AlwaysOn: Impact on the primary workload when you run reporting workload on the secondary replica
The primary goal of AlwaysOn technology is to provide High Availability for Tier-1 workloads. The ability to leverage secondary replica(s) to offload reporting workloads and database/transaction log backups is useful, but only if it does not compromise High Availability. This is one of the very common concern/question that I have heard from many of you. In this context, let us evaluate the impact of Active Secondary on the primary replica and workload and what you can do to minimize its impact.
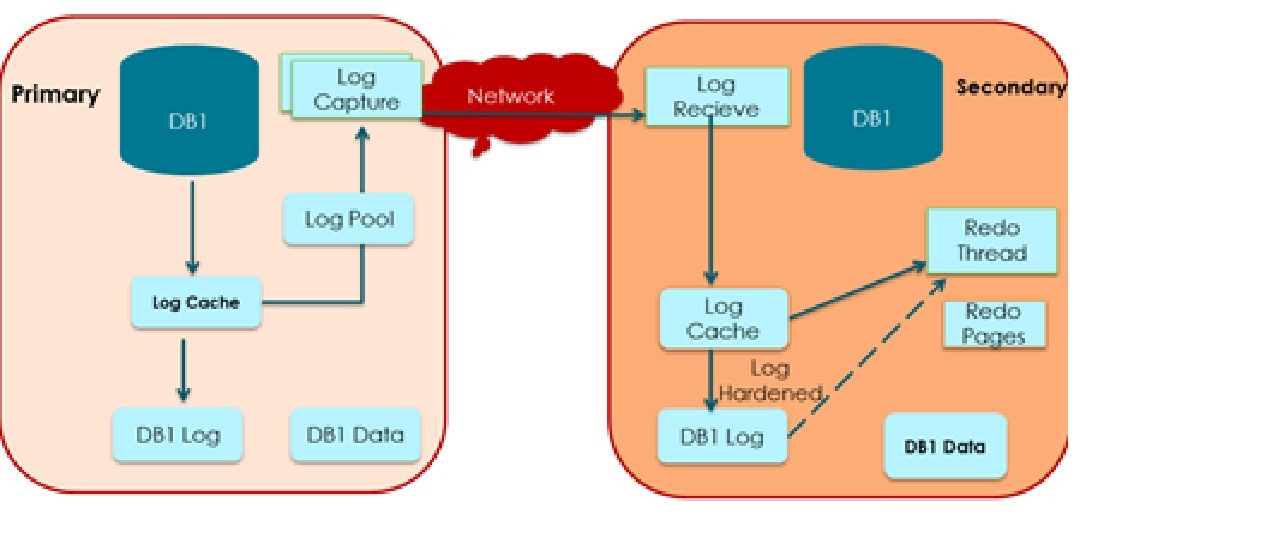
- Transaction response time: When a transaction is run on the primary replica, its transaction log records are written to log buffer and at the same time are sent to log pool to be sent to the secondary replica (for now, we will consider only 1 secondary replica but the same logic holds for multiple replicas) as shown in the picture below. If the secondary replica is configured in async mode, there is no impact on the transaction response time on the primary. However, if the secondary replica is configured in ‘sync’ mode, then the primary replica only commits a transaction when the ‘commit’ log record has been hardened on the secondary replica (it sends an acknowledgement to primary replica). A delay in the acknowledgement from the secondary replica will add to the latency of the transaction. The question that needs to be answered if read workload running on the secondary replica can impact the ACK for the transaction commit? If you look at the secondary replica in the picture below, there are essentially two background threads, one receives the log record over the network and the other hardens that log record. SQL Server gives priority to background threads over user threads (including the ones that are running read workload). This means that at least from CPU perspective, read workload cannot ‘delay’ the ACK. Other possibility is the IO bottleneck caused by read workload that can slow down the transaction log write but this can only happen if data and transaction log share the same physical disk. In most production deployments, transaction log disk is not shared with data disk(s) so it is a non-issue. Having said that, a network bottleneck can add to the latency of the transaction but then it is unrelated to read workload. As we will see later in this article, if REDO thread is not able to keep with the transaction log generated, it can potentially lead to log to grow which can to the transaction latency. In a well configured and managed system, it is unlikely that the read workload on the primary will add to the transactional latency.
{kind=link}
- Transaction throughput: Just like the case of transactional response time discussed earlier, there should not be any impact on the transactional throughput with readable secondary except for the unlikely case when either REDO thread is slowed due to concurrent read workload or blocked which can cause transaction log to grow or run out of space. We will discuss when and how a REDO thread can get blocked and what you can do about it.
- Recovery Point Objective (RPO): RPO refers to data loss in case the primary replica fails over to secondary replica. If the secondary replica chosen as the new primary is configured with ‘Sync’ mode, there cannot be any data loss regardless of the fact that readable secondary has been enabled or not. You may ask what happens if the secondary replica was set in ‘Async’. Interestingly, in this case, there will be no additional impact on the RPO (yes, you can lose data as it is possible if you failover to an ‘Async’ replica) due to running reporting workload on secondary. The reason is that the reporting workload does not interfere with the log transfer path from primary replica to log buffer and its hardening on the secondary replica assuming you log files are mapped to their own storage.
- Recovery Time Objective (RTO): The interesting case for us to know here is the time needed to bring the database ONLINE after a fail over to the secondary replica. When the database restarts after a failover, the REDO thread needs to apply the transaction log records from its current position to the end of the transaction log. The more REDO thread has fallen behind in applying the transaction, the longer (i.e. RTO will be larger) it will take to bring the database ONLINE. Now here, the read workload can potentially impact the RTO negatively for the following two reasons
o As part of applying log records on the secondary replica, REDO thread reads log records from the log disk and then for each log record, it access the data page(s) to apply the log record. The page access can cause a physical IO if the page is not already in the buffer pool. Now, if read workload is IO bound, it will compete for IO resources with REDO thread thereby slowing it down.
o REDO thread can get blocked by read workload. A blocked REDO cannot apply any log record until it is unblocked which can lead to unbounded impact on the RTO. As described in https://blogs.msdn.com/b/sqlserverstorageengine/archive/2011/12/22/alwayson-minimizing-blocking-of-redo-thread-when-running-reporting-workload-on-secondary-replica.aspx, the design center of readable secondary has eliminated blocking in common scenario and in the event there is blocking, it provides users tell-tale signs both in the dash-board and in the form of XEvent to warn the user of the situation so that a corrective action can be taken
With this, I hope that I have answered most common concerns. I look forward to your questions and suggestions
Thanks
Sunil Agarwal
Comments
Anonymous
June 22, 2012
Thank you for this post. So if I understand this correctly, the main potential bottlenecks in transaction throughput between a primary and a sync replica (excluding the failover scenario) are: (1) network latency between the primary and the replica; (2) disk I/O on the sync-replica log drive location (assuming data and log are separated onto distinct spindles). I will be setting up an environment with a primary, a sync and an async replica sharing the same SAN and being on the same local-area network. I am tempted to allow both the sync and async replicas to be readable, so I can have all 3 nodes being actively used all the time (as opposed to having the sync node sitting as a purely "passive" failover node). I am not sure if that is a good idea for my workload characteristics and what to watch out for, in terms of throughput performance in that scenario. Any advice would be appreciated.Anonymous
June 24, 2012
Given your configuration, you should be fine allowing read on both sync and async replica. thanks SunilAnonymous
November 18, 2014
REDO thread will get blocked only in Synchronous mode ?- Anonymous
March 17, 2016
No... sync mode has nothing to do with SYNC mode... sync mode only impacts latency of a transaction on the primary
- Anonymous
Anonymous
September 10, 2015
The comment has been removed- Anonymous
March 17, 2016
your question relates to Quorum. you can configure such that primary continues to run... please refer to https://blogs.msdn.microsoft.com/sqlalwayson/2012/03/13/quorum-vote-configuration-check-in-alwayson-availability-group-wizards-andy-jing/ and other related docs
- Anonymous