Understanding VM Availability in Azure
When discussing Azure Virtual Machine (VM) resiliency with customers, they typically assume it is comparable to their on-prem VM architecture and as such, features from on-prem is expected in Azure. Well, it is not the case, thus I wanted to put this together to provide more clarity on the VM construct in Azure to better understand how VM availability in Azure is typically more resilient then most on-prem configuration.
A VM has 3 main components: Compute, Storage and Networking. For this discussion I will only target the Compute(VM) and Storage components.
A few important concepts to understand first:
Fabric Controller (FC)
- The FC is the kernel of the Microsoft Azure cloud operating system. It monitors and manages most Azure resources. It also detects and responds to both software and hardware failure automatically.
Partitioning
Azure's Fabric Controller uses two types of partitions: Update Domains(UDs) and Fault Domains(FDs).
- An Update Domain is used to upgrade a service’s role instances in groups. Azure deploys service instances into multiple update domains. For an in-place update, the FC brings down all the instances in one update domain, updates them, and then restarts them before moving to the next update domain. This approach prevents the entire service from being unavailable during the update process.
- A Fault Domain defines potential points of hardware or network failure. For any role with more than one instance, the FC ensures that the instances are distributed across multiple fault domains, in order to prevent isolated hardware failures from disrupting service. All exposure to server and cluster failure in Azure is governed by fault domains.
Azure Blob Storage
Architecture Overview:
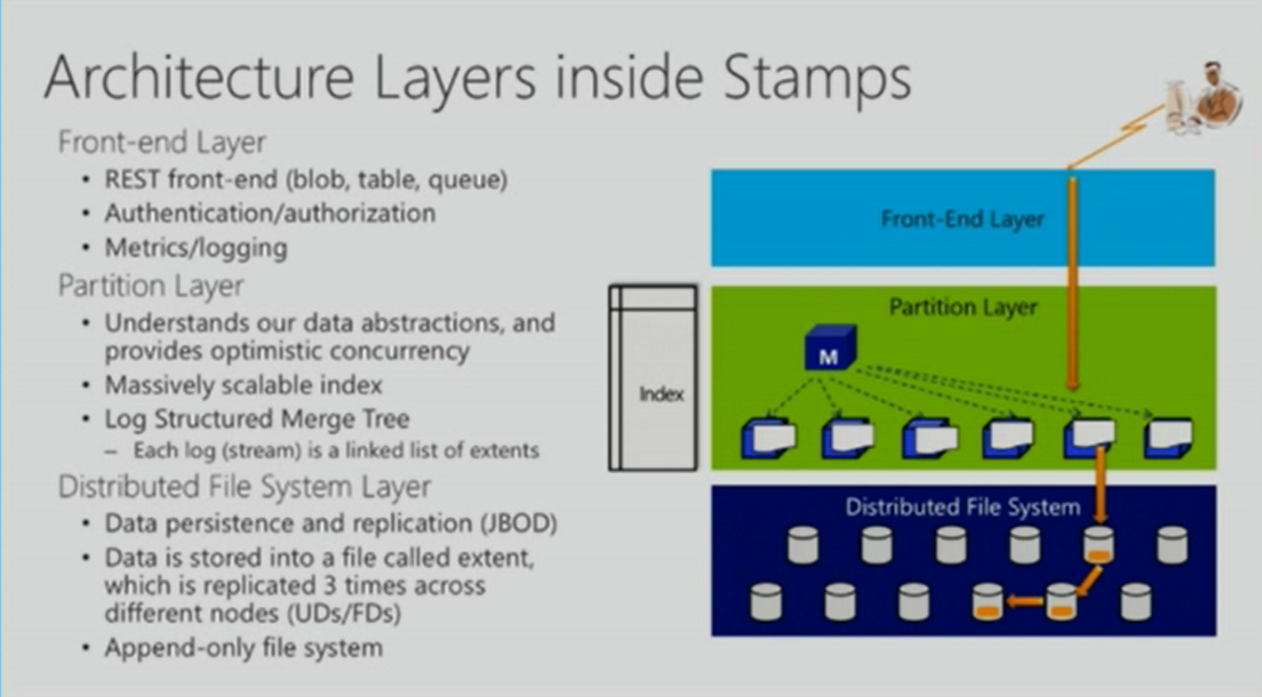
As per the above slide from Brad Calder at Build 2013, a Stamp is a cluster of servers hosted in Azure Datacenter. Each Datacenter have multiple Stamps. It is composed of 3 layers with built-in redundancy to provide High Availability. For the purpose of this discussion, I will only target the lower level layer. At the Distributed File System layers, 3 replicas of each file, referred as Extent, are maintained on 3 different servers partitioned between Update Domains and Fault Domains. Each write operations are performed Synchronously and control is returned only after the 3 copies completed the write, thus ensuring consistency.
Virtual Machine
Architecture Overview:

In Azure, Virtual Machines and the Hypervisor physical hosts are monitored and managed by the Fabric Controller(FC). The FC has the ability to detect failures in 2 modes: Reactive and Proactive. If the FC detects failures in reactive mode (Heartbeats missing) or proactive mode (known situations leading to a failure) from a VM or a hypervisor host, it will initiate a recovery by either redeploying the VM on a healthy host (same host or another host) and mark the failed resource as unhealthy and remove it from the rotation for further diagnosis. This process is also known as Self-Healing or Auto Recovery.
Summary:
With the approach Microsoft took when designing the Azure platform, Microsoft has built an Enterprise ready Cloud which provides a high level of resiliency. With this detailed concept of VM construct in mind, the discussion around HA workload might be slightly different for an Azure architecture compare to an on-prem architecture.
For example:
- Why and what type of availability is required for a specific workload within the Datacenter?
- How fast can the workload recover from a SAN storage outage?
- Can a workload recover automatically from a host failure?
- How many identical copies of my VM disks is maintained?
Note:
- This blog IS NOT a recommendation for managing your workloads High Availability(HA) in Azure. Guidance is provided here Manage the availability of virtual machines
- [Update] Microsoft does offer SLA for single instance VM with very specific requirements. Please visit the SLA for Virtual Machines webpage for more info.
References:
- Azure Resiliency Technical Guidance
https://azure.microsoft.com/en-us/documentation/articles/resiliency-technical-guidance/ - Windows Azure Storage: What’s Coming, Best Practices, and Internals
https://channel9.msdn.com/Events/Build/2013/3-541 - Service Healing - Auto-recovery of Virtual Machines
https://azure.microsoft.com/en-us/blog/service-healing-auto-recovery-of-virtual-machines/ - Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency
https://www-bcf.usc.edu/~minlanyu/teach/csci599-fall12/papers/11-calder.pdf
This posting is provided "AS IS" with no warranties and confers no rights.