Загрузки данных с помощью Microsoft ® SQL Server® Integration Services (SSIS) (ru-RU)

SQL Server Технические статьи
Писатели: лен Уайетт, Тим Ши, Дэвид Пауэлл
Опубликовано: Март 2009
Применимо к: SQL Server 2008
Предложенная статья является машинным переводом оригинала.
Автоматизация интеллектуального анализа данных с помощью интеграции Services_files
Резюме: В феврале 2008 года корпорация Майкрософт объявила о загрузки рекордные данных с помощью Microsoft ® SQL Server® Integration Services (SSIS): 1 ТБ данных менее чем 30 минут. Что загрузки данных, с помощью SQL Server служб Integration Services, был 30% быстрее, чем предыдущие лучшее время с помощью коммерческих ETL средство. В этом документе изложены, он взял: программного обеспечения, оборудования и конфигурация . Мы будем описывать то, что мы сделали для достижения этого результата и внести предложения о том, как соотнести эти методы для типичных сценариев. Даже для клиентов, которые не имеют нужды довольно как это ориентир такие усилия могут научить много о получении оптимальной производительности.
Введение
Предприятия имеют постоянно растущим объемам данных, хранящихся во многих гетерогенных системах. Предоставлять конечным пользователям значимые, непротиворечивой и надежной информации, эти предприятия полагаются на технологии интеграции данных для извлечения, преобразования и загрузки данных (более известный как операции ETL) при передаче данных между системами. ETL инструменты такие, как Microsoft SQL Server Integration Services (SSIS) поддерживают эти виды деятельности по интеграции данных. Предприятия хотят знать, что ETL средство , они выбирают сможет поддержать любой объем данных, они могут потребовать и в то же время позволяет им интегрировать данные из любого из их гетерогенных источников данных.
Чтобы проиллюстрировать служб SSIS способность удовлетворять такие показатели потребностей, Microsoft и Unisys, организовал для загрузки более 1 терабайт (ТБ) данных, считанное из плоских файлов на четырех источник серверов в базу данных SQL Server на сервере одного назначение . В ходе этого испытания было зачитано данные, преобразуется из текстовых полей в типы данных базы данных, передаваемых по сети и вставляется в назначение базе данных менее чем 30 минут. Чтобы быть точным, 1.18 ТБ данных, плоский файл был загружен в 1794 секунд. Это эквивалентно 1.00 ТБ в 25 минут 20 секунд или 2,36 ТБ в час.
Важно отметить, что это не то же самое, как просто сделать массовую загрузку данных в базу данных. Если данные доступны в системе назначение , и если это не нужно быть стандартные или исправить ошибки до того, как он будет загружен, массовая загрузка данных имеет смысл. В более распространенный вариант где данные должны перемещать между системами и преобразован в пути необходимы инструменты ETL. Инструменты ETL как служб SSIS можно выполнять такие функции, как перемещение данных между системами, преобразования данных, проверки, ключ поиска и отслеживания lineage целостности. В наш 1 ТБ загрузки эксперимент мы не проводило широкие преобразованиями, потому что мы хотели запустить эксперимент, который был бы сопоставим с то, что другие поставщики средство ETL опубликовал.
Идея о возможности для сравнения средство является весьма важным. Клиенты должны иметь возможность сравнить инструменты ETL таким же образом, что они могут использовать TPC-E или TPC-H ориентир сегодня для сравнения реляционных баз данных. С��ществует не часто приняли ориентир для ETL-инструменты. Microsoft думает, должно быть. Стандартных критериев может привести к здоровой конкуренции, более высокого качества продукции и лучше публикации методов, используемых для высокой производительности. Корпорация Майкрософт поддерживает идею определения стандартный критерий, который отражает реального мира использования инструментов ETL.
Обзор архитектуры
Концептуально дизайн этой системы является очень простой, как показано на рисунке 1. Есть 56 потоков данных, получаемых как плоских файлов, с использованием генератора данных TPC-H, так что будет 56 случаев выполнения пакет служб SSIS параллельно. Они должны написать в один назначение базы данных. Каждый экземпляр пакет будет читать один из типов файлов, созданных генератор данных: клиентов, LineItem, заказы, часть, PartSupp и поставщика. Имена файлов для использования передаются в качестве аргументов в пакет. источник файлы будут описаны в следующем разделе, и служб SSIS пакет будут описаны подробно в разделе на дизайн па��ет служб SSIS.

Рисунок 1: поток концептуальных данных
На выходе каждый пакет направит другой раздел в назначение таблицы. Более точно, как показано на рисунке 2 каждый пакет будет записывать в отдельную таблица для максимальной производительности, и таблицы "переключается в" разделы больших размеров таблица. Это будут описаны более подробно в разделе на Настройка базы данных. Существует несколько раз, когда секционирование таблица является хорошей практикой, один из них при несколько больших вставок должны быть выполненных concurrently–exactly ситуация, у нас есть для этого сценария. Каждый из основных таблиц TPC-H (клиентов, LineItem, заказы, часть, PartSupp, поставщик) была разделена для этого упражнения. Крошечные таблицы нации и региона не были разделены.
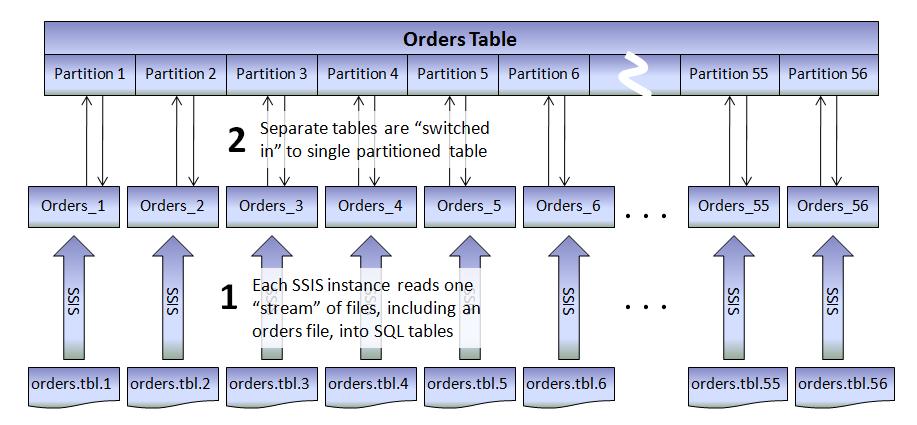
Рисунок 2: от плоских файлов для секционированных таблица
Служб SSIS пакет , загрузке данных была довольно проста. Рисунок 3 описывает это в деталях. Поток управления пакет состоит из шести потоков данных, одна для каждого из основных таблиц, которые выполняются последовательно. Каждый поток данных имеет плоский файл источник , посылать данные назначениеOLE DB. источник плоского файла содержит определения поле для его типа файлов, и типы данных поля должны быть преобразованы (32-разрядное целое число, типы даты/времени, деньги, и так далее). назначение OLE DB содержит сопоставление столбцов в потоке данных для столбцов в назначениетаблица в реляционной базе данных. Обратите внимание, что мы использовали OLE DB объект назначение, не SQL Server назначение. Это означает, что пакет мог бы написали данных к любому типу реляционной базы данных OLE DB адаптер, не только SQL Serverи что назначение базы данных не нужно быть на том же компьютере, на котором выполняется пакетслужб SSIS. Более подробная информация о пакет следовать в разделе Дизайн пакет служб SSIS.
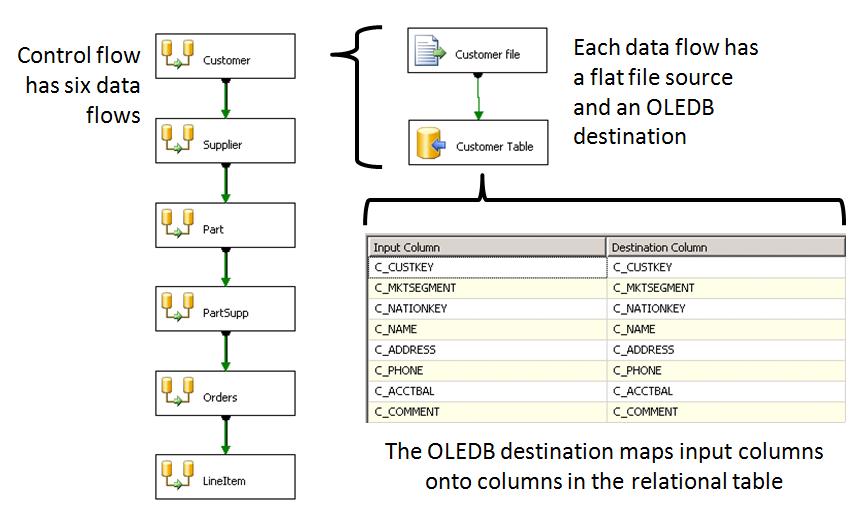
Рисунок 3: обзор пакет служб SSIS
Физически источник файлы распределены по четыре источник серверов и назначение база данных расположена на сервере Unisys ES7000. Как показано на рисунке 4, экземпляров пакет служб SSIS выполнить на источник серверы, и SQL Server СУБД работает на ES7000. Каждый источник сервер подключен к назначение с использованием двух 1 Gb Ethernet соединения, с тем чтобы обеспечить достаточную пропускную способность для этого сценария. Работа сети, к которой соединения были оттеснены от 70% до 100% мощности, поэтому важно создать идеальный сетевых параметров во избежание перегрузки ЦП с сети прерываний. Более подробную информацию о сервере, операционной системы и настройки сети находятся в следующих разделах настоящего документа.
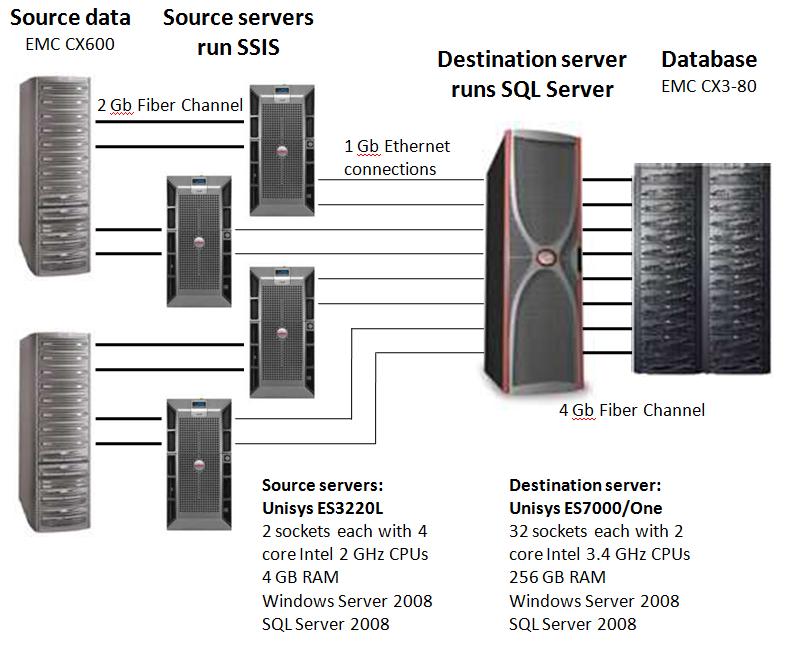
Рисунок 4: физической топологии
Исходные данные
Мы использовали генератор данных от Совета обработки транзакций TPC-H ориентиром для создания данных для этого эксперимента. Существуют две причины для этого выбора:
- Генератор предоставляет удобный способ для создания реалистичных данных, которые будут распознаваться многих людей.
- Выбор этой данных, набор позволила нам сделать прямое сравнение с результатами, достигнутыми другими поставщиками, которые использовали же данных, набор.
Хотя генератор данных TPC-H был использован, это не результат тестирования TPC-H. Это было просто для удобства использования, что данных, набор. Как отмечалось ранее, не существует общепринятых критериев для ETL-инструменты в настоящее время.
Генератор данных TPC-H называется DBGEN, и он создает текстовые файлы для загрузки в базу данных. Хотя служб SSIS можно переместить данные непосредственно из одной базы данных в другую, и этот шаблон использования рекомендуется из его эффективность, это не редкость в мире ETL для выгрузки данных из одной базы данных в плоских файлов и загрузки их в другой. По сути плоские файлы являются «наименьшего общего знаменателя» для обмена данными. Потому что DBGEN создает плоских файлов, мы решили использовать их точно так, как они были произведены.
DBGEN предоставляет параметр для разделения данных на несколько потоков, которые могут быть загружены параллельно. Например команда
dbgen –T o –fF –q необходимо dists.dss -s 1000 - C 56 -S 6
будет создавать данные для заказов и LINEITEMS таблиц в масштабе указывают 1000 (примерно 1 ТБ данных размер). Данные будут секционирована в 56 потоки, и команда будет создавать данные для потока 6.
Когда создается все данные для потока 6, будут представлены следующие файлы:
02/14/2008 07:31 PM 444,676,242 customer.tbl.6
02/14/2008 08:12 PM 14,551,494,208 lineitem.tbl.6
02/14/2008 08:12 PM 3,235,968,117 orders.tbl.6
02/14/2008 08:17 PM 444,959,263 part.tbl.6
02/14/2008 08:17 PM 2,216,550,617 partsupp.tbl.6
02/14/2008 08:18 PM 25,768,892 supplier.tbl.6
Мы загружены данные из 56 потоков параллельно, соответственно мы создали 56 файлов клиента, 56 файлов элемент линии, и так далее. Данные для каждого из 56 потоков довольно одинаковый размер, и коллективно набор добавляет до 1.18 ТБ источник данных. Позднее мы будем описывать, как файлы были изложены на диске для достижения необходимой производительности. Это обычный текст файлы с полей переменной длины и вертикальной черты ("|") как разделители поле . Например вот первые три строки в файл part.tbl.6 (усечены для удобства чтения):
17857141|ПРОМО ПОЛИРОВАННЫМ NICKEL|17|Бренд # 54|cream Перу...
17857142|БОЛЬШИЕ ЩЕТКОЙ TIN|47|Бренд # 51|violet однообразных …
17857143|СРЕДНИЙ ПОЛИРОВКА BRASS|3|Бренд # 32|orange желтый...
Во время выполнения служб SSIS будет читать файлы в этом формате как первый шаг в подготовке, переводе и загрузку данных.
Настройка базы данных
Во многих отношениях конфигурация SQL Server базу данных использовать настройки по умолчанию или общей конфигурация практики. Мы рассмотрим детали, но две необычные настройки использования программного неоднородного доступа к памяти (программного NUMA) распределять нагрузку поровну между процессорами и использование флага запуска –x для SQL Server. Программная архитектура NUMA будет обсуждаться более подробно ниже. –X параметр отключает коллекция статистики производительности во время выполнения, которые появляются в счетчики производительности и DMV. Существует один особый счетчик, который влияющие на эти усилия, и в последующих построениях была введена исправление для этой проблемы. Данное исправление находится в код выпущенного продукта. Это больше не необходимые для запуска –x для обеспечения производительности, похоже мы достигли.
Группы файлов и таблиц для загрузки
База данных была созд��на на 16 томов данных (логических дисков), а также тома журнала. Все тома были предоставлены EMC SAN. Была создана группа отдельный файл для каждого входящего потока данных, группы файлов, только один файл с файлами данных тома в назначение циклического [ref01]. Вот как база данных была создана.
Создание базы данных по TPCHdestination
PRIMARY
(Имя = N «TPCHdata0»,
Имя файла = N'C:\Mount\Drive1\SQLdata\TPCHdata0.mdf' ,
РАЗМЕР = 1 ГБ, MAXSIZE = НЕОГРАНИЧЕННОЕ, FILEGROWTH = 10%),
ПП1 ФАЙЛОВАЯ ГРУППА
(Имя = N «TPCHdataG1F1»,
Имя файла = N'C:\Mount\Drive1\SQLdata\TPCHdataG1F1.mdf' ,
РАЗМЕР = 24 ГБ, MAXSIZE = 24 ГБ),
ПП2 ФАЙЛОВОЙ ГРУППЫ
(Имя = N «TPCHdataG2F1»,
Имя файла = N'C:\Mount\Drive2\SQLdata\TPCHdataG2F1.mdf' ,
РАЗМЕР = 24 ГБ, MAXSIZE = 24 ГБ),
. . .
LOG ON
(Имя = N «TPCHdata_log»,
Имя файла = N'C:\Mount\Log\SQLlog\TPCHdata_log.ldf' ,
РАЗМЕР = 25 ГБ, MAXSIZE = 25 ГБ)
GO
ИЗМЕНИТЬ простой набор восстановления базы данных TPCHdestination
GO
процедура sp_dboption «tpchdestination», «автоматическое создание статистики», «OFF» ;
go
процедура sp_dboption 'TPCHdestination', 'автоматическое обновление статистики', «OFF» ;
go
Alter database TPCHdestination набор PAGE_VERIFY нет;
go
С создания группы файлов таблиц необходимо загрузить данные были помещены в группы файлов, например,
создание таблица ORDERS_6
(O_ORDERDATE smalldatetime не null,
O_ORDERKEY bigint не null,
O_CUSTKEY int не null,
O_ORDERPRIORITY char(15) не null,
O_SHIPPRIORITY int не null,
O_CLERK char(15) не null,
O_ORDERSTATUS char(1) не null,
O_TOTALPRICE деньги не null,
O_COMMENT varchar(79) не null)
на FG6
Помните, что каждый из этих таблиц на самом деле во временное расположение служб SSIS можно быстро загрузить данные. Он будет затем переключаться в разделы всю таблица.
Таблицы создаются без индексов. Это типично для сред, где большое количество данных загружаются – это часто лучше сначала загрузить данные, а затем добавить индексы. Вот как этот тест был проведен. Мы предполагаем, что добавление индексов является отдельной операцией после загрузки данных. Индексирование не включены в время загрузки.
Секционирование
Данные загружаются в отдельные временные таблицы, потому что это самый быстрый способ загрузки данных. Далее в этом документе мы объясняем, что загрузка в одной куче это почти так же быстро, но проще набор и управлять. Мы ожидаем, что большинство сайтов, найти более простой дизайн достаточно быстро.
После того, как данные загружаются во временные таблицы, они затем переключаются в стать разделов в порционных полные столы. Этот параметр является операцией только над метаданные -данные не нужно быть скопированы или физически перемещены для ее выполнения. Это значительный кусок власти разделов, и этот метод был загрузки практики с SQL Server 2005 Рекомендуемая данных.
Каждый секционированной таблица использует секционирования функция и схемы секционирования [ref02]. Короче говоря раздел функция дает пограничные точки для секций в таблица, и схемы секционирования рассказывает какие каждой секции будет находиться на группу файлов. Во многих реализациях разделы будут разделены вдоль границ времени, такие, как создание нового раздела каждую неделю для новых данных. В этом эксперименте, секционирование потоков, созданных DBGEN был просто первичного ключ каждой таблица. Хотя это не полностью типичной реализации, показать, как секционирование работает. секционированиеметод должен всегда определяться потребности в данных приложения.
Ниже приведены определения функциясекционирования, схемы секционирования и таблица для таблицаOrders. Для таблицаOrders секционирование является O_ORDERKEY, поэтому значения в функция секционирования являются O_ORDERKEY. Обратите внимание, что определение заказы таблица здесь идентичен временной таблица (показано выше), что данные сначала загружаются в. Это требование для того переключить данные в секции.
PfnORDER (bigint) значения для ЛЕВОГО AS диапазона (CREATE PARTITION FUNCTION
107142850,214285700,321428550,428571424,535714274,642857124,
749999974,857142848,964285698,1071428548,1178571398,1285714272,
1392857122,1499999972,1607142822,1714285696,1821428546,1928571396,
2035714246,2142857120,2249999970,2357142820,2464285670,2571428544,
2678571394,2785714244,2892857094,2999999968,3107142818,3214285668,
3321428518,3428571392,3535714242,3642857092,3749999942,3857142816,
3964285666,4071428516,4178571366,4285714240,4392857090,4499999940,
4607142790,4714285664,4821428514,4928571364,5035714214,5142857088,
5249999938,5357142788,5464285638,5571428512,5678571362,5785714212,
5892857062)--максимальный — 6000000000
PscORDER AS раздела pfnORDER TO (CREATE PARTITION SCHEME
ПП1, ПП2, НОМЕР, FG4, FG5, FG6, FG7, FG8, FG9, FG10, FG11, FG12,
FG13, FG14, FG15, FG16, FG17, FG18, FG19, FG20, FG21, FG22, FG23,
FG24, FG25, FG26, FG27, FG28, FG29, FG30, FG31, FG32, FG33, FG34,
FG35, FG36, FG37, FG38, FG39, FG40, FG41, FG42, FG43, FG44, FG45,
FG46, FG47, FG48, FG49, FG50, FG51, FG52, FG53, FG54, FG55, FG56)
GO
создание таблица заказов
(O_ORDERDATE smalldatetime не null,
O_ORDERKEY bigint не null,
O_CUSTKEY int не null,
O_ORDERPRIORITY char(15) не null,
O_SHIPPRIORITY int не null,
O_CLERK char(15) не null,
O_ORDERSTATUS char(1) не null,
O_TOTALPRICE деньги не null,
O_COMMENT varchar(79) не null)
на pscORDER(O_ORDERKEY)
Окончательный требованием для переключения секции является, что должны существовать ограничения на временные таблицы таким образом, чтобы только отборочный данных может быть показано в таблице. Должны быть диапазон проверки на таблицах, поэтому данные не будут нарушать диапазоны для данных в функция секционирования для секционированной таблица. Вот пример ограничение диапазон , на Orders_6 временную таблица. Опять же фактический ключ значения, движет входных данных:
ALTER TABLE ORDERS_6 С проверить добавить ограничение check_ORDERS_6
ПРОВЕРИТЬ (O_ORDERKEY > = 535714275 И O_ORDERKEY < = 642857124)
С таблицы набор как описано, после загрузки данных служб SSIS во временные таблицы, выполнение переключатель так же просто, как это:
ALTER ТАБЛИЦЫ ORDERS_6 ПЕРЕЙТИ В РАЗДЕЛ 6 ПОСТАНОВЛЕНИЯ
Когда все коммутаторы сделали, будет существовать единой таблица заказы с все данные. Этот же процесс применяется для каждого из основных таблиц.
Программная архитектура NUMA и сопоставление портов
Программная архитектура NUMA обеспечивает способ дробление процессоров на сервере на меньшие логические группы. Планировщик SQL Server известно об этих групп, так что работа остается более локализованных, чем в противном случае может потребоваться аппаратное обеспечение системы. После того, как определены логические узлы, сопоставление портов может использоваться для направления работы на некоторых узел, основанный на номер порта, используемый в TCP-соединение. Более подробная информация о программных NUMA- и сопоставление портов, а также обсуждение аппаратной поддержки NUMA, который мы указываем ссылку далее в этом документе, находится в SQL Server электронной документации [ref03].
Для этого упражнения мы использовали программный NUMA и сопоставление портов заставить каждый входящий поток данных (по одному от каждого пакетслужб SSIS) для перехода к другой процессор. Частично это было обойти некоторые особенности в Планировщик SQL Server (который мы надеемся изменятся в будущих выпусках), но мы вероятно использовали бы NUMA и порт картирования в любом случае держать местных сетевого трафика для каждого узла NUMA оборудования на сервере. Детали за это будет описано далее в разделе на настройки сети. Сейчас мы просто скажем, что существуют восемь ядер в каждом узле NUMA оборудования. Мы поручили все сети DPC трафика для каждого узла NUMA одному ядру с этого узла, и мы использовали другие семь ядра для обработки SQL Server . Это постоянно поступающих данных из сети местных с каждым узлом оборудования NUMA. Каждый пакет служб SSIS, подключенный к одному из имеющихся программных NUMA-узлов. Потому что там были восемь оборудования NUMA на сервере и каждый из них семь программных NUMA-узлов, доступных для работы, мы побежали в общей сложности 56 потоков одновременно.
Нам не нужно предпринимать шаги для обеспечения местности дисковых операций ввода-вывода трафика на контроллеры дисков на оборудования NUMA. Это еще один оптимизации, которые могут быть рассмотрены.
Создание программных NUMA-узлов и сопоставления портов осуществляется в системном реестре. Параметры реестра, используемые были [ref04]:
Редактор реестра Windows версии 5.00
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration]
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node0]
«cpumask» = hex: 01
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node1]
«cpumask» = hex: 02
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node2]
«cpumask» = hex: 04
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node4]
«cpumask» = hex: 10
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node3]
«cpumask» = hex: 08
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node5]
«cpumask» = hex: 20
. . .
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node62]
«cpumask» = hex: 00, 00, 00, 00, 00, 00, 00, 40
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\100\NodeConfiguration\Node63]
«cpumask» = hex: 00, 00, 00, 00, 00, 00, 00, 80
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL10.STAB1300_04\
MSSQLSERVER\SuperSocketNetLib\Tcp\IPAll]
«TcpPort «=» 2000 [0x00000001] 2001 [0x00000002], 2002 [0x00000004], 2003 [0x00000008],
2004 [0x00000010], 2005 [0x00000020], 2006 [0x00000040], 2007 [0x00000080], 2008 [0x00000100],
2009 [0x00000200], [0x00000400] 2010 2011 года [0x00000800], 2012 года [0x00001000], 2013 [0x00002000]
2014 года [0x00004000], 2015 [0x00008000], 2016 [0x00010000], 2017 [0x00020000], 2018 [0x00040000],
2019 [0x00080000], 2020 [0x00100000], 2021 [0x00200000], [0x00400000], 2022 2023 [0x00800000],
2024 [0x01000000], 2025 [0x02000000], 2026 [0x04000000], 2027 [0x08000000], 2028 [0x10000000],
2029 [0x20000000], 2030 [0x40000000], 2031 [0x80000000], [0x100000000], 2032 2033 [0x200000000]
2034 [0x400000000], 2035 [0x800000000], 2036 [0x1000000000], 2037 [0x2000000000], 2038 [0x4000000000]
2039 [0x8000000000], 2040 [0x10000000000], [0x20000000000] 2041, 2042 [0x40000000000]
2043 [0x80000000000] [0x100000000000], 2044, 2045 [0x200000000000], 2046 [0x400000000000]
2047 [0x800000000000], [0x1000000000000], 2048 2049 [0x2000000000000], 2050 [0x4000000000000]
2051 [0x8000000000000], 2052 [0x10000000000000], 2053 [0x20000000000000], [0x40000000000000], 2054 2055 [0x80000000000000], 2056 [0x100000000000000], 2057 [0x0200000000000000]
2058 [0x400000000000000], 2059 [0x800000000000000], 2060 [0x1000000000000000]
2061 [0x2000000000000000], [0x4000000000000000], 2062 2063 [0x8000000000000000] "
"TcpDynamicPorts"=""
«displayname» = «Любой IP-адрес»
Другие параметры базы данных и параметры
Мы набор размер сетевого пакета до 32 k вместо того, чтобы по умолчанию 4 k. Это было осуществлено сбоку обе базы данных с использованием параметра Размер сетевого пакета (B) и в пакет служб SSIS как описано в следующем разделе.
Дизайн пакетов служб SSIS
Дизайн раздела обзор и рисунке 3 выше дал обзоруровень высоко - дизайн пакет служб SSIS. пакет выполняется в 56 параллельных экземпляров. Каждый экземпляр пакет загружает один файл клиента в одной таблица, один файл поставщика в один поставщик таблицаи так далее, в последовательности. Последовательность определяется зависимостей задач, набор вверх в потоке управления пакет. Каждая из задач является один поток данных, единственного плоского файла источник и назначениеOLE DB.
Один из важных аспектов потока данных служб SSIS является выбор типов данных для использования. В общем, это хорошая идея для получения типов, преобразуется в конвейере служб SSIS в типы данных, которые будут родной для назначение базы данных. Таким образом данные не нужно снова преобразовать в базе данных. Когда они считываются из текстовых файлов, типы данных задаются в редакторе диспетчера соединений с плоскими файлами. На рисунке 5 показан пример. Он показывает, что столбец O_ORDERKEY, при считывании из файла orders.tbl.n, должен быть преобразован в 8 байтовое целое, которое является одинаковым как bigint в Transact-SQL. Каждый входной столбец может быть сопоставлен надлежащим образом в редакторе диспетчера соединений.
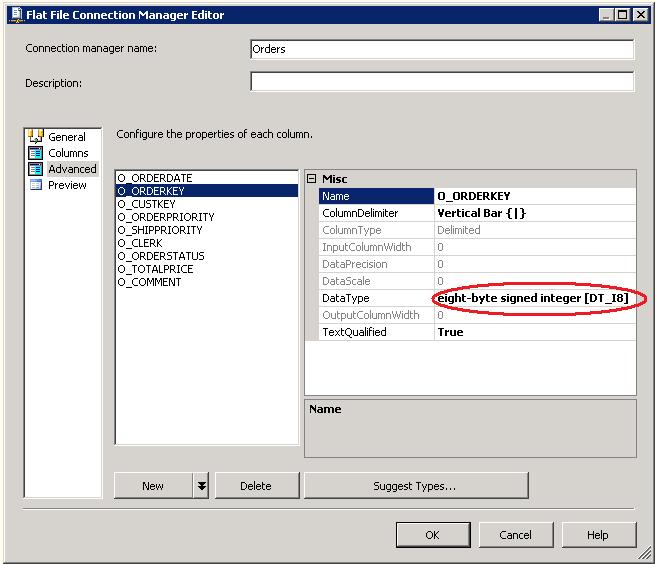
Рисунок 5: Настройка типов данных в редакторе диспетчера соединений
Кроме того, есть опция для ускорения разбора целое, типы даты и времени если преобразование не нужно быть локаль-чувствительных. набор за-столбец используя расширенный редактор для плоского файла источник, как показано на рисунке 6.
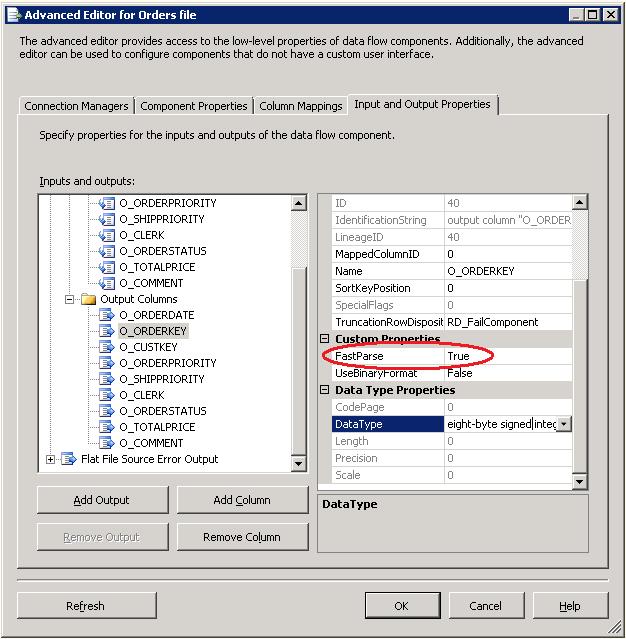
Рисунок 6: Установка FastParse в расширенный редактор
назначение выбран является OLE DB назначение, потому что службы SSIS пакет выполняется на другом сервере чем назначение базы данных. Это было локальной базы данных, мы могли бы получили дальнейшей оптимизации с использованием SQL Server назначение.
Настройка выходов является немного проще, чем входные данные текстового файла, потому что типы данных уже определены конвейера служб SSIS и определениетаблица назначение. Потому что мы позаботились тщательно выбрать типы данных служб SSIS, они будут сопрягать типы данных базы данных. Остается лишь выбрать параметры для назначение. Обратите внимание на рисунке 7, что мы использовали функции быстрой загрузки. У нас теперь есть параметр для вставки таблица блокировка, чтобы отключить проверку ограничений и чтобы набор размер пакет . Хотя мы побежали с размер пакет 100 000 строк для этого проекта, которые могут более чем необходимыми – мы увидели никакого существенного различия для этого данные, набор при запуске с 1 000 или 10 000 строк партий. Мы обнаружили, что это было лучше оставить зафиксировать размер по умолчанию.
Обратите на рисунке 7 получение имя таблица для загрузки во время выполнения из переменной. Это позволяет каждыйэкземпляр пакетдля записи в другую таблица.

Рисунок 7: назначениеOLE DB
С пакет определен она должна вызываться во время выполнения. Это делается с помощью программы командной строки dtexec, как показано ниже. Пробел был добавлен для ясности. Естественно эта Командная строка была создана в цикл, который начал все 56 потоки; Это представляет собой поток 6. Каждый из диспетчеров подключения файлов имеет имя файла, набор, и набор . Этот тип координации также можно было добиться внутри служб SSIS – мы могли бы прошли в одну переменную с номером потока и служб SSIS может определили имена файлов и имена таблица . Это было бы разумным вариантом для многих участков.
DTExec.exe
/ Conn DestinationDB;
«Источник данных = 10.1.1.2, 2006; Первоначальный каталог = TPCHdestination;
Поставщик = SQLNCLI10.1; Встроенная безопасность = SSPI;
Размер_пакета = 32767;AutoTranslate = False; "
/ Конн клиента;"C:\Mount\Source6\TPCH1000GBby56\customer.TBL.6 "
/ Конн LineItem;"C:\Mount\Source6\TPCH1000GBby56\lineitem.TBL.6 "
/ Конн заказов;"C:\Mount\Source6\TPCH1000GBby56\orders.TBL.6 "
/ Конн часть;"C:\Mount\Source6\TPCH1000GBby56\part.TBL.6 "
/ Конн PartSupp;"C:\Mount\Source6\TPCH1000GBby56\partsupp.TBL.6 "
/ Конн поставщика;"C:\Mount\Source6\TPCH1000GBby56\supplier.TBL.6 "
/набор \Package\Customer.Variables[dynCustomerTabName].Значение;CUSTOMER_6
/набор \Package\Supplier.Variables[dynSupplierTabName].Значение;SUPPLIER_6
/набор \Package\Part.Variables[dynPartTabName].Значение;PART_6
/набор \Package\PartSupp.Variables[dynPartSuppTabName].Значение;PARTSUPP_6
/набор \Package\Orders.Variables[dynOrdersTabName].Значение; ORDERS_6
/набор \Package\LineItem.Variables[dynLineItemTabName].Значение;LINEITEM_6
/F «c:\etlwr\ops\src\WRpackages\WRproject\WRproject\SOLEDBstream.dtsx»
Источник данных и Размер_пакета значениями являются двумя другими элементами в команды DTExec. Значение источника данных равно IP адрес и номер порта для программных NUMA-узла, которому этот пакет будет подключиться. В большинстве сайтов источника данных значение будет просто имя компьютера; Иногда она будет сопровождаться именемэкземпляр SQL Server. Здесь мы обходят обычные именования и пошел прямо на IP адрес и номер порта. Значение Размер_пакета было набор до 32 K вместо 4 K сократить количество обращений сети по умолчанию.
Настройка системы
Настройка диска на сервере базы данных
Сервер базы данных был присоединен к SAN с одной стойке диски в зеркальный RAID конфигурация. Таким образом мы создали систему клиента реалистичная хранения, с помощью выполнения текущей общей технологии, включая ES7000 сервера, технологии EMC SAN, подключениями Fibre Channel и стандартных жестких дисков. Сан была настроена раскрыть 16 данных тома и тома журнала, которые были отформатированы с Windows ® и используемый SQL Server.
Для размещения файлов базы данных SQL Server , Unisys поставляется EMC SAN, 6, 4 Гбит/С подключенных EMC CLARiiON CX3-80 с одной стойке (11 лотки на 15 дисков) 146 ГБ диски, спиннинг на 15 k RPM. Сан был настроен для предоставления 17 LUN, каждый из которых сопоставляется обратно 8 дисков, расположенных в 4 x 2 конфигурацияRAID 10. Таким образом, на каждом LUN файлы базы данных являются чередуются на четыре набора пар зеркального диска. Эта конфигурация является отказоустойчивым и оставляет один горячего резерва в лоток. На размер полоса 64 k, через четыре пары зеркального диска LUN должен обрабатывать красиво пишет 256 k. Лаборатории тестирования и подтвердил максимальная записи скорости ввода/вывода размер 256 k каждой операции записи.
Каждый LUN был отформатирован как логического тома и возложенные на точку подключения Windows NTFS файловой системе сервера. Эта задача могла бы быть выполнена в оснастке «Управление дисками консоли управления Windows Server ® 2008»; Мы использовали DISKPART для удобства в сценарии задачи конфигурация . Обратите внимание, что в Windows Server 2003 можно использовать DISKPART чтобы набор правильный раздел выравнивание на диске, указав смещение раздела; Windows Server 2008 выполняет это автоматически.
Тестирование с sqlio.exe средство подтвердил скорость записи чуть более 800 МБ/с (параллельные потоки записи 256 КБ буферов для всех LUN).
16 Данных, томами, упомянутыми в разделе Настройка базы данных были сопоставлены с точки первых 16 подключения. 17 Объем был использован для файла жу��нала базы данных SQL Server . В ходе испытания Мы измерили запись в среднем количество 608 МБ/сек с вершиной 872 МБ/сек с SQL Server , как показано на рисунке 8. Обратите внимание, как изменяется скорость серверов служб SSIS загрузить различные таблицы TPC-H в разное время на выполнение.
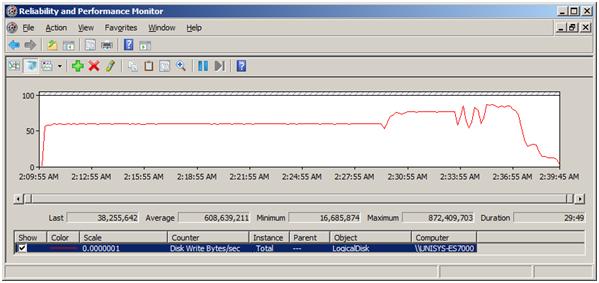
Рисунок 8: скорость записи сервера базы данных во время выполнения теста
Все файлы данных и журналов были precreated ликвидировать рост файла во время процесса ETL. SQL Server Быстрая инициализация файлов [ref05] была настроена для создания файлов базы данных; время, чтобы набор копию базы данных был по существу раз до нуля файла журнала. Мы нашли 50 GB журнал файла достаточно, и скорее всего он мог бы быть хороший немного меньше.
NUMA на сервере базы данных
ES7000 представляет собой неоднородной памяти (NUMA) доступ к архитектуры машину. Мы смотрели на два варианта памяти NUMA: полностью с чередованием и штабелироваться ячейка пара. Мы использовали четыре пары в общей сложности.
ES7000 был настроен как единый 32 сокет сервера из восьми узлов четыре процессора, в одной стойке. Каждый узел была в паре с одного соседа через жесткую выполеннными боковой панели, которая является электрическим увязывать его близнеца системной шины каждой машины связи. Такой пары узлов включает супер ячейка, и в данном вариант, поочередно для создания системы сингл памяти местных супер ячейкапамяти из каждого узла. Четыре супер клетки были связаны через сеть кабели внешних так называемых перекладину. В этой конфигурация мы имели возможность "наложения" памяти, где остается местные последствия NUMA и супер ячейка памяти в Супер ячейка имеет развернутое, или чередование памяти всех супер ячейках. Мы надеемся, этот последний подход к сокращению плюсы и минусы NUMA дизайн машины.
Другие конфигурации памяти могут быть физически возможно но не проверялись.
Мы протестировали против двух памяти конфигураций, описанных выше. Тест был немного лучше в полностью с чередованием конфигурация. Наши работы предполагается, что разница в производительности был результатом плохой населенный пункт сети получают буферы с карты сетевого интерфейс . Другими словами, памяти конфигурация , развернуто NUMA эффекты не выполняют как памяти конфигурация , свести их к минимуму. Это может означать наличие проблемы с сетью получить буфер размещения в пространстве памяти узла, содержащего физически сетевого адаптера, с помощью каждого буфера. Можно также указать, что сети получают буфера отсутствует. Это может быть области для дальнейших исследований; Мы не преследуем он потому что разница в производительности является небольшим и могут варьироваться на сервере новее с обновленную поддержку ACPI. Информация о стандартных ACPI, доступных онлайн [ref06].
Разница в производительности теста при сравнении двух конфигураций памяти NUMA можно наблюдать в среднем писать скорость на SQL Server (Обратите внимание, является для среднего через экземпляр счетчики физического диска), где в обоих случаях тест ЦП на сервере. По итогам тестирования мы наблюдали учетом 38.6 MB/sec с накоплением памяти и ставок 39,7 МБ/сек с использование чередующейся памяти, различие в 2,9%, в соответствии с наблюдаемые различия в тест задержка 2,6%.
Диск установки на серверах служб SSIS
конфигурация диска на серверах служб SSIS был простым и упрощенные. Мы использовали четырех серверов класса сырьевого источник данных ETL и выполнять пакеты служб SSIS и двумя массивами хранения для физически удержания 1.18 ТБ данных источник плоского файла. Таким образом мы моделировать сценарии, в котором несколько источников данных, или ETL "источник" серверов, записывать на склад целевой одновременно. Данные, обрабатываемые каждый сервер служб SSIS уникальна; Существует не реплицируемые или общего источник данных.
Четыре Unisys ES3220Ls (с двумя разъемами, четырехъядерные) были подключены к двум EMC CLARiiON CX600s с два, 2Gbit ФК соединения от каждого сервера к CX600. Каждый CX600 провел 45 шпиндели для в общей сложности 90 шпиндели, обслуживающих плоский файл источник данных.
Каждый из четырех серверов служб SSIS поехали семь потоков данных от каждого из двух источник томов, для в общей сложности 56 параллельных потоков данных обрабатываются и отправляются на сервер баз данных во время процесса ETL. Каждый источник тома проходил н�� LUN, подвергается источник сервера. Каждый LUN был отформатирован и возложенные на точку подключения Windows NTFS файловой системе сервера, с помощью служебной программы DISKPART. Эта конфигурация поставляется необходимой чтения ставки 164 МБ/с для чтения 1.18 ТБ данных плоского файла в 1800 секунд.
Это было бы возможно, но не является необходимым настроить Сан подвергать большее количество LUN, меньшее количество шпинделей, оптимизировать для последовательного чтения. В нашем тестирования конфигурация каждого источник сервера pulled семь потоков плоского файла данных от каждого из двух LUN.
TPC-H источник данные файлы были созданы с утилитой DBGEN из базового набора. Мы изначально используется параллельный процесс для записи большинство из источник файлов, параллельно. Эта стратегия, создали чрезвычайно высоким (нереально так) уровнях фрагментации в файловой системе. Создавая данные в запасных хранения перед перемещением их на источник томов, мы поняли небольшом выигрыше чтения задержка.
Другие параметры
Несколько корректировки были внесены в параметры системы в достижении цели 30-минутный 1.18 ТБ ETL загрузки с SQL Server и служб Integration Services.
На сервере базы данных, мы включили доступные параметры производительности кэша процессора: аппаратные реестрам и прилегающие кэш линии prefetch [ref07].
Реестрам кэша оборудования представляет собой систему, в которой контроллер памяти процессора определяет шаблон последовательного доступа к памяти и когда такая закономерность предсказывает следующий кусок памяти, который будет запрашиваться и помещает его в кэш. Если предсказание Контролера является правильным, доступ к памяти становятся значительно быстрее для остальной части гласит в последовательности, потому что процессор не нужно ждать медленно поездка в основной памяти и обратно (или даже хуже, с удаленным узлом NUMA).
Прилегающие кэш линии prefetch просто означает, что контроллер памяти хватает вдвое больше памяти на один раз, или две строки кэша, вместо обычных одну строку. В нынешних систем строки кэша (или строка кэша) часто является 64 или 128 байт. Размер строки кэша является атрибут неизменности аппаратных средств.
Как отмечалось ранее, мы позволили полностью чередованием режим для доступа к памяти. Что касается программного обеспечения мы позволили большие кодовых страниц для образа программы SQL Server [ref08], [ref09]; Пожалуйста, обратите внимание, что данное требование не распространяется даже на 64-разрядной версия Windows, и ее следует включать только в производстве когда рекомендуемые корпорацией Майкрософт на основе конкретного вариант .
На источник сервер мы дали процесс служб SSIS (DTEXEC) небольшой толчок в класс приоритета. В аналогичные испытания, мы наблюдаем, что такой импульс выравнивает из скорость обработки потоков данных, что уменьшает общее время обработки путем уменьшения разброса данных поток обработки задержка. Потому что задержка тест определяется как время начала обработки до завершения последнего поток, уменьшение разброса отдельных потока задержки уменьшает тест задержка. Другими словами сокращается время ожидания для окончательного потоков для завершения. Этот эффект наблюдался только когда сервер служб SSIS был связан с Процессором.
Детали сети
Выбор операционной системы
В начале этого проекта мы обсуждали различные выбор архитектуры системы. В отличие от Windows Server 2008 R2 Windows Server 2008 ограничена 64 логических процессоров, и некоторые раннем эксперименты предложил мы не смогли достижения наших целей, если мы себя к использованию все на одной системе. Потому что это был наш первый раз работает основной рабочей нагрузки ориентир ETL, мы сделали крупные выбор на раннем этапе, который благоприятствования управляемость и гибкость масштабного более простота использования. Скорее всего мы продолжим другой подход (простой) следующий раз.
Возможность горизонтальное масштабирование передней части системы означает запуск служб SSIS на разных серверах, чем системы, которая будет принимать реляционной базы данных, поэтому мы взяли на раннем этапе для загрузки по сети. Так как Windows Server 2008 будет начато в то же время как SQL Server 2008, и в новой операционной системе включены все новые, более современные стека TCP/IP, мы сочли этот выбор также даст нам возможность удар шины сети следующего поколения новой операционной системы.
Выбор сетевого интерфейса карты (NIC)
Модель сервера Unisys ES7000, мы использовали был пожилые зрелые кэш последовательной NUMA машине [ref10], с заменены новой модели с быстрее радиотелефонным интерфейсом памяти, Unisys. Мы быстро отверг идею с помощью NIC совместную работу, из страха не в состоянии NUMA размещения элементов управления, если мы хит chokepoints на сервере соединения. Этой старой системы сервера не имеют диапазон квалифицированных NIC в новых машин в сегодня, так что мы руководили clear использования 10 сетевые платы Gigabit Ethernet для этого сначала перейдите на установление новый мировой рекорд ETL.
Сетевые интерфейсные платы на сервере Unisys были встроенные контроллеры Intel PRO/1000 MT LAN-на платы (ЛОМ). Мы использовали, что было затем последнюю публично доступные версия драйвера Intel для данного контроллера Ethernet. На стороне клиент мы использовали сетевых адаптеров Intel ® PRO/1000 PT. Это работает очень хорошо, как с точки зрения производительности и стабильности надежны.
Параллелизм в топологии сети
Мы поселились на использование четырех серверов переднего плана многоядерных "клиент", для запуска служб SSIS. Эти системы будут читать данные плоского файла от RAID поддерживаемых файловых систем, необходимые тип преобразования и затем загружать эти данные по сети в SQL Server на 64 P ES7000. Сетевая архитектура, мы выбрали для подключения клиентов и сервера было использовать выделенный 1 GbE ссылку для каждого узла Unisys NUMA, восемь 1 GbE ссылки в общей сложности. Чтобы иметь возможность отслеживать и управлять вещи плотно, мы создали четкое соответствие между физических соединений Ethernet и слой 3 IP-адреса на каждом конце, как это.
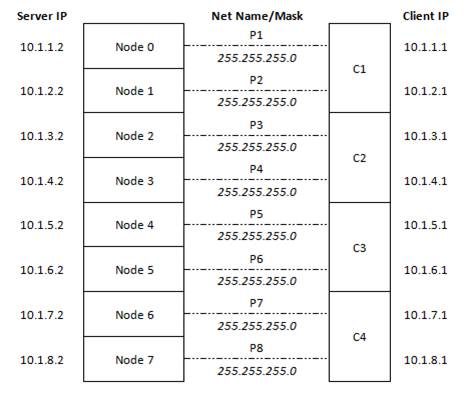
Рисунок 9: логическая схема сетевая архитектура
Gigabit Ethernet ссылка подключения каждого из модулей сервера ccNUMA Unisys ES7000 с одним из четырех клиентов, поэтому каждый клиент имел два выделенных 1 Гбит/с соединения с сервером. Этот механизм облегчает производительности следственной работы и не обязательно является то, что мы предложив для развертывания серийного производства.
Расширение параллелизма в стек с IntPolicy
Мы решили расширить наши параллельной, секционированные сетевой архитектуры вверх в сервера базы данных, с помощью свободно доступных Microsoft средство, называемый IntPolicy, для привязки NIC прерывания и DPC [ref11] к конкретным процессоров на сервере. Мы хотели бы иметь возможность четко соблюдать ЦП из сети прерываний/DPC, чтобы иметь возможность вносить коррективы в ходе нашей работы. IntPolicy доступен в центре загрузки Microsoft в [ref12], и он работает на Windows Server 2008 и Windows Server 2008 R2.
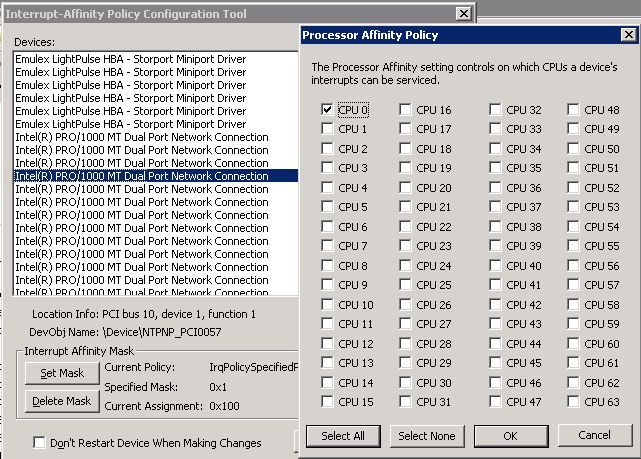
Рисунок 10: установка сродства процессора, с помощью IntPolicy
Эта структурированная конфигурация было полезным для управления NUMA местности, но также позволило нам легко Карта производительности вопросы конец в конец через нашу архитектуру клиентКлиент/Server.
Единственный drawback к с помощью IntPolicy, что это немного боль для настройки. Вам нужно разобраться сопоставление между физический интерфейс, имя устройства сетевого подключения и объект физического устройства (устройствфункция # s), чтобы иметь возможность выяснить, какие NIC прерываний/DPC должен приземлиться на желаемый процессора. Это не для faint сердца или нормальные люди, но это не ракетостроение либо. С помощью команды ipconfig/all, devmgmt.msc и IntPolicy, это полезно для создания таблица , как это держать прямо сопоставления.
Интерфейс |
Margate IP |
Узел |
Порт л/П |
NetConn имя устройства |
Шина PCI |
Устройства PCI |
PCI Func |
Новый диапазон процессора |
Новый DPC процессора |
P1 |
10.1.1.2 |
0 |
R |
#4 |
10 |
1 |
1 |
0-7 |
0 |
P2 |
10.1.2.2 |
1 |
R |
#12 |
67 |
1 |
1 |
8-15 |
8 |
P3 |
10.1.3.2 |
2 |
R |
#16 |
95 |
1 |
1 |
16-23 |
16 |
P4 |
10.1.4.2 |
3 |
R |
#10 |
123 |
1 |
1 |
24-31 |
24 |
P5 |
10.1.5.2 |
4 |
R |
#2 |
151 |
1 |
1 |
32-39 |
32 |
P6 |
10.1.6.2 |
5 |
R |
#14 |
179 |
1 |
1 |
40-47 |
40 |
P7 |
10.1.7.2 |
6 |
R |
#8 |
207 |
1 |
1 |
48-55 |
48 |
P8 |
10.1.8.2 |
7 |
R |
#6 |
235 |
1 |
1 |
56-63 |
56 |
Таблица 1: Пример отслеживания сопоставление между физических сетевых интерфейсов и ES7000 процессора, который будет получать сетевые прерываний/DPC
Первоначальные настройки сетевой конфигурации с NTttcp
После того, как мы все это фиксированных вверх и настроен, мы решили Предполётная эксперименты ETL путем проверки эффективности сети, с помощью внутреннего средство под названием NTttcp [ref13]. Основываясь на те же концепции, введены в оригинальные ttcp Майк Muuss средство [ref14], NTttcp предоставляет некоторые дополнительные возможности управления возможности, воспользоваться преимуществами функций ядра Windows. Мы привыкли Предполётная основные характеристики нашей сети до начала запуска ETLWR рабочей нагрузки с помощью служб SSIS и SQL ServerNTttcp.
Один поток эксперимент с NTttcp показал некоторые значения в работает с L2 большие кадры (9014-байтовый Ethernet-фреймов), так что мы набор через драйвер Intel дополнительные параметры конфигурация . Хотя мы в конечном итоге получат мировой рекорд таким образом, позднее сетевых открытий показал нам, мы вероятно может иметь застряли со стандартной по умолчанию (1500 байт). Чтобы сохранить производительность осложнений до минимума, мы отключили NetBT (поддержки NETBIOS) и брандмауэр Windows на частных базовых сетевых интерфейсов.
В управлении NTttcp, мы обычно используются параметры –v, –a, –fr и заставок на получающей стороне, чтобы: (1) подробный вывод, (2) асинхронных разъема ввода/вывода количество ожидающих запросов, (3) полный буфер (не частичного) ��олучает, и (4) для указания число потоков и на какие процессоры этих потоков следует выполнять запросы ttcp. К примеру:
ntttcpr.exe - v - 6 -fr -м 2,1,10.1.1.2 2,9,10.1.2.2 2,17,10.1.3.2 2,26,10.1.4.2\
2,33,10.1.5.2 2,40,10.1.6.2 2,48,10.1.7.2 2,56,10.1.8.2
устанавливает два получить потоков процессора, на ЦП 1, 9, 17, 26, 33, 40, 48 и 56 и позволяет до шести выдающихся асинхронных запросов ввода-вывода каждого поток. И на стороне отправки, мы использовали внедрить аналогичные варианты, но очевидно может пропустить полное получает:
ntttcps.exe - v 6 - м 2,1,10.1.1.2 2,5,10.1.2.2 2,9,10.1.3.2 2,13,10.1.4.2
Не раз мы были запущены темпами строка с один поток, поэтому следующий шаг заключается в том, чтобы запустить восемь потоков в параллельных, один для каждого порта GbE NIC-пары между системами. Прямо сейчас мы попали проблему. Мы могли бы работать с двумя потоками и получить строки, но как только мы добавили третий, другие потоки будет нанесен ущерб, до более низкой ставке пропускную способность. Как мы просверленные в этот вопрос, мы нашли достаточно запутано, касающийся набор вопросов, участвующих в версия ACPI, который старше сервер поддерживается, как NDIS выделяет NIC получения буферов и NUMA ткань поведение. В конце концов мы вырежьте этот гордиев узел вся память чередование на ES7000 и путем изменения двух параметров BIOS, влияющие предварительную загрузку кэша (thanks to Unisys Боб Мерфи). В BIOS мы набор оборудования реестрам отключить = No и прилегающих кэш линии Prefetch отключить = №
С этими изменениями восемь потоков NTttcp (толщиной 16 потоков на стороне приема), смогли выдерживать около 118 МБИТ/с на 1 GbE потока, когда параллельно все, который составляет почти полная линия.
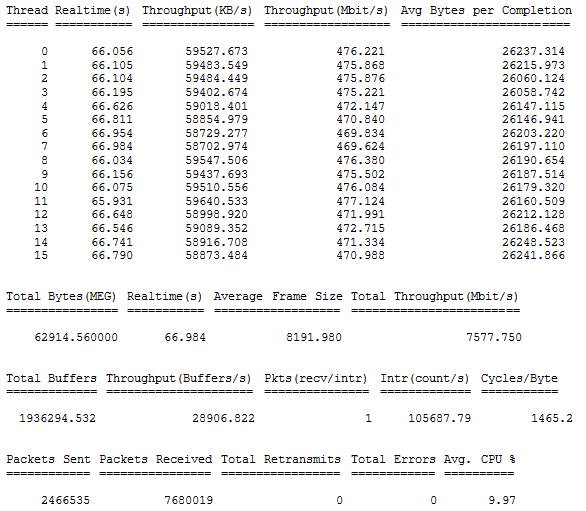
Рисунок 11: образец вывода из восьми поток запуска из NTttcp
Этот NTttcp ЦП означало, что мы потребляющих примерно шесть из восьми процессоров, мы посвятили для обработки сетевого трафика, который не плох на всех Учитывая возраст контроллеры Intel PRO/1000 MT ЛОМ на сервере Unisys.
Открытия сети под управлением рабочей нагрузки
С нижнего уровень сети конфигурация на месте мы были готовы к показу уменьшенной версии рабочей нагрузки ETLWR полное применение. Мы разработали сценарий автоматизации и пакеты служб SSIS, которые могут быть запущены в полном масштабе, ingesting 1 ТБ источник данных и другой версия , который работал с 10% от полной источник данных. С этих точек масштаба и помощью средство под названием TCP анализатор мы смогли выявить и устранить последние препятствия на пути к под-30-минутный запуска.
Когда мы начали экспериментальной работает с 10% данных набор, мы наблюдали 56 ЦП, выделенных SQL Server для обработки строк полностью удерживались. Перенести часть Процессорного времени вдали от обработки пакетов TDS накладные расходы и в строку обработки, мы увеличили размер пакетов TDS от установленного по умолчанию 4 k максимальное значение 32 k уменьшая количество пакетов, обмен между клиент и сервером. Это Улучшенная производительнос��ь (то есть, снижение нагрузки время) на 25%.
На этот раз мы наблюдали большие различия в пропускной способности сети во время выполнения теста. Мы использовали служб SSIS пакет загрузки таблицы, используя поток выполняющееся данных в пределах пакет. Чтобы получить ясность на источник колебаний, мы перешли на запуск служб SSIS пакет загрузки таблицы серийно, который в свою очередь помогает нам понять различные характеристики во время выполнения обработки каждой из различных таблиц TPC-H. Для экземпляр, во время обработки одного из большой, широкий таблиц, таких как LineItem, сетевой трафик через интерфейсы снизится как сервере ЦП стал перегружены на обработке больших строк. Узкий таблиц, как приказы, позволило бы служб SSIS для привода всех восьми сетевых интерфейсов темпами строка.
Распутывания служб SSIS пакеты помогли нам понять сетевых потребностей и поведение обработки каждой таблица, но мы до сих пор видел gyrations пока служб SSIS работал для каждой таблица. На данный момент мы решили вывести новый Windows SDK средство, называемый TCP анализатор, чтобы выяснить, что происходит. Это приложение, которое был написан основной сетевой группы Windows, позволяет включить поддержку нового стека протокола TCP/IP для IETF TCP продлен статистики (ESTATS) MIB, чтобы увидеть в реальном времени то, что происходит с конкретного потока TCP. Мы эксперименты с изменением числа буферов L2 NIC, выделенных для каждого адаптер, но один взгляд на TCP анализатор показали, что мы Лай вверх неправильно дерево (thanks to Мурари Раджу Sridharan TCP анализатор советы).

Рисунок 12: анализатор TCP - использование по умолчанию TCP получает автоматической настройке окно
Этот анализатор TCP скриншот, принятые в ходе его экземпляр 10% ETLWR перспективе, показывает, что происходит за один поток TCP, между служб SSIS на отправителя (где TCP анализатор лучше всего работать) и SQL Server получателя. Глядя на пропускную способность истории реберный граф вы можете увидеть gyrations пропускной способности. Реальный откровением смотреть этот работать в режиме реального времени и видеть сколько времени этот поток TCP в спасении от перегрузки. К счастью анализатор TCP поддерживает также связи жизни круговая диаграмма, нарушающим это вниз, так что вы можете видеть, что значительное количество времени, в течение этого 10% ETLWR запустить провели ждет TCP путь стать загруженности!
Мы взяло на себя что не TCP -уровень вопросы, и мы эксперименты с выделения меньше или больше числа буферов, L2 сетевого адаптера. Мы явно Лай вверх по дереву, неправильно, как набор экспериментов показали. В самом деле давая драйвера сетевого адаптера более L2 отправить буферов, хотя они используются по умолчанию TCP автоматической настройки алгоритма, на самом деле сделал производительность хуже, потому что отправитель может еще более легко overwhelm SQL Server приемник, который сегодня имеет некоторые ограничения вокруг количество выдающихся принимать запросы, он держит в полете. Новый сетевой стек поддерживает три уровня Автонастройка TCP: по умолчанию, инвалидов (не авто настройки TCP получения окно) и ограниченные ( окноприема TCP какие авто мелодии но меньше агрессивно параметр по умолчанию).
Работает несколько экспериментов было интересно, не только за результаты пропускной способности и run-time мы получили, но и для стабильности перемещения данных. Просто коммутации, TCP-автонастройки ограничены, мы смогли получить 10% увеличение производительности. Изменение числа NIC Автонастройка буферы сделал небольшое различие, но это изменение в рамках нашей run запуск вариации, вероятно, не очень значительной. В таблице 2 приведены результаты сравнения производительности ETLWR с изменения TCP получить параметр автоматической настройки окно и количество буферов передачи сетевой адаптер настроен на Gigabit Ethernet адаптер.
Run тип |
Ник # TxBufs |
TCP Rx АВТОТЮНИНГ |
Во время выполнения (сек.) |
Дельта времени выполнения |
Комментарии |
56 10% Данных потоков |
512 |
Нормальный |
233 |
— |
Базовые |
56 10% Данных потоков |
128 |
Нормальный |
215 |
7.7% |
Уменьшить количество буферов сетевой адаптер |
56 10% Данных потоков |
128 |
Инвалидов |
231 |
0.9% |
Отключение автоматической настройки TCP Rx |
56 10% Данных потоков |
128 |
Ограничен |
208 |
10.7% |
Попробуйте ограниченных TCP автонастройки |
56 10% Данных потоков |
256 |
Ограничен |
207 |
11.2% |
Увеличить количество буферов сетевой адаптер |
Таблица 2: автоматической настройке окно получения эффекта TCP и количество NIC передавать буферов на производительность ETLWR
Перед запуском каждый эксперимент, мы просто использовали встроенные средство netsh для изменения TCP получить автонастройки, как это:
Netsh int tcp набор глобальные autotuninglevel = ограничено
Еще больший выигрыш был в улучшении пропускной способности сети стабильность, с ограниченным TCP автонастройки. Еще один TCP анализатор скриншот рассказывает всю историю.
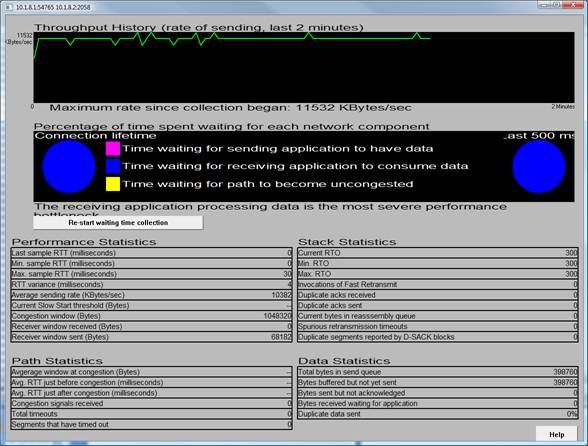
Рисунок 13: авто настройке окно получения TCP анализатор - с использованием «ограниченного использования» TCP
Вы можете увидеть, что средний поток отправки ставка выше, но что более важно, не времени тратится на ожидание на отправителя или не дожидаясь путь стать загруженности, и потока пропускная способность — это исключительно стабильной. На данный момент мы были приемник, связаны, которая является то, что мы ожидали. Следует отметить, что поведение автоматической настройки по умолчанию TCP/IP можно улучшить в более поздних версиях Windows, так что будьте осторожны, если слишком много.
Как мы получили короткие штрихи для этих усилий, TCP анализатор пришел в удобно еще один раз, хотя коренной причиной проблемы было не совсем сетевые проблемы. После того, как преодолеть проблему Автонастройка TCP, мы собрались быстро яркие расстоянии от нашей цели, но она по-прежнему танцевал только из достичь, потому что некоторые ЦП на сервере базы данных выставлены «длинный хвост» в конце выполнения. (Длинный хвост является большое количество уникальных элементов, каждый в относительно небольших количествах). Мы посвятили некоторые процессоры сетей во избежание именно этот вид результата, и тем не менее здесь было. Мы изучили системного монитора и статистики SQL Server на сервере базы данных, но могут не понять.
Затем один вечер (или ранним утром, более вероятно), мы думали, для подключения TCP анализатор для сетевого потока, связанные с одной из процессоров длинный хвост. Длинные хвосты произошло последовательно, и не случайно, так что это было легко сделать (и также немного тусклый, сама по себе). Еще раз TCP анализатор показал нам, что мы искали в неправильном месте.
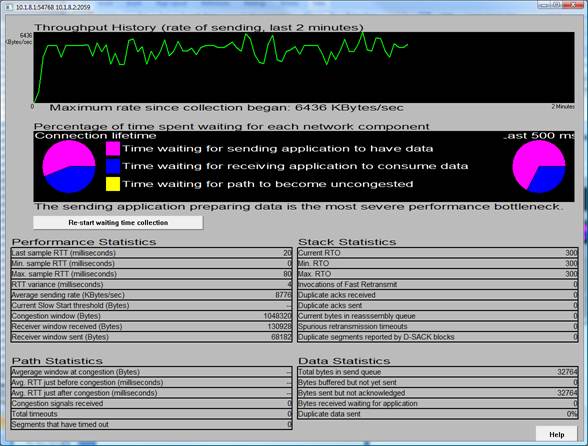
Рисунок 14: анализатор TCP - длинный хвост служб SSIS потоков были привязкой отправителя
Вы можете увидеть что сетевой поток, связанный с потоком служб SSIS длинный хвост, отправитель limited, не привязанные к получателю. Как только мы перешли наше внимание к клиентам, мы заметили небольшое, но значимое аномалия в дисковой подсистемы одной из клиент машин, которые были вызваны разрозненных источник файловой системы. Решение этой проблемы, мы получили через линию финиша!
Сведения О конфигурации
Сервер базы данных
Производитель: Unisys
Модель: ES7000/один сервер предприятия
ОПЕРАЦИОННАЯ СИСТЕМА: Windows Server 2008 x 64 Datacenter
ПРОЦЕССОР: 32 разъема dual core Intel ® Xeon 3.4 ГГц (7140M)
ОЗУ: 256 ГБ
HBA: Двойной 8 портов 4Gbit FC
База данных: Предварительная сборка SQL Server 2008 Enterprise (V10.0.1300.4)
Хранение. EMC Clariion CX3-80 (Кол-во 1)
11 лотков 15 дисков; 165 шпиндели x 146 Гбайт 15Krpm; ФК 4Gbit
Серверы служб SSIS
Количество: 4
Производитель: Unisys
Модель: ES3220L
ОПЕРАЦИОННАЯ СИСТЕМА: Windows 2008 x64 Корпоративная
ПРОЦЕССОР: 2 разъем четырехъядерными процессорами Intel Xeon @ 2,0 ГГц
ОЗУ: 4 ГБ
HBA: 1 двойной порта Emulex ФК 4Gbit
СЕТЕВОЙ АДАПТЕР: Двухпортовый Intel PRO1000/PT
База данных: Предварительной сборки служб интеграции SQL Server 2008 (V10.0.1300.4)
Хранение. 2 x EMC CLARiiON CX600 (ea: 45 шпиндели, 4 2 Гбит ФК)
Заключение
Установка ETL мировой рекорд является одновременно очень важных и неважных. Это важно, потому что это ясно показывает, что служб SSIS входит в число мировых лидеров в области производительности ETL. Делая это, мы продемонстрировали методы, которые могут быть применены для достижения выдающихся служебных заслуг. Эти методы могут применяться клиентами сегодня. Мы также узнали вещи, которые могут быть использованы для создания лучшего продукта. Некоторые из этих вещей были выполнены; Некоторые будут выпускаться в следующих выпусках.
ETL мировой рекорд, как любой ориентир, неважно, если Рабочая нагрузка не имеет некоторое сходство с вас как клиента нужно. ETL охватывает широкий спектр операций, многие из которых не были включены в этом ориентир. В то время как мы следили за пример, в котором было набор на рынке, мы также ожидаем стандартных критериев, которые лучше представляют потребности клиентов. Microsoft вместе с другими лидерами отрасли в транзакций обработки производительности Совета (ТУК) для разработки стандартного базового ETL. В то же время мы хотели бы вновь подтвердить, что методы, описанные здесь являются полезными во многих ситуациях. Мы продемонстрировали, что служб SSIS может работать как лошадь расы.
Благодарности
Авторы хотели бы поблагодарить наших партнеров на Unisys за их помощь и советы, особенно Хенк ван дер Валк, который провел много дней и ночей в лаборатории, работая с нами, чтобы усовершенствовать систему.
Авторы также хочу поблагодарить:
- Intel, для кредитования PRO/1000 PT сетевых интерфейс .
- Ахмед Талат, для консультации по NTttcp и IntPolicy.
- Боб Мерфи, Unisys, за его идеи на параметры конфигурация кэша BIOS.
- Мурари Раджу Sridharan, анализатор TCP советы.
Для получения дополнительной информации:
http://www.Microsoft.com/SQLServer/: SQL Server веб-сайт
http://TechNet.Microsoft.com/en-US/SQLServer/: SQL Server TechCenter
http://MSDN.Microsoft.com/en-US/SQLServer/: SQL Server DevCenter
Ссылки
[ref01] Этот формат может быть более чем необходимы. В более поздних работает мы повторили результат с тома данных 8 и 16 групп файлов.
[ref02] Чтобы узнать осекционирование таблицав SQL Server 2008, см. http://msdn.microsoft.com/en-us/library/ms188706.aspx
[ref03] SQL Server 2008 электронной документации. Понимание неоднородного доступа К памяти. http://msdn.microsoft.com/en-us/library/ms178144.aspx
[ref04] Отметить, что эти записи реестра создания узлов на всех 64 ядрах и назначить номер порта для каждой, хотя восемь из ядер зарезервированы для сети DPC обработки. Мы могли бы оставить эти ядра, unmapped в порты; Мы просто решили управлять выбором процессоров, используемых для SQL Server обработки из пакетов служб SSIS, вместо того, чтобы соблюдение на сервере базы данных.
[ref05] SQL Server 2008 электронной документации. Базы данных файла инициализации. http://msdn.microsoft.com/en-us/library/ms175935.aspx
[ref06] Корпорации Intel. Дополнительные конфигурации & Интерфейс питания (ACPI). http://developer.intel.com/technology/iapc/acpi
[ref07] Корпорации Intel. Улучшение производительности приложений на микроархитектуры Intel ® Core ™ с использованием аппаратных реализовано Prefetchers. http://Software.Intel.com/en-US/articles/optimizing-Application-Performance-on-Intel-coret-Microarchitecture-using-Hardware-implemented-prefetchers/
[ref08] MSDN ®. Включение поддержки памяти для более чем 4 ГБ физической памяти. http://msdn.microsoft.com/en-us/library/ms190730.aspx
[ref09] MSDN. Как: включить параметр Блокировка страниц в памяти (для Windows). http://msdn.microsoft.com/en-us/library/aa366720.aspx
[ref10] Технически сокращенное ccNUMA, но cc префикс часто не используется, и это то, что люди обычно значу NUMA.
[ref11] Отложенные вызовы процедур (DPC) — это метод используется семейство серверных операционных систем Windows для обработки сетевого трафика, за пределами критического аппаратного прерывания, обработка окно.
[ref12] Центр разработчиков оборудования Windows. Инструмент политики прерываний схожести. http://www.microsoft.com/whdc/system/sysperf/intpolicy.mspx
[ref13] Центр разработчиков оборудования Windows. Как использовать NTttcp для тестирования сети производительности. http://www.microsoft.com/whdc/device/network/TCP_tool.mspx
[ref14] Майкл Джон Muuss. История программы TTCP. http://ftp.arl.mil/~mike/ttcp.html