Explore a arquitetura da solução
Vamos revisar a arquitetura que você decidiu para o fluxo de trabalho de operações de aprendizado de máquina (MLOps) para entender onde e quando devemos verificar o código.
Nota
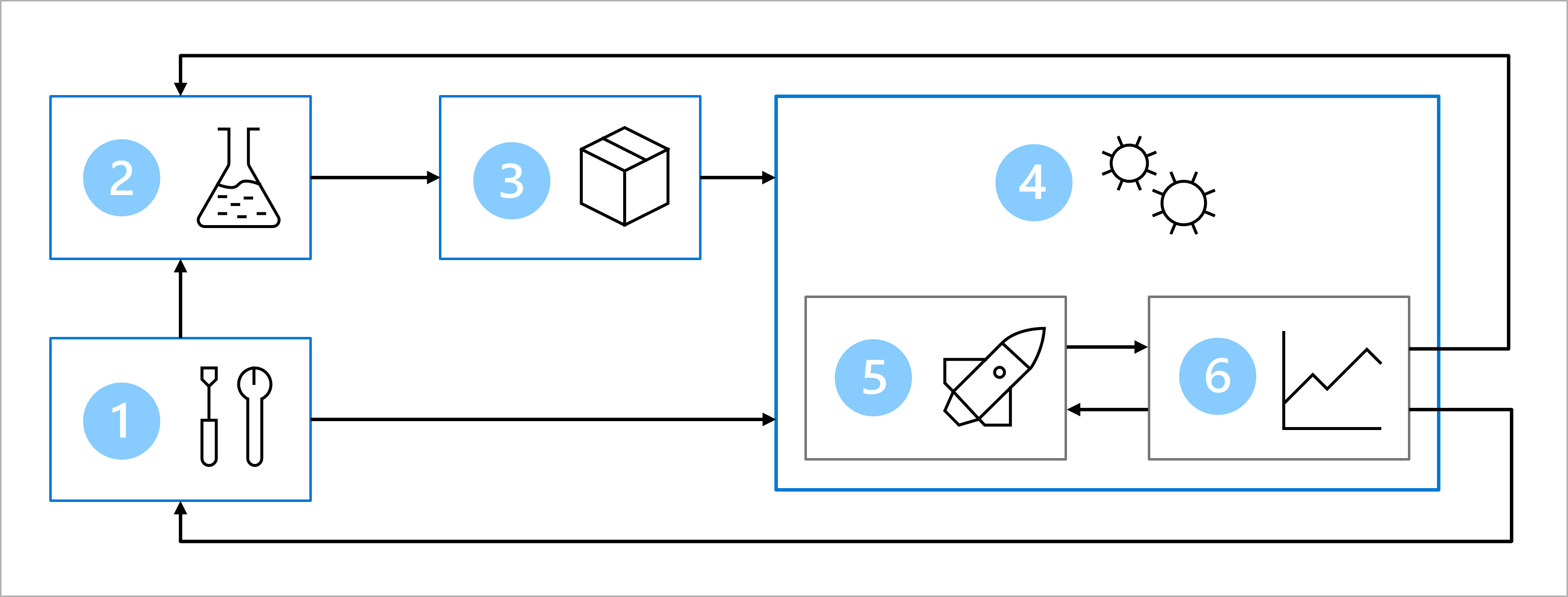
O diagrama é uma representação simplificada de uma arquitetura MLOps. Para exibir uma arquitetura mais detalhada, explore os vários casos de uso no acelerador de solução MLOps (v2).
O principal objetivo da arquitetura MLOps é criar uma solução robusta e reproduzível. Para isso, a arquitetura inclui:
- Configuração: crie todos os recursos necessários do Azure para a solução.
- Desenvolvimento do modelo (loop interno): Explore e processe os dados para treinar e avaliar o modelo.
- Integração contínua: Empacotar e registrar o modelo.
- Implantação do modelo (loop externo): implante o modelo.
- Implantação contínua: teste o modelo e promova para o ambiente de produção.
- Monitoramento: Monitore o desempenho do modelo e do ponto final.
Para mover um modelo do desenvolvimento para a implantação, você precisará de integração contínua. Durante a integração contínua, você empacotará e registrará o modelo. Antes de empacotar um modelo, no entanto, você precisará verificar o código usado para treinar o modelo.
Juntamente com a equipe de ciência de dados, você concordou em usar o desenvolvimento baseado em tronco. As ramificações não apenas protegerão o código de produção, mas também permitirão que você verifique automaticamente quaisquer alterações propostas antes de mesclá-lo com o código de produção.
Vamos explorar o fluxo de trabalho para um cientista de dados:
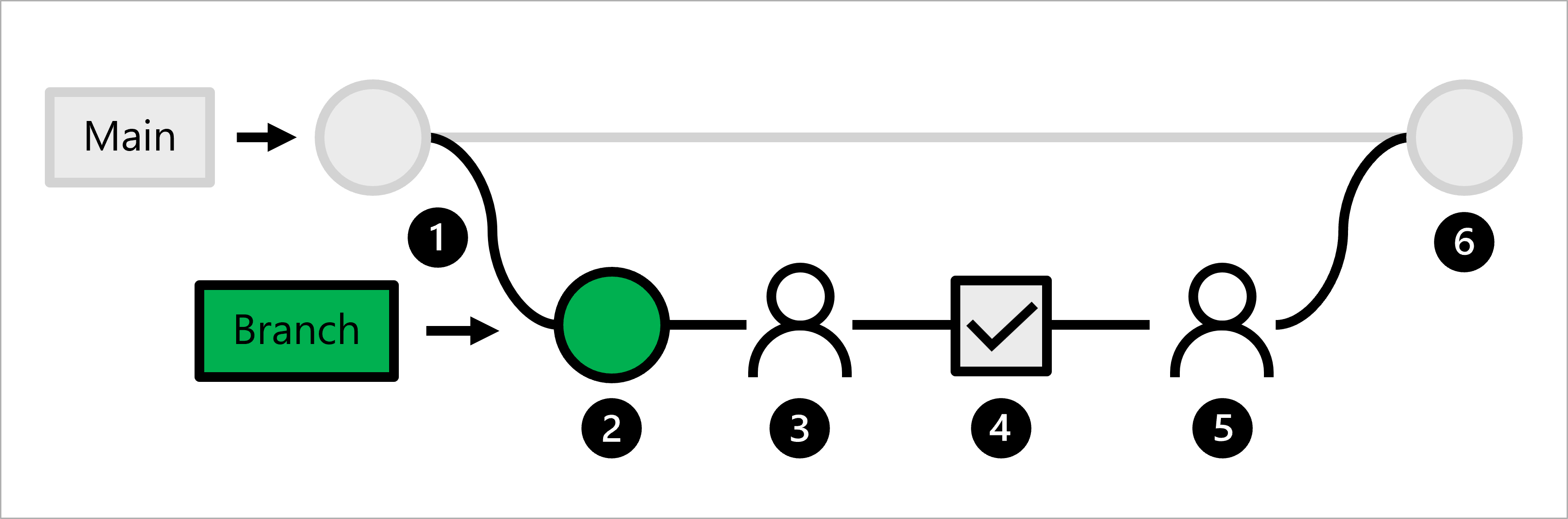
- O código de produção é hospedado na ramificação principal .
- Um cientista de dados cria uma ramificação de recurso para o desenvolvimento de modelos.
- O cientista de dados cria uma solicitação pull para propor alterações por push para a ramificação principal.
- Quando uma solicitação pull é criada, um fluxo de trabalho de Ações do GitHub é acionado para verificar o código.
- Quando o código passa no linting e no teste de unidade, o cientista de dados líder precisa aprovar as alterações propostas.
- Depois que o cientista de dados líder aprova as alterações, a solicitação pull é mesclada e a ramificação principal é atualizada de acordo.
Como engenheiro de aprendizado de máquina, você precisará criar um fluxo de trabalho de Ações do GitHub que verifique o código executando um linter e testes de unidade sempre que uma solicitação pull for criada.
Gorjeta
Saiba mais sobre como trabalhar com controle de origem para projetos de aprendizado de máquina, incluindo desenvolvimento baseado em tronco e verificação local do código.