Otimizar tabelas delta
O Spark é uma estrutura de processamento paralelo, com dados armazenados em um ou mais nós de trabalho. Além disso, os arquivos Parquet são imutáveis, com novos arquivos escritos para cada atualização ou exclusão. Esse processo pode resultar no armazenamento de dados do Spark em um grande número de arquivos pequenos, conhecido como o problema do arquivo pequeno. Isso significa que consultas sobre grandes quantidades de dados podem ser executadas lentamente ou até mesmo não serem concluídas.
Função OptimizeWrite
OptimizeWrite é um recurso do Delta Lake que reduz o número de arquivos à medida que são gravados. Em vez de escrever muitos ficheiros pequenos, escreve menos ficheiros maiores. Isso ajuda a evitar o problema de arquivos pequenos e garantir que o desempenho não seja degradado.
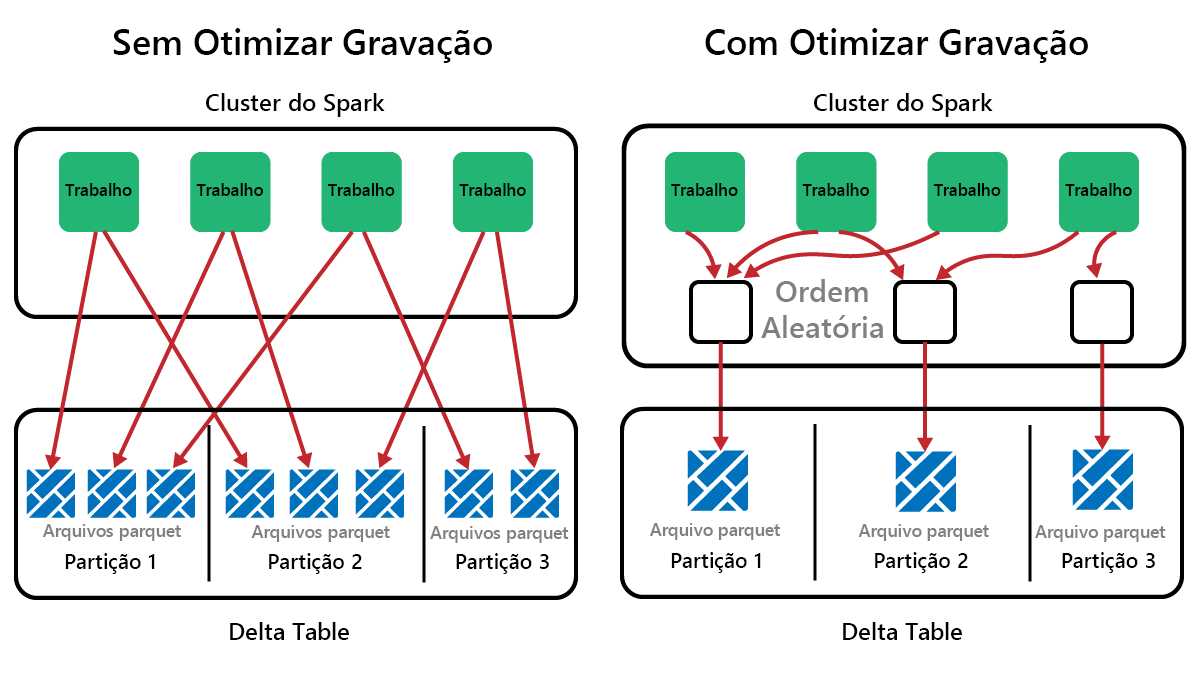
No Microsoft Fabric, OptimizeWrite está habilitado por padrão. Você pode ativá-lo ou desativá-lo no nível da sessão do Spark:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Nota
OptimizeWrite também pode ser definido em Propriedades da tabela e para comandos de gravação individuais.
Otimização
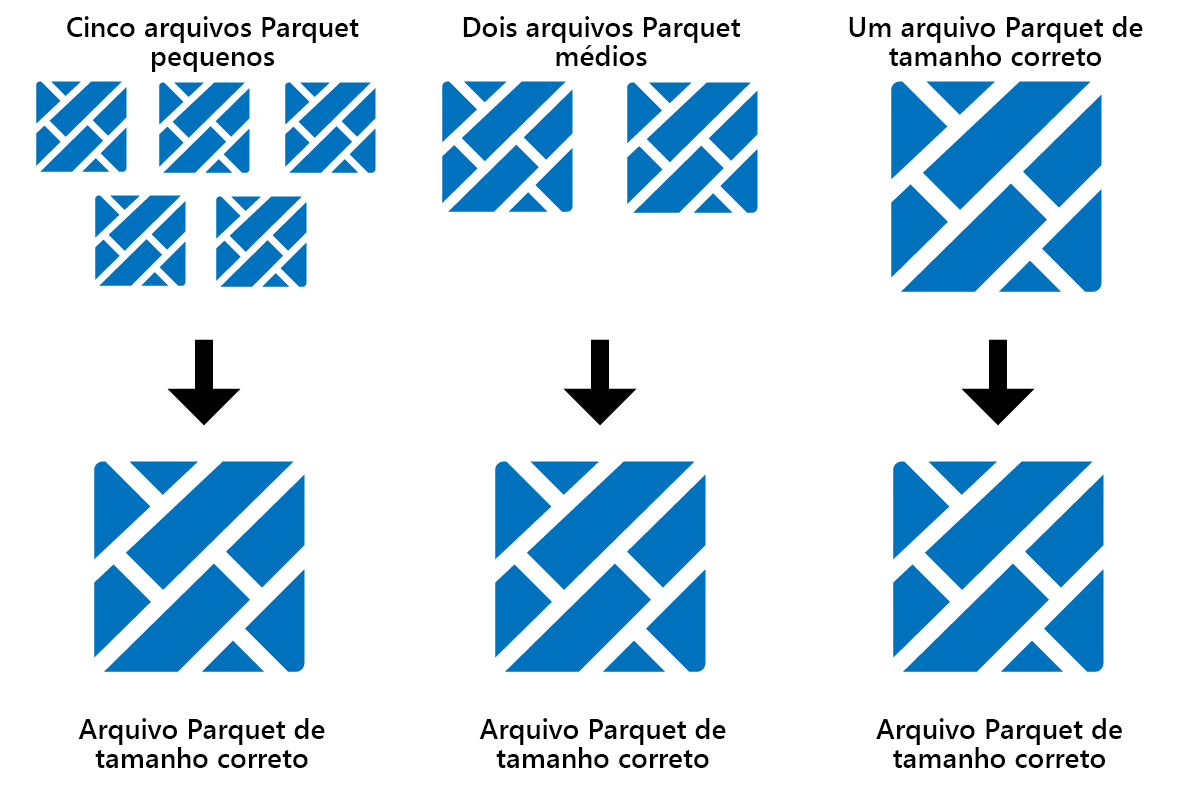
O Otimize é um recurso de manutenção de tabela que consolida arquivos pequenos do Parquet em menos arquivos grandes. Você pode executar o Otimize depois de carregar tabelas grandes, resultando em:
- menos ficheiros maiores
- melhor compressão
- Distribuição eficiente de dados entre nós
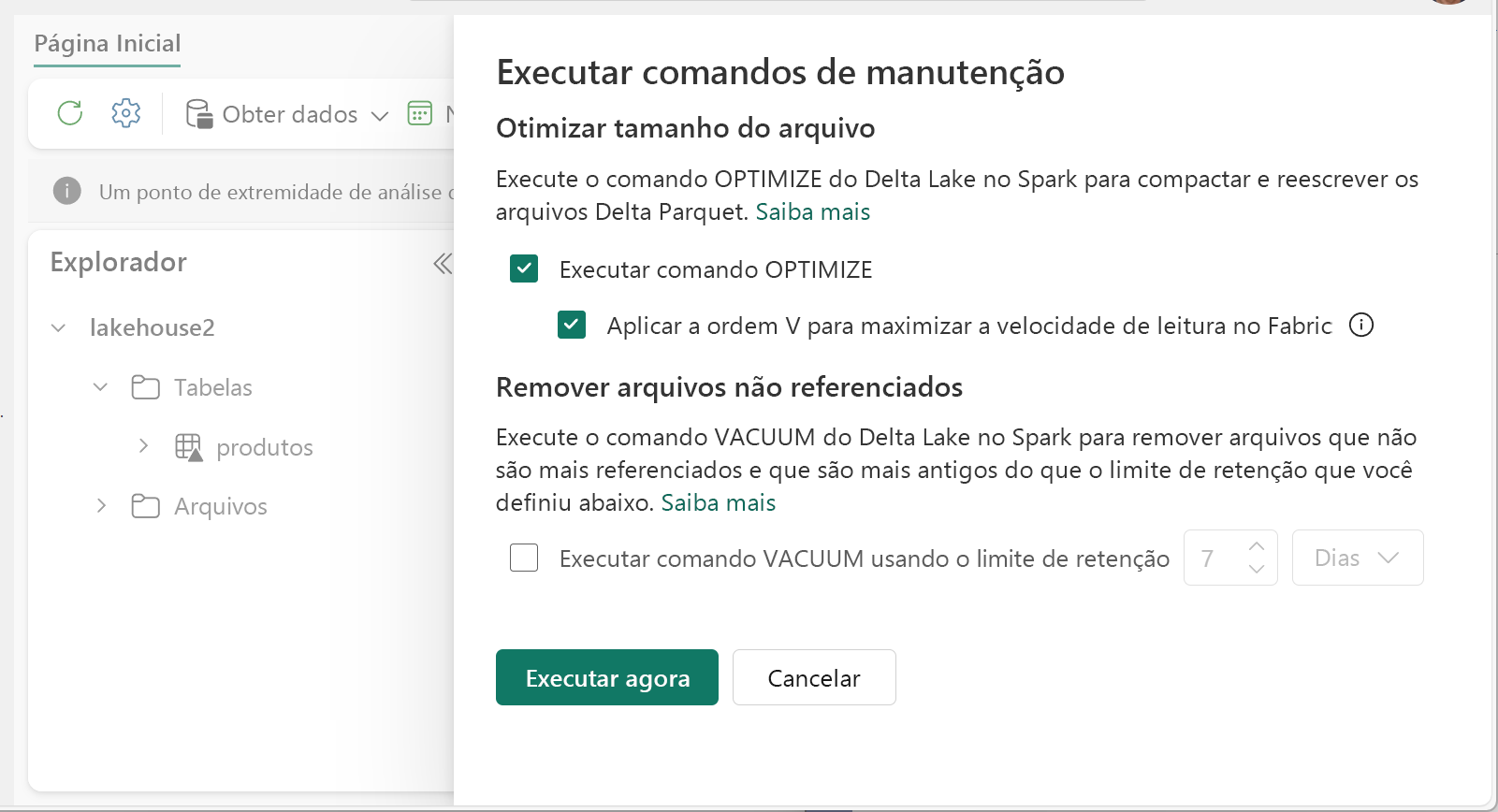
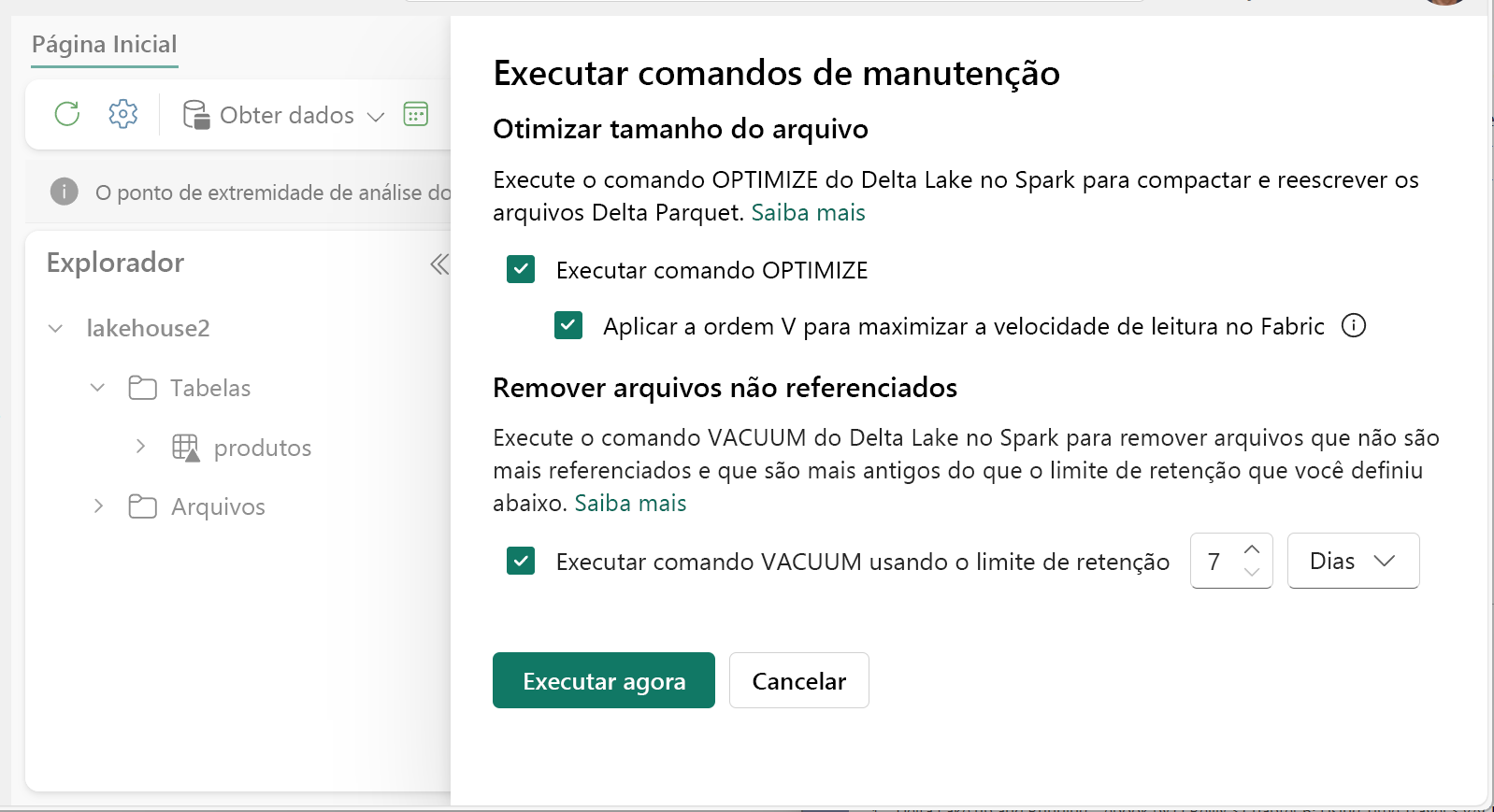
Para executar o Otimize:
- No Lakehouse Explorer, selecione o botão ... ao lado do nome de uma tabela e selecione Manutenção.
- Selecione Executar comando OTIMIZE.
- Opcionalmente, selecione Aplicar ordem V para maximizar as velocidades de leitura no Fabric.
- Selecione Executar agora.
Função V-Order
Ao executar o Otimize, você pode, opcionalmente, executar o V-Order, que foi projetado para o formato de arquivo Parquet na malha. O V-Order permite leituras extremamente rápidas, com tempos de acesso a dados semelhantes aos da memória. Ele também melhora a eficiência de custos, pois reduz os recursos de rede, disco e CPU durante as leituras.
V-Order é habilitado por padrão no Microsoft Fabric e é aplicado à medida que os dados estão sendo gravados. Ele incorre em uma pequena sobrecarga de cerca de 15%, tornando as gravações um pouco mais lentas. No entanto, o V-Order permite leituras mais rápidas dos mecanismos de computação do Microsoft Fabric, como Power BI, SQL, Spark e outros.
No Microsoft Fabric, os mecanismos Power BI e SQL usam a tecnologia Microsoft Verti-Scan, que aproveita ao máximo a otimização V-Order para acelerar as leituras. O Spark e outros motores não usam a tecnologia VertiScan, mas ainda se beneficiam da otimização V-Order em leituras cerca de 10% mais rápidas, às vezes até 50%.
V-Order funciona aplicando classificação especial, distribuição de grupo de linhas, codificação de dicionário e compactação em arquivos Parquet. É 100% compatível com o formato Parquet de código aberto e todos os motores Parquet podem lê-lo.
O V-Order pode não ser benéfico para cenários de gravação intensiva, como armazenamentos de dados de preparo em que os dados são lidos apenas uma ou duas vezes. Nessas situações, desativar o V-Order pode reduzir o tempo total de processamento para a ingestão de dados.
Aplique V-Order a tabelas individuais usando o recurso Manutenção de Tabela executando o OPTIMIZE comando.
Limpeza
O comando VACUUM permite-lhe remover ficheiros de dados antigos.
Toda vez que uma atualização ou exclusão é feita, um novo arquivo Parquet é criado e uma entrada é feita no log de transações. Os arquivos antigos do Parquet são retidos para permitir a viagem no tempo, o que significa que os arquivos do Parquet se acumulam ao longo do tempo.
O comando VACUUM remove arquivos de dados antigos do Parquet, mas não os logs de transações. Quando executa o VACUUM, não pode viajar no tempo antes do período de retenção.
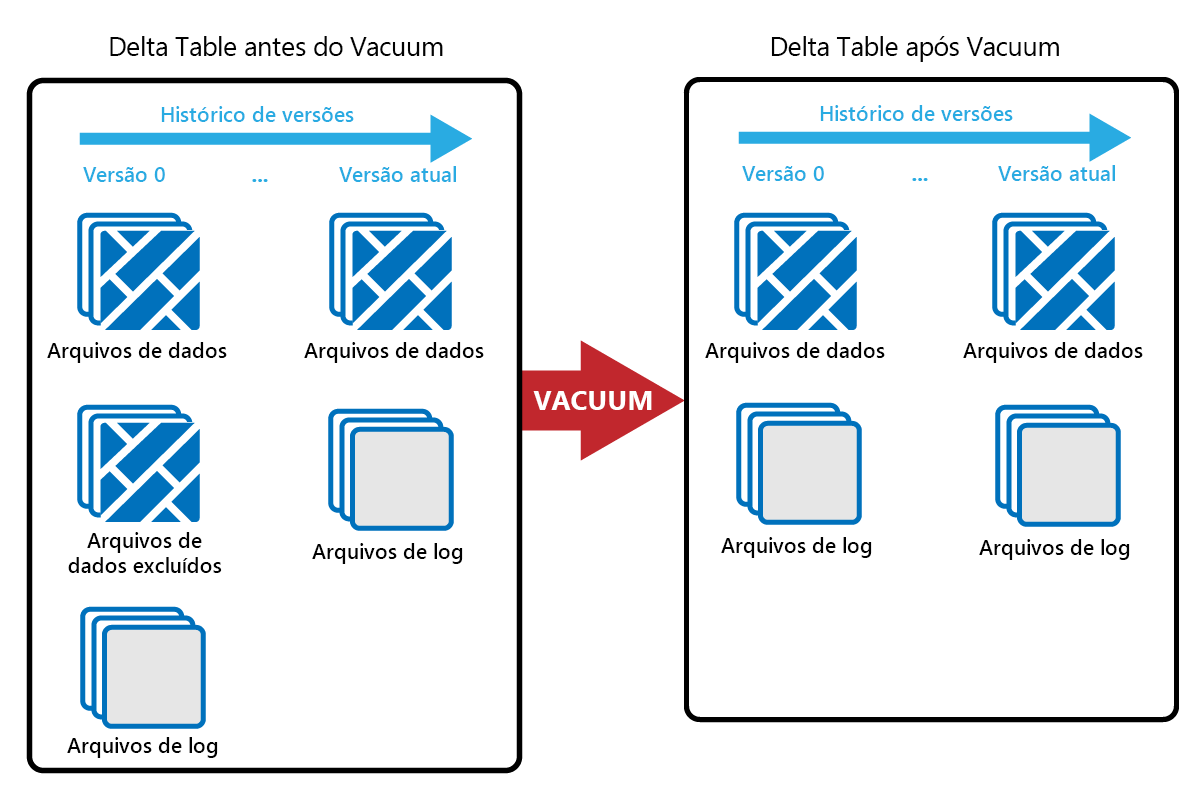
Os arquivos de dados que não são atualmente referenciados em um log de transações e que são mais antigos do que o período de retenção especificado são excluídos permanentemente executando VACUUM. Escolha o seu período de retenção com base em fatores como:
- Requisitos de conservação de dados
- Tamanho dos dados e custos de armazenamento
- Frequência de alteração de dados
- Requisitos regulamentares
O período de retenção padrão é de 7 dias (168 horas) e o sistema impede que você use um período de retenção mais curto.
Você pode executar o VACUUM de forma ad hoc ou agendada usando notebooks Fabric.
Execute o VACUUM em mesas individuais usando o recurso de manutenção de tabela:
- No Lakehouse Explorer, selecione o botão ... ao lado do nome de uma tabela e selecione Manutenção.
- Selecione Executar comando VACUUM usando o limite de retenção e defina o limite de retenção.
- Selecione Executar agora.
Você também pode executar VACUUM como um comando SQL em um bloco de anotações:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM se compromete com o log de transações Delta, para que você possa visualizar execuções anteriores em DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
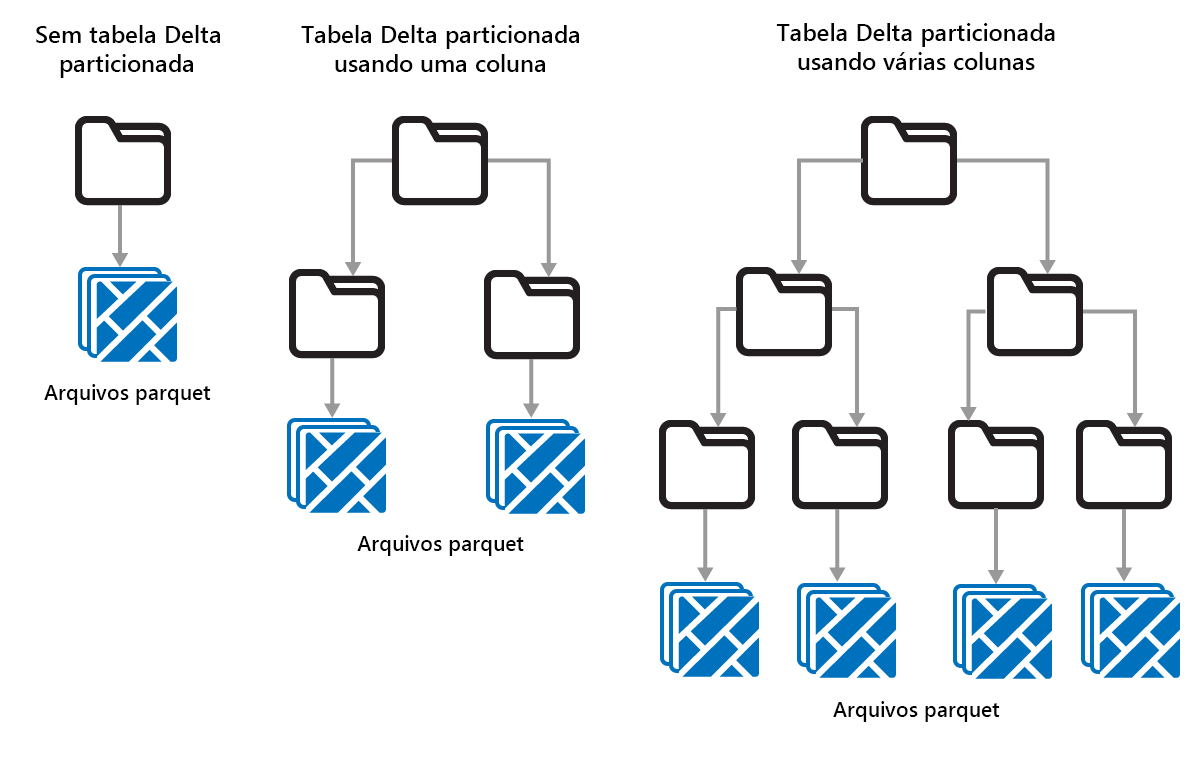
Particionamento de tabelas Delta
Delta Lake permite organizar dados em partições. Isso pode melhorar o desempenho habilitando o salto de dados, o que aumenta o desempenho ignorando objetos de dados irrelevantes com base nos metadados de um objeto.
Considere uma situação em que grandes quantidades de dados de vendas estão sendo armazenadas. Você pode particionar os dados de vendas por ano. As partições são armazenadas em subpastas denominadas "year=2021", "year=2022", etc. Se você quiser apenas relatar os dados de vendas de 2024, as partições de outros anos podem ser ignoradas, o que melhora o desempenho de leitura.
O particionamento de pequenas quantidades de dados pode degradar o desempenho, no entanto, porque aumenta o número de arquivos e pode exacerbar o "problema de arquivos pequenos".
Use o particionamento quando:
- Você tem grandes quantidades de dados.
- As tabelas podem ser divididas em algumas partições grandes.
Não use particionamento quando:
- Os volumes de dados são pequenos.
- Uma coluna de particionamento tem alta cardinalidade, pois isso cria um grande número de partições.
- Uma coluna de particionamento resultaria em vários níveis.
As partições são um layout de dados fixo e não se adaptam a diferentes padrões de consulta. Ao considerar como usar o particionamento, pense em como seus dados são usados e sua granularidade.
Neste exemplo, um DataFrame contendo dados do produto é particionado por Categoria:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
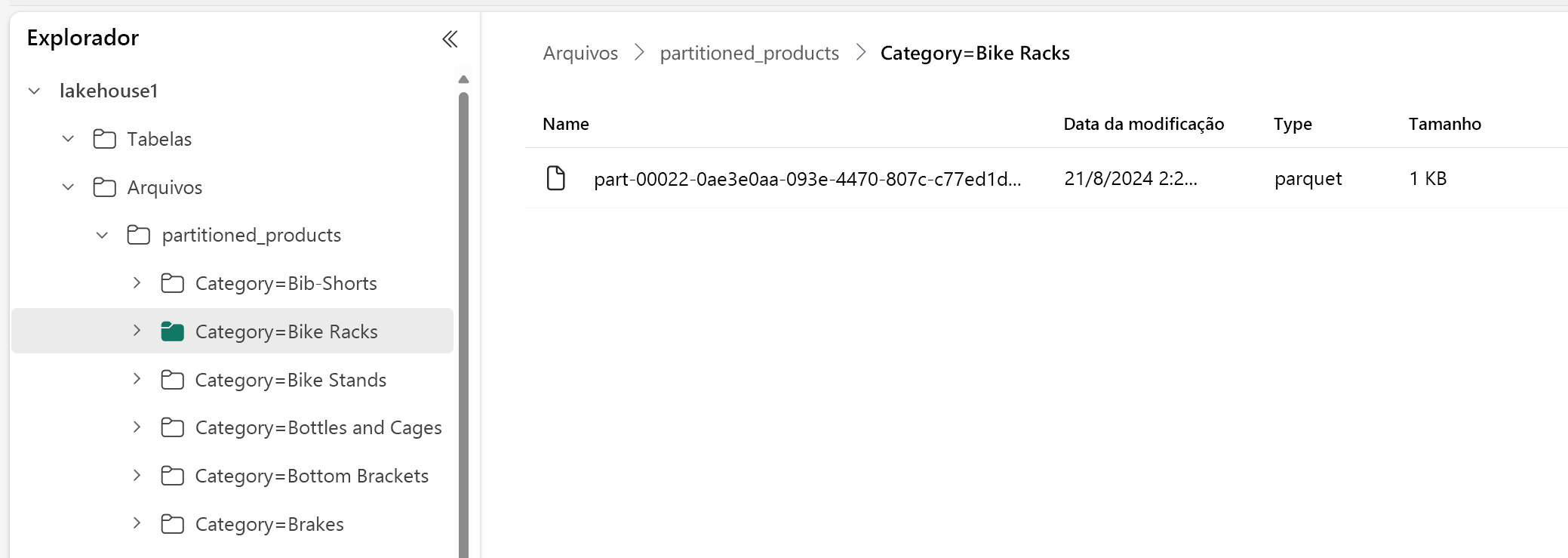
No Lakehouse Explorer, você pode ver que os dados são uma tabela particionada.
- Há uma pasta para a tabela, chamada "partitioned_products".
- Existem subpastas para cada categoria, por exemplo "Category=Bike Racks", etc.
Podemos criar uma tabela particionada semelhante usando SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);