Создаем географически распределенный (multi-site) отказоустойчивый кластер Windows Server 2012
Недавно в своей практике столкнулся с вопросом – как построить геораспределенный (в оригинальной терминологии "multi-site") отказоустойчивый кластер на Windows Server 2012? Поскольку информации по данной теме очень мало, пришлось решать проблему своими силами, что и привело меня к написанию данной статьи.
Для сценария с геораспределенным отказоустойчивым кластером специфична проблема: как обеспечить быстрый и надежный доступ к хранилищу, на котором будут храниться данные кластеризованного приложения, если узлы располагаются в разных географических локациях. Для решения этой задачи резонно в каждом сайте разместить локализованную копию хранилища и тут же возникает вопрос, как реализовать согласованность данных между этими копиями.
Поскольку кластер не поддерживает репликацию хранилища между сайтами собственными средствами, то задача по обеспечению согласованности таковых возлагается на СХД решение.
Общая схема моего экспериментального стенда имеет следующий вид:
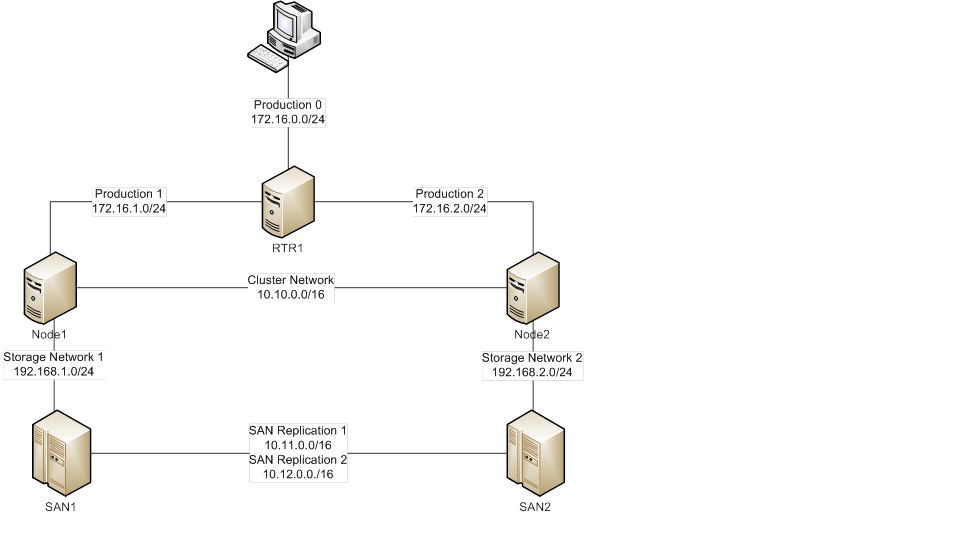
Продукционная сеть Production(состоящая для наглядности из трех подсетей), из которой мы «увидим» кластеризованный сервис и сможем проверить «обход сбоя».
Кластерная сеть и сети для репликации хранилища (в реальной среде WAN) – Cluster и SANReplication, соответственно.
Сеть хранилища для каждого сайта – Storage Network1 и .Storage Network2.
В своем примере для организации хранилища я использовал iSCSI SAN от StarWind, который поддерживает репликацию хранилища. Пробную версию продукта можно получить с сайта www.starwindsoftware.com.
В консоли управления StarWind в левой части через контекстное меню “StarWind Servers” создадим серверную группу “SANRepl1” и добавим к ней серверы-партнеры через пункт меню “Add StarWind Server” , указав адрес каждого сервера. Подключаемся к каждому (правый щелчок – “Connect”).
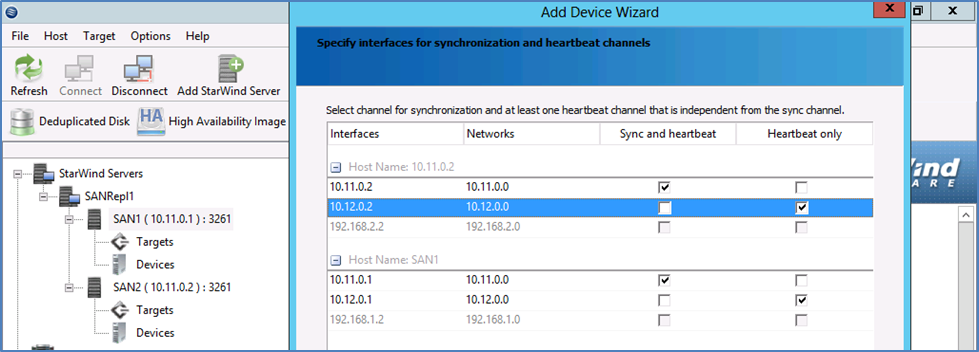
Создаем, как показано ниже, высокодоступное устройство, указав хосты, между которыми оно будет реплицироваться.

Задаем путь расположения и название виртуальному диску на каждой реплике хранилища:
:
Укажем интерфейсы для синхронизации и heartbeat.
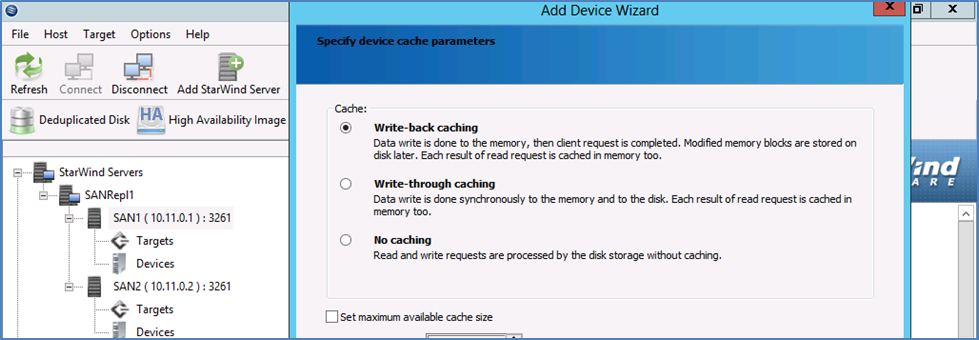
Ниже показаны шаги по настройке реплицируемого хранилища.
В следующем шаге мастера укажем “Synchronize Virtual Disks”.
Возвращаясь к вопросу о репликации. Важно обеспечить подходящий механизм таковой, которых имеется два: синхронная и асинхронная. Хотя для ситуации, когда потеря данных неприемлема, привлекательной выглядит синхронная репликация, в нашем случае мы столкнемся с проблемой задержки обусловленной дистанцией между сайтами т.к. приложение ждет подтверждения записи данных с обоих хранилищ. Процесс синхронной репликации может выполняться медленно, особенно если целевая система расположена на другом конце соединения WAN. Следовательно, остается асинхронная репликация, которая обходит ограничения, вызванные задержкой и дистанцией за счет подтверждения только локальных операций записи на диск, и производит дисковую запись на удаленном хранилище отдельной транзакцией.
Асинхронная репликация производит запись в удаленное хранилище после произведения записи на локальное, следовательно, за повышенную скорость асинхронной репликации приходится платить неопределенностью состояния данных на целевом томе.
Кроме реплицируемой СХД, обеспечим необходимые для построения кластера требования:
в каждом сайте должен быть контроллер домена и DNS, между узлами должно быть соединение с задержкой менее 1000 ms для heartbeat (например, VPN-туннель).
В своем примере, для экономии ресурсов я использовал объединение ролей: установил на одной системе службу маршрутизации, контроллер домена и DNS, тем самым сделав их доступными в обоих сайтах, а также создал общую папку для файлового ресурса-свидетеля.
Завершив подготовительную часть, перейдем к практической реализации географически распределенного кластера средствами Windows Server 2012.
Добавим узлы Node1 и Node2 в домен contoso.com.
На узле Node1.contoso.com настроим iSCSI Initiator на подключение к iSCSI Target по адресу 192.168.1.2, на узле Node2 к iSCSI Target по адресу 192.168.2.2.
Устанавливаем компонент Failover Cluster на хостах Node1 и Node2 после чего запускаем мастер создания кластера. Указываем имя будущего кластера “Cluster1” и добавляем в него узлы Node1 и Node2.
Характерным отличием данного сценария развертывания является тот факт, что узлы находятся в разных подсетях.
Следующей особенностью сценария является выбор модели кворума. В продукционной среде для распределенного кластера характерны сбои не только на уровне узлов и локальной сети, но и на уровне WAN –соединения, поэтому для кворума необходимо определить подходящую модель.
Если в результате сбоя WAN между primary и secondary сайтами произойдет потеря соединения, majority должно быть доступно для продолжения операций.
Для случая с распределенным кластером характерно четное количество узлов и оптимальной представляется модель кворума «Node and File Share Majority» (в случае выбора диска-свидетеля пришлось бы реплицировать том между инстанциями СХД). Настроить модель кворума можно как показано ниже:
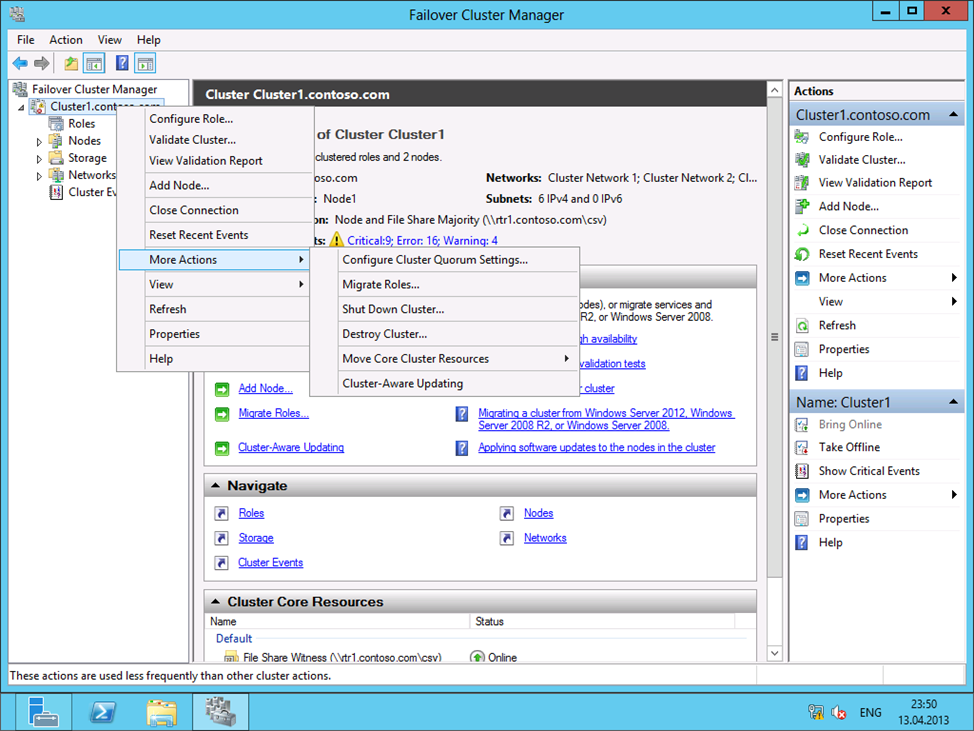
Указываем использовать общий файловый ресурс в роли свидетеля:
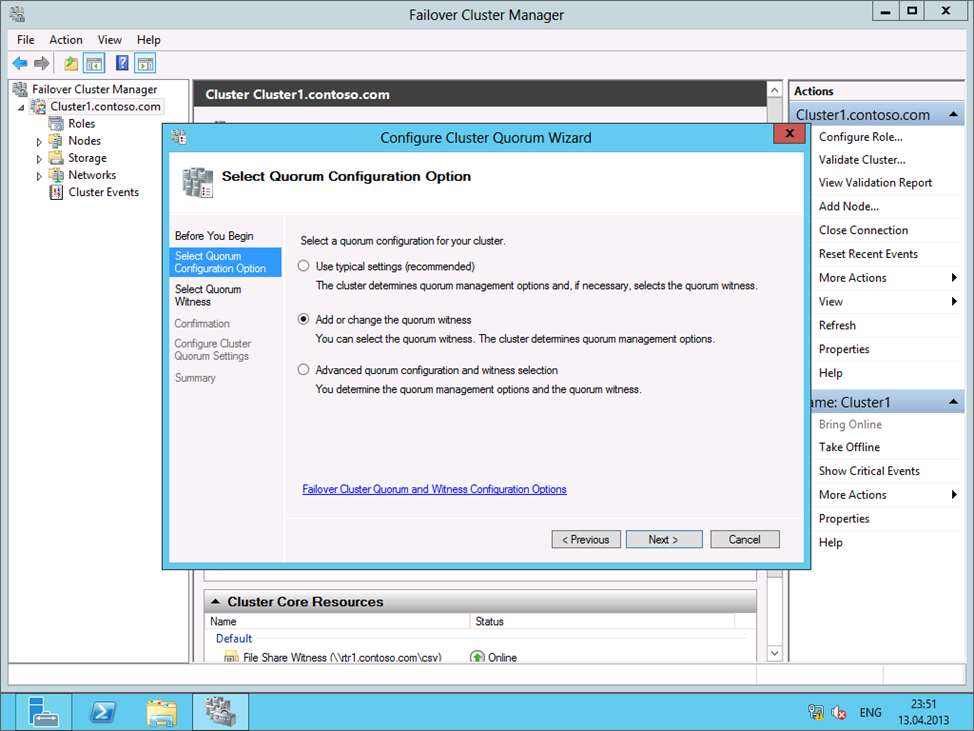
Из соображений отказоустойчивости, файловый ресурс-свидетель резонно расположить в отдельном сайте. В данном сценарии мы используем заранее созданную общую папку “CSV” на сервере RTR1. Соответственно, в следующем окне мастера пропишем путь к ресурсу: file://rtr1.contoso.com/csv.
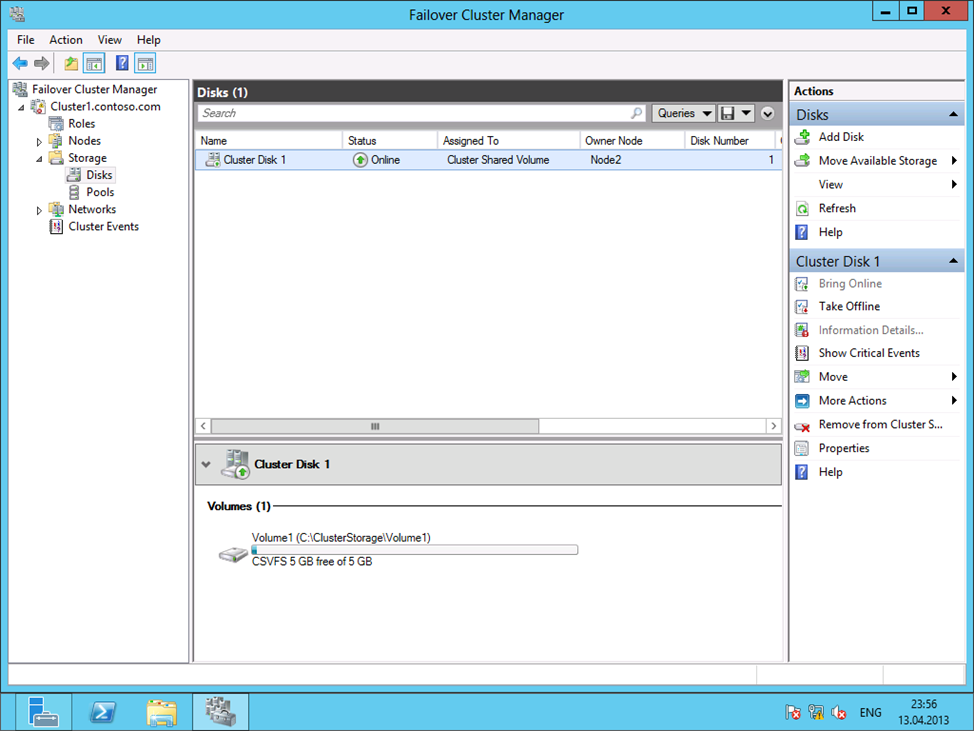
Создаем на диске хранилища общий кластерный том для хранения данных приложений - правый щелчок на Cluster Disk 1 – Add Cluster Shared Volume:
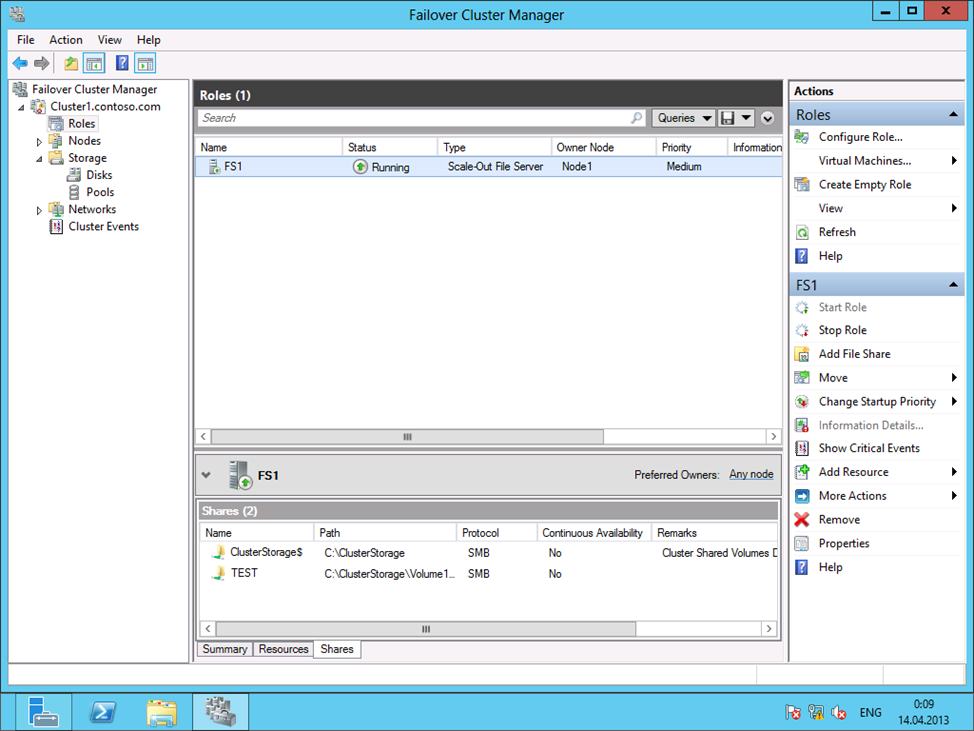
Теперь для тестирования обхода сбоя создадим кластеризованную роль, например, Scale-Out File Server (SOFS) – нововведение в Windows, позволяющее хранить базы данных SQL Server , образы виртуальных машин для Hyper-V в общих файловых ресурсах и т.д. Один узел SOFS становится главным и отслеживает состояние других. В случае выхода из строя одного из узлов, все подключенные к нему клиенты перенаправляются на другой узел, без нарушения коммуникаций.
Зададим кластеризованному SOFS имя fs1.contoso.com.

Создадим на любом узле в кластерном томе по пути C:\ClusterStorage\Volume1 общую папку “Test” для хранения данных кластеризованных ролей, а в ней создадим текстовый документ.
Ну и в финальной фазе перейдем к тестированию – эмулируем сбой, поставив на паузу один из двух узлов кластера и проверяем функциональность решения.
На клиенте Clt-01 в проводнике Windows вводим \fs1\test и открываем текстовый документ.
Открываем командную строку, вводим ping fs1.contoso.com – ответ приходит с активного узла, например, 172.16.1.250. Ставим на паузу узел Node2, сбрасываем кэш DNS на клиенте – ipconfig /flushdns и вновь запускаем ping fs1.contoso.com – ответ приходит с адреса узла Node2 (172.16.2.250). Как видим – решение работоспособно.
Автор: Михаил Соколов, MCT
msokolov@specialist.ru