Visores e conteúdo
A Manipulação Direta usa visores, conteúdo econtatos para descrever os elementos interativos da interface do usuário.
- Configurando um visor
- Ajustar pontos e limites
- Deslocamento de ponto de ajuste e cenários RTL
- Comportamentos
- Sistema de coordenadas
- Transformações
- Estado do visor
- Tópicos relacionados
Um visor é uma região dentro de uma janela que pode receber e processar entradas de interações do usuário. O visor representa a região do conteúdo que pode ser vista pelo usuário final em um determinado momento (também chamado de clipe de conteúdo). O visor tem várias funções:
- Ele gerencia o estado de interação (por exemplo, quando o conteúdo está pronto para ser manipulado, quando o conteúdo está passando por manipulação, quando o conteúdo está em animação de inércia) e mapeia a entrada para transformações de saída.
- Ele contém conteúdo que se move em resposta à interação do usuário. Pode ser um elemento HTML div (rolagem), uma lista pan-able (a tela inicial do Windows 8) ou o menu pop-up de um controle de seleção.
Um visor é criado chamando CreateViewport. Vários visores podem ser criados em uma única janela para produzir uma experiência de interface do usuário avançada.
O conteúdo representa o elemento que é transformado em resposta a uma interação. Em outras palavras, o conteúdo é o que se move ou dimensiona à medida que o usuário pressiona ou pinça. Há dois tipos de conteúdo:
- O conteúdo primário é o único elemento intrínseco dentro de um visor que responde a manipulações de entrada e inércia. O conteúdo primário é criado ao mesmo tempo que o visor e não pode ser adicionado ou removido de um visor. Você pode personalizar o comportamento do conteúdo primário usando pontos de ajuste (discutidos posteriormente).
- O conteúdo secundário se move em relação ao movimento do conteúdo primário. O conteúdo secundário é criado separadamente do visor e pode ser adicionado ou removido de um visor. Todas as transformações de conteúdo secundário são calculadas com base na transformação do conteúdo primário. Regras específicas podem ser aplicadas para alterar a forma como a transformação é calculada com base na finalidade pretendida do elemento, identificado por seu CLSID durante a criação.
Neste diagrama mostrando antes e depois de uma panorâmica, um único contato foi usado para aplicar panorâmica ao conteúdo primário. Embora o usuário não esteja interagindo diretamente com o indicador de movimento panorâmico (conteúdo secundário), o conteúdo secundário se move à medida que o conteúdo primário é exibido. Isso fornece indicações visuais de quão longe o usuário fez panned.

Configurando um visor
Depois de criar o visor. configurar seu comportamento usando uma configuração de interação. A configuração de interação especifica quais manipulações, como movimento panorâmico, têm suporte.
O movimento panorâmico altera a posição do conteúdo ao longo do eixo horizontal ou vertical ou ambos como painéis de usuário. Quando você configura a tradução em ambos os eixos, o conteúdo se move livremente em qualquer direção.
Para restringir o movimento do conteúdo, configure trilhos, normalmente no eixo horizontal e vertical. Se a interação de um usuário estiver principalmente ao longo de um único eixo (representado pelas regiões azuis no próximo diagrama), a panela se tornará gradeda e o conteúdo se moverá apenas ao longo do eixo ferroviário. Se o usuário tiver feito movimento panorâmetro e estiver atualmente preso e executar uma segunda panorâmica enquanto o conteúdo estiver em inércia, a nova panela continuará a ser pressionada.
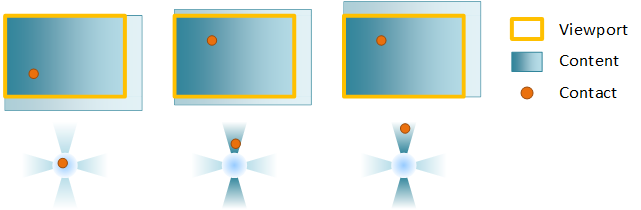
Exemplo: um visor está configurado para movimento panorâmico horizontal e vertical. No primeiro quadro, o contato cai. No segundo, uma panela vertical é iniciada e o contato é bloqueado para o trilho vertical. Por fim, depois que a panela é gradeda, apenas o componente vertical de uma panela diagonal é usado para mover o conteúdo.
Se o usuário for panorâmica diagonalmente de uma forma que não esteja nas regiões de detecção de trilhos (as regiões brancas), a panela ficará sem corrimão e o conteúdo será movido livremente em ambos os eixos.
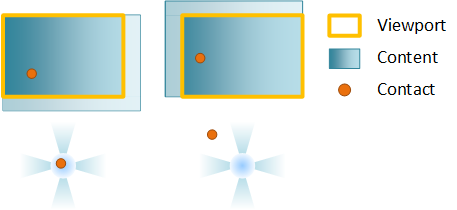
O zoom altera o fator de escala do conteúdo à medida que um usuário pinça ou se alonga. O ponto em torno do qual o conteúdo é dimensionado (chamado de centro de zoom) está no centro dos contatos. Se você definiu o alinhamento horizontal ou vertical, o centro de zoom será alterado para preservar o alinhamento.
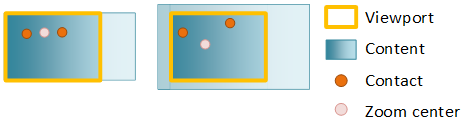
Você pode substituir esse comportamento especificando o centro de desbloqueio, que define o centro de zoom no centro dos contatos.
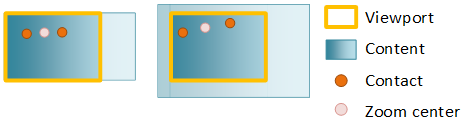
Inércia é a desaceleração gradual de uma manipulação, movimento panorâmico e zoom, depois que todos os contatos tiverem sido levantados (no caso de toque) ou após a entrada do teclado/mouse (como clicar em uma barra de rolagem ou pressionar as teclas de direção). Quando um usuário manipula o conteúdo, a manipulação não para imediatamente depois que o contato é retirado. Em vez disso, o conteúdo continua na direção e velocidade atuais, desacelerando gradualmente até uma parada.
Ajustar pontos e limites
Uma animação de inércia ocorre depois que a manipulação termina como resultado de um dedo sendo retirado da tela (no caso de toque) ou como resultado de uma ação de teclado/mouse (como teclas de direção, página para cima/para baixo, rolagem da roda do mouse etc.).
Há duas informações que definem a animação de inércia:
- O ponto restante da animação – a posição final final do componente de transformação específico.
- A duração, a curva e a velocidade da animação – elas são determinadas pelo tipo do ponto restante.
A animação de inércia é afetada por pontos de ajuste e limites. Os limites especificam os pontos de descanso máximo e mínimo para o conteúdo. Se o conteúdo atingir um limite durante a inércia, uma animação de limite será aplicada. Os pontos de ajuste são definidos no conteúdo primário para modificar o ponto restante e modificar a própria curva de animação de inércia.
Você define pontos de ajuste com SetSnapInterval quando o conteúdo é espaçado regularmente ou com SetSnapPoints quando o conteúdo é espaçado de forma desigual. Aqui está um exemplo de pontos de ajuste:
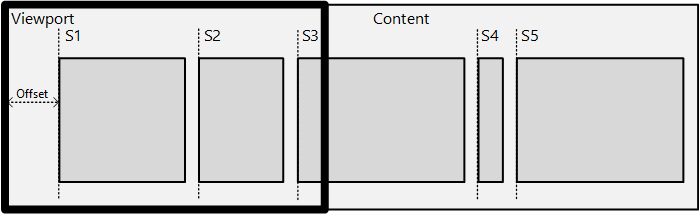
No diagrama, há um conteúdo com uma série de blocos de sub-conteúdo – itens de notícias em um aplicativo de tipo leitor de notícias ou itens em um Modo de Exibição de Grade. A intenção é ajustar a borda esquerda de um item na borda esquerda do visor após o término da inércia.
Há dois grupos de tipos de ponto de ajuste:
- Opcional vs. Obrigatório: um ponto de ajuste opcional ajusta a animação de inércia somente se o ponto de descanso de inércia estiver próximo ao ponto de ajuste. Um ponto de ajuste obrigatório sempre ajusta a animação de inércia a um ponto de ajuste especificado.
- Único vs. Múltiplo: um tipo de ponto de ajuste múltiplo permite que o conteúdo passe por muitos pontos de ajuste antes de ficar em repouso em um ponto de ajuste próximo ao seu ponto de descanso natural. Um único tipo de ponto de ajuste escolhe o próximo ponto de ajuste mais próximo como o ponto de descanso para a animação de inércia.
O próximo diagrama demonstra como os tipos de ponto de ajuste modificam a posição restante da animação de inércia.
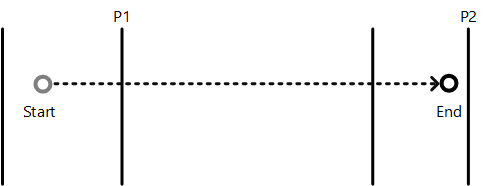
Neste diagrama, o ponto de partida de inércia é rotulado como 'Start' e a posição final de inércia natural na ausência de pontos de ajuste como 'End'. As linhas verticais marcam os vários pontos de ajuste. Esta tabela descreve como cada tipo de snap point afetará a posição final da animação.
| Tipo de ponto | Descrição |
|---|---|
| Único obrigatório | O ponto de ajuste P1 é escolhido porque é o primeiro ponto de ajuste na direção da inércia |
| Múltiplos obrigatórios | O ponto de ajuste P2 é escolhido porque está mais próximo do ponto final na direção da inércia |
| Single opcional | O ponto de ajuste P1 é escolhido porque é o primeiro ponto de ajuste encontrado durante a inércia |
| Múltiplo opcional | O ponto de ajuste P2 é escolhido porque está perto do ponto de extremidade natural |
Deslocamento de ponto de ajuste e cenários RTL
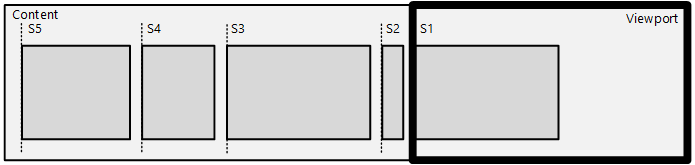
Você aplica o deslocamento de ponto de ajuste e o sistema de coordenadas usando a API SetSnapCoordinate – que desloca todos os pontos de ajuste ou intervalos de ajuste usando o sistema de deslocamento/coordenadas especificado.
O sistema de coordenadas é muito útil em cenários RTL, em que você deseja descrever pontos de ajuste da borda esquerda do conteúdo na direção inversa. No diagrama anterior, SetSnapCoordinate é usado com o sinalizador DIRECTMANIPULATION_MOTION_TRANSLATEX e DIRECTMANIPULATION_COORDINATE_MIRRORED , que desloca automaticamente os pontos de ajuste da borda esquerda do conteúdo e os fornece em ordem da direita para a esquerda: S1 está em 0px, S2 está em 50px (e assim por diante). Qualquer deslocamento definido usando SetSnapCoordinate será deslocado ainda mais dessa borda esquerda do conteúdo automaticamente, incluindo o fator de escala correto.
Você quase sempre usará SetSnapCoordinate com o parâmetro de origem definido para evitar definir pontos de ajuste fora da área de conteúdo.
Por exemplo, se o visor for 200x200 e o conteúdo for 1000x200 e a interface for RTL, o visor terá a borda esquerda em x=800 quando o visor for apresentado pela primeira vez. Chame SetSnapCoordinate com SetSnapCoordinate(DIRECTMANIPULATION_MOTION_TRANSLATEX, DIRECTMANIPULATION_COORDINATE_MIRRORED, 1000.0) para especificar que os pontos de ajuste devem ser calculados da ordem da direita para a esquerda a partir da borda DIREITA do conteúdo.
Comportamentos
Um comportamento é um objeto que pode ser anexado a um visor para modificar como a Manipulação Direta manipula a transformação de saída do conteúdo primário ou secundário de um visor. Um objeto de comportamento pode afetar um ou mais aspectos de uma manipulação, como como a entrada é processada ou como a animação de inércia é aplicada. Por exemplo, um comportamento de registro automático afeta a animação de inércia executando uma animação de rolagem em direção a uma extremidade do conteúdo primário. Um comportamento de configuração entre slides afeta o processamento de entrada de Manipulação Direta, que detecta quando uma ação entre slides está sendo executada.
Um objeto de comportamento é criado chamando CreateBehavior, adicionado a um visor e, em seguida, seu comportamento é configurado de forma assíncrona. Remover o comportamento do visor remove seus efeitos.
Sistema de coordenadas
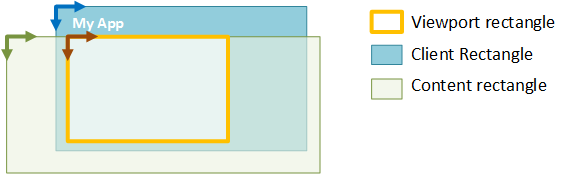
Há três sistemas de coordenadas main empregados pela Manipulação Direta:
- Sistema de coordenadas do cliente – descreve o retângulo da janela do cliente. As unidades estão em pixels.
- Sistema de coordenadas do visor – descreve o retângulo de uma região dentro do cliente que pode processar a entrada. As unidades são definidas pelo aplicativo (usando SetViewportRect).
- Sistema de coordenadas de conteúdo – descreve o retângulo ou o tamanho do conteúdo primário. As unidades são definidas pelo aplicativo (usando SetContentRect).
Para todos os três sistemas, as coordenadas são definidas em relação à respectiva origem superior esquerda e são positivas aumentando para a direita e para baixo. Esses sistemas de coordenadas são ilustrados no próximo diagrama. Somente a seção do conteúdo no retângulo do visor pode ser vista ou manipulada pelo usuário final.
Transformações
A Manipulação Direta mantém várias transformações diferentes que contribuem para a saída geral exibida.
- Transformação de conteúdo – a transformação inicial calculada pela Manipulação Direta com base em uma manipulação ou inércia. Ele captura os efeitos de pontos de ajuste, grade, overpan padrão (manipulação), excesso de disponibilidade padrão (inércia) e animações ZoomToRect.
- Transformação de saída – o visual final ou a transformação de saída. É a combinação do conteúdo, bem como das transformações de sincronização.
- Transformação de sincronização – computada quando você chama SyncContentTransform. Ele ajuda a Manipulação Direta a aplicar uma nova transformação de conteúdo fornecida pelo aplicativo, mantendo também a transformação de saída existente.
- Transformação de exibição – aplicada pelo aplicativo como parte do pós-processamento. Consulte SyncDisplayTransform para obter mais detalhes.
Como a transformação de saída destina-se a compensar uma superfície visualmente na tela, a Manipulação Direta executa o arredondamento necessário nos componentes de transformação de saída para que o texto e outros conteúdos sejam sempre renderizados/compostos em um limite de pixel integral. O mecanismo de arredondamento depende de vários fatores, incluindo a velocidade do movimento e a presença da Área de Trabalho Remota. O mecanismo de arredondamento para conteúdo secundário corresponde ao do conteúdo primário, levando em conta a diferença no movimento entre os dois. Os clientes de GetOutputTransform não devem depender do mecanismo de arredondamento exato da transformação de saída, pois vários fatores a afetam.
Observação
Isso significa que os componentes de uma transformação de conteúdo podem não ser integrais e podem conter deslocamentos de sub-pixel. Os clientes que usam a Manipulação Direta são incentivados a usar o GetOutputTransform para calcular a transformação visual correta a ser aplicada no conteúdo ao usar o modo de atualização manual. Ao usar o modo de atualização automática usando o compositor interno, a Manipulação Direta aplica automaticamente essa transformação em nome do cliente. Essa transformação é gerada pela Manipulação Direta para garantir resultados visualmente agradáveis ao redigir a saída visual.
Estado do visor
À medida que a entrada é processada, o visor gerencia o estado de interação e o mapeamento de entrada para transformações de saída. Verifique o estado de interação do visor chamando GetStatus.
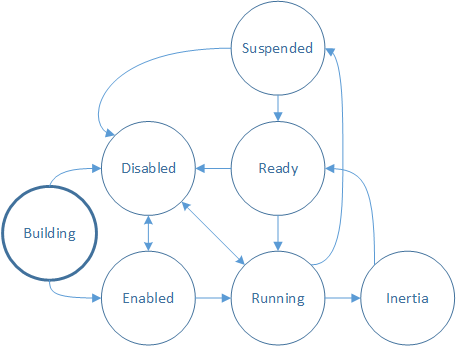
Compilação – o visor está sendo criado e ainda não é capaz de processar a entrada. Para processar a entrada, chame IDirectManipulationViewport::Enable. Se Habilitar não for chamado, o visor irá para o estado Desabilitado.
Observação
Esse é o estado inicial da interação.
Habilitado – o visor está pronto para processar a entrada. Quando um contato é desligado (SetContact é chamado) e uma manipulação é detectada, o visor faz a transição para Em execução.
Em execução – o visor está processando atualmente a entrada e a atualização de conteúdo. Quando o contato é levantado, o visor faz a transição para Inércia, se configurado.
Inércia – o conteúdo está se movendo em uma animação de inércia. Depois que a inércia for concluída, o visor fará a transição para Pronto. Se a desabilitação automática tiver sido definida no visor, ela fará a transição de Inércia para Pronto e, em seguida, para Desabilitado.
Pronto – o visor está pronto para processar a entrada. Quando um contato é desligado (SetContact é chamado) e uma manipulação é detectada, o visor faz a transição para Em execução.
Suspenso – o visor pode se tornar Suspenso quando sua entrada for promovida a um pai na cadeia SetContact . Isso é discutido com mais detalhes em Vários visores: teste de clique e hierarquia do visor.
Desabilitado – o visor não processará a entrada nem fará retornos de chamada. Um visor pode ser desabilitado de vários estados chamando IDirectManipulationViewport::D isable. Se a desabilitação automática tiver sido definida no visor, ela fará a transição automaticamente para Desabilitada depois que uma manipulação for processada. Para reabilitar um visor desabilitado, chame IDirectManipulationViewport::Enable.
Tópicos relacionados
Vários visores: teste de clique e hierarquia de visor, ActivateConfiguration, GetOutputTransform, SyncDisplayTransform