Windows glyph processing for OpenType fonts, part 2
As the central element of Windows glyph processing, the OpenType font format is a vast subject. Fortunately, the specification provides not only minute detail of the font table structures, header formats and internal tag lists, but a large number of examples that demonstrate the function of specific aspects of the technology. The following information provides a detailed introduction to the key glyph processing aspects of the OpenType format, somewhere between the level of the overview in Part One and the technical coverage of the specification itself, and some “real world” examples of OTL feature implementation.
OpenType is an extension of the original TrueType format, developed in partnership by Microsoft and Adobe Systems. OpenType makes use of the basic architecture of TrueType to add support for a wide variety of glyph substitution, positioning, justification and alignment features. The TrueType font format is based on a series of tables containing code and data for different aspects of the font architecture: character mapping, glyph outline descriptions, spacing metrics information, glyph naming, copyright and licensing, etc.. OpenType adds to the number of possible tables in the existing TrueType specification, to allow a greater degree of intelligence to be built into a font. Most of these new tables are optional, and it is important to note that it is possible to produce an OpenType font without any of the glyph substitution and positioning features encountered in Part One. The tables that will be discussed in this article are the five optional Advanced Typographic Tables:
- GDEF — Glyph definition data
- GSUB — Glyph substitution data
- GPOS — Glyph positioning data
- BASE — Baseline data
- JSTF — Justification data
and two required tables
- CMAP — Character to glyph mapping
- DSIG — Digital Signature
There is also a discussion of the role of script and language system tags.
CMAP Table
Every glyph in a TrueType font is identified by a unique Glyph ID (GID), a simple sequential numbering of all the glyphs in the font. These GIDs are mapped to character codepoints in the font’s CMAP table. In OpenType fonts, the principal mapping is to Unicode codepoints; that is, the GIDs of nominal glyph representations of specific characters are mapped to appropriate Unicode values.
The key to OpenType glyph processing is that not every glyph in a font is directly mapped to a codepoint. Variant glyph forms, ligatures, dynamically composed diacritics and other rendering forms do not require entries in the CMAP table. Rather, their GIDs are mapped in layout features to the GIDs of nominal character forms, i.e. to those glyphs that do have CMAP entries. This is the heart of glyph processing: the mapping of GIDs to each other, rather than directly to character codepoints.
In order for fonts to be able to correctly render text, font developers must ensure that the correct nominal glyph form GIDs are mapped to the correct Unicode codepoints. Application developers, of course, must ensure that their applications correctly manage input and storage of Unicode text codepoints, or map correctly to these codepoints from other codepages and character sets.
GDEF Table
As discussed in Part One, the most important tables for glyph processing are GSUB and GPOS, but both these tables make use of data in the Glyph Definition table. The GDEF table contains three kinds of information in subtables: glyph class definitions that classify different types of glyphs in a font; attachment point lists that identify glyph positioning attachments for each glyph; and ligature caret lists that provide information for caret positioning and text selection involving ligatures.
The Glyph Class Definition subtable identifies four glyph classes: simple glyphs, ligature glyphs (glyphs representing two or more glyph components), combining mark glyphs (glyphs that combine with other classes), and glyph components (glyphs that represent individual parts of ligature glyphs). These classes are used by both GSUB and GPOS to differentiate glyphs in a string; for example, to distinguish between a base vowel (simple glyph) and the accent (combining mark glyph) that a GPOS feature will position above it.
The Attachment Point List identifies all the glyph attachment points defined in the GPOS table. Clients that access this information in the GDEF table can cache attachment coordinates with the rasterized glyph bitmaps, and avoid having to recalculate the attachment points each time they display a glyph. Without this table, GPOS features could still be enabled, but processing speed would be slower because the client would need to decode the GPOS lookups that define the attachment points and compile its own list.
The Ligature Caret List defines the positions for the caret to occupy in ligatures. This information, which can be fine tuned for particular bitmap sizes, makes it possible for the caret to step across the component characters of a ligature, and for the user to select text including parts of ligatures. In the example on the left, below, the caret is positioned between two components of a ligature; on the right, text is selected from within a ligature.
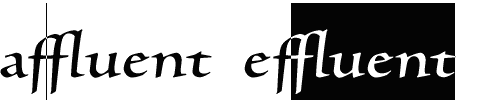
The Ligature Caret List can contain positioning data in both X and Y directions.
GSUB Table
The GSUB table contains substitution lookups that map GIDs to GIDs and associate these mappings with particular OpenType Layout features. The OpenType specification currently supports six different GSUB lookup types:
- Single
Replaces one glyph with one glyph. - Multiple
Replaces one glyph with more than one glyph. - Alternate
Replaces one glyph with one of many glyphs. - Ligature
Replaces multiple glyphs with one glyph. - Context
Replaces one or more glyphs in context. - Chaining Context
Replaces one or more glyphs in chained context.
Although these lookups are defined by the font developer, it is important for application developers to understand that some features require relatively complex UI support. In particular, OTL features using type 3 lookups may require the application to present options to the user (an example of this is provided in the discussion of OTLS in Part One). In addition, some registered features allow more than one lookup type to be employed, so application developers cannot rely on supporting only some lookup types. Similarly, features may have both GSUB and GPOS solutions—e.g. the “Case-Sensitive Forms” feature—so applications that want to support these features should avoid limiting their support to only one of these tables. In setting priorities for feature support, it is important to consider the possible interaction of features and to provide users with powerful sets of typographic tools that work together.
Scripts and Language Systems
A discussion of GSUB lookups and features affords a good opportunity to introduce the importance of script and language systems. These are a central aspect of the OpenType format: all glyph processing is defined within a context of script and language system. Even features that are not script or language specific by nature are located in this hierarchy:
Script > Language System > Feature > Lookup
An OpenType language system tag is always associated with a script tag, and indicates a specific orthographic convention for writing that language in that script. Because many written languages sharing a common script also share common typographic requirements, font developers can specify a Default <dflt> language system for each script that will be sufficient to support all but a few languages. By specifying additional language systems, the font developer can modify the function of OTL features when a script is used to represent these languages. This, of course, requires application level support for different language systems, possibly including mapping of OTL language systems to user locales, as well as language tagging of text runs.
In this example of a truncated tree structure, a Turkish language system has been added to Latin script support in a font in order to enable an exception to the default results of the “Standard Ligatures” feature. This feature includes the common f-ligatures in the Default language system, including the ffi and fi ligatures, but the latter are excluded in the Turkish language system to avoid confusion between the dotless i in the ligature glyphs and the Turkish letter with the same form. Mnemonic glyph names are used here, rather than GID numbers.
Latin <latn>
Default <dflt>
Standard Ligatures <liga> (GSUB feature)
All f-ligs (GSUB type 4 lookups)
f f i -> ffi
f f l -> ffl
f f -> ff
f i -> fi
f l -> fl
Turkish <TRK>
Standard Ligatures <liga> (GSUB feature)
ff and fl f-ligs (GSUB type 4 lookups)
f f l -> ffl
f f -> ff
f l -> fl
It should be noted that there are several different ways to achieve the same rendering, using different sets of lookups within the OTL feature. The best method will depend on the nature of the different languages supported by the font, and the number of exceptions to the default glyph processing.
The differing results of the same feature applied under two different language systems are shown below.

(Both the English and Turkish samples are from the work of the Turkish poet Nazim Hikmet.)
Note: although they enable exceptions to the Default language system feature behavior, additional language systems do not act exceptionally; that is, all desired features need to be associated with each language system, not just those that differ from the Default language system feature set.
While any OTL feature can be associated with different language systems, and may provide distinct glyph processing results for each, some registered features are designed specifically to take advantage of OpenType’s language system tags. One of these is the “Localized Forms” feature that associates stylistic glyph variants with particular language systems. This enables developers to provide support for different localized typographic cultures within the same script, and to “disunify” Unicode codepoint assignments at the font level. One important implementation of this would be in East Asian fonts that provide preferred forms of Han ideographs for Traditional and Simplified Chinese, Japanese and Korean users. In the simpler example below, the “Localized Forms” feature is used in an italic font to substitute the traditional Serbian forms of some Cyrillic letters where they differ from the international norms based on the Russian tradition. Again, mnemonic glyph names are used rather than GIDs.
Cyrillic <cyrl>
Default <dflt>
...
Serbian <SRB>
Localized Forms <locl> (GSUB feature)
Serbian forms (GSUB type 1 lookups)
cyrbe -> cyrbe.serb
cyrghe -> cyrghe.serb
cyrde -> cyrde.serb
cyrpe -> cyrpe.serb
cyrte -> cyrte.serb
The illustration below shows the dramatic results of this feature applied to just a few lines of Serbian poetry. The text on the left uses the font’s default glyph forms, the Russian norms, and the text on the right uses the substituted Serbian forms; the affected letters are indicated in red. Once again, the text string remains entirely unchanged, and only the rendering differs.

(These are the opening lines of “Belgrade, April 1944”, by the poet Miodrag Pavlović.)
As in the previous example, there are many ways to achieve the same results, and the OpenType specification does not favor any particular solution. It would be perfectly legitimate to designate the Serbian forms as the default glyphs for these Cyrillic characters, i.e. to make Serbian the Default language system. However, this would require many more instances of the “Localized Forms” feature to be applied to substitute the Russian forms that are also used for so many other languages like Belarusian, Ukrainian and dozens of minority languages within the Russian Federation. OpenType font developers need to plan their projects carefully to make efficient use of features and lookups.
GPOS table
The GPOS table contains a very powerful set of lookup types to reposition glyphs relative to their normative positions and to each other. Glyph positioning lookups work in two ways: by adjusting glyph positions relative to their metrical space or by linking predefined attachment points on different glyphs. These two methods are further divided into specific adjustment and attachment lookup types that can be used to control positioning of diacritics relative to single or ligatured characters, and even to enable chains of contextual positioning operations. The OpenType specification currently supports eight different GPOS lookup types:
- Single adjustment
Adjusts the position of a single glyph. - Pair adjustment
Adjusts the position of a pair of glyphs. - Cursive attachment
Attaches cursive glyphs to each other. - MarkToBase attachment
Attaches a combining mark to a base glyph. - MarkToLigature attachment
Attaches a combining mark to a ligature. - MarkToMark attachment
Attaches a combining mark to another mark. - Context positioning
Positions one or more glyphs in context. - Chained Context positioning
Position one or more glyphs in chained context.
Adjustment lookups are defined using the font’s internal metrical units (font units), which are specified as units of the total body or em height of the font, hence em units. The TrueType specification allows font developers to set the number of units per em in a font, but recommends the use of a power of two. This is actually a procurement requirement for fonts that ship with Microsoft products, and the majority of TrueType fonts have an em of 2048 units. It was much easier to visualize an em in earlier days, when the body of a piece of type was a chunk of metal. Digital glyph outlines are drawn on a Cartesian grid originating at the intersection of the left sidebearing and the nominal baseline. Digital ems are invisible most of the time, and the same glyph in different fonts may occupy more or less of the body height, and may even overflow the total height. The illustration below shows the lowercase b from the Windows 2000 font Sylfaen on its Cartesian grid with an em of 2048 units. Sylfaen is a font that comes close to filling the em height with its Latin ascender height and descender depth, but there are many fonts that are “cast small on the body”, whose glyphs occupy much less vertical space.
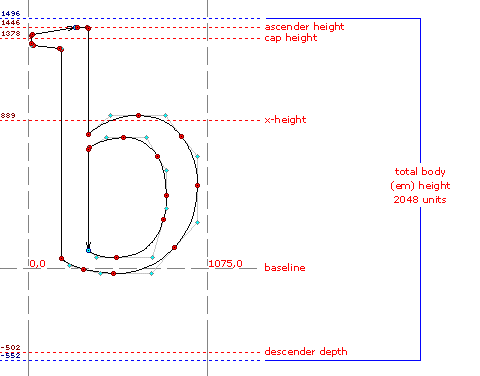
GPOS adjustment lookups can shift the position of a glyph in both X and Y directions, and can move a glyph well beyond its normative sidebearings and em height. Lookups are defined as offsets from the normative glyph position.
Among the OTL features that call GPOS table entries, the “Kerning” feature deserves special mention because it provides a new solution for an existing function in most text layout software. This feature generally implements type 2 GPOS lookups (chained contextual kerning is also possible using type 8 lookups), and has several advantages over traditional kerning pairs as stored in the TrueType KERN table. The GPOS “Kerning” feature can make use of class-based kerning, that is, adjustment of inter-glyph spacing in horizontal text according to predefined classes of glyphs with similar shapes and spacing. This both speeds up font production, especially in OpenType fonts with large glyph sets involving many diacritic variants of base glyphs, and decreases the file size of a well-kerned font. The “Kerning” feature can also provide device dependent kerning data for specific bitmap sizes to optimize screen typography. GPOS kerning and KERN table kerning information can be stored in the same font, and applications can decide which to make use of, although the production advantages of class-based kerning may render the KERN table effectively obsolete as more applications support the “Kerning” feature.
GPOS attachment lookups are made by predefining one or more absolute points on a glyph’s em grid, and then aligning attachment points on different glyphs. Attachment points are defined in the Glyph Definition Table (GDEF), which is referenced by the GPOS table. GPOS lookup types allow for attachment of marks, e.g. combining accents or vowel matras in Indic scripts, to base glyphs or to other marks. The latter MarkToMark attachments can be used to avoid collisions when more than one mark is applied to a base glyph. When contextual positioning or chained contextual positioning is used, it is possible to reposition glyphs more than once as the sequence of input characters is rendered.
The following example, using the Windows Devanagari UI font, Mangal, demonstrates how two different GPOS lookups are applied in conjunction with an initial GSUB lookup in shaping an Indic syllable. In the first line, the ja consonant, its inherent vowel suppressed by the halant, combines with the nya consonant to form an akhand, a required ligature form; this is achieved by implementing a type 4 (Ligature) GSUB lookup called by the “Akhand” feature. In the second line, the inherent vowel in jnya is replaced by the u vowel matra; this is a type 5 (MarkToLigature) GPOS attachment lookup called by the “Below-base Mark Positioning” feature. The attachment point on the two glyphs is indicated in the illustration by a small green dot; the lookup aligns these attachment points to correctly position the u matra below the conjunct ligature. In the third line, an anudatta stress accent is added to the syllable; this is lowered from its normative position and repositioned below the u matra by a type 2 (Pair adjustment) GPOS lookup, also called by the “Below-base Mark Positioning” feature. The pre-adjustment position of the anudatta is indicated in the final syllable by the pale gray rectangle.
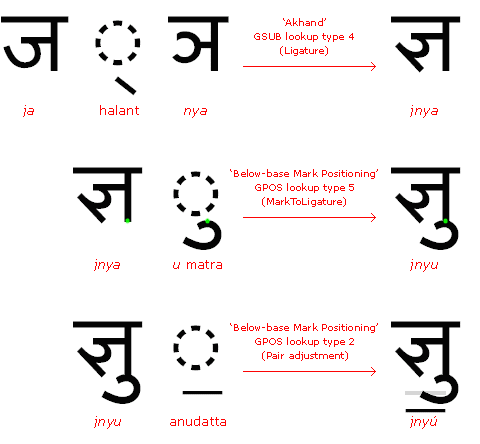
BASE table
BASE table entries, defined relative to the em height, are used to adjust the vertical position of lines of text composed with glyphs of different scripts and point sizes. Every glyph in a font has a nominal default baseline and, presuming the font has been well made, this baseline will provide consistent alignment appropriate for the supported script or scripts. When scripts are mixed in text, correct alignment and interlinear spacing may require an adjustment of the vertical position of one or more scripts relative to the baseline of the “dominant” script. In the example below, the dominant script is Latin, and the single kanji character needs to be moved down in order to align it correctly with the Latin text. CJKV ideographs have a default baseline near the bottom of the character, and in order to properly align with Latin text they need to have a BASE table entry identifying a second baseline that will set them lower on the line of text.
(CJKV is a common software development abbreviation for Chinese, Japanese, Korean and Vietnamese. It is also frequently encountered simply as CJK, since the Chinese ideographs are no longer part of the day-to-day writing system of most Vietnamese. The best source of information on East Asian text and digital typography is Ken Lunde’s book CJKV Information Processing.)
In the first sample, the kanji character’s default baseline is used; this positions the glyph too high and it almost collides with the descender of the p. In the second sample, this problem has been corrected by using the BASE table entry for dominant Latin text.

In addition to allowing multiple baselines to be identified for different scripts, the BASE table also gives clients the option of using minimum and maximum text extent entries to override the default text extent of particular scripts. The BASE table can define script, language system and feature specific min/max extent values. This is particularly useful for word processing applications that employ automatic interlinear adjustment to prevent collisions, as layout can be optimized for specific glyph processing features.
JSTF table
The JSTF table provides font developers with increased control over glyph substitution and positioning in justified text, i.e. text that is flush to both the left and right margins. JSTF table entries are designed to supplement an application’s justification algorithms by enabling or disabling specific OTL features. The table entries present a sequence of suggested priorities to improve the spacing and general appearance or “color” of justified text, the options for which will depend on particular script and language systems. For example, the spacing of justified Latin text might be improved in some circumstances by decomposing ligatures, while Arabic text may benefit from the use of swash forms or kashidas.
(A kashida is a lengthening stroke that extends, often very dramatically, certain Arabic letters in traditional calligraphic styles and fine typography.)
DSIG table
At the beginning of this section, I referred to the DSIG table as a “required” table. In fact, a digital signature is not required in the same sense that the CMAP and many other tables are required simply for the font to work. A font without a DSIG table will work, but it will not be recognized as an OpenType font by the Windows operating system. Because the OpenType format is an extension of the TrueType format, and most of the new tables are optional, Windows makes a distinction between the two formats based solely on the presence or absence of a DSIG table. A font with a DSIG table will be recorded in the Windows font folder as an OpenType font and presented with the OpenType icon.
A digital signature assures users that the signed software or document (in this case, the font) has not be altered or tampered with since it was signed by the maker, and that it does not contain malicious code or dangerous flaws. Digital signatures are based on a public/private key model, and keys are granted by Certification Authorities. Font developers can download a free font signing tool from the Microsoft Typography website. This is a command line utility that, in addition to adding a DSIG table to a font, runs a number of glyph integrity checks to confirm that the font is minimally conformant with the font format specification. If the font contains errors that may affect its performance, the digital signature tool will fail.
OTLS in Detail
The OpenType Layout Services library is currently available under a free license to application developers who are interested in using its helper functions to implement OpenType glyph processing. As explained in Part One, OTLS is composed of helper functions that insulate client applications from the details of the OpenType font tables and assist in applying GSUB and GPOS features. Client applications are free to make full or partial use of OTLS functions, making it a highly adaptive solution for developers who want to implement OpenType glyph processing support within existing text layout architecture.
In order to process runs of text, as defined in Part One, a client needs to be able to store characters, glyph coordinates, and flag and formatting properties. To make this easy, OTLS provides a general purpose object called an otlList. In addition to identifying and tagging runs of text, an OTLS client needs to be able to create and fill otlLists using inline helper functions. These otlLists will be used as input and output parameters for OTLS functions.
The principal OTLS functions are grouped in three categories. Font Information Functions are used to query an OpenType font about what scripts, language systems and features it supports:
- GetOtlVersion
Returns current library version. - GetOtlScriptList
Enumerates scripts in a font. - GetOtlLangSysList
Enumerates language systems in each script. - GetOtlFeatureDefs
Enumerates OTL features in each language system.
Text Information Functions return information about text layout and locate run elements such as character position and feature parameters:
- GetOtlLineSpacing
Returns interlinear spacing for a run of text. - GetOtlBaselineOffsets
Returns baseline adjustment between two scripts in adjacent runs (using font BASE table). - GetOtlCharAtPosition
Identifies what character is at given x,y coordinate. - GetOtlExtentOfChars
Returns location of character range. - GetOtlFeatureParams
Finds feature parameters within a run.
Text Layout Functions implement GSUB and GPOS features:
- SubstituteOtlChars
Performs primary glyph substitutions, i.e. substitutions of default glyphs. - SubstituteOtlGlyphs
Performs secondary glyph substitutions, i.e. substitutions of subsequent glyphs. - PositionOtlGlyphs
Performs initial glyph positioning. - RePositionOtlGlyphs
Adjusts glyph positioning.
In addition to these functions, OTLS provides a resource management function, FreeOtlResources, to clear client memory.
It should also be noted that, although it pays particular attention to Windows glyph processing, the OTLS library is designed to be adaptable to other platforms. Developers who are interested in obtaining a version of OTLS for a non-Windows platform should contact Microsoft Typography.
Uniscribe in Detail
The Uniscribe processor, USP10.DLL, ships with Windows 2000 and with Internet Explorer 5.0+, which is the current update mechanism. Uniscribe is not available under license to other vendors, but any application and font needing complex script shaping in Windows 2000 can make use of it. Applications can also use Uniscribe to display and print complex script text on older versions of the operating system, if the DLL is present.
Windows applications have a number of system API options for performing text layout. These include basic Win32 text APIs such as TextOut; more advanced Win32 edit controls that have been extended in Windows 2000 to support multilingual text and some aspects of complex scripts such as right-to-left reading order; the higher level interfaces of RichEdit control that take advantage of Uniscribe; and finally Uniscribe itself, which can be called directly by clients.
Uniscribe provides a large set of APIs to handle all aspects of text layout for supported scripts, including cursor position and hit testing, advance width calculation, linebreaking, complex script determination, localized digit substitution, etc..
We have already seen, in our Devanagari example in Part One, three of these APIs in action. Uniscribe divided the text run into clusters and generated glyphs (ScriptShape function), these glyphs are then positioned (ScriptPlace function), and displayed (ScriptTextOut function). During this process, additional APIs such as ScriptStringValidate might be called to confirm processing requirements.
The ScriptShape, ScriptPlace and ScriptTextOut APIs all interact with the Uniscribe shaping engines. As discussed in Part One, each shaping engine contains specific knowledge about a script or groups of related scripts. As support for new scripts is added to Uniscribe, new shaping engines may be defined or existing shaping engines may be extended to cover related scripts. For example, Syriac script support has been added to the existing Arabic shaping engine, while the similar processing requirements of Hebrew and Thaana allow the latter to be added to the Hebrew shaping engine. All the script engines analyze text runs to isolate the basic unbreakable element, the cluster. As we saw in the Devanagari example, clusters identified by the Indic shaping engine correspond to syllables. In Arabic, each cluster corresponds to an adjacent pair of characters, and the shaping engine moves along the text string classifying each character relative to its neighbors. For example, the first Arabic letter (determined by Unicode character properties) following a space character will first be classified as an isolated form, but if the next character is also an Arabic letter, the first will be reclassified as an initial form and the second classified as a final form. The shaping engine then moves along the string, making this second letter the first character of the next cluster. If the following character is a third letter, the second is reclassified as a medial form, the new character is classified as a final form, and the engine moves on. Uniscribe calls OTLS functions to render the correct forms using the OpenType Layout GSUB features “Initial Forms”, “Medial Forms” and “Terminal Forms” (the isolated form is presumed to be the default glyph form). This will result in basic minimum Arabic shaping. In the illustration below, a ligature feature has been applied to render the cluster in the second line. In the third line, however, the shaping engine finds another letter in the new cluster, so it goes back and replaces the ligature form from line two with the initial and medial forms of the first and second letters, to which the new final form letter is joined. The Unicode codepoints to the right of the grey line are stored in logical order, left-to-right, while the Arabic glyphs are rendered right-to-left. The cluster being processed in each line is indicated by the red codepoints.

The Arabic shaping engine will automatically call all required OTL features, e.g. the “Required Ligatures” feature to render the lam alef combination. A client application can make optional features available to users; for Arabic typography, these will likely include additional ligatures and swash forms. If vowel points or other marks are included in a text string, the Arabic script engine will use the Unicode character properties and shaping rules to ensure that these do not interfere with the rendering of the correct letter forms. GPOS lookups can be used to dynamically and contextually reposition point marks.
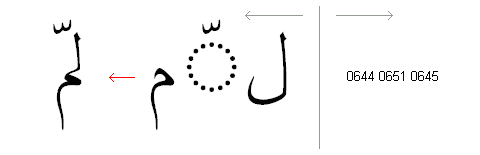
Note that, in addition to the complex script support described here, Uniscribe also understands the non-OpenType layout font formats for Arabic, Hebrew and Thai that were supported in previous localized versions of the operating system.
It is worth repeating that Uniscribe script engines implement Unicode Standard shaping rules for complex scripts. This gives font and application developers a common set of complex script expectations: font developers should be able to expect an application to be able to execute—directly or by calling Uniscribe—script rules as defined in the Unicode Standard, and application developers should be able to expect fonts with glyphs and layout features that are responsive to these rules.
Uniscribe currently has shaping engines for the following scripts.
- Arabic
- Arabic, Syriac
- Hebrew
- Hebrew, Thaana
- Indic
- Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, Telugu
- Old Hangul
- Hangul Jamo
- Thai
- Thai
Note that not all of these scripts are actively supported in Windows 2000 yet, usually due to the absence of fallback fonts. Fonts are in development for most of these scripts, and are in the pipeline to be added to Windows along with appropriate keyboard drivers, locale definitions, etc..
In addition to script support, Uniscribe provides processing for Unicode surrogate pairs that extend the number of characters that can be encoded in Unicode to almost one million. Among the first characters to be added to the surrogate extension planes are a large number of additional Han ideographs, so surrogate support will be an important aspect of East Asian text processing.
Uniscribe also implements the Unicode bidirectional (bidi) algorithm for mixed and nested text directions. This is essential for correctly rendering Unicode text strings containing characters with different direction properties, e.g. Arabic words within English text. Use of the bidi algorithm is not limited to mixing scripts, however; Arabic and Hebrew are both scripts with strong right-to-left reading direction, but which require digits to be rendered from left-to-right.
Conclusion
We have seen in this article how glyph processing extends the capabilities of fonts and text layout applications, and we have seen practical demonstrations of why this technology is needed to process the world’s many complex writing systems and the languages that use them. We’ve also seen, for example in the use of localized glyph forms for Serbian, how this technology can respond to the typographical preferences of particular user communities even as it provides a universal text processing solution using the Unicode Standard for character encoding. Not least, we have seen how glyph processing can enable rich typographic features that can be applied to text without font switching, custom encodings or other primitive solutions that threaten the semantic integrity of the text.
Many people will look at these capabilities and identify complex script support as an obvious priority; after all, such support is necessary to allow users of these scripts to communicate at a basic level. Text processing for complex scripts is glyph processing, and the challenges of implementing OpenType Layout features simply cannot be avoided. It seems likely then, that application developers looking to prioritize resource allocation for implementing glyph processing support are likely to view correct Arabic shaping as much more important than, for example, adding smallcaps support for the Latin script.
It is indeed difficult to overestimate the importance of Arabic shaping, but it is easy to underestimate the importance of Latin smallcaps. It is easy to think of typography as simply making text look nice, and so to treat many elements of typography as frills: luxuries that applications can get around to supporting when they have dealt with all the more important things.
I want to conclude this article by suggesting why support for sophisticated typography belongs among the important things, and not relegated to a frill. The role of typography is not to prettify text, but to articulate it. That it does so in an aesthetic way—utilizing all the art it can draw from its own heritage, the heritage of manuscript tradition, and individual creative vision—should not disguise the expressive and organizational relationship of typography to text. A typographic culture, such as the one in which you engage as you read this article, is a system of visual indicators that helps readers navigate text and helps writers express their ideas. In the 550 years since Gutenberg developed metal type casting at Mainz, the printed Latin script has developed a particularly rich typographic culture, using romans, italics, bold type, smallcaps, ligatures, swash forms, etc., to organize and articulate the texts of hundreds of languages around the world. Other scripts have developed equally complex and adaptive systems, some more complex and sophisticated, while others are only just beginning their typographic journey. Typography is part of how the human race expresses itself, individually and collectively. Sadly, whenever support for a particular aspect of a typographic culture is limited, texts are inevitably rendered less expressive of the ideas they contain than they might be. As if we were forced to speak in a monotone, we cannot fully articulate what we need to say.
Software developers, of course, have to prioritize, to allocate resources carefully, and they need to ship a product in a marketplace that will not wait for them to do everything they might like to do. The Windows glyph processing model provides such developers with a powerful set of helper functions and system components to provide users with rich, expressive typographical controls. The OpenType format provides font developers with ways to add considerable typographic intelligence to their fonts: intelligence that, with proper application support, can help users articulate their ideas with the full register of their typographic voices.