Usar o Spark no Azure Synapse Analytics
Você pode executar muitos tipos diferentes de aplicativos no Spark, incluindo código em scripts Python ou Scala, código Java compilado como um Java Archive (JAR) e outros. O Spark é comumente usado em dois tipos de carga de trabalho:
- Tarefas de processamento em lote ou fluxo para ingerir, limpar e transformar dados - geralmente em execução como parte de um pipeline automatizado.
- Sessões de análise interativas para explorar, analisar e visualizar dados.
Executando o código Spark em blocos de anotações
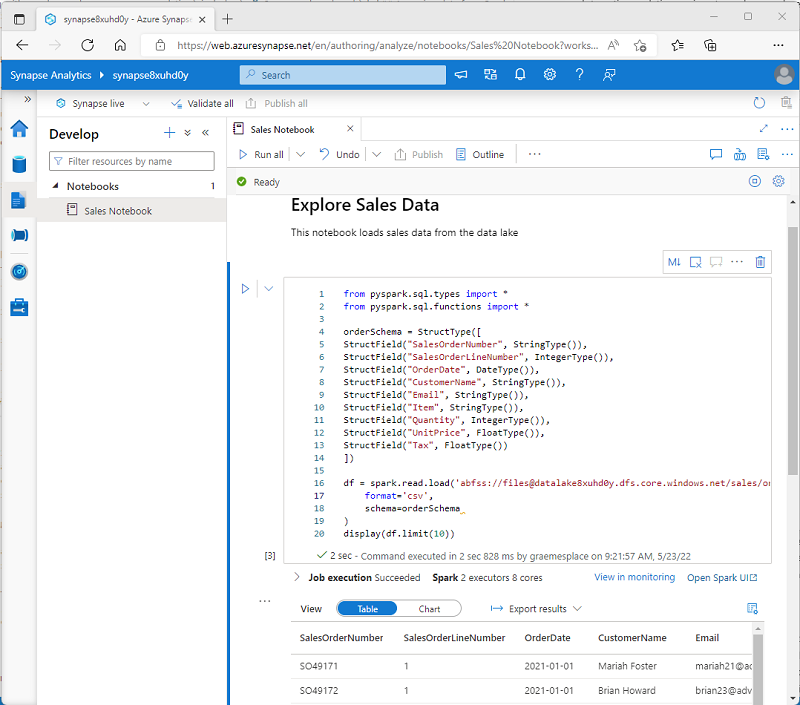
O Azure Synapse Studio inclui uma interface de bloco de notas integrada para trabalhar com o Spark. Os notebooks fornecem uma maneira intuitiva de combinar código com notas Markdown, comumente usadas por cientistas de dados e analistas de dados. A aparência da experiência de notebook integrada no Azure Synapse Studio é semelhante à dos notebooks Jupyter - uma plataforma de notebook de código aberto popular.
Nota
Embora geralmente usados interativamente, os blocos de anotações podem ser incluídos em pipelines automatizados e executados como um script autônomo.
Os blocos de notas consistem em uma ou mais células, cada uma contendo código ou marcação. As células de código nos blocos de notas têm algumas funcionalidades que o podem ajudar a ser mais produtivo, incluindo:
- Realce de sintaxe e suporte a erros.
- Preenchimento automático de código.
- Visualizações de dados interativas.
- A capacidade de exportar resultados.
Gorjeta
Para saber mais sobre como trabalhar com blocos de anotações no Azure Synapse Analytics, consulte o artigo Criar, desenvolver e manter blocos de anotações Synapse no Azure Synapse Analytics na documentação do Azure Synapse Analytics.
Acessando dados de um pool Synapse Spark
Você pode usar o Spark no Azure Synapse Analytics para trabalhar com dados de várias fontes, incluindo:
- Um data lake baseado na conta de armazenamento principal para o espaço de trabalho do Azure Synapse Analytics.
- Um data lake baseado no armazenamento definido como um serviço vinculado no espaço de trabalho.
- Um pool SQL dedicado ou sem servidor no espaço de trabalho.
- Um banco de dados SQL ou SQL Server do Azure (usando o conector Spark para SQL Server)
- Um banco de dados analítico do Azure Cosmos DB definido como um serviço vinculado e configurado usando o Azure Synapse Link for Cosmos DB.
- Um banco de dados Kusto do Azure Data Explorer definido como um serviço vinculado no espaço de trabalho.
- Um metastore externo do Hive definido como um serviço vinculado no espaço de trabalho.
Um dos usos mais comuns do Spark é trabalhar com dados em um data lake, onde você pode ler e gravar arquivos em vários formatos comumente usados, incluindo texto delimitado, Parquet, Avro e outros.