Solucionar problemas de uma rede usando métricas e logs do Inspetor de Rede
Se quiser diagnosticar um problema rapidamente, você precisa entender as informações disponíveis nos logs do Observador de Rede do Azure.
Em sua empresa de engenharia, você deseja minimizar o tempo necessário para sua equipe diagnosticar e resolver qualquer problema de configuração de rede. Você quer garantir que eles saibam quais informações estão disponíveis em quais logs.
Neste módulo, você se concentrará em logs de fluxo, logs de diagnóstico e análise de tráfego. Você aprenderá como essas ferramentas podem ajudar a solucionar problemas da rede do Azure.
Utilização e quotas
Você pode usar cada recurso do Microsoft Azure até sua cota. Cada assinatura tem cotas separadas e o uso é rastreado por assinatura. É necessária apenas uma instância do Observador de Rede por subscrição e por região. Esta instância fornece uma visão do uso e das cotas para que você possa ver se corre o risco de atingir uma cota.
Para exibir as informações de uso e cota, vá para Todos os Serviços>Rede>Observador de Redee selecione Uso e cotas. Você verá dados granulares com base no uso e na localização do recurso. São capturados dados para as seguintes métricas:
- Interfaces de rede
- Grupos de segurança de rede (NSGs)
- Redes virtuais
- Endereços IP públicos
Aqui está um exemplo que mostra o uso e as cotas no portal:

Registos
Os logs de diagnóstico de rede fornecem dados granulares. Você usará esses dados para entender melhor os problemas de conectividade e desempenho. Há três ferramentas de exibição de log no Network Watcher:
- Logs de fluxo NSG
- Logs de diagnóstico
- Análise de tráfego
Vejamos cada uma dessas ferramentas.
Logs de fluxo NSG
Nos registos de fluxo NSG, pode visualizar informações sobre o tráfego IP de entrada e saída nos grupos de segurança de rede. Os logs de fluxo mostram os fluxos de entrada e de saída para cada regra, com base no adaptador de rede ao qual o fluxo se aplica. Os logs de fluxo do NSG indicam se o tráfego foi permitido ou negado com base nas informações de cinco tuplas capturadas. Estas informações incluem:
- IP de origem
- Porta de origem
- IP de destino
- Porto de destino
- Protocolo
Este diagrama mostra o fluxo de trabalho que o NSG segue.
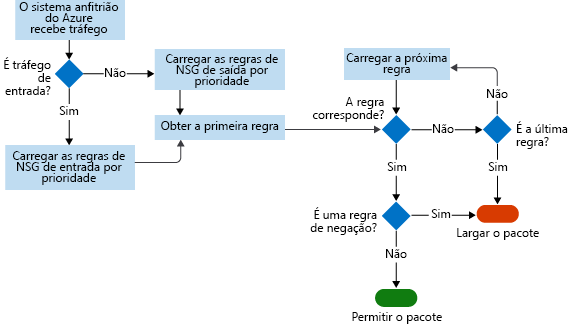
Os logs de fluxo armazenam dados em um arquivo JSON. Pode ser difícil obter informações sobre esses dados pesquisando manualmente os arquivos de log, especialmente se você tiver uma implantação de infraestrutura grande no Azure. Para resolver esse problema, use o Power BI.
No Power BI, você pode visualizar os logs de fluxo do NSG de várias maneiras. Por exemplo:
- Top talkers (endereço IP)
- Fluxos por direção (entrada e saída)
- Fluxos por decisão (permitidos e negados)
- Fluxos por porto de destino
Você também pode usar ferramentas de código aberto para analisar seus logs, como Elastic Stack, Grafana e Graylog.
Observação
Os logs de fluxo do NSG não oferecem suporte a contas de armazenamento no portal clássico do Azure.
Logs de diagnóstico
No Monitor de Rede, os logs de diagnóstico são um ponto central para ativar e desativar registos para recursos de rede do Azure. Esses recursos podem incluir NSGs, IPs públicos, balanceadores de carga e gateways de aplicativos. Depois de ativar os logs que lhe interessam, você pode usar as ferramentas para consultar e exibir entradas de log.
Você pode importar logs de diagnóstico para o Power BI e outras ferramentas para analisá-los.
Análise de tráfego
Para investigar a atividade de usuários e aplicativos em suas redes de nuvem, use a análise de tráfego.
A ferramenta fornece informações sobre a atividade da rede em todas as assinaturas. Você pode diagnosticar ameaças à segurança, como portas abertas, VMs se comunicando com redes defeituosas conhecidas e padrões de fluxo de tráfego. A análise de tráfego analisa os logs de fluxo do NSG em regiões e assinaturas do Azure. Você pode usar os dados para otimizar o desempenho da rede.
Esta ferramenta requer o Log Analytics. O espaço de trabalho do Log Analytics deve existir em uma região suportada.
Cenários de casos de uso
Agora, vamos examinar alguns cenários de caso de uso em que as métricas e os logs do Azure Network Watcher podem ser úteis.
Relatos de clientes sobre desempenho lento
Para resolver o desempenho lento, você precisa determinar a causa raiz do problema:
- Há muito tráfego limitando o servidor?
- O tamanho da VM é apropriado para o trabalho?
- Os limites de escalabilidade são definidos adequadamente?
- Estão a acontecer ataques maliciosos?
- A configuração de armazenamento da VM está correta?
Primeiro, verifique se o tamanho da VM é apropriado para o trabalho. Em seguida, habilite o Diagnóstico do Azure na VM para obter dados mais granulares para métricas específicas, como uso de CPU e uso de memória. Para ativar o diagnóstico para a VM através do portal, vá até a VM , selecione 'Configurações de Diagnóstico' e ative o diagnóstico.
Vamos supor que você tenha uma VM que esteja funcionando bem. No entanto, o desempenho da VM se degradou recentemente. Para identificar se você tem algum gargalo de recursos, você precisa revisar os dados capturados.
Comece com um intervalo de tempo de dados capturados antes, durante e depois do problema relatado para obter uma visão precisa do desempenho. Esses gráficos também podem ser úteis para cruzar diferentes comportamentos de recursos no mesmo período. Você verificará:
- Gargalos de CPU
- Gargalos de memória
- Afunilamentos de disco
Gargalos de CPU
Quando você está olhando para problemas de desempenho, você pode examinar as tendências para entender se elas afetam seu servidor. Para identificar tendências, a partir do portal, use os gráficos de monitoramento. Você pode ver diferentes tipos de padrões nos gráficos de monitoramento:
- Picos isolados. Um pico pode estar relacionado a uma tarefa agendada ou a um evento esperado. Se você sabe o que é essa tarefa, ela é executada no nível de desempenho exigido? Se o desempenho estiver OK, talvez não seja necessário aumentar a capacidade.
- Spike up e constante. Uma nova carga de trabalho pode causar essa tendência. Habilite o monitoramento na VM para descobrir quais processos causam a carga. O aumento do consumo pode ser devido a um código ineficiente ou pode ser o consumo normal da nova carga de trabalho. Se o consumo for normal, o processo funciona no nível de desempenho exigido?
- Constante. A sua VM sempre foi assim? Em caso afirmativo, você deve identificar os processos que consomem mais recursos e considerar a adição de capacidade.
- Aumento constante. Vê um aumento constante do consumo? Nesse caso, essa tendência pode indicar um código ineficiente ou um processo que assume mais carga de trabalho do usuário.
Se você observar alta utilização da CPU, você pode:
- Aumente o tamanho da VM para dimensionar com mais núcleos.
- Investigue melhor o problema. Localize o aplicativo e o processo e solucione problemas de acordo.
Se você aumentar a escala da VM e a CPU ainda estiver sendo executada acima de 95%, o desempenho do aplicativo será melhor ou a taxa de transferência do aplicativo será maior para um nível aceitável? Caso contrário, solucione problemas desse aplicativo individual.
Gargalos de memória
Você pode exibir a quantidade de memória que a VM usa. Os logs irão ajudá-lo a entender a tendência e se eles correspondem ao momento em que você vê problemas. Você não deve ter menos de 100 MB de memória disponível em nenhum momento. Esteja atento às seguintes tendências:
- Aumento acentuado e consumo constante. A alta utilização da memória pode não ser a causa do mau desempenho. Algumas aplicações, como mecanismos de base de dados relacional, consomem muita memória por conceção. Mas se houver várias aplicações que consomem muita memória, poderá experimentar um desempenho ruim porque a contenção de memória resulta em redução e paginação no disco. Esses processos causarão um impacto negativo no desempenho.
- Aumento constante do consumo. Essa tendência pode ser um aplicativo aquecendo. É comum quando os motores de bases de dados arrancam. No entanto, também pode ser um sinal de um vazamento de memória em um aplicativo.
- Utilização de ficheiros de página ou de troca. Verifique se você está usando muito o arquivo de paginação do Windows ou o arquivo de permuta do Linux, localizado em /dev/sdb.
Para resolver a alta utilização da memória, considere estas soluções:
- Para alívio imediato ou uso de arquivo de página, aumente o tamanho da VM para adicionar memória e, em seguida, monitore.
- Investigue melhor o problema. Localize o aplicativo ou processo que está causando o gargalo e solucione-o. Se você conhece o aplicativo, veja se consegue limitar a alocação de memória.
Afunilamentos de disco
O desempenho da rede também pode estar relacionado ao subsistema de armazenamento da VM. Você pode investigar a conta de armazenamento para a VM no portal. Para identificar problemas com o armazenamento, examine as métricas de desempenho do diagnóstico da conta de armazenamento e do diagnóstico da VM. Procure as principais tendências quando os problemas ocorrem dentro de um determinado intervalo de tempo.
- Para verificar o tempo limite no Armazenamento do Azure, utilize as métricas ClientTimeOutError, ServerTimeOutError, AverageE2ELatency, AverageServerLatencye TotalRequests. Se vir valores nas métricas TimeOutError, uma operação de E/S demorou demasiado tempo e expirou. Se vir o AverageServerLatency aumentar ao mesmo tempo que os TimeOutErrors, poderá ser um problema de plataforma. Levante um caso com o suporte técnico da Microsoft.
- Para verificar a limitação do Armazenamento do Azure, use a métrica da conta de armazenamento ThrottlingError. Se notar uma limitação, está a atingir o limite de IOPS da conta. Você pode verificar esse problema investigando a métrica TotalRequests.
Para corrigir problemas de alta utilização e latência do disco:
- Otimize a E/S de VM para ultrapassar os limites do disco rígido virtual (VHD).
- Aumente a taxa de transferência e reduza a latência. Se você achar que tem um aplicativo sensível à latência e precisa de alta taxa de transferência, migre seus VHDs para o Armazenamento Premium do Azure.
Regras de firewall de máquina virtual que bloqueiam o tráfego
Para solucionar um problema de fluxo NSG, use a ferramenta de verificação de fluxo IP do Network Watcher e o registo de fluxo NSG para determinar se um NSG ou UDR (Roteamento Definido pelo Utilizador) está a interferir no fluxo de tráfego.
Execute a verificação do fluxo IP e especifique a VM local e a VM remota. Depois de selecionar Check, o Azure executa um teste lógico nas regras em vigor. Se o resultado for que o acesso é permitido, utilize os registos de fluxo do NSG.
No portal, vá para os NSGs. Nas configurações do log de fluxo, selecione On. Agora tente se conectar à VM novamente. Use a análise de tráfego do Inspetor de Rede para visualizar os dados. Se o resultado for que o acesso é permitido, não há nenhuma regra NSG como obstáculo.
Se você chegou a esse ponto e ainda não diagnosticou o problema, pode haver algo errado na VM remota. Desative o firewall na VM remota e teste novamente a conectividade. Se você puder se conectar à VM remota com o firewall desativado, verifique as configurações do firewall remoto. Em seguida, reative o firewall.
Incapacidade de comunicação entre as sub-redes front-end e back-end
Por padrão, todas as sub-redes podem se comunicar no Azure. Se duas VMs em duas sub-redes não puderem se comunicar, deve haver uma configuração que esteja bloqueando a comunicação. Antes de verificar os registos de fluxo, execute a ferramenta de verificação de fluxo IP da VM front-end para a VM back-end. Esta ferramenta executa um teste lógico nas regras na rede.
Se o resultado for um NSG na sub-rede de retaguarda bloqueando toda a comunicação, reconfigure esse NSG. Por motivos de segurança, você deve bloquear alguma comunicação com o front-end porque o front-end está exposto à Internet pública.
Ao bloquear a comunicação com o back-end, você limita a quantidade de exposição no caso de um malware ou ataque de segurança. No entanto, se o NSG bloquear tudo, ele está configurado incorretamente. Habilite os protocolos e portas específicos necessários.