Spark Job Submission on HDInsight 101
This article is part two of the Spark Debugging 101 series we initiated a few weeks ago. Here we discuss ways in which spark jobs can be submitted on HDInsight clusters and some common troubleshooting guidelines. So here goes.
Livy Batch Job Submission
Livy is an open source REST interface for interacting with Apache Spark remotely from outside the cluster. It is a recommended way to submit batch jobs remotely.
Livy Submission blog provides detailed explanation on how to submit livy jobs. We take one such example and detail on how to run it on our cluster and where to find relevant logs to debug some preliminary issues.
Note: For the sake of convenience, we are using postman to submit livy jobs here. Feel free to use curl to submit the same jobs.
Authorization: In our case this is basic authentication using your admin/Ambari credentials.
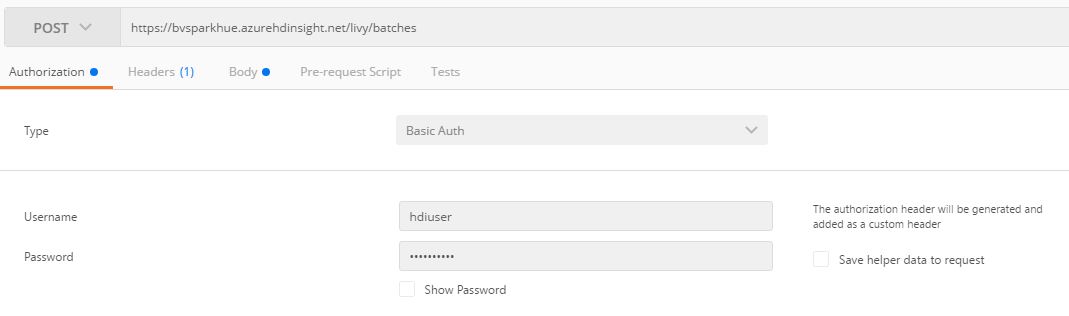 POST URL: The url to post the request to will be https://<your_cluster_name>/livy/batches
POST URL: The url to post the request to will be https://<your_cluster_name>/livy/batches
[ Note the using of secure connection here. Https is necessary. ]
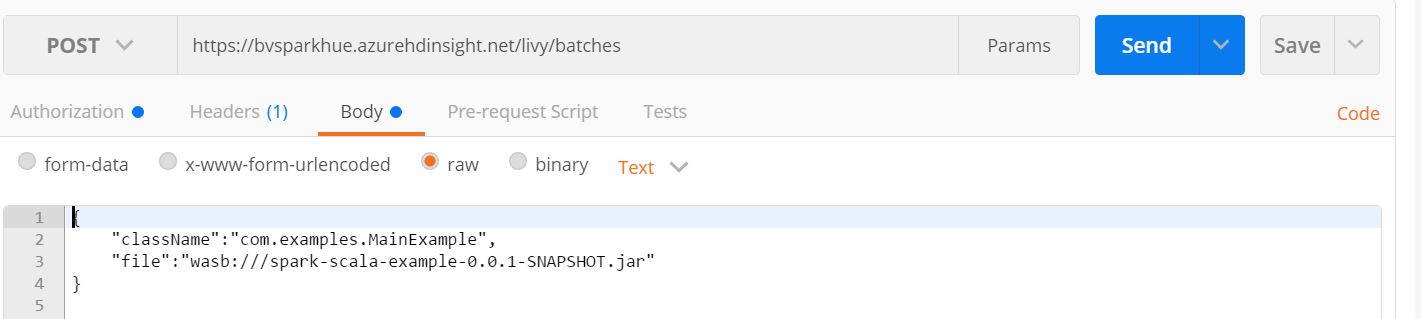
Body: These are the arguments that you pass to your spark job. It is passed in the form of json. At the least you will need className which indicates the main class to be run and the source jar. For a detailed explanation on the arguments that you can pass in please refer to this github link.
 Finding the job in yarn: Job submitted through yarn will be submitted as user:spark under the name "Livy". So by clicking on the running jobs, you should be able to easily locate this job on your cluster. Further log analysis on yarn would be very similar to spark-submit log analysis explained in the section above.
Finding the job in yarn: Job submitted through yarn will be submitted as user:spark under the name "Livy". So by clicking on the running jobs, you should be able to easily locate this job on your cluster. Further log analysis on yarn would be very similar to spark-submit log analysis explained in the section above.
 Livy Specific Logs: Livy specific logs are logged in /var/log/livy on the headnode of the cluster. If livy was not able to submit your job to spark, it will log all debug information here. In case the job got submitted, a spark-submit corresponding to this job will be logged here.
Livy Specific Logs: Livy specific logs are logged in /var/log/livy on the headnode of the cluster. If livy was not able to submit your job to spark, it will log all debug information here. In case the job got submitted, a spark-submit corresponding to this job will be logged here.

Interactive Shells
Spark introduces two shell interpreters Pyspark and Spark-shell to allow users to explore data interactively on their cluster. These executables can be run by ssh into the headnode. These shells are often the simplest way to learn spark APIs. "pyspark" executable launches a Python interpreter that is configured to run spark applications while spark-shell does the same for Scala applications.
Pyspark Launcher: pyspark  Spark Scala Launcher: spark-shell
Spark Scala Launcher: spark-shell 
Just like hive or any interactive shell, both these interpreters dump results and logs to stdout. This should help in preliminary debugging and validating the output.
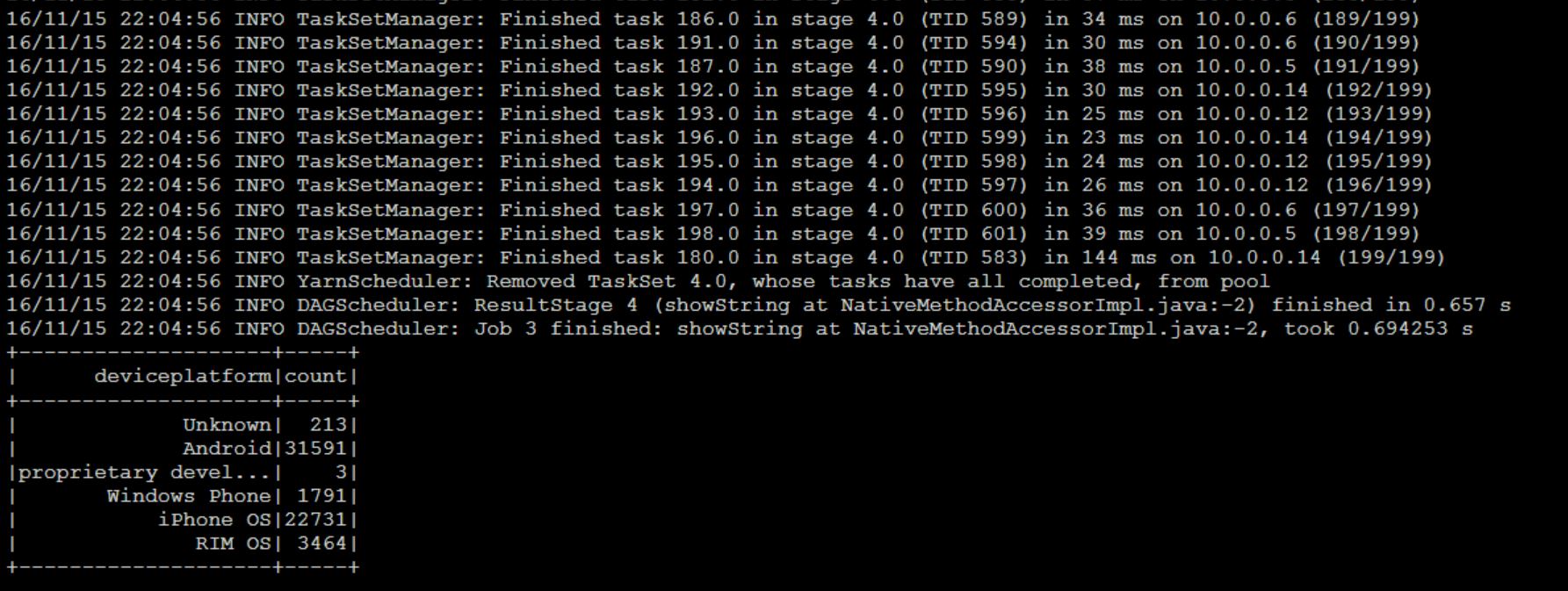
Each of these shells run through Thrift server on Yarn. So once you launch any command on these shells you should see a new process launched in yarn in their respective name.
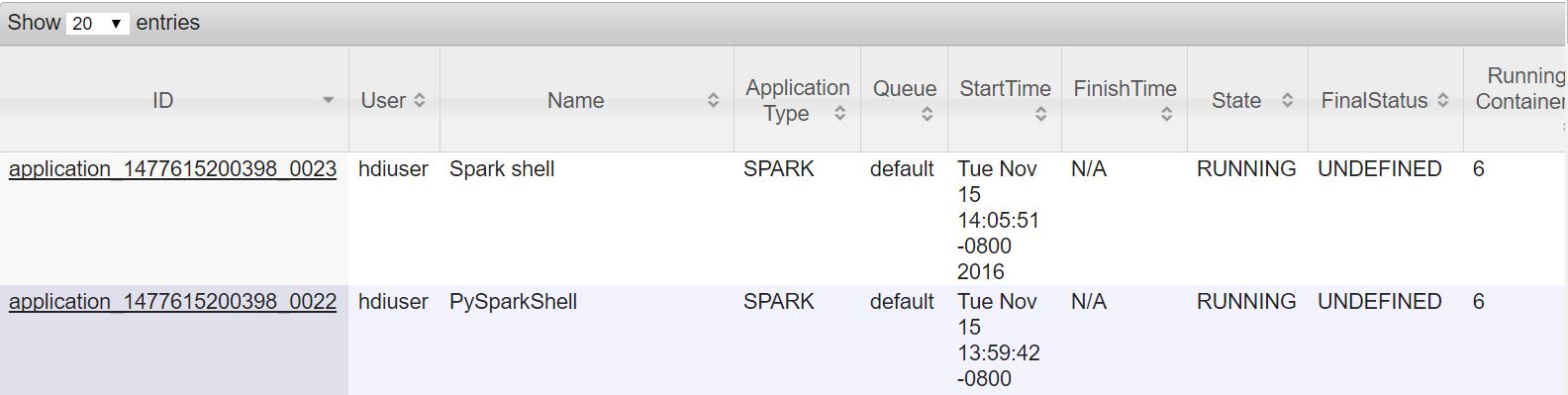
Further debugging these applications can be done similar to the details in the general debugging section.
Jupyter Notebooks
Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text. HDInsight supports jupyter out of the box to help in building interactive applications. This helps data scientists visualize results on each step to provide a true interactive experience.
This MSDN article provides a quick easy-to-use onboarding guide to help get acclimatized to Jupyter. You can also try several applications that come pre-installed on your cluster to get hands on experience of jupyter.
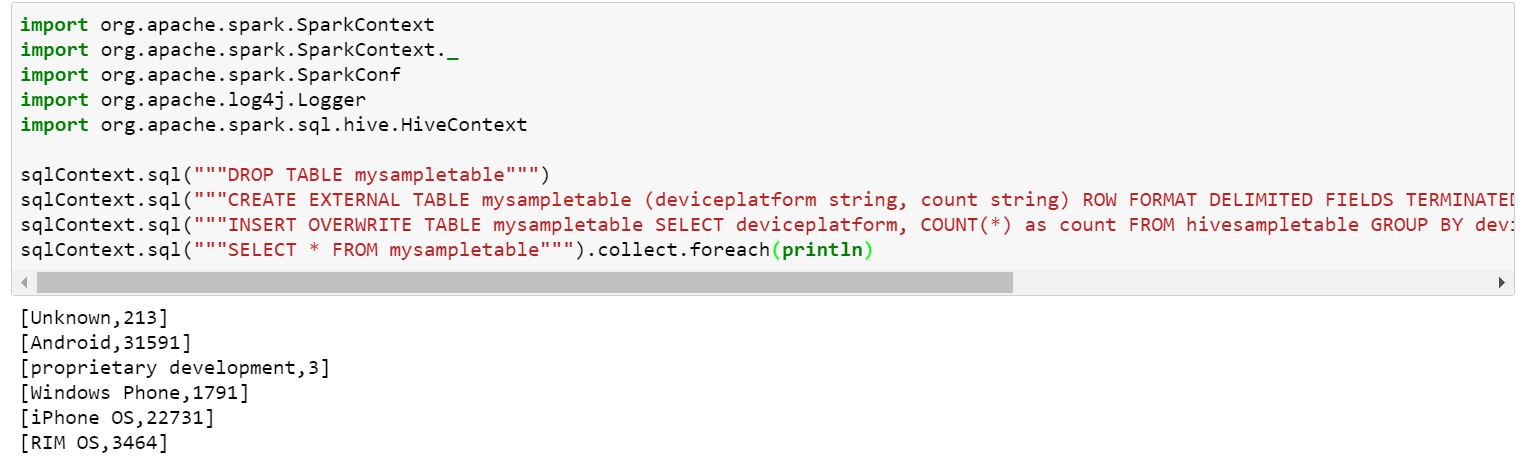
Jupyter notebook creates a SparkContext and HiveContext by default on running the first cell in jupyter. Spark Context can be utilized in your notebook as 'sc' and HiveContext can be utilized as 'sqlContext'. Just like in spark-submit, you can pass custom arguments that will be valid for the context of the entire notebook run.

It is important to note that this configure needs to be the first cell in your jupyter notebook for this to effect. To rephrase, params should be given to the notebook before it creates the spark context.
Similarly, to pass custom configurations, use the 'conf' construct inside configure and to pass custom jars, use 'jars' construct. The properties passed to jupyter follow the same syntax as livy described here.
Running applications:
Depending on the language of your development, you can chose either the pyspark or the spark kernels. Spark represents Scala notebooks while pyspark represents Python notebooks. Inside the notebook, you can key in your code and pressing Shift+Enter will run the application and give you the result right below the cell.
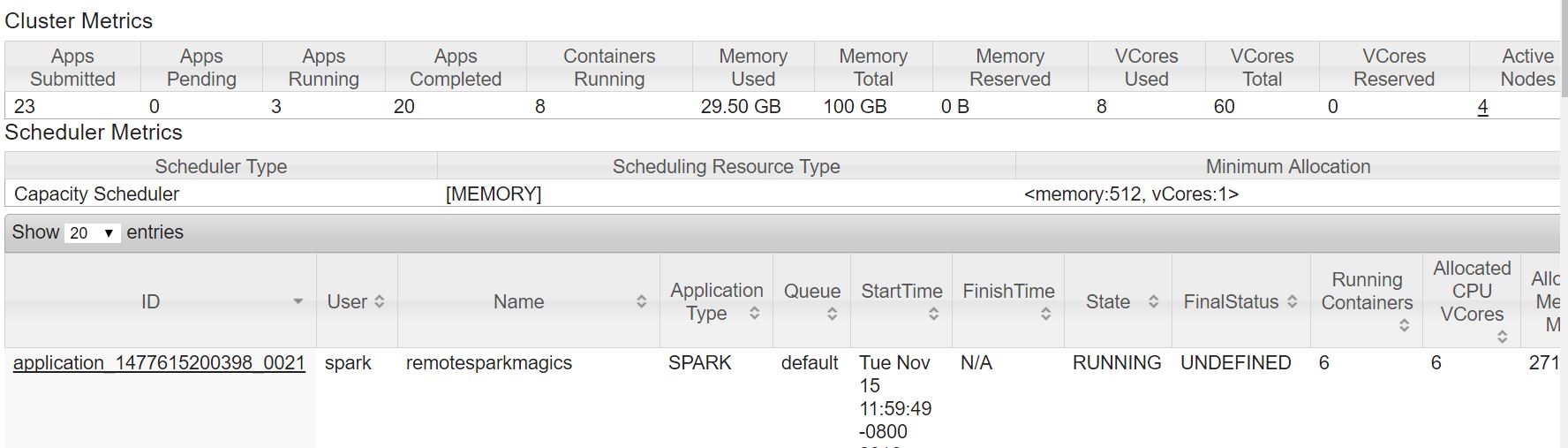
Finding my notebook application in yarn:
In HDI 3.4 all notebook applications were named as "remotesparkmagics". So finding your notebook would mean finding an application named "remotesparkmagics" in yarn running applications.
In HDI 3.5 and further, each running jupyter session has a session number and it is appended to your session name. So if this is the first session you have ever opened in notebook, then your session will be named livy-session-0 and livy-session-1 for the next and likewise.
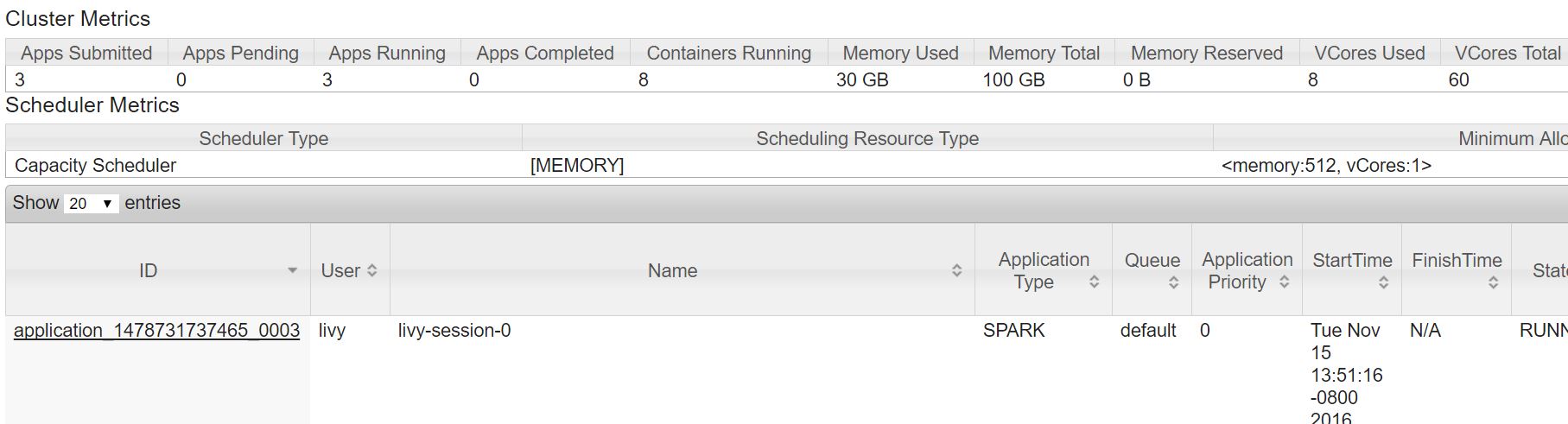
Finding jupyter specific logs:
Jupyter inturn runs as a livy session so most of the logging we discussed for livy and spark-submit sections will hold true for jupyter too. Additionally, In HDI 3.4 clusters, you can track the spark-submit command that your jupyter cell ran in /var/log/livy/livy.log.

All jupyter specific logging will be redirected to /var/log/jupyter.
Zeppelin Notebooks
From HDI 3.5 onwards, our clusters come preinstalled with Zeppelin Notebooks. Much like Jupyter notebooks, Zeppelin is a web-based notebook that enables interactive data analytics. It provides built-in Spark intergration that allows for:
- Automatic SparkContext and SQLContext injection
- Runtime jar dependency loading from local filesystem or maven repository. Learn more about dependency loader.
- Canceling job and displaying its progress
This MSDN article provides a quick easy-to-use onboarding guide to help get acclimatized to Zeppelin. You can also try several applications that come pre-installed on your cluster to get hands on experience of Zeppelin.
Although Zeppelin and Jupyter are built to accomplish similar goals, they are inherently very different by design and common misconceptions arise from users mixing both these syntaxes.
Zeppelin by default shares its interpreters which means the Spark Context you initiated in notebook1 can be used in notebook2. This also means that variables declared in Notebook1 can be used in Notebook2. This functionality can be changed using interpreter settings by changing the default shared context setting to isolated. When set to isolated, each notebook instantiates its own interpreter.
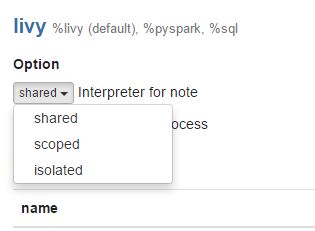
We can set livy properties like executor instances, memory, cores etc using the same interpreter settings.
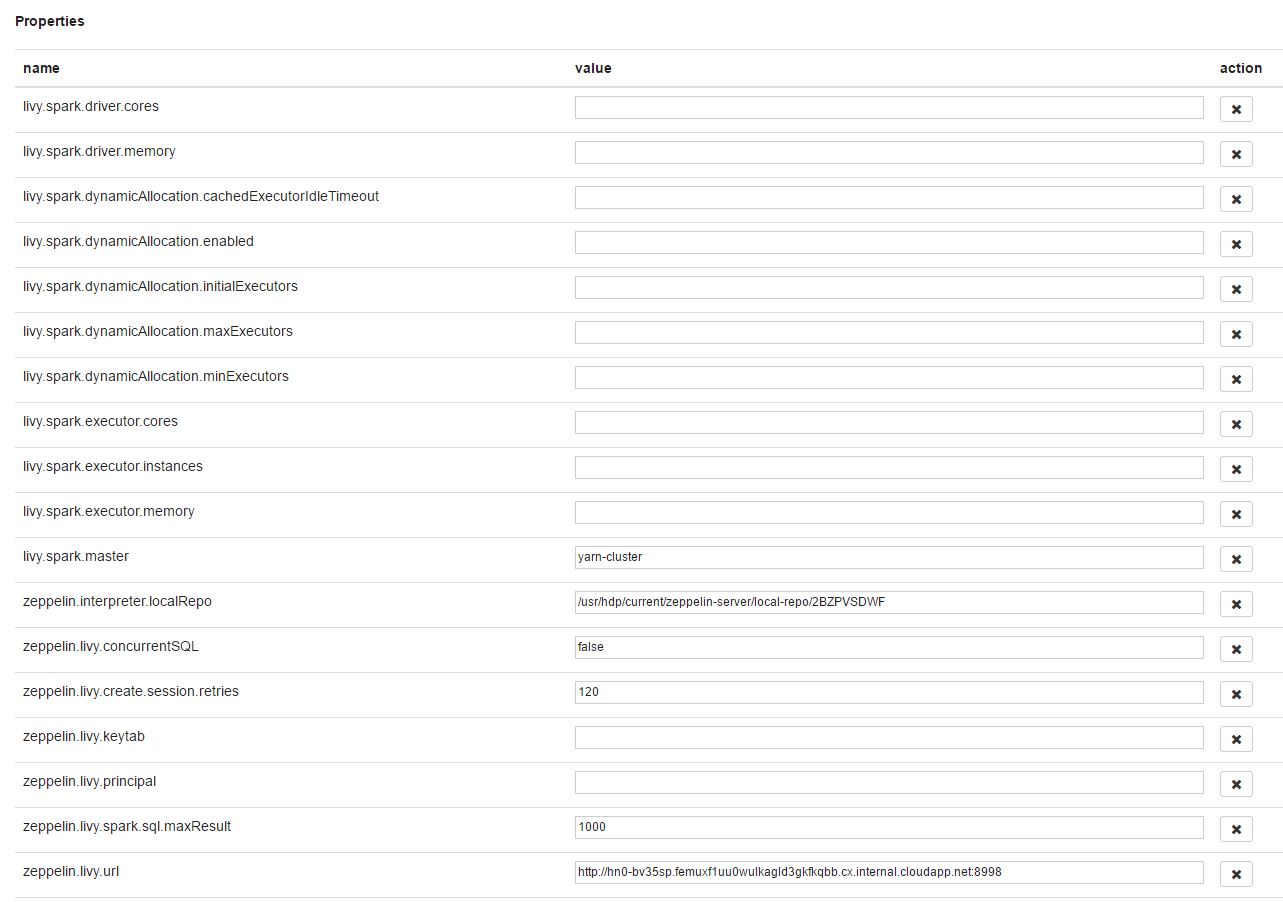
Apart from the predefined settings, you can add your custom settings at the bottom of the properties list and can add dependencies that you need to be added to the classpath when the interpreter starts.
For a full set of configurations that can be set, please refer to Spark Additional Properties
Irrespective of whether the interpreter is shared or isolated, livy properties are shared between all notebooks which means all notebooks and interpreters get the same settings.
Finding my logs and Notebook in Yarn
Similar to HDI 3.5 Jupyter, each running zeppelin session has a session number and it is appended to your session name. So if this is the first session you have ever opened in notebook, then your session will be named livy-session-0 and livy-session-1 for the next and likewise.
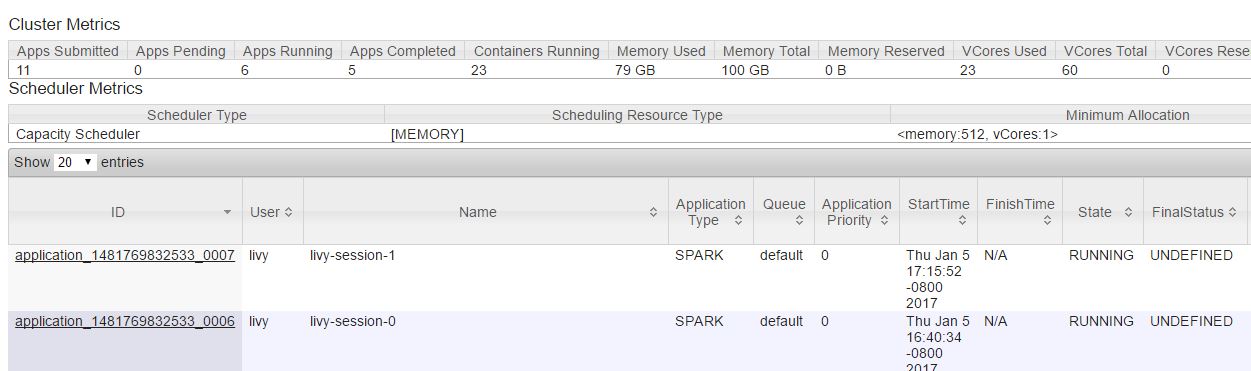
Logging in zeppelin remains similar to jupyter and all logs are stored in /var/log/zeppelin on the headnode.
Thats it for today folks. In the next article we will discuss some of the most common issues that users face with Spark on HDInsight and some common tips and tricks to navigate them hassle free.
Related Articles
This is the first part of this Spark 101 series Spark Debugging 101
Comments
- Anonymous
August 30, 2017
Is there any way to authenticate using token when submitting Spark Job into Azure HDI cluster? We have application submitting .jar file and it doesn't seems keeping the user name and password in the application config.