вкладке и убедитесь, что параметр падение и восстановления выходную таблица выбран.
Это завершает пакет. Теперь можно выполнить этот пакет как раньше.
При выполнении этот пакет, фактической обработки каждой модели может занять довольно долгое время, в зависимости от того, сколько модели доступны. Вы можете добавить ведения журнала в пакет для отслеживания времени, используется для обработки каждой модели.
Этап 4 - создать прогнозы для всех моделей
В этот пакетвы создавать прогнозирующие запросы, с помощью задачи «Запрос интеллектуального анализа данных» и применять их для всех моделей, которые вы только что создали и обработки:
- Вы сначала использовать «выполнение SQL» для запрос списка моделей в базе данных и сохранить этот перечень в переменной.
- Затем цикл Foreach использует переменную сначала настроить целевые показатели прогноза, вставляя название модели из переменной в две задачи Запрос интеллектуального анализа данных.
- Вы пишете результаты прогноза в таблица в реляционной базе данных, используя пару задач потока данных, которые также выполнять некоторые полезные метаданныезапись.
- Выполнение инструкции DDL служб Analysis Services задача выполняет обновленный XML для Аналитики заявление, содержащееся в переменной.
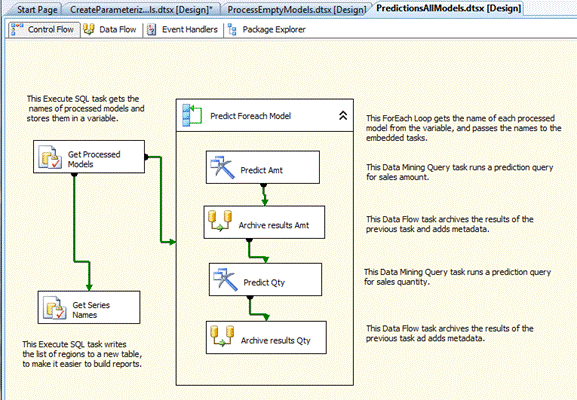
Создание пакета и переменных (PredictionsAllModels.dtsx)
- Создать новый пакет служб Integration Services и назовите его PredictionsAllModels.dtsx.
- Создайте переменную с пакет область :
objProcessedModels Объект
Создание выполнения задачи SQL (получить обработки модели)
- Создание новой задачи Выполнение SQL и назовите его получить обработки модели.
- В редактор задачи «Выполнение SQL», для связь, использование соединений OLE DB и для сервера, введите *< имя локального сервера > /*DM_Reporting.
- Для привести набор, выберите полный результирующий набор.
- Для SQLSourceType, выберите прямой ввод.
- Для инструкции SQL, введите следующий текст запрос . (Добавить условие WHERE призвана гарантировать, что не создается прогноз против модель, которая не была обработана, который будет генерировать ошибку).
Выберите MODEL_NAME от dbo.tmpProcessingStatus
ГДЕ LAST_PROCESSED IS NOT null
- На результирующий набор tab, назначить переменных столбцов в результирующий набор . Существует только один столбец в результирующий набор, так что присвоить переменной User::objProcessedModels ResultSet 0 (ноль).
Совет: когда вы работаете с модели интеллектуального анализа данных и особенно при создании сложных запросов, мы рекомендуем что вы строите DMX-запросы заранее, открыв модель непосредственно в разработчик бизнес-аналитики и использовать построитель прогнозирующих запросов, или запуская построитель прогнозирующих запросов от SQL Server Management Studio. Причина заключается в том, что когда вы строите запросы с помощью конструкторов интеллектуального анализа данных в среде Management Studio SQL Server или разработчик бизнес-аналитики, службы Analysis Services проводит некоторую проверку, которая позволяет вам просматривать и выбирать действительных объектов. Однако построитель запросов, представлена в задаче «Запрос интеллектуального анализа данных» не имеет этой связи и не может проверить или помочь с выбранными.
Создание «выполнение SQL» (Get серии имена)
Эта задача не является строго обязательным для прогнозирования, но он создает данные, является полезным позже для отчетности.
Напомним, что модель интеллектуального анализа данных временных рядов основывается на данные о продажах для различных производственных линий в различных регионах, с каждой комбинации линия продукции плюс регион одной серии. К примеру можно прогнозировать продажи для продукта M200 в Европе или продукта M200 в Северной Америке. Здесь имя ряда извлекается и хранятся в таблица, что делает его легче группировать и фильтровать прогнозы позднее в службах Reporting Services:
- Добавить новую задачу Выполнение SQL и назовите его получить имена рядов.
- Подключите его к предыдущей задаче.
- В редактор задачи «Выполнение SQL», выбрать соединений OLE DBи связь, тип *< имя локального сервера > /*DM_Reporting.
- Для привести набор, выберите ни.
- Для SQLSourceType, выберите прямой ввод.
- Для инструкции SQL, введите следующий текст запрос .
ЕСЛИ СУЩЕСТВУЕТ
(Выберите [modelregion] из DMReporting.dbo.tmpModelRegions)
BEGIN
УСЕЧЕНИЕ таблицы DMReporting.dbo.tmpModelRegions
Вставка DMReporting.dbo.tmpModelRegions
Выбор отдельных [ModelRegion]
ОТ AdventureWorksDW2008R2.dbo.vTimeSeries
END
Создайте цикл Foreach (предсказать Foreach модель)
В этом цикле Foreach, вы создаете две пары задачи: прогнозирующий запрос плюс данных потока для обработки результатов, один для сумма и один для количество.
Вы можете спросить, почему генерировать результаты для сумма и количество отдельно, когда построитель прогнозирующих запросов позволяет предсказать оба сразу?
Причина заключается в том, что интеллектуального анализа запрос возвращает в��оженный набор строк для каждого ряда данных вы предсказать, но поставщики в службы Integration Services может работать только с плоские наборы строк. Если вы предсказать, как сумма и количество в одном запрос, набор строк содержит много значения NULL, когда уплощенная. Вместо того, чтобы попытаться удалить значения NULL и отсортировать результаты, это проще для создания отдельного набор результатов и затем объедин��ть их позднее в потока данных служб Integration Services.
- Создайте новый контейнер цикл и назовите его предсказать модель Foreach. Подключите его к задаче, получить обработки модели.
- С помощью контейнера цикл выбран, откройте переменных окно и создайте новую переменную областью действия задачи, а именно:
strModelName Строка
- Возвращение к Редактор циклов Foreachи набор тип перечислителя перечислитель ADO по каждой СТРОКЕ.
- В конфигурацияперечислителя панель, набор переменная источник объекта ADO для User::objProcessedModels.
- Задать режим перечисления для строк в первой таблица только.
- В переменные сопоставления панели, присвоить переменной User::strModelName для индекса 0. Каждая строка одно -столбец таблица , возвращаемой функцией запрос подается в переменную strModelName, который в свою очередь используется для обновления прогнозирующий запрос в следующий набор задач.
Создание переменных для контейнера цикла по каждому элементу
Большая часть работы в этот пакет осуществляется значений переменных. Создается один набор переменных, хранящих текст прогнозирующих запросов, а затем вставить имя модели интеллектуального анализа данных, поиск в другой переменной, strModelName. Это иллюстрирует полезным методом в службах Integration Services: Обновление содержимого переменной с помощью выражение как определения переменной.
- В цикле Foreach создайте четыре новых переменных:
strQueryBaseAmount Строка
strQueryBaseQty Строка
strPredictAmt Строка
strPredictQty Строка
- Для значения переменной strQueryBaseAmount, введите следующий запрос.
Выберите плоский «ModelNameHere» как [имя модели]
[ModelNameHere].[Модель регион] как [модель и регион],
(Выберите $время как закрытое,
Сумма как NewValue,
PredictStDev ([количество]) как ValueStDev,
PredictVariance([Amount]) как ValueVariance
ОТ PredictTimeSeries ([ModelNameHere]. [Сумма], 10))
КАК прогнозы
ОТ [ModelNameHere]
Важные: здесь запрос форматируется для удобства чтения, но запрос не будет работать, если вы скопировать и вставить эти заявления в переменную как. Вы должны сначала скопируйте инструкцию в текстовый редактор и удалить все разрывы. К сожалению Редакторы служб Integration Services не обнаружить разрывы и поднять любые ошибки при редактировании задачи, но когда запуска пакет, вы получите ��ообщение об ошибке. Так что не забудьте сначала удалить разрывы!
- Для значения переменной strQueryBaseQty, введите следующий запрос после удаления разрывов.
Выберите плоский «ModelNameHere» как [имя модели]
[ModelNameHere].[Модель регион] как [модель и регион],
(Выберите $время как закрытое,
Количество как NewValue,
PredictStDev ([количество]) как ValueStDev,
PredictVariance([Quantity]) как ValueVariance
ОТ PredictTimeSeries ([ModelNameHere]. [Сумма], 10))
КАК прогнозы
ОТ [ModelNameHere]
Обратите внимание, заполнитель, ModelNameHere, в этой процедуре. Этот прототип будет заменен с именем допустимая модель, которая получает пакет из переменной strModelName.
Следующие шаги описывают создание выражение , обновляет текст запрос каждый раз, когда выполнении цикла.
- В переменных окно, выберите переменную strPredictQtyи затем открыть или выберите свойства окно для просмотра расширенных свойств переменной.
- Найдите Evaluate как выражение и набор значение для действительно.
- Найдите выражение и введите или вставьте следующее выражение.
ЗАМЕНИТЬ (@ [User::strQueryBaseQty], "modelnamehere" @ [User::strModelName2])
- Повторите этот процесс для переменной strPredictAmt, используя следующее выражение.
ЗАМЕНИТЬ (@ [User::strQueryBaseAmount], "modelnamehere" @ [User::strModelName2])
Создайте задачи «Запрос интеллектуального анализа данных» (предсказать Amt)
Теперь, когда вы настроили переменные, большая часть работы делается. Все, что вам нужно сделать, это создать пару задач запрос интеллектуального анализа данных. Каждая задача получает обновленный запрос строка из переменной, вы только что создали, выполняет запрос, а затем сохраняет прогнозы на указанный выход:
- Перетащите новую задачу запрос интеллектуального анализа данных в контейнере цикл. Назовите его предсказать Amt.
- В редактор задач запросов интеллектуального анализа данных, модель интеллектуального анализа данных вкладка, для связи, выберите имя службы Analysis Services экземпляр , содержащий ваши модели. Например*: <servername>.*ForecastingModels.
- Для структура интеллектуального анализа данных, выбрать прогнозирование.
- На вывода вкладка, для связь, выберите экземпляр компонента database engine, где будут храниться результаты. К примеру *<servername>.*DM_Reporting.
- Для вывода таблица, выберите или введите имя таблица , tmpPredictionResults. Выберите опцию падение и восстановления выходную таблица. (Примечание: если этот пакет никогда не запускались, необходимо ввести имя таблица, и задача будет затем создать его. Однако если вы повторным выполнением пакет, таблица уже существует, поэтому его необходимо удалить и затем перестройте.)
- На запроса вкладка, для построить запрос, вы можете вставить в базовый запрос временно. Он будет заменен с содержимое переменной. После того, как пакет выполняется один раз, вы должны увидеть текст базового запрос.
- С выбранной задачи прогнозирования Amt, откройте свойства панели и найдите выражения свойство.
- Разверните список выражений и добавить переменную @ [User::strPredictAmt] в качестве значения для QueryString свойство. Также можно выбрать значение из списка, нажав кнопку Обзор (...) кнопку.
Создайте второй запрос интеллектуального анализа данных задачи (предсказать Кол-во)
Повторите шаги, только что описал для запрос , который делает то же самое, только с количеством как прогнозируемый столбец:
- Создание новой задачи Запрос интеллектуального анализа данных с именем предсказать Кол-во
- Повторите шаги 2-6 из предыдущей процедуры точно так же, как описано.
- С выбранной задачи прогнозирования Qty, откройте свойства панели и найдите выражения свойство.
- Разверните список выражений и добавить переменную @ [User::strPredictQty] в качестве значения для QueryString свойство.
После того, как вы один раз запустить пакет , инструкцию расширений интеллектуального анализа данных содержит пустые скобки, подобные этим.
ВЫБЕРИТЕ УПЛОЩЕННАЯ '' как [имя модели]
[].[Модель регион] как [модель и регион],
(Выберите $время как закрытое, сумму как NewValue,
PredictStDev ([количество]) как ValueStDev,
PredictVariance([Amount]) как ValueVariance
ОТ PredictTimeSeries ([]. [Сумма], 10))
КАК прогнозы
ОТ]
Эти квадратные скобки будут заполняться в переменной, предоставляющий имя модели во время выполнения.
Для суммирования всех переменных активности во время выполнения:
- Этот пакет получает переменную со списком моделей.
- Цикл получает имя одной модели из списка.
- Цикл получает прогнозирующий запрос из переменной, вставляет имя модели и записывает новый прогнозирующего запрос.
- Задача « запрос » выполняет обновленный прогнозирующий запрос.
Обратите внимание, что все эти прогнозирующих запросов записи их результаты той же временной таблица, который удаляется и затем перестраивается в ходе каждого цикла. Таким образом необходимо добавить задачу потока данных в период, который перемещает результаты в архивную таблица , а также добавляет некоторые метаданные.
Создание задач потока данных в архив результаты
Помните, что вы создали отдельные прогнозы для значений данных, сумма и количество, чтобы избежать борьбы с большим количеством значений NULL в результатах. Затем они объединяются обратно для подготовки отчетов, чтобы сделать таблица , которая выглядит примерно так.
Идентификатор задания |
Время выполнения |
Series |
Временной срез |
Тип прогноза |
Прогнозируемое значение |
StDev |
Дисперсия |
012 |
2010-09-20 |
M200 Europe |
январь 2012 г. |
Сумма продаж |
283880 |
nnn |
nnn |
012 |
2010-09-20 |
M200 Europe |
Февраля 2012 года |
Сумма продаж |
251225 |
nnn |
nnn |
012 |
2010-09-20 |
M200 Europe |
январь 2012 г. |
Количество продаж |
507 |
nnn |
nnn |
012 |
2010-09-20 |
M200 Europe |
Февраля 2012 года |
Количество продаж |
758 |
nnn |
nnn |
Можно также добавить любые дополнительные метаданные , которые могли бы быть полезным позже, например, с момента предсказания были созданы, Идентификатор задание и так далее.
Препятствуйте нам принять другой взгляд на инструкции запрос расширений интеллектуального анализа данных, используемый для создания прогнозов.
Выберите время $ как закрытое, сумму как NewValue, PredictStDev ([количество]) как ValueStDev,PredictVariance([Amount]) как ValueVariance от PredictTimeSeries
Обычно называются имена столбец по умолчанию, которые создаются в прогнозирующий запрос по умолчанию, основанные на имя прогнозируемого столбец , так что имена будет что-то вроде PredictAmount и PredictQuantity. Однако, можно использоватьпсевдоним столбецв выходных данных (здесь, это NewValue) чтобы легче объединить прогнозируемые значения.
Опять же потому что службы Integration Services являются настолько гибок, есть много других способов, вы можете это сделать:
- Хранить результаты в памяти и объединить их перед записью в архивную таблица.
- Храните результаты в разных столбцах, один для каждого типа прогноза.
- Запись результатов временные таблицы и объединить их позже.
- Используйте формат файлов raw служб Integration Services для быстрого написания а затем читать промежуточные результаты.
Однако в этом случае, вы хотите проверить данные прогноза, формируемый каждого запрос. Таким образом вы использовать следующий подход:
- Напишите предсказания во временную таблица.
- Используйте компонент источника OLE DB для получения прогнозов, которые были написаны для временной таблица.
- Используйте преобразование «производный столбец для очистки данных и добавить некоторые простые метаданные.
- Сохраните результаты в архивную таблица , используемый для представления на всех моделях.
На рисунке показана общего потока задач в рамках каждой задачи потока данных.
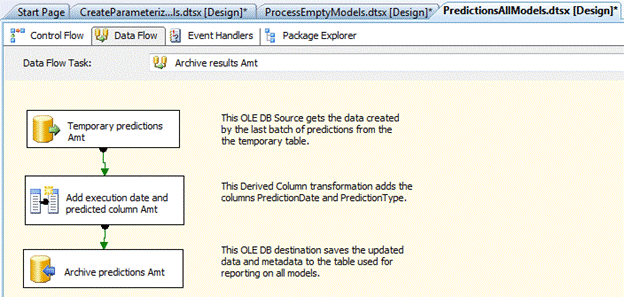
Создание задач потока данных (Qty результаты Архив, Архив результаты Amt)
- В цикле Foreach модели прогнозирования создайте две задачи потока данных и назвать их результаты Qty Архив и Архив результаты Amt.
- Задача его соответствующий запрос интеллектуального анализа данных, в порядке, показанном в схеме ранее потока управления для пакета 3 подключение каждой задачи потока данных.
Примечание: вы должны имеет эти задачи в определенной последовательности, потому что они используют ту же временную таблица и Архив таблица. Если службы Integration Services выполняет задачи параллельно, процессы могут конфликтовать при попытке получить доступ к той же таблица.
- В каждой задачи потока данных добавьте следующие три компонента:
- С данных OLE BD источник , который считывает из tmpPredictionResults
- Производный столбец преобразование , как они определены в следующей таблица
- Объект OLE DB назначение , который записывает в таблица ArchivedPredictions
- Создайте выражения в каждом производный столбец преобразованиедля создания данных для новых столбцов следующим.
Имя задачи |
Имя производного столбец |
Тип данных |
Значение |
Архив результатов Кол-во |
PredictionDate |
DateTime |
GETDATE() |
Архив результатов Кол-во |
PredictedValue |
строка |
Сумма |
Архив результатов Amt |
PredictionDate |
DateTime |
GETDATE() |
Архив результатов Amt |
PredictedValue |
строка |
Количество |
Подсказка: изоляции данных потоков для каждого типа прогноза имеет еще одно преимущество: это гораздо, гораздо легче возиться с пакет позже. К примеру вы можете решить, что нет никаких оснований для создания отдельного прогноза для количества. Вместо того, чтобы редактирование запрос или выходных данных, можно просто отключить эту часть пакет и он по-прежнему будет работать без изменений – вы просто не будете иметь прогнозы для количества.
Запуск отладки и аудита пакеты
Вот она-пакеты содержат все инструменты, вам нужно динамически создавать и обновлять несколько моделей интеллектуального анализа данных.
Пакеты для данного сценария были разработаны таким образом, чтобы их можно запускать отдельно. Мы рекомендуем запустить каждый пакет самостоятельно по крайней мере один раз, чтобы чувствовать себя за то, что каждый пакет производит. Позднее можно добавить лесозаготовок в пакеты для отслеживания ошибок, или создать родительской задачи чтобы соединить их, добавляя задачу «Выполнение пакета».
Этап 5 - анализ и предоставление отчетов
Теперь, когда у вас есть набор прогнозов для нескольких моделей, вы обеспокоены вероятно чтобы увидеть тенденций и проанализировать различия.
Использование средства просмотра интеллектуального анализа данных
Самый быстрый способ для просмотра отдельных моделей — с помощью средства просмотра интеллектуального анализа данных. Средство просмотра временных рядов Microsoft (http://technet.microsoft.com/en-us/library/ms175331.aspx) особенно удобно, потому что она сочетает в себе исторические данные с прогнозами для каждого ряда, и он отображает планки погрешностей для прогнозов.

Однако некоторые пользователи не удобны с использованием Business Intelligence Development Studio. Даже при использовании надстроек интеллектуального анализа данных для Microsoft Office, которая обеспечивает средство просмотра Microsoft Visio и время серии браузера, количество деталей в средстве просмотра временных рядов может быть огромным.
В противоположность этому, аналитики обычно хотят еще более подробно, включая статистику встроенных в содержимом модели, вместе с метаданные вы захватили о источник и параметров модели. Невозможно угодить всем!
К счастью служб Reporting Services позволяет выбрать данные, добавить дополнительные наборы данных и связанные отчеты, фильтр и группировка, поэтому можно создавать отчеты, которые отвечают потребностям каждого набор пользователей.
С помощью службы Reporting Services для интеллектуального анализа данных результатов
Вы уже видели, что потребность в отчетности и анализа вынудили многие из проектных решений пакет служб Integration Services.
Наши основные требования были следующими:
- Все соответствующие модели должны быть на одной диаграмме, для быстрого сравнения.
- Для упрощения сравнения, мы можем представить прогнозы для количества и количества отдельно.
- Результаты должны быть отделимыми от модели и региона.
- Нам нужно сравнить прогнозы за те же периоды, для нескольких моделей.
Чтобы сделать его проще для объединения данных, все данные сохранены в хранилище реляционных, чтобы избежать необходимости для запрос служб Analysis Services.
Дополнительные потребности могли бы включать:
- Диаграмма, показывающая исторических ценностей наряду с прогнозами.
- Статистические данные получены из сравнение прогнозирующих значений.
- Метаданные о каждой модели в связанный отчет.
Как аналитик вы можете даже более подробно, который легко захватить со службами Integration Services, а затем представить в связанные отчеты:
- Первая и последняя даты, используемые для подготовки каждой модели
- Список параметров алгоритма и шаблон формулы
- Описательные статистические данные, которые кратко неустойчивости и диапазон источник данных в каждой серии, или через серии
Однако для целей данного пошагового руководства, уже существует много деталей для сравнения моделей.
На следующем рисунке показано, что службы Reporting Services отчет, который сравнивает результаты прогноза для каждой модели:
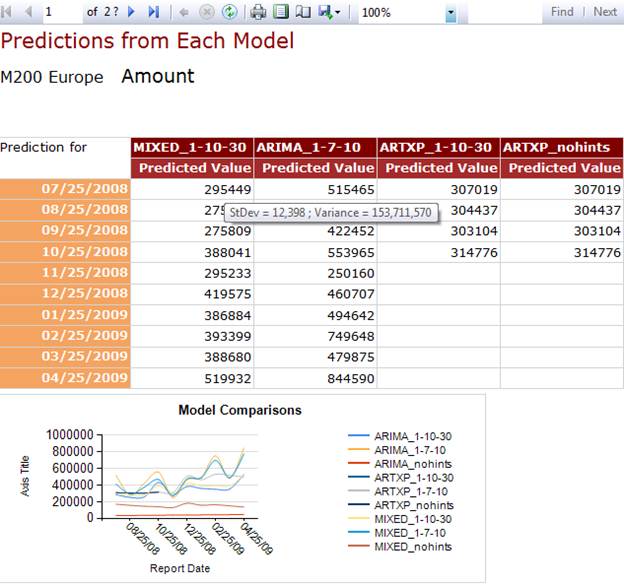
Обратите внимание, что можно настроить отчет для отображения всех видов информации в подсказках — в данном примере, как наведении мыши прогноза, появиться стандартное отклонение и дисперсия для прогнозов.
Следующее показывает ряд диаграмм, которые были скопированы в матрицу. С помощью матрицы, можно создать набор отфильтрованных диаграммы. Эта серия графиков показывает прогнозы на сумму для всех моделей.
|
M200 |
R750 |
T1000 |
Европа |
|
|
|
Северная Америка |
|
|
|
Pacific |
|
|
|

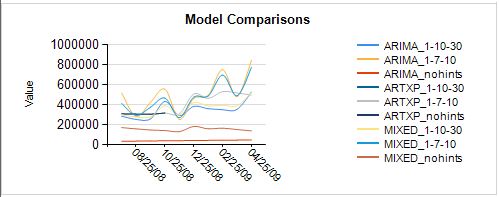
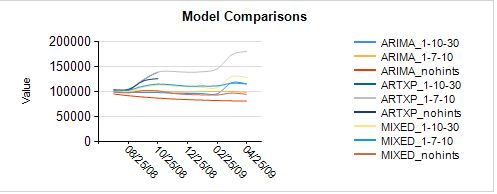
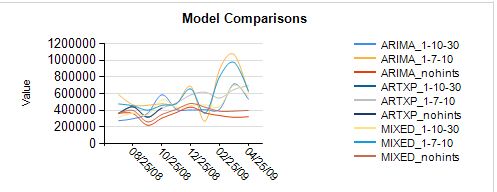

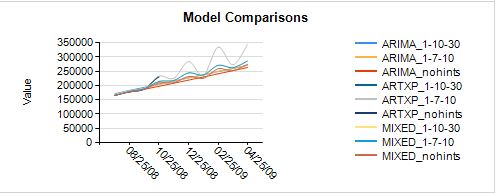
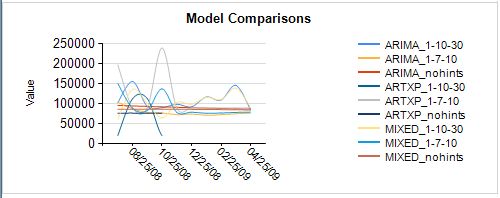
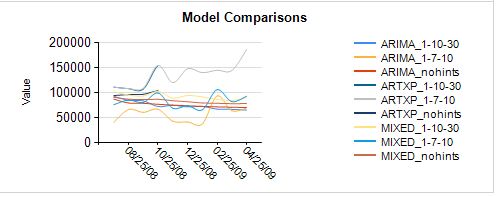
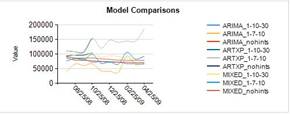
Интерпретация результатов
Если вы знакомы с моделированием серии времени, несколько тенденций начинают выскочить на вас только из проверки этих диаграмм:
- Есть некоторые серии extreme моделей ARIMA — возможно периодичности указание является обвинить.
- Прогнозы в моделях ARTXP cut off в определенный момент многих серии. Это ожидается, потому, что обнаруживает нестабильности модели ARTXP и не делать прогнозы, если они не являются достаточно надежными.
- Вы ожидаете СМЕШАННЫЕ модели обычно выполняет лучше, потому что они сочетают в себе лучшие характеристики ARTXP и ARIMA. Действительно они кажутся более надежными, хотя вы хотели бы проверить, что.
Интересны следующие линии тренда, и они иллюстрируют некоторые проблемы, с которыми вы можете увидеть с модели. Результаты может указывать, что данные это плохо, имеется недостаточно данных или данные слишком переменной по совпадение.
R750 Европа (сумма) |
R750 Европа (количество) |
|
|
R250 Северной Америки (сумма) |
R250 Северной Америки (количество) |
|
|

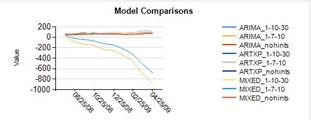
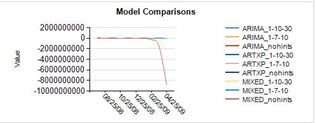

Когда вы видите, дико различные тенденции от моделей на тех же данных, вы конечно же следует пересмотреть параметры модели, но может также использовать перекрестное прогнозирование или агрегат данных по-разному, чтобы избежать слишком сильно под влиянием одного ряда данных:
- Перекрестное прогнозирование можно построить надежную модель и делать прогнозы, основанные на нем для каждого ряда. Модели ARTXP поддерживает перекрестное прогнозирование.
- Если у вас нет достаточного количества данных для эффективного анализа каждого региона или продукт линии отдельно, может получить лучшие результаты, кувейтских продукта или региона и создавать прогнозы от агрегат модели.
Обсуждение
Интеллектуального анализа данных может быть трудоемким процессом. От сбора данных и подготовки, моделирование, тестирование и изучение результатов много усилий необходима для обеспечения данных поддерживает предполагаемый анализ и что выходные данные модели имеет смысл.
Некоторые части процесса построения модели будет всегда требуют вмешательства человека – понять результаты, например, требует тщательного пересмотра экспертом, который может оценить ли номера иметь смысл.
Однако, автоматизируя часть процесса интеллектуального анализа данных, службы Integration Services могут не только ускорить процесс, но и потенциально улучшить результаты. Например если вы не знаете, какие смесь алгоритмов производит самые лучшие результаты, или то, что самое время циклов в ваших данных, автоматизации можно использовать для экспериментирования.
Кроме того существуют преимущества за рамки простой экономии времени.
В случае модели ансамбль
Automation поддерживает создание ансамбля моделей. Ансамбль модели (грубо говоря) являются модели, которые строятся на ��е же данные, но используют различные методы анализа.
Обычно результаты нескольких моделей по сравнению или вместе взятых, приносить результаты, которые лучше, чем какой-либо единой модели. Оценки несколько моделей для той же задачи прогнозирования теперь считается наилучшей практики, даже с лучших данных. Некоторые причины, которые часто упоминается для использования ансамбль модели включают в себя:
- Во избежание Оверфиттинг. Когда модель слишком близко узором на специальную подготовку, набор, вы получите большой прогнозы на тест данных набор соответствующий обучающих данных и много изменчивости, когда вы попробовать модель на реальных данных.
- Выбор переменных. Каждый тип алгоритма по-разному обрабатывает данные и поставляет различные идеи. Вместо того, чтобы сравнить прогнозы, как мы сделали здесь, можно использовать один алгоритм для определения наиболее важных переменных или prescreen для корреляции, которые может маскировать другие наиболее интересных моделей.
Было много исследований в последние годы на лучшие методы для объединения оценок от ансамбля моделей — слияние, упаковка в мешки, голосования, в среднем, взвешивания задняя доказательств, ограничением и так далее. Обсуждение моделей ансамбль выходит за область настоящего документа, и вы увидите, что мы не пытались объединить результаты прогноза в настоящем документе; Мы только представил их для сравнения. Однако мы рекомендуем вам прочитать связанные ресурсы чтобы узнать больше об этих методов.
Закрытие петель: толкование и получения отзывов о модели
Теперь, когда вы кратко изложены результаты в удобном для чтения доклада, что будет дальше? Как правило вы как раз думайте больше вопросов ответить!
- Как насчет внутреннего продвижения по службе или известных событий? Мы упразднили известна корреляция?
- Местные и культурные события могут существенно повлиять на продажи отдельных видов продукции. Вместо того, чтобы ожидать же сезонности в разных регионах, мы должны отдельные регионы для моделирования?
- Мы должны выбрать алгоритм временных рядов, которые можно объяснить последствия случайных или циклический внешние события, или же мы хотим для сглаживания данных найти общие тенденции?
- Можно сравнивать эти прогнозы графики с проекцией, проделанную традиционных бизнес метод сравнения год к дата?
- Как соотносятся эти прогнозы увеличения доли мишенью бизнес?
К счастью потому что вы создали расширяемую инфраструктуру для включения интеллектуального анализа данных в анализ с использованием служб Integration Services, будет относительно легко собрать больше данных, обновление моделей и уточнения вашей презентации.
Заключение
С результаты сохранены в хранилище реляционных данных, поощрять систематический подход к прогностической аналитики представил рамки для автоматизации интеллектуального анализа данных, этот документ.
В этом пошаговом руководстве показал, что относительно легко набор пакеты служб Integration Services для создания модели интеллектуального анализа данных и генерирующими прогнозы плотности от них. Рамки как один продемонстрировали здесь могут быть расширены для поддержки дальнейшего параметризации, поощрять использование модели ансамбля и включения интеллектуального анализа данных в других аналитических процессов.
Ресурсы
[1] Джейми Макленнан: прохождение SQL Server 2005 Integration Services для интеллектуального анализа данных
http://www.sqlserverdatamining.com/ssdm/Default.aspx?tabid=96 & Id = 338
[2] Microsoft Research: ансамбль модели
http://Academic.Research.Microsoft.com/Paper/588724.aspx
[3] Учебники по службам отчетов
http://MSDN.Microsoft.com/en-us/library/bb522859.aspx
[4] Майкла Ohler: оценка прогноза точность
http://www.isixsigma.com/index.php?Option=com_k2 & вид =элемент& id=1550:assessing-forecast-accuracy-be-prepared-rain-or-shine & Itemid = 1 & tmpl = компонент и печати = 1
[5] Статистические методы для оценки моделей интеллектуального анализа данных
http://MS-OLAP.blogspot.com/2010/12/Do-You-Trust-Your-Data-Mining-Results.HTML
[6] Джон Maindonald, «Интеллектуального анализа данных с точки зрения статистики»
http://maths.anu.edu.au/~johnm/DM/dmpaper.HTML.
Выражение признательности
Я выражаю благодарность моим коллегам за их помощь и содействие. Карла Sabotta (технический писатель, службы Integration Services) оказались бесценным опытом о шагах в каждом из пакетов служб SSIS, обеспечение того, что я не оставил вне что-нибыдь. Ranjeeta Нанда любезно группа тестирования служб Integration Services обзор код в задаче «Сценарий». Мэри Lingel (технический писатель, службы Reporting Services) принял мой сложных данных источник и разработала набор отчетов, которые сделали это смотреть простой.
Код для задачи «Сценарий»
Следующий код могут добавляться к задаче «Сценарий», чтобы изменить значения в определении модели XML. Это очень простой образец был написан с использованием VB.NET, но задачи «Сценарий» поддерживает C# как хорошо.
Количество окон сообщений были добавлены для проверки, что задача была обработки XML, как ожидалось. Вы в конечном итоге будет прокомментировать это. Также следует добавить строка длины проверки и другие для предотвращения инъекций расширений интеллектуального анализа данных.
Public Sub Main()
' получить базовый XML для Аналитики и создайте новый пустой XML для Аналитики используется для вывода
Dim strXMLABaseDef как String = Dts.Variables("strBaseXMLA").Value.ToString
Dim strXMLANewDef как String = strXMLABaseDef
' ��оздать локальные переменные и их заполнения значениями из SQL- запрос
Dim txtModelID как String = Dts.Variables("strModelID").Value.ToString
Dim txtModelName как String = Dts.Variables("strModelName").Value.ToString
Dim txtForecastMethod как String = Dts.Variables("strForecastMethod").Value.ToString
Dim txtPeriodicityHint как String = Dts.Variables("strPeriodicityHint").Value.ToString
' первый обновленный базовый XML для Аналитики с новой модели ID и имя модели
' <ID> ForecastingDefault </ID>
' <Name> ForecastingDefault </Name>
Dim txtNewID как String = «<ID>» & txtModelID & «</ID>»
Dim txtNewName как String = «<Name>» & txtModelName & «</Name>»
' вставить значения
strXMLANewDef = strXMLANewDef.Replace ("ForecastingDefault </ID> <ID>", txtNewID)
strXMLANewDef = strXMLANewDef.Replace ("<Name> ForecastingDefault </Name>", txtNewName)
' Отображать имена моделей – только при устранении неполадок
MessageBox.Show (strXMLANewDef, «Проверять новые модели ID и name»)
' создать временные переменные для замены операций
Dim strParameterName как String = ""
Dim strParameterValue как String = ""
' обновление значения для ПРОГНОЗА метода. Потому что все возможные значения имеют точно 5 символов, просто замените
strParameterName = «forecast_method»
strParameterValue = «СМЕШАННЫЙ» «значение по умолчанию
Если затем strXMLABaseDef.Contains(strParameterValue)
' заменить значения по умолчанию СМЕШАННЫЙ с все, что содержится в переменной из SQL Server запрос
strXMLANewDef = strXMLANewDef.Replace (strParameterValue, txtForecastMethod)
' отображать прогноз параметр value– для устранения неполадок только
MessageBox.Show (strXMLANewDef, «Проверить прогноз метод», MessageBoxButtons.OK)
Другое: MessageBox.Show («Проблемы с базовым XML для Аналитики», "XMLA определение не включает параметр," & _
strParameterName, MessageBoxButtons.YesNoCancel)
End If
«Ищите PERIODICITY_HINT значение
strParameterName = «periodicity_hint»
strParameterValue = «{1}» «значение по умолчанию
Если затем strXMLABaseDef.Contains(strParameterName)
Dim StartString As Integer = strXMLABaseDef.IndexOf("{")
Dim EndString As Integer = strXMLABaseDef.IndexOf("}")
' заменить все в переменной значение по умолчанию {1}
strXMLANewDef = strXMLANewDef.Replace (strParameterValue, txtPeriodicityHint)
MessageBox.Show (strXMLANewDef, «Проверьте периодичность подсказку», MessageBoxButtons.OK)
Другое: MessageBox.Show («Проблемы с базовым XML для Аналитики», "XMLA определение не включает параметр," & _
strParameterName, MessageBoxButtons.YesNoCancel)
End If
' сохранить заполненные определение переменной пакет
DTS.Variables("strModelXMLA").Значение = strXMLANewDef
DTS.TaskResult = ScriptResults.Success
End Sub
Для получения дополнительной информации:
http://www.Microsoft.com/SQLServer/: SQL Server веб-сайт
http://TechNet.Microsoft.com/en-US/SQLServer/: SQL Server TechCenter
http://MSDN.Microsoft.com/en-US/SQLServer/: SQL Server DevCenter