Configuration of the Drill Cluster
NOTE This post is part of a series on a deployment of Apache Drill on the Azure cloud.
With our Azure resources deployed and the ZooKeeper ensemble up and running, we can now proceed with the installation and configuration of Drill. I've deployed four VMs on which I intend to run the Drill software. The steps that follow need to be performed on each of these in a consistent manner unless otherwise noted. Again, if I was a better shell scripter, I might automate this using the Azure CustomScript extension, but I know my personal limits :-) .
The actions I need to perform on each VM might be summarized as:
- Install Drill
- Configure the Drill Cluster
- Configure Drill to Start with the VM
- Confirm the Drill Cluster is Running
I will need to SSH into each of the VMs in order to perform these tasks.
Install Drill
My first action is to install the Java Runtime Engine:
sudo apt-get update
sudo apt-get -y install default-jre
Now I will create a directory for Drill and deploy the software to it. The complete list of mirrors for the Drill download are found here:
sudo mkdir /drill
cd /drill
sudo wget https://apache.mesi.com.ar/drill/drill-1.6.0/apache-drill-1.6.0.tar.gz
sudo tar -xvzf apache-drill-1.6.0.tar.gz
With the software unpacked into the appropriate directory, I now want to create a link that will hopefully make future updates easier and make sure ownership of the files consistently assigned to root:
sudo ln -s apache-drill-1.6.0/ current
sudo chown -R root:root /drill
Configure the Drill Cluster
Configuration of the Drill cluster is pretty simple. All I need to do is give the cluster a name and point the Drill server to the ZooKeeper nodes. This is done by making edits to the drill-override.conf file:
cd /drill/current/conf
sudo vi drill-override.conf
It is important that the cluster-id registered here is consistent across my Drill VMs and that this value is unique within the ZooKeeper ensemble. This is the fundamental mechanism by which these four servers will know to work together. With that in mind, I update the config file now open in vi to something like this:
drill.exec:{
cluster-id: "drillcluster001",
zk.connect: "zk001:2181,zk002:2181,zk003:2181"
}
At this point, the basic configuration of Drill has been done. I need to note that Drill by default will consume 8 GB of memory. As I have far more than that on these VMs, I should come back later and configure the software to use more of the available memory but for right now I want to focus simply on getting the software running.
Configure Drill to Start with the VM
I will assume that you have been reading this series of posts from top to bottom. If you have, then you are familiar with the basic steps I am using to get the service to start with the VM so that I'm not going to provide too much explanation or another apology for my shortcomings with Linux administration here:
sudo cp /drill/current/bin/drillbit.sh /etc/init.d/drillbit.sh
sudo vi /etc/init.d/drillbit.sh
In the vi editor, I comment out the top two bin variable assignments and hardcode my own value for bin:
#bin=`dirname "${BASH_SOURCE-$0}"`
#bin=`cd "$bin">/dev/null; pwd`
bin=/drill/current/bin
With updates to the script saved, I now tell the OS to launch the script on start up:
sudo update-rc.d -f drillbit.sh defaults
sudo update-rc.d -f drillbit.sh enable
Typically at this point I will launch the service using service drillbit.sh start and then verify the service has started using service --status-all. I have found that even though Drill launches successfully, the service --status-all command will show it in a stopped state. Not sure what's going on here but Drill is working regardless.
Confirm the Drill Cluster is Running
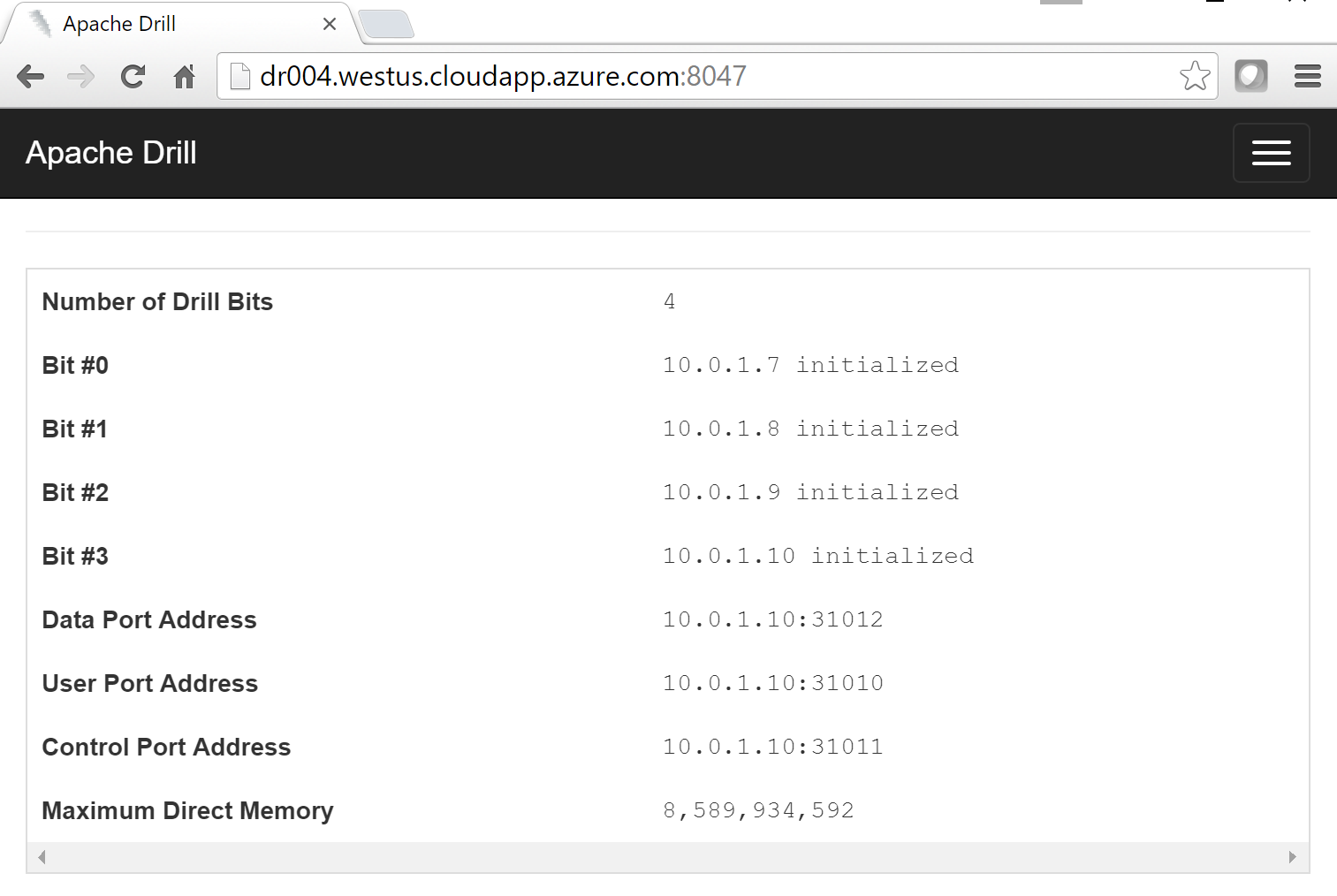
Once the previous actions have been completed on each VM, I restart each to launch the Drill software. At this point, I want to connect to Drill to verify it is working correctly. There are several ways to do this but I'm going to recommend you connect to the Drill Web Console on one of the Drill servers as this will provide you a clear sense of the status of your cluster and is needed later in your use of Drill.
I am going to connect to the Drill Web Console from my PC which sits outside the Azure Virtual Network into which I've deployed the cluster. In order to get through the VNet to Drill, I'll need to configure the Network Security Group associated with one of my Drill VMs to allow inbound traffic on TCP port 8047. As we previously used PowerShell to deploy our environment to Azure previously, I'll just use PowerShell again to do this. Here, I am opening up inbound TCP traffic to port 8047 on the dr004 VM:
$subscriptionName="my subscription name"
$resourceGroupName="drill"Login-AzureRmAccount
Set-AzureRmContext -SubscriptionName $subscriptionName$nsg = Get-AzureRMNetworkSecurityGroup -Name "dr004" -ResourceGroupName $resourceGroupName
$maxPriority=0
foreach($securityRule in $nsg.SecurityRules) {
if ($securityRule.Priority -gt $maxPriority) {$maxPriority=$securityRule.Priority}
}$maxPriority = $maxPriority+10
$nsg = Add-AzureRMNetworkSecurityRuleConfig -Name "drill-web-console" -Direction Inbound `
-Priority $maxPriority -Access Allow -SourceAddressPrefix '*' -SourcePortRange '*' `
-DestinationAddressPrefix '*' -DestinationPortRange "8047" -Protocol 'TCP'`
-NetworkSecurityGroup $nsg
Now I should have access to the Drill Web Console at https://dr004.westus.cloudapp.azure.com:8047. Please note that the fully qualified public name of my VM follows the form <vm name>.<region name>.cloudapp.azure.com. You will need to make appropriate substitutions based on the name of your VM and the region into which you deployed it.
Once connected, I should be presented with a home page which shows that I have 4 nodes in my Drill cluster: