Automating Capture, Save and Analysis of HTTP Traffic – Part II
The previous post Automating Capture, Save and Analysis of HTTP Traffic – Part I explains how to capture and save the HTTP traffic in an automated fashion. This post covers the right most block shown in the figure below which is to perform analysis on the gathered traffic (which is in the form of csv log files) again in an automated fashion. But before going further into details let's first define the scope of this analysis. I do believe the script can be extended with little effort to meet your unique requirements.

- Request severed from CDN: CDN is a content delivery network which helps storing resources at various geographically dispersed location and help client avoid full round trip to the web server. You may be interested to keep track of requests facilitated by CDN because there can be opportunity to improve the throughput by placing files on the CDN. Resources like script file (e.g. JQuery script file) are common candidate for CDN and almost always served from CDN. You should able to provide list of resources that are expected to be served from CDN.
- Requests not served by CDN: In conjunction with files which are served from CDN provides you would want ability to track which files are not coming from CDN. For example if you want to JQuery script files to be served from CDN then if JQuery is served from non-CDN location you want to track that too.
- Requests served from browser Cache: When a file is first served from the server to the client it can be cached locally by the browser and later served directly by the browser from its cache. This off course has performance benefit so you may be interested to know which files are severed by the cache. This also works other way around when you don't want files to serve from the cache and want to keep track of that.
- File that should not be requested (eliminated/non-eliminated files): While doing performance enhancement you always want to look into files requested by the client and served that may be eliminated altogether, perhaps multiple references exists to the same file within the page etc. In situation like these you can provide the list of files that you want to verify for removal/elimination from the requests and should get details if these files still been requested by the client.
- Size of the Request/Response: The actual size of the server request/response can play important factor on performance and it's you want to keep track of – especially the request size.
- Ability to capture HTTP Request Status: These are the codes like 302 (redirect), 401 (Unauthorized) etc. While doing performance related work you may want to keep track of these and count each one of them and the request that cause these to occur.
You can download all the required items to work with this post here. Following is the brief details of each file that is part of the download.
- Globals.ps1: This is a global script file containing few utility functions but nothing related to the actual analysis.
- AnalyzeCsvLogsOnPerfCounters.ps1: Performs the actual analysis based on the requirements mentioned above and display the results on the console and also provide ability to save the results to an output file.
- Logs.Csv: This is an input log file in csv format containing all the traffic which captures requests/responses b/w client and server. This file is the actually the output of the GatherPerfCountersForPages.ps1 script which was the covered in the first part of this blog series. If you don't want to run that script again to generate the log file I have made one available as part of the download so you can use it instead.
- Output.txt: Sample output file that is generated when AnalyzeCsvLogsOnPerfCounters.ps1 is run. I included it as part of the download because you may want to take a look at it before running the script. Anyways, later in the post you will generate the output file by running the script but useful to have this file for reference purposes.
Performing Analysis on the Log Files
The listing below shows the script (AnalyzeCsvLogsOnPerfCounters.ps1). I will do a complete walkthrough of it in rest of this post but first let's run it and look at the end result so you get better idea of what work script is actually doing.
Note: I have to mention that no matter what setting I use to publish this post the script does get some extra spaces and line breaks. I highly recommend downloading script and avoid any copy/paste directly from the post itself. On my machine I have downloaded and unzip the files at "C:\Scripts" folder, you can choose folder of your liking but do remember to change the path when run the script later.
# ******************************************************************************
# THIS SCRIPT AND ANY RELATED INFORMATION ARE PROVIDED "AS IS" WITHOUT WARRANTY
# OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A PARTICULAR PURPOSE"
# ******************************************************************************
<#
.SYNOPSIS
Analyze the trace from the log files (.csv) and output the information by categorizing it into
(1) Requests served form CDN
(2) Requests not served from CDN
(3) Requests served from browser Cache
(4) Track files that should not be requested by the client but are still getting requested (referred as files eliminated / not eliminated)
(5) Requests end up with specefic return code (404,302,500,etc)
.INPUT: args[0] --> <logFilesPath>: Location of the log files
args[0] --> <logExtenstion> Extension type of a log file
args[1] --> <statusCodes>: HTTP Status code(s) to analyze in log file
args[2] --> <cdnLinks>: Comma separated links of CDN hosts
args[3] --> <removedFiles>: Comma separated list of files which should not be part of any requests
args[4] --> <saveOutputToFile>: $true | $false. If set to true output will be written to a file otherwise text will be displayed on the console.
.EXAMPLE
.\AnalyzeCsvLogsOnPerfCounters.ps1 "C:\Files" ".csv" "302,404" "ajax.microsoft.com" "jquery.js,core.css" $true | Out-File "C:\Files\Report.txt"
.\AnalyzeCsvLogsOnPerfCounters.ps1 "C:\Files" ".csv" "302,404" "ajax.microsoft.com" "jquery.js,core.css" $false
.LINK
.NOTES
File Name : AnalyzeCsvLogsOnPerfCounters.ps1
Author : Razi bin Rais*
Prerequisite : PowerShell v1 or above, Globals.ps1
*When using/reusing any part of this script you must retain/refer to the original author.
#>
Function
AnalyzeCsvLogsOnPerfCounters
{
[CmdletBinding()]
Param(
[Parameter(Mandatory=$true,Position=0)][string]
$logFilesPath,
[Parameter(Mandatory=$true,Position=1)][string]
$logExtenstion
=".csv",
[Parameter(Mandatory=$false,Position=2)][string]
$statusCodes,
[Parameter(Mandatory=$false,Position=3)][string]
$cdnLinks,
[Parameter(Mandatory=$false,Position=4)][string]
$removedFiles,
[Parameter(Mandatory=$false,Position=5)][bool]
$saveOutputToFile
)
#Declare and set variables
Set-Variable
CACHE
-option
Constant
-value
"(Cache)"
Set-Variable
ABORTED
-option
Constant
-value
"(Aborted)"
$count=0;
$cdnUrls
=
StringToArray
$cdnLinks
$eliminatedFiles
=
StringToArray
$removedFiles
$returnCodes
=
StringToArray
$statusCodes
#Load single log file at a time and go through the requests
foreach($file
in (Get-Childitem
$logFilesPath
|? {$_.extension -eq $logExtenstion}))
{
$log
=
Import-Csv
$file.FullName
$trace
=
$log
|
where {$_.Result -ne $ABORTED}
WriteToOutPut ("**********Loading log file ..."
+
$file.FullName) "Green" $saveOutputToFile
if ($trace.Count -eq
0)
{
WriteToOutPut ("No requests found in the log file:- "
+
$file) "Yellow"
$saveOutputToFile
continue;
}
WriteToOutPut ("Total requests send by browser:- "
+
$trace.Count) "Yellow" $saveOutputToFile
$nonCdnRequest
= @();
$returnStatus
= @{};
if ($returnCodes.Count -gt
0){
$returnCodes
|
% { $returnStatus.Add($_,(@{}));} #Add status code as main hash key, the value is another hastable with key = counter and value = actual url
}
#Analyze CDN Requests
WriteToOutPut
"***********Analyzing requests coming from CDN"
"Green"
$saveOutputToFile
foreach($entry
in
$trace )
{
if(ContainsAny
$entry.URL $cdnUrls)
{
switch ($entry.Result)
{
$CACHE { WriteToOutPut ($entry.Url +
" - "
+ $entry.Result) "White" $saveOutputToFile }
default {
if ($returnStatus.ContainsKey($entry.Result.Trim()))
{
$returnStatus[$entry.Result.Trim()].Add(($returnStatus[$entry.Result.Trim()].Keys.Count)+1 ,$entry.Url)
}
switch($entry.Method)
{
"GET" { WriteToOutPut ($entry.Url +
" - "
+ $entry.Received +
" bytes") "White" $saveOutputToFile}
"POST" { WriteToOutPut ($entry.Url +
" - "
+ $entry.Send +
" bytes") "White" $saveOutputToFile}
default { WriteToOutPut ($entry.Url) "White" $saveOutputToFile}
}#end switch
}
}#end switch
$count++
} #end if
else
{
$nonCdnRequest
+=
$entry;
}
}#end foreach
WriteToOutPut ("Total requests served by CDN: "
+
$count) "Yellow"
$saveOutputToFile
$count=0;
#Analyze Non-CDN Requests
WriteToOutPut
"***********Analyzing requests Not coming from CDN"
"Green"
$saveOutputToFile
foreach($entry
in
$nonCdnRequest)
{
switch ($entry.Result)
{
$CACHE { WriteToOutPut ($entry.Url +
" - "
+ $entry.Result) "White" $saveOutputToFile}
default
{
if ($returnStatus.ContainsKey($entry.Result.Trim()))
{
$returnStatus[$entry.Result.Trim()].Add(($returnStatus[$entry.Result.Trim()].Keys.Count)+1 ,$entry.Url)
}
switch($entry.Method)
{
"GET" { WriteToOutPut ($entry.Url +
" - "
+ $entry.Received +
" bytes") "White" $saveOutputToFile}
"POST" { WriteToOutPut ($entry.Url +
" - "
+ $entry.Send +
" bytes") "White" $saveOutputToFile}
default { WriteToOutPut ($entry.Url) "White" $saveOutputToFile}
}#end switch
}#end default
}#end switch
}#end foreach
WriteToOutPut ("Total requests Not served by CDN: "
+
$nonCdnRequest.Count) "Yellow" $saveOutputToFile
#Analyzing Status Codes
if($returnStatus.Count -gt
0)
{
#Each key contain status code (e.g. 302, 404 etc)
foreach($key
in
$returnStatus.Keys)
{
WriteToOutPut ("***********Analyzing requests that received "+
$key
+" response from server") "Green"
$saveOutputToFile
WriteToOutPut ("Total requests that received "
+
$key
+
" - "+$returnStatus[$key].Keys.Count) "Yellow" $saveOutputToFile
#The child ht contains (counter,url) pair so every value is a Url
foreach($url
in
$returnStatus[$key].Values)
{
if(![String]::IsNullOrEmpty($url))
{
WriteToOutPut ($url) "White"
$saveOutputToFile
}
}
}
}#end Status Code Check
if($eliminatedFiles.Length -gt
0)
{
#Analyze requests that are eliminated
WriteToOutPut ("***********Analyzing requests for files that are eliminated/not eliminated") "Green"
$saveOutputToFile
$filesNotRemoved
= @{};
foreach($entry
in
$trace)
{
$count=0;
foreach ($fileName
in
$eliminatedFiles)
{
if($entry.URL.Contains($fileName.Trim()))
{
$count++;
if(!$filesNotRemoved.ContainsKey($fileName.Trim()))
{
$filesNotRemoved.Add($fileName.Trim(),(@()));
}
$filesNotRemoved[$fileName.Trim()]
+= $entry.Url
}
}#end innter-loop
}#end outer-loop
#Display files that are eliminated
WriteToOutPut ( "Total files that are eliminated: "
+ ($eliminatedFiles.Count -$filesNotRemoved.Count)) "Yellow" $saveOutputToFile
if ($eliminatedFiles.Count -gt $filesNotRemoved.Count)
{
#WriteToOutPut ("List of files that are eliminated") "Green" $saveOutputToFile
$eliminatedFiles
|
% {
if(!$filesNotRemoved.Contains($_)) { WriteToOutPut ("$_ ") "White" $saveOutputToFile}
}
}
#Display files that are not eliminated
WriteToOutPut ( "Total files that are not eliminated: "
+
$filesNotRemoved.Count) "Yellow" $saveOutputToFile
if($filesNotRemoved.Count -gt
0)
{
foreach($key
in
$filesNotRemoved.Keys)
{
WriteToOutPut ("Filename: "
+
$key) "Green"
$saveOutputToFile;
foreach($url
in
$filesNotRemoved[$key])
{
WriteToOutPut ($url) "White"
$saveOutputToFile
}
}
}
}
$count=0;
}#end foreach
}#end function
Open up the Logs.csv file (partially shown below) which is part of downloads and notice the data inside it. If you followed the previous part on this series, this is the output of that. I choose to open it using Microsoft Excel so I can easily display the columns that are part of this csv but you can use software of your choice to do that.

So to start the analysis open up the PowerShell console, go to the directory where downloaded scripts are located and run following command with given parameters (will explain them in a moment)
PS C:\scripts> .\AnalyzeCsvLogsOnPerfCounters.ps1 "logs.csv" ".csv" "302,404" "ajax.microsoft.com,dnn506yrbagrg.cloudfront.net" "jquery.js,sp.ribbon.js,core.css" $true | Out-File "output.txt"
You should see the output similar to following screenshot. I have removed few lines for brevity as they are taking too much space on the post, however I do maintain all of the major portions. Also, take a look inside the folder where scripts are located and open up output.txt file. Examine its content and notice they are same as console output.
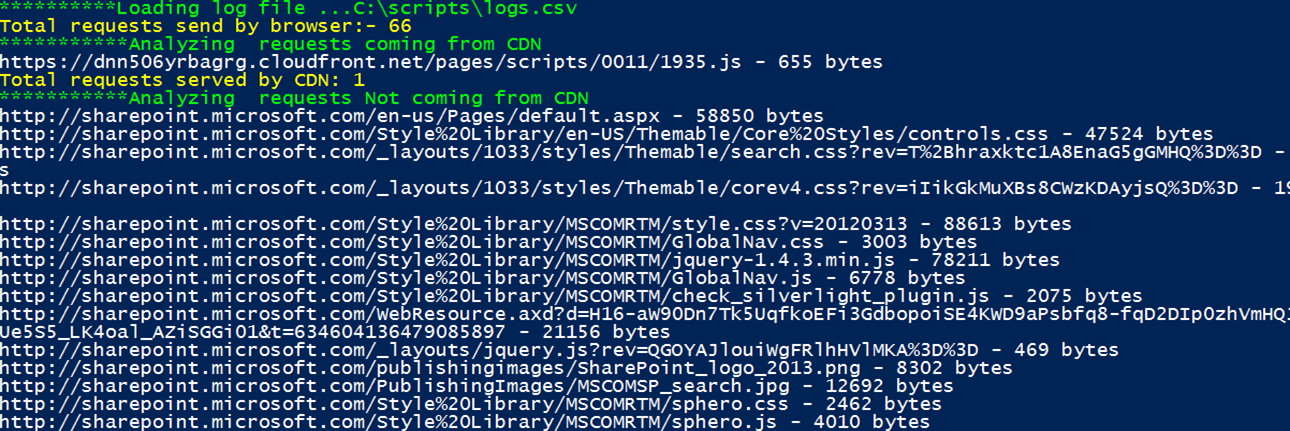

Let's quickly examine the output on the console, the text in the yellow is the key piece of information that you are really after. It's essentially covers the basic requirements mentioned earlier in the post including number of requests served from CDN versus non-CDN along with bytes received as a response, HTTP status received and files that were are not requested (referred as eliminated).
The parameters passed to the scripts are actual drivers and are explained next, the power and flexibility really comes with providing the relevant input parameters to make script work on information that you are interested in.
Parameter |
Description |
logFilesPath |
Path to folder with Csv log files. E.g. "C\Scripts\Logs" It can also point to specific log file, e.g. C:\Scripts\Logs\Logs.csv. The execution context must have read access to this file. This parameter is case-insensitive. |
logExtenstion |
This should always be ".csv", the default value is already set to ".csv". This parameter is case-insensitive. |
statusCodes |
Comma separated list of valid Http Status Codes. E.g. "302,402". For a single item comma separation is not required. This parameter is case-insensitive. |
cdnLinks |
Comma separated list of CDN links to seek in the log file. E.g. "ajax.microsoft.com". For a single item comma separation is not required. This parameter is case-insensitive. |
removedFiles |
Comma separated list of files that needs to be checked for removal/elimination from the request(s). E.g. "jquery.js,core.css". For a single item comma separation is not required. This parameter is case-insensitive. |
outputToFile |
A Boolean flag with a value of $true|$false. When $true verbose is saved to an output file. This is an optional parameter. This parameter is case-insensitive. |
Script begin by declaring few variables cdnUrls, eliminatedFiles and returnCodes. Notice the conversion of passed parameter from string to array because parameters are essentially carrying comma delimited string and can't be used as is. CACHE and ABORTED are two variables that are used later to distinguish among the requests that are either aborted or being served from cache. This is an important consideration because if a request to the server is ABORTED it should avoid during the analysis because it may not even reached the server for processing. Actually ABORTED is a special tag used by the HTTPWatch (tool used to capture the logs and discussed in previous part of this series) and shown under STATUS column within log file, this status is treated as a special Result status because it differs from normal status's like 302,404 etc. I don't want to make things overly complicated but if you dig into ABORTED as a status you may found that certain number of requests were actually reached to the server (some might not) and then got aborted, you can read more about ABORTED status on tje HTTPWatch blog here. I choose to simply ignore any entry with ABORTED Result status because I want to keep script relatively simple and empirically I found very small portion of requests (if any) actually get aborted. But it's something worthy to point out and keep note of.
The requests severed from the browser CACHE on the other hand will be call out as such because they won't incur the roundtrip to the Web/CDN server and does not cause same performance hit as the ones that are actually served by Web/CDN server.
CDN & Non-CDN Requests + Requests Severed from Cache: The work begins by first foreach loop that open the csv log files from the folder (one file at a time). Next variables nonCdnRequest and returnStatus are declared as array and hashtable respectively and they get initialized for every log file. The returnStatus hastable is worthy of some explanation, it store status code as a key and then for its value it declares an array, this array will contain the actual requests that end up getting the particular status code.
The next foreach (let's call it CDN requests loop) iterate through the trace which is essentially a single line from the log file representing a single request/response. Cache check is made first and then check for the status code is made. In case relevant status code is found it's added to the returnStatus hashtable. Also part of output is request/response details including URL along with the size in bytes which is based on HTTP verb i-e GET or POST. Lastly, in case the trace entry is not served from CDN then it needs to be added to the nonCdnRequest array so it can be tracked separately and accounted for. This is done in following foreach loop and it follows essentially same logic as preceding one expect that it works on nonCdnRequest array, and once completed output the count of total non CDN requests.
HTTP Status Codes: This is done by first checking the count of returnStatus hashtable. Then a foreach loop iterates through its keys and every single key represent a unique code (e.g. 302). Also for against each key there may be more than one URL that received that status and for that to be counted inner foreach iterate through the values against that particular key. Please note that the values represent the actual URL(s) that result in status code equal to the particular key.
Files Eliminated & Not Eliminated From Requests: The eliminatedFiles array carries all the files that supposed to be not requested by the client, so any request for them should be tracked and call out in the output. This is done by first declaring filesNotRemoved hashtable and then iterating all the requests within the log file – one at a time. The filesNotRemoved hashtable carries name of the file as a key and its value is an array which contains URL(s) that were requested against the particular key. This allows capturing the name of the file which is not removed along with all of the requested URL(s) for it and aggregating them by filename. Once the iteration is completed for all the entries in the log file, the output begins first for files that were eliminated (not requested) by iterating over eliminatedFiles array and by checking for absence of any filename within filesNotRemoved hashtable which uses filename as its key. Secondly, output is made for file(s) which does not get eliminated (and hence requested) by iterating through the filesNotRemoved hashtable. There are actually two loops for this, one for the filename (which is a key) and then inner loop which output the actual URL(s) which requested that file.
Summary
That's it! , I do want to mention that the log file do contains many other useful bits of information that I didn't analyze within the script. That is something you may want to explore on your own as per your needs and perhaps enhance the script for it. For example columns like Type (content-type), Time, Compression can be good candidate for further analysis.