La démocratisation du data mining
Mais au juste, qu'est-ce que le data mining?
Commençons par rectifier quelques fausses idées.
Les activités suivantes ne sont pas une implémentation du data mining:
- Le "reporting ad_hoc". C'est la conception de rapport et la mise en relief de données à partir de méta-données. Ce n'est qu'une présentation des données existantes.
- La navigation dans un cube. Dans un cube, les données sont mise en forme de manière structurées et agrégées facilitant ainsi l'interrogation et la comparaison de métriques essentielles à la prise de décision.
- L'abonnement à des évènements pour accélérer la prise de décision.
- Les statistiques. Bien qu'elles soient à la base du data mining, ça reste différent…
Robert Grossman nous donne une définition intéressante : "Le data mining est la conception semi-automatique ou automatique de modèles visant à mettre en avant des liens entre des données, détecter des anomalies, des changements,..., et le tout à partir d'un ensemble important d'informations. »
C'est donc le procédé qui permet d'identifier des tendances à partir de fait existants, on l'appelle aussi analyse prédictive ou exploration de données.
Dans quel cadre s'applique le data mining?
Les usages les plus souvent cités sont :
- L'analyse des fraudes. Une compagnie d'assurance doit traiter une quantité importante de dossiers par jour et elle doit s'équiper d'un outil pour déceler les dossiers frauduleux.
- L'étude des comportements des consommateurs.
- La prédiction, comme le passage d'un client à la concurrence
- La classification des clients afin de cibler une campagne publicitaire sur une population particulière.
L'exemple historique est celui d'une entreprise de grande distribution américaine. Après avoir analysé les ventes, ils se sont aperçus que les paquets de couches pour bébés étaient souvent achetés le samedi par les pères à cause de leur gros volume. D'où la réorganisation des rayons des supermarchés avec le positionnement des packs de bière à coté des couches. Le samedi étant un jour de match, les ventes ont amplement augmenté ! Cette image illustre bien les capacités de retour sur investissement (ROI) des travaux de data mining et plus généralement d'informatique décisionnelle.
Le cabinet d'étude IDC estime que dans certains cas, le data mining apporte un ROI de 150%!
Afin de répondre aux problèmes adressés par le data mining, il existe un certains nombre de procédés type comme la classification, le regroupement, la mise en association, la prédiction, l'analyse de séquence, la régression.
C'est à ce niveau qu'intervient le rôle des algorithmes car c'est eux qui permettent d'effectuer ces transformations de données.
La figure 1 ci-dessous présente la matrice des différents algorithmes liés aux tâches de transformation de données.
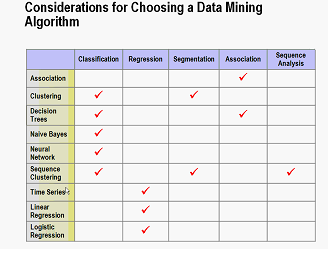
Figure 1 – Critères de choix pour un algorithme
La démarche de mise en œuvre
Comme dans tous projets, une démarche/méthodologie doit être mise en place pour assurer son bon déroulement.
Une méthodologie de référence est celle proposée par le CRISP-DM (CRoss Industry Standard Process for Data Mining)
. 
Figure 2 : Méthodologie CRISP
Comme l'illustre la figure 2, cette méthodologie se décompose en 6 phases qui sont :
Analyse du métier
Cette phase initiale permet de définir les objectifs et les besoins d'un point de vue métier, afin de formuler le cahier des charges.
Compréhension des données
Cette phase consiste à partir d'échantillonnage d'évaluer la qualité des données, de définir les premiers jeux d'informations utiles pour répondre aux besoins métiers
Préparation des données
Cette phase permet de construire, transformer les données afin qu'elles puissent être consommées par les outils de modélisation.
Modélisation
Lors de cette phase plusieurs modèles sont appliqués et validés. Il n'est pas rare de revenir à la phase de préparation de données.
Evaluation
A ce niveau d'avancement, il est important de faire valider les modèles dans une perspective métier.
Déploiement
La phase finale consiste à rendre accessible les modèles élaborés aux utilisateurs finaux.
Mais pourquoi donc une démocratisation du data mining?
Microsoft est entré dans le domaine du data mining avec la version 2000 de SQL Server et le produit a bien évolué avec la version 2005 et maintenant 2008.
Comme le montre de nombreuses études, l'outil privilégié des analystes reste Excel. L'idée est donc de fournir dans Excel les outils nécessaires à la mise en œuvre d'un projet de data mining. Depuis le SP2 de SQL Server 2005, un add-in de data mining est intégrable dans Excel. Le lien de pour télécharger cet add-in est mentionné ci-dessous.
Pour s'éloigner un peu de la théorie, présentons par l'exemple un cas concret, celui de la définition des prix d'assurance de voiture en fonction des différentes caractéristiques.
Notre compagnie d'assurance possède une liste de véhicules avec l'ensemble des attributs qui les caractérisent en particuliers, un coefficient de risque.
Comme le montre la figure 3 ci-dessous, l'add-in Excel a été conçu pour suivre la méthode CRISP-DM.

Figure 3 – L'add in Excel
Décrivons dans le tableau suivant les étapes d'analyse :
Description de l'étape |
Présentation de l'étape |
Phase CRISP : Compréhension des données
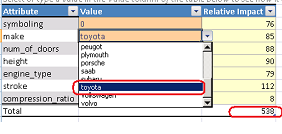
L'outil nous assiste pour déterminer les attributs majeurs qui influent sur le coefficient de risque. |
|
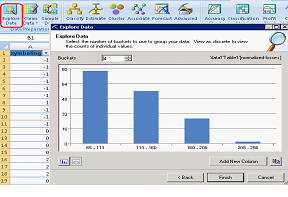
Phase CRISP : Préparation des données.
Les données sont facilement analysées de sorte à transformer notre coefficient risque en deux valeurs : important et faible (risque). |
|



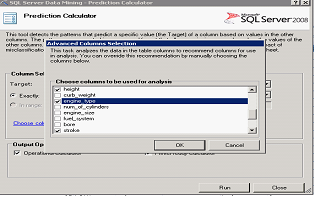
Phase CRISP : Modélisation.
Une fois les données préparées, nous rentrons dans la phase de modélisation en utilisant en entrée les attributs prépondérants à l'affectation du coefficient risque. Ainsi dans notre cas, nous avons implémenté un arbre de décision qui permet de définir des relations entres les attributs. |
|
Phase CRISP : Validation et déploiement.
Plusieurs modèles sont implémentés puis comparés à l'aide de la « matrice de classification ». Dans notre cas, l'usage de l'algorithme arbre de décision est plus performant que le réseau de neurones. Les résultats obtenus sont facilement consultables à l'aide d'un portail comme Sharepoint. |
|
Phase CRISP : Déploiement.
A partir des données analysées, il est possible de définir la politique tarifaire pour des nouveaux véhicules. Ainsi dans notre cas, nous pouvons évaluer le niveau de risque d'assurance en fonction des attributs du nouveau véhicule et donc associer par la suite un coût d'assurance. |
|



A travers cet exemple, nous venons de montrer comment l'enrichissement d'Excel permet d'aider à la prise de décision.
Bien entendu, d'autres scénarios métiers peuvent être entièrement abordés à travers Excel comme déceler les acheteurs potentiels en vue d'une campagne marketing.
Au cœur de la bête
Nous avons vu comment implémenter un scénario de data mining avec Excel, mais que se passe-t'il en arrière plan ?
C'est Analysis Services (SSAS) la plateforme de data mining, bien qu'il soit aussi le moteur multidimensionnel de la suite SQL Server. Regardons comment il est structuré pour répondre aux problématiques de data mining.
Cet outil est organisé en plusieurs briques, comme le montre la figure 4.
 Figure 4 – Analysis Services et le Data Mining
Figure 4 – Analysis Services et le Data Mining
La modélisation multidimensionnelle commence par la création d'un cube, qui est la structure visant à manipuler les données. Dans ce cube, des dimensions sont créées afin de disposer de plusieurs axes pour analyser les données.
La modélisation prédictive (data mining) fonctionne de la même façon : une structure doit être créée pour accueillir les données concernées, et à l'intérieur de celle-ci, un ou plusieurs modèles seront implémentés, afin de dégager les tendances.
La création de structures et de modèles est accessible avec le DMX (Data Mining eXtension). Ce langage d'interrogation et de manipulation des objets, qui est au data mining ce que le SQL est à la base de données, a été créé et proposé par Microsoft, afin d'interagir avec Analysis Services. Il est relativement simple, comme le montre l'exemple suivant, qui crée un nouveau modèle selon l'algorithme de Naive Bayes :
CREATE
MINING
MODEL [NBExemple]
(
CustomerKey LONG
KEY,
Gender TEXT
DISCRETE,
[Number Cars Owned] LONG
DISCRETE,
[Bike Buyer] LONG
DISCRETE
PREDICT
)
USING
Microsoft_Naive_Bayes
Quand le volume de données à manipuler est très important ou quand on veut lier des analyses prédictives à de l'analyse multidimensionnelle, Excel ne suffit plus. Il faut alors passer dans du développement Business Intelligence Development Studio, c'est pourquoi il est nécessaire de faire collaborer les équipes fonctionnelles et techniques pour les projets avancés.
Bien que plusieurs algorithmes soient fournis de base, il est possible d'enrichir l'outil en proposant d'autres personnalisés. On bénéficie ainsi de l'ossature offerte par l'offre Microsoft: Analysis Services et Excel. Certains acteurs reconnus dans le monde du data mining ont développé des extensions pour transporter leurs méthodes dans SQL Server. On peut notamment citer SPSS qui propose leurs analyses statistiques ou Visual Numerics qui ont interfacé leurs méthodes d'analyse numériques vers SQL Server.
SQL Server : Plateforme intégrée et cohérente
Si l'investissement dans la suite SQL Server est essentiellement motivé par l'acquisition d'un outil de data mining, la montée en compétences des équipes sur le produit pourra être capitalisée lors de développement d'applications décisionnelles.
La suite SQL Server (SSIS – Integration Services, SSAS – Analysis Services, SSRS – Reporting Services) est complète pour mener à bien un projet décisionnel et un projet data mining selon la démarche expliquée précédemment. Dès qu'on attaque la manipulation des données, chaque module répond au besoin de chaque étape :
SSIS permet de préparer l'échantillon de données, et également d'alimenter un datawarehouse
SQL Server permet de stocker le volume important de données
La modélisation et l'évaluation des modèles prédictifs se fait dans SSAS, qui fait également de la modélisation dimensionnelle
Les utilisateurs peuvent accéder à tous les résultats via SSRS.
Donc, SQL Server peut être utilisé aux deux fins d'analyse décisionnelle et prédictive, l'implication et la formation des équipes de développement est réutilisable, pour obtenir une application de pilotage complète, qui donne une vision globale et précise de l'activité.
Conclusion
Ainsi, les besoins en data mining peuvent être assez rapidement comblés directement par les utilisateurs fonctionnels, l'accès par Excel étant relativement simple. Si les demandes sont plus complexes, on bénéficie d'une plateforme appropriée pour faire des analyses plus précises, plateforme qui reste ouverte et peut être enrichie avec d'autres modèles. La suite SQL Server, qui permet donc la démocratisation du data mining, est un outil complet d'aide à la décision.
Pour aller plus loin
Source pour le DMX : https://msdn.microsoft.com/fr-fr/library/ms132058.aspx
Add-in Office 2007: https://www.microsoft.com/sqlserver/2008/en/us/data-mining-addins.aspx
SPSS : https://www.spss.com/sqlserver/
Visual Numerics : https://www.vni.com/company/whitepapers/MicrosoftBIwithNumericalLibraries.pdf
Méthodologie CRISP-DM : https://www.crisp-dm.org/
SQL Server data mining : https://www.sqlserverdatamining.com/ssdm/
Blog des experts data mining chez Microsoft :
Jamie MacLennan : https://blogs.msdn.com/jamiemac/
Bogdan Crivat : https://www.bogdancrivat.net/dm/
Comments
- Anonymous
May 07, 2009
PingBack from http://asp-net-hosting.simplynetdev.com/la-democratisation-du-data-mining/