Checklist for production-ready AI models
Creating AI models is more than training and validating a model. This article summarizes key requirements for production-ready models.
💡Model development checklist:
- Datasets are versioned, centrally available and discoverable. Also full lineage of features and engineering is captured.
- Models trained are versioned, centrally available and discoverable.
- Unit and integration tests have been applied to the training and inference pipeline. Also static seeds applied where relevant, to ensure near identical and reproducible results.
- A consistent scoring and evaluation approach has been implemented.
- Performance and parallel processing improvements are designed, tested, monitored and partially implemented and tested. Compute environments are explored for optimum results.
The following sections describe more elements of developing high-quality production models.
Feature management
Much of the complexity in developing ML systems is in data preparation and data normalization for feature engineering workflows. Feature management enables accessing features by name, model version, lineage, etc., in a uniform way across environments. Using feature management provides consistency to help improve developer productivity. It also promotes discoverability and reusability of features across teams.
For more information, see Feature Management
Understanding machine learning pipelines
A machine learning pipeline is an automated process that generates an AI model. In general, it can be any process that uses machine learning patterns and practices or a part of bigger ML process. It’s common to see data preprocessing pipelines, scoring pipelines for batch scenarios, and even pipelines that orchestrate training based on cognitive services. Therefore, an ML pipeline should be understood as a set of steps that is sequential or in parallel, where each step is executed on a single or multiple nodes (to speed up some tasks). The pipeline itself defines the steps and configures the compute resources needed to execute the steps and access-related datasets and data stores. To keep things simple, a pipeline typically is built with a well-defined set of technologies and/or services.
If a pipeline is properly configured, regenerating a model is simple and reliable. If the same training dataset is used each time the pipeline runs, the quality of the model should be similar. The importance of a given model artifact is thus reduced, as it can be regenerated. (We are not yet discussing model deployment.)
Datasets are important from many different perspectives, including traceability, data labeling, and data drift detection. While each of these topics is complex, we'll make some simplified assumptions for this article.
- A single, immutable dataset in a fixed location.
- Dataset and hyperparameters can be passed to the ML pipeline as a parameter.
Consider the following example: We need to train a model to find some bad pixels in raw video frames. In most real-world scenarios, raw data must be preprocessed before they can be used to train models. In this example, raw video files first need to be decomposed into raw video frames, and more preprocessing is likely to be required for each frame. Other processing includes selecting statistically relevant training data, extract features, and so on. Only when all data curation/preparation steps are finished can model training begin.
It is not uncommon for pre-processing to take more time than training itself. We might mitigate this time by running pre-processing on several compute nodes at the same time. This mitigation requires an updated pipeline to split processing into multiple steps that execute in different environments. For example, using multi-node clusters or single-node clusters, or GPU nodes versus CPU nodes. If we use a diagram to design our pipeline, it might look like this:
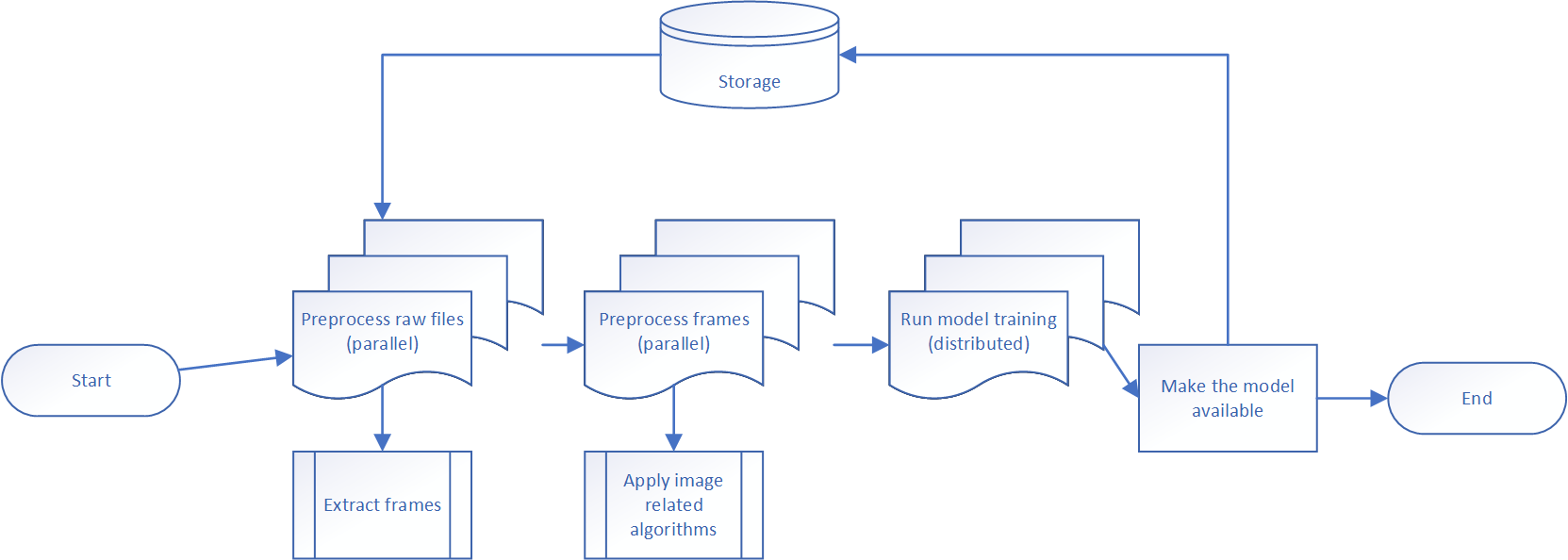
In this pipeline, there are four sequential steps:
- The first step is executed in parallel on several nodes to convert all available video files into images.
- The second step also runs in parallel, but it might use a different number of nodes because we have more images to pre-process than we had raw video files.
- One more step is training itself, which can also use a distributed approach (for example, Horovod or Parameter Server).
- Finally, we have a single node step to log the model into storage.
This example illustrates why a robust ML pipeline is required rather than a simple build script or manually run process. Let’s discuss technologies.
Building a pipeline with the Azure Machine Learning service
There are many different technologies to implement a pipeline. For example, it's possible to use Kubeflow as a framework for pipeline development and Kubernetes as a compute cluster. Databricks and MLFlow can be utilized as well. At the same time, Microsoft offers a service to develop and manage machine learning pipelines (jobs): Azure Machine Learning service. Let's take Azure ML as an example of a technology to implement our generalized pipeline.
Azure ML has several important components that are useful for pipeline implementations:
- Azure ML SDK for Python and Azure ML CLI: To create all Azure ML components and communicate to Azure ML service.
- Azure ML Compute: The ability to create and manage clusters to execute pipeline steps there. It can be just one cluster for all steps or different clusters per step. There is a way to mount storage to compute cluster instances, and we are going to use this feature implementing our pipeline steps.
- Azure ML Model Registry: Azure Machine Learning provides a managed API to register and manage models. A model is a single file or a folder with a set of files with included version tracking.
- **CommandJob Class: It's possible to implement single instance jobs, batch workloads or distribute training jobs.
Let’s show how our generalized pipeline will look from a technologies perspective:
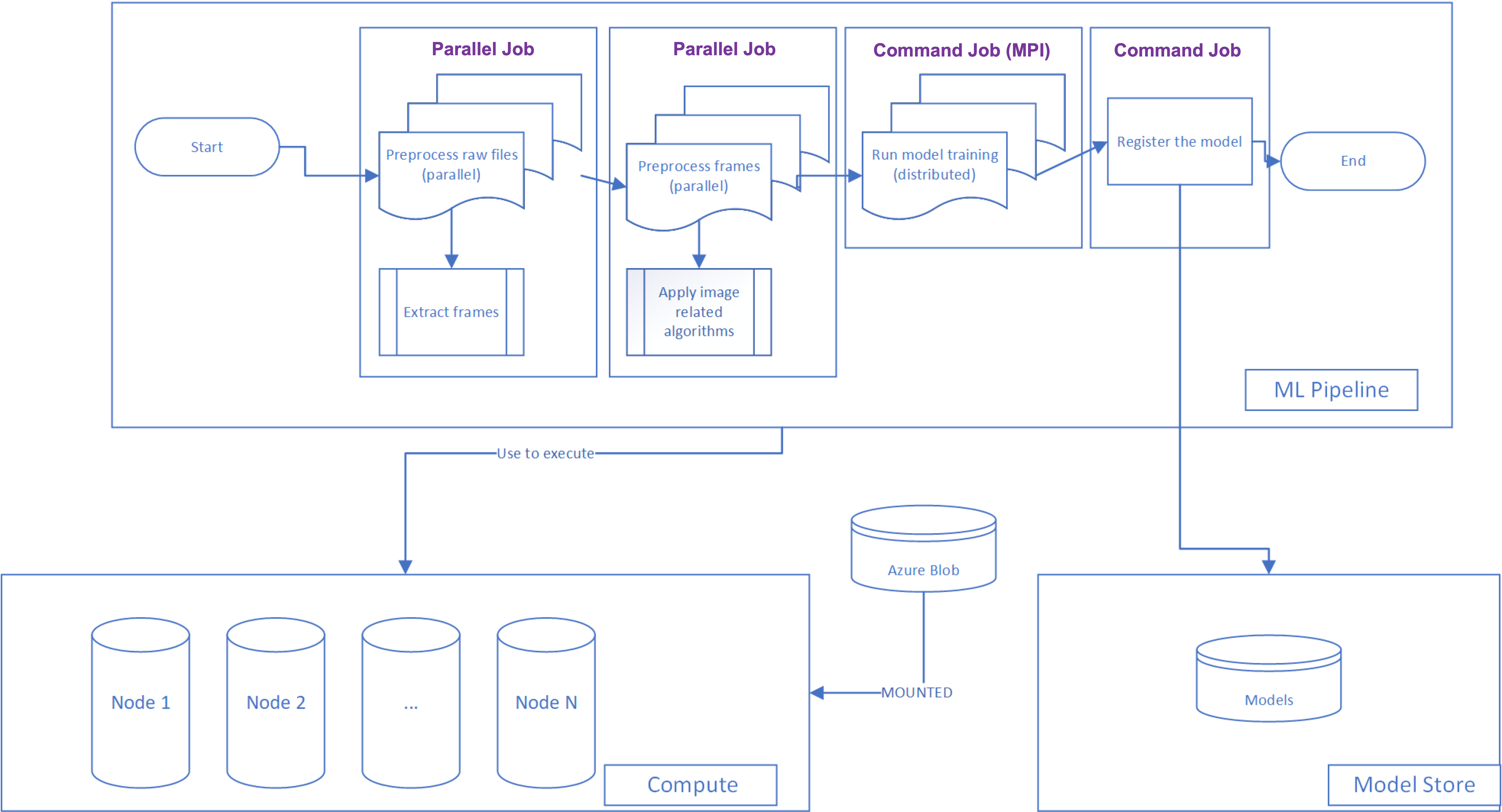
When to implement an ML pipeline
Data scientists generally prefer using Jupyter Notebooks for Exploratory Data Analysis and initial experiments.
Requiring the use of pipelines at this stage may be premature, as it could limit the data scientists technology choices and overall creativity. Not every Jupyter notebook is going to create a need for a production pipeline, as the data scientists need to test many different approaches and ideas before converging on an approach. Until that work is done, it is hard to design a pipeline.
While the initial experimentation can be done in a notebook, there are some good signals that tell when it is time to start moving experiments from a notebook to an ML pipeline:
- The approach and code are stabilizing, meaning it's reasonable to begin transitioning from research to development.
- Data scientists are ready to share the same code and experiment with different parameters.
- Data scientists need more compute resources since a single VM or a local computer is no longer sufficient.
When these things begin happening, it’s time to wrap up experimentation and implement a pipeline with technology such as the Azure ML Pipeline SDK.
We recommend following a three-step approach:
- Step 1. Refactor the notebook into clean Python code. The primary goal being to move all methods/classes to separate Python files to make them independent from the execution environment.
- Step 2. Convert the existing notebook to a single step pipeline. You can use the following guideline to create a single-step pipeline to execute on a single instance only. The only difference is it is your own code in
train.py. At this stage, you will see how the pipeline works and be able to define all datasets/datastores and parameters as needed. Starting from this stage you are able to run several experiments of the pipeline using different parameters. - Step 3. Identify critical blocks in the pipeline and move them to different steps. The primary reason for this step is to make your pipeline faster. You need to identify your clusters (GPU or non-GPUs and VM sizes) and the kinds of steps to use to wrap components from your code (single, parallel or distributed TF/PyTorch etc.).
Here is an example of an Azure ML pipeline definition: https://github.com/microsoft/mlops-basic-template-for-azureml-cli-v2/blob/main/mlops/nyc-taxi/pipeline.yml. This YAML file defines a series of steps (called "jobs" in the YAML) consisting of the Python scripts which execute a training pipeline. The examples follow this sequence of steps (you may not use all of the steps):
prep_job, which processes and cleans the raw datatransform_job, which shapes the cleansed data to match the training job's expected inputstrain_job, which trains the modelpredict_job, which uses a test set of data to run a set of predictions through the trained modelscore_job, which takes the predictions, and scores them against the ground truth labels.
Each of these steps references a Python script, which was likely once a set of cells in a notebook. Now, they consist of modular components that can be reused by multiple pipelines.
The full template is available in the MLOps Basic Template for Azure ML CLI v2 repo:
Here are other similar templates:
Development process implementation
From a DevOps perspective the development process can be divided into three different stages:
- Publish and Execute a pipeline from a local computer (or VM) using the full dataset or just a subset of data. Usually, it’s happening from a local feature branch where a developer or a data scientist is tuning the pipeline. Note, we are executing the pipeline from a local computer rather than on a local computer.
- Create and validate Pull Request for changes from a feature branch towards to the development branch.
- Publish and execute the pipeline in the development environment based on the full dataset.
There are a few pieces of advice that we can provide:
- Host all different parameters that are required for pipeline publishing as environment variables. In this case, you will be able to initialize your local environment and publish the pipeline from a local computer. Or, you can use a variable group in your favorite DevOps system to publish the pipeline from there.
- Make sure the pipeline includes needed files only rather than everything from the repository. For example, Azure ML supports
.amlignorefile. - Use branch names and build IDs to enable developers modifying the pipeline simultaneously (see below).
Branch name utilization
The biggest challenge of the ML pipeline development process is how to modify and test the same pipeline from different branches. If we use fixed names for all experiments, models, and pipeline names, it will be hard to differentiate your own artifacts working in a large team. To make sure we can locate all feature branch-related experiments, we recommend using the feature branch name to mark all pipelines. Also, use the branch name in experiments and artifact names. This way, it will be possible to differentiate pipelines from different branches and help data scientists to log various feature-branch runs under the same name.
The designed scripts can be utilized to publish pipelines and execute them from a local computer or from a DevOps system. Below is an example of how you can define Python variables based on initial environment variables and on a branch name:
pipeline_type = os.environ.get('PIPELINE_TYPE')
source_branch = os.environ.get('BUILD_SOURCEBRANCHNAME')
model_name = f"{pipeline_type}_{os.environ.get('MODEL_BASE_NAME')}_{source_branch}"
pipeline_name = f"{pipeline_type}_{os.environ.get('PIPELINE_BASE_NAME')}_{source_branch}"
experiment_name = f"{pipeline_type}_{os.environ.get('EXPERIMENT_BASE_NAME')}_{source_branch}"
You can see that in the code above we are using branch name and pipeline type. The second one is useful if you have several pipelines. To get a branch name from a local computer, you can use the following code:
git_branch = subprocess.check_output("git rev-parse --abbrev-ref HEAD",
shell=True,
universal_newlines=True)
Pull request builds
Let’s start with introduction of two branch types that we are going to use in the process:
- Feature branch: any branch owned by a developer to develop a feature. Since we are not planning to preserve and manage this branch, the developer has to decide how to name the branch.
- Development branch: it’s our primary source for all feature branches and we treat it as a stable development environment that we are using to run our experiments on the full dataset. Potentially, the development branch and a current model can be a good candidate for production at any point in time.
So, we need to start with a feature branch. It's important to guarantee that all code that is going to a development branch can represent working ML training pipelines. The only way to do that is to publish the pipeline and execute the pipelines on a toy data set. The toy dataset should be prepared in advance. It should be small enough to guarantee the pipelines won't spend much time on execution. Therefore, if we have changes in our ML training pipeline, we have to publish it and execute it on the toy dataset.
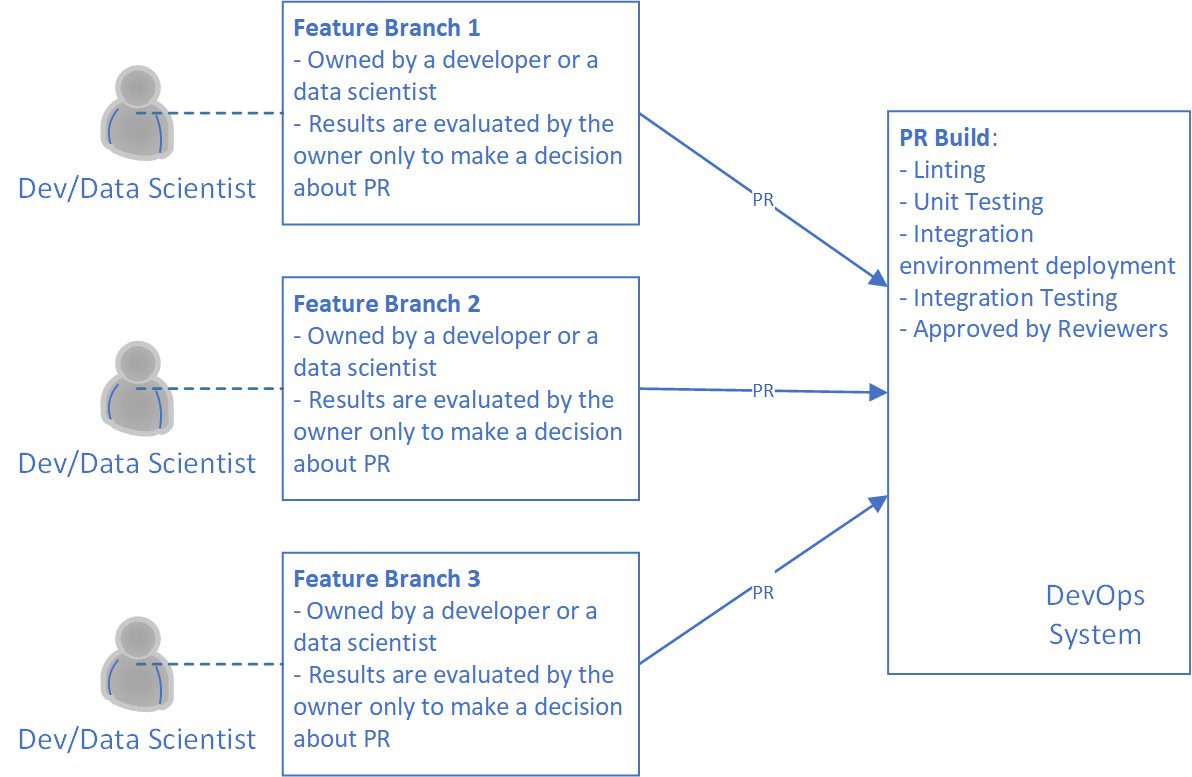
The diagram above demonstrates the process that we explained in the section. Furthermore, you can see that there is a Build for Linting and Unit Testing. This Build can be another policy to guarantee code quality.
Pay attention so that if you have more than one pipeline in the project, you might need to implement several PR Builds. Ideally, one Build per pipeline, if it's available in your DevOps system. Our general recommendation is to have as many Builds for as many pipelines as we have. It allows us to speed up the development process since developers shouldn't wait for all experiments to be done. In some cases, it’s not possible.
Development branch Builds
Once we have code in our development branch, we need to publish modified pipelines to our stable environment, and we can execute it to produce all required artifacts (models, update scoring infrastructure, etc.)
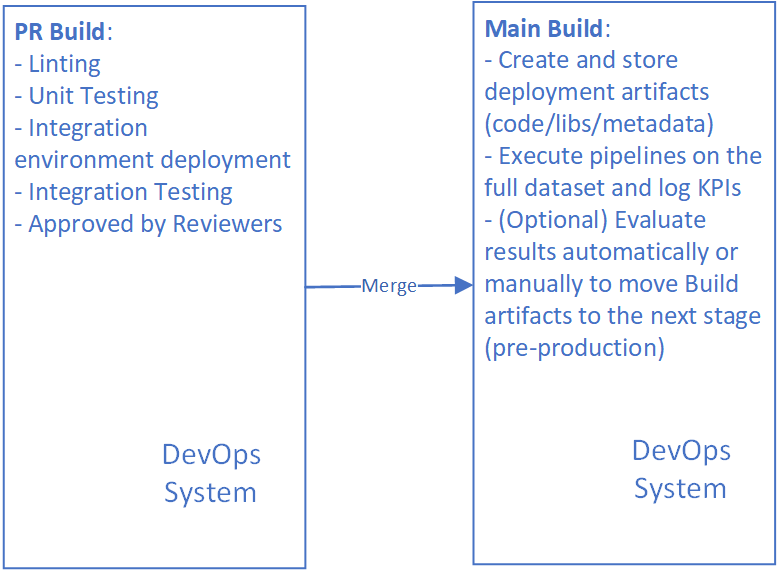
Pay attention that our output artifact on this stage is not always a model. It can be a library or even our pipeline itself if we are planning to run it in production (scoring one, for example).
Look at the Model Release section to get details about next steps.
Unit testing for ML pipelines
When unit testing we should mock model load and model predictions similarly to mocking file access.
There may be cases when you want to load your model to do smoke tests, or integration tests.
Note, it will often take a bit longer to run it's important to be able to separate them from unit tests. The developers on the team will still be able to run unit tests as part of their test-driven development.
One approach is using marks
@pytest.mark.longrunning
def test_integration_between_two_systems():
# this might take a while
Run all tests that are not marked long-running
pytest -v -m "not longrunning"
Basic Unit Tests for ML Models
ML unit tests are not intended to check the accuracy or performance of a model. Unit tests for an ML model are for code quality checks - for example:
- Does the model accept the correct inputs and produce the correctly shaped outputs?
- Do the weights of the model update when running
fit?
The ML model tests do not strictly follow all of the best practices of standard Unit tests; not all outside calls are mocked. These tests are much closer to a narrow integration test. However, the benefits of having simple tests for the ML model help to stop a poorly configured model from spending hours in training, while still producing poor results.
Examples of how to implement these tests (for Deep Learning models) include:
- Build a model and compare the shape of input layers to that of an example source of data. Then, compare the output layer shape to the expected output.
- Initialize the model and record the weights of each layer. Then, run a single epoch of training on a dummy data set, and compare the weights of the "trained model"; only check if the values have changed.
- Train the model on a dummy dataset for a single epoch, and then validate with dummy data. Only validate that the prediction is formatted correctly, this model will not be accurate.
Data Validation
An important part of the unit test is to include test cases for data validation.
For example:
- No data is supplied.
- Images are not in the expected format.
- Data containing null values or outliers to make sure that the data processing pipeline is robust.
Model Testing
Apart from unit testing code, we can also test, debug, and validate our models in different ways during the training process.
Some options to consider at this stage:
- Adversarial and Boundary tests to increase robustness
- Verifying accuracy for under-represented classes
AI/ML systems adversarial threat modeling
Running AI/ML systems in production expose companies to a brand-new class of attacks. The following attacks should be considered:
- Model stealing (extraction): Adversaries can recreate a model that could be used offline to craft evasion attacks or just as it is.
- Model tricking (evasion): Adversaries can modify model queries to get a desired response.
- Training data recovery (inversion): Private training data can be recovered from the model.
- Model contamination to cause targeted or indiscriminate failures (poisoning): Adversaries can corrupt training data to misclassify specific examples (targeted) or to make the system unavailable (indiscriminate).
- Attacking ML supply chain: Adversaries can poison third-party data and models.
These attacks should be carefully considered. For information on adversarial attacks and how to include them in the threat modeling process, follow the links below:
Failure Modes in ML | Microsoft Docs
Threat Modeling AI/ML Documentation | Microsoft Docs
Video processing pipeline example based on Azure AI Services
As we mentioned above, there are many technologies to use to implement a generalized pipeline. In this example, we show a pipeline implementation based on Microsoft Azure AI Services.
This example contains an AI enrichment pipeline, the pipeline is triggered by the upload of a binary file to an Azure Storage account. The pipeline will "enrich" the file with insights from various Azure AI Services, custom code, and Video Indexer before submitting it to a Service Bus queue for further processing.
The entire end-to-end pipeline illustrates the flow data: From ingestion, to enrichment, to training, to inference for use with unstructured data such as videos, documents, and images.
The image below illustrates the high-level system architecture:
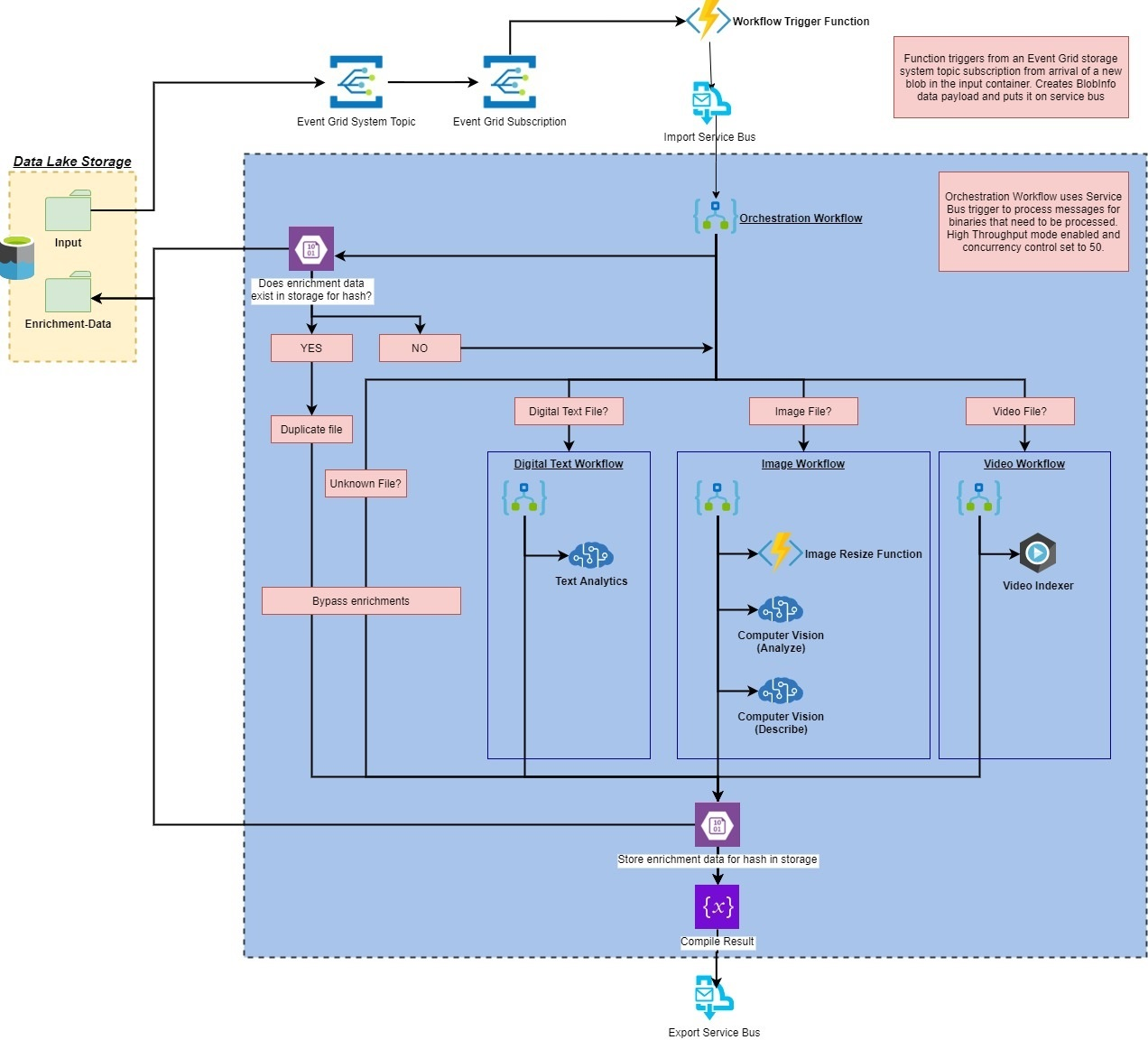
The full example and source code may be found in the Official Azure Media Services | Video Indexer Samples repository