Repositórios e desenvolvimento baseado em tronco
Muitos cientistas de dados preferem trabalhar com Python ou R para definir cargas de trabalho de aprendizado de máquina. Você pode ter blocos de anotações ou scripts Jupyter para preparar dados ou treinar um modelo.
Trabalhar em qualquer ativo de código torna-se mais fácil quando você usa o controle do código-fonte. O controle do código-fonte é a prática de gerenciar o código e controlar quaisquer alterações feitas pela sua equipe no código.
Se você trabalha com ferramentas de DevOps, como o Azure DevOps ou o GitHub, o código é armazenado em um chamado repositório ou repositório.
Repositório
Ao configurar a estrutura MLOps, é provável que um engenheiro de aprendizado de máquina crie o repositório. Se você optar por usar o Azure Repos no Azure DevOps ou nos repositórios do GitHub, ambos usam repositórios Git para armazenar seu código.
Geralmente, há duas maneiras de definir o escopo do repo:
- Monorepo: mantenha todas as cargas de trabalho de aprendizado de máquina dentro do mesmo repositório.
- Vários repositórios: crie um repositório separado para cada novo projeto de aprendizado de máquina.
A abordagem que sua equipe prefere depende de quem deve ter acesso a quais ativos. Se você quiser garantir acesso rápido a todos os ativos de código, os monorepos podem atender melhor aos requisitos da sua equipe. Se você quiser dar às pessoas acesso a um projeto apenas se elas estiverem trabalhando ativamente nele, sua equipe pode preferir trabalhar com vários repositórios. Lembre-se de que o gerenciamento do controle de acesso pode criar mais sobrecarga.
Estruture seu repositório
Seja qual for a abordagem adotada, é uma prática recomendada concordar com a estrutura de pastas padrão de nível superior para seus projetos. Por exemplo, você pode ter as seguintes pastas em todos os seus repositórios:
.cloud: contém código específico da nuvem, como modelos, para criar um espaço de trabalho do Azure Machine Learning..ad/.github: contém artefatos do Azure DevOps ou GitHub, como pipelines YAML para automatizar fluxos de trabalho.src: contém qualquer código (scripts Python ou R) usado para cargas de trabalho de aprendizado de máquina, como pré-processamento de dados ou treinamento de modelo.docs: contém quaisquer arquivos Markdown ou outra documentação usada para descrever o projeto.pipelines: contém definições de pipelines do Azure Machine Learning.tests: contém testes de unidade e integração usados para detetar bugs e problemas em seu código.notebooks: contém cadernos Jupyter, usados principalmente para experimentação.
Nota
Os dados de treinamento não devem ser incluídos no seu repositório. Os dados devem ser armazenados em um banco de dados ou data lake. O Azure Machine Learning pode ter acesso direto a um banco de dados ou data lake armazenando as informações de conexão como um armazenamento de dados.
Ao ter uma estrutura padrão que cada projeto usa, os cientistas de dados e outros colaboradores terão mais facilidade em encontrar o código em que precisam trabalhar.
Gorjeta
Encontre mais práticas recomendadas para estruturar projetos de ciência de dados.
Para aprender a trabalhar com repositórios como cientista de dados, você aprenderá sobre o desenvolvimento baseado em tronco.
Desenvolvimento baseado em tronco
A maioria dos projetos de desenvolvimento de software usa o Git como um sistema de controle de origem, que é usado pelo Azure DevOps e pelo GitHub.
O principal benefício de usar o Git é a fácil colaboração no código, ao mesmo tempo em que acompanha todas as alterações feitas. Além disso, você pode adicionar portas de aprovação para garantir que apenas as alterações que foram revisadas e aceitas serão feitas no código de produção.
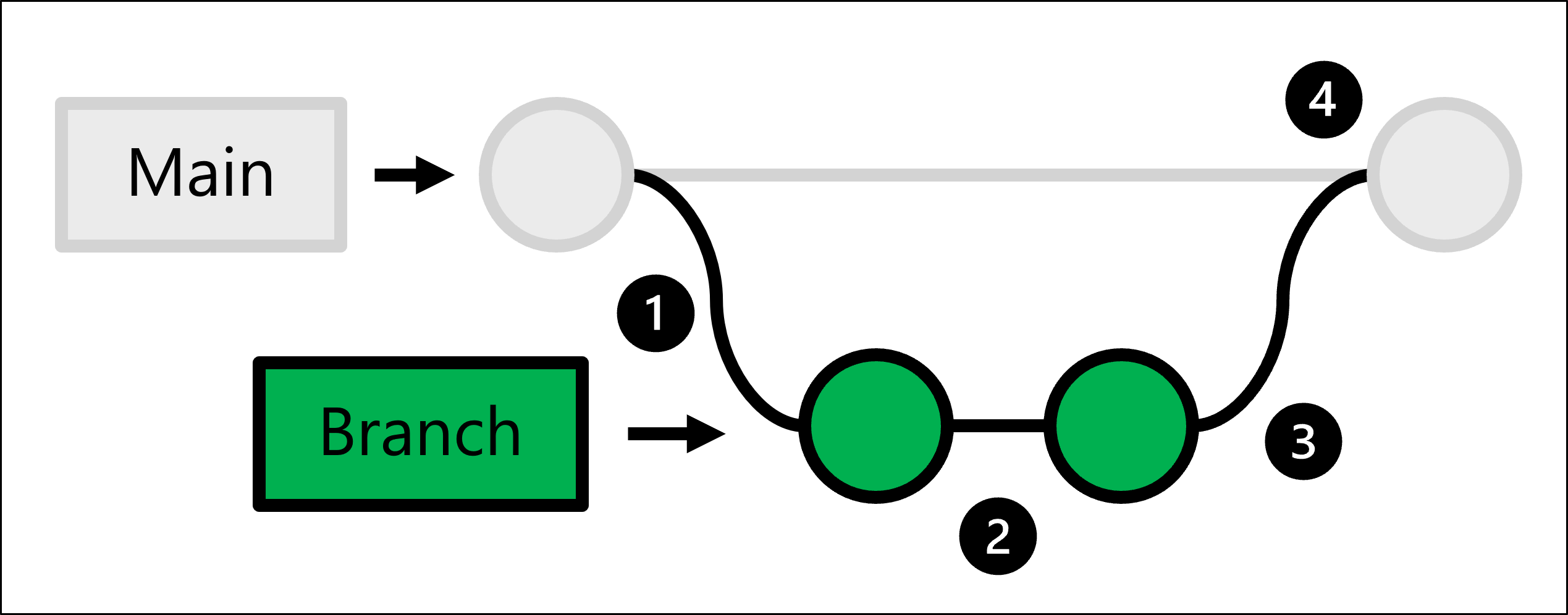
Para realizar o acima, o Git faz uso do desenvolvimento baseado em tronco que permite criar ramificações.
O código de produção é hospedado na ramificação principal . Sempre que alguém quiser fazer uma alteração:
- Você cria uma cópia completa do código de produção criando uma ramificação.
- Na ramificação que você criou, você faz as alterações e as testa.
- Assim que as alterações na sua filial estiverem prontas, pode pedir a alguém que as reveja.
- Se as alterações forem aprovadas, você mesclará a ramificação criada com o repositório principal e o código de produção será atualizado para refletir suas alterações.