Executar um trabalho de pipeline
Quando tiver criado um pipeline baseado em componentes no Azure Machine Learning, pode executar o fluxo de trabalho como um trabalho de pipeline.
Configurar um trabalho de pipeline
Um pipeline é definido em um arquivo YAML, que você também pode criar usando a @pipeline() função. Depois de usar a função, você pode editar as configurações do pipeline especificando quais parâmetros deseja alterar e o novo valor.
Por exemplo, talvez você queira alterar o modo de saída para as saídas de trabalho de pipeline:
# change the output mode
pipeline_job.outputs.pipeline_job_transformed_data.mode = "upload"
pipeline_job.outputs.pipeline_job_trained_model.mode = "upload"
Ou, você pode querer definir a computação de pipeline padrão. Quando uma computação não é especificada para um componente, ela usará a computação padrão:
# set pipeline level compute
pipeline_job.settings.default_compute = "aml-cluster"
Você também pode querer alterar o armazenamento de dados padrão para onde todas as saídas serão armazenadas:
# set pipeline level datastore
pipeline_job.settings.default_datastore = "workspaceblobstore"
Para revisar a configuração do pipeline, você pode imprimir o objeto de trabalho do pipeline:
print(pipeline_job)
Executar um trabalho de pipeline
Depois de configurar o pipeline, você estará pronto para executar o fluxo de trabalho como um trabalho de pipeline.
Para enviar o trabalho de pipeline, execute o seguinte código:
# submit job to workspace
pipeline_job = ml_client.jobs.create_or_update(
pipeline_job, experiment_name="pipeline_job"
)
Depois de enviar um trabalho de pipeline, um novo trabalho será criado no espaço de trabalho do Azure Machine Learning. Um trabalho de pipeline também contém trabalhos filho, que representam a execução dos componentes individuais. O estúdio do Azure Machine Learning cria uma representação gráfica do seu pipeline. Você pode expandir a visão geral do trabalho para explorar os parâmetros do pipeline, saídas e trabalhos filho:
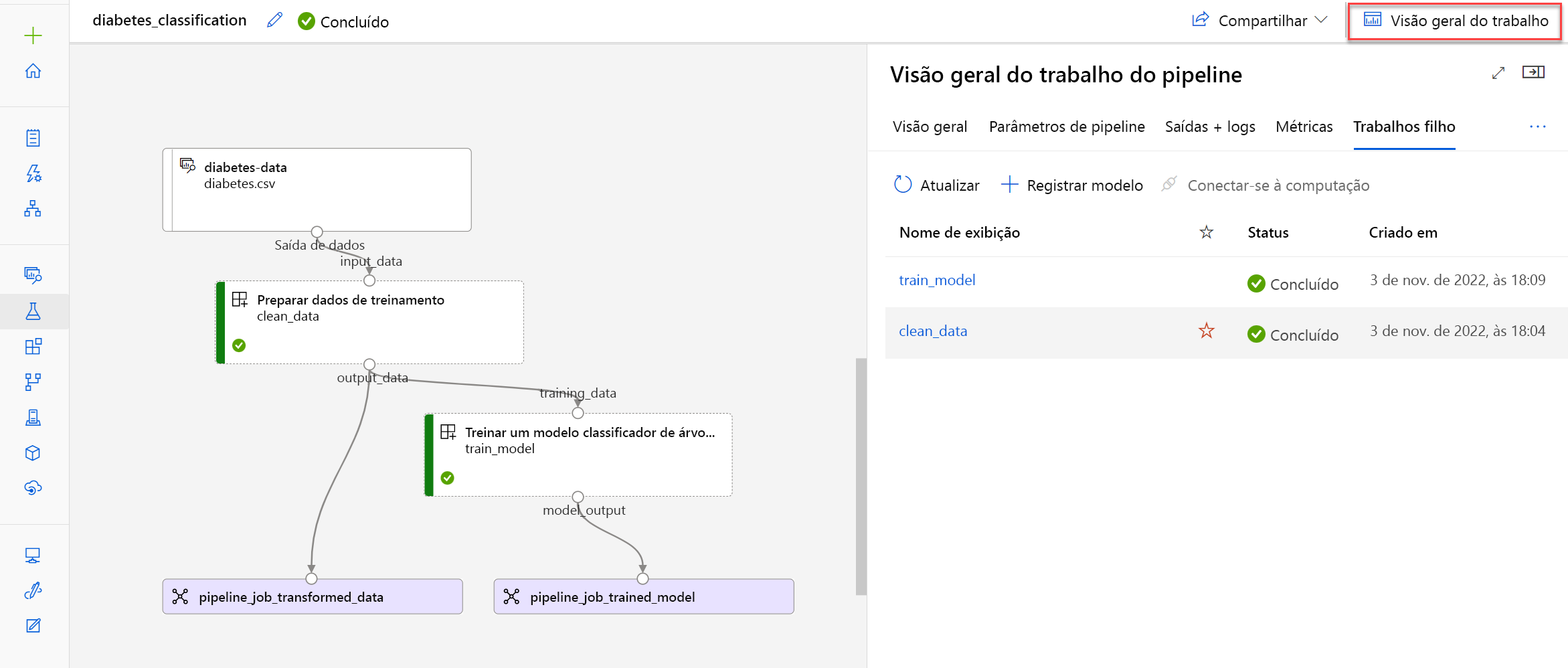
Para solucionar problemas de um pipeline com falha, você pode verificar as saídas e os logs do trabalho de pipeline e seus trabalhos filho.
- Se houver um problema com a configuração do pipeline em si, você encontrará mais informações nas saídas e logs do trabalho de pipeline.
- Se houver um problema com a configuração de um componente, você encontrará mais informações nas saídas e logs do trabalho filho do componente com falha.
Agendar um trabalho de pipeline
Um pipeline é ideal se você quiser preparar seu modelo para produção. Os pipelines são especialmente úteis para automatizar o retreinamento de um modelo de aprendizado de máquina. Para automatizar o retreinamento de um modelo, você pode agendar um pipeline.
Para agendar um trabalho de pipeline, você usará a JobSchedule classe para associar um agendamento a um trabalho de pipeline.
Há várias maneiras de criar uma agenda. Uma abordagem simples é criar um cronograma baseado em tempo usando a RecurrenceTrigger classe com os seguintes parâmetros:
frequency: Unidade de tempo para descrever a frequência com que o cronograma é acionado. O valor pode serminute,hour,day,week, oumonth.interval: Número de unidades de frequência para descrever a frequência com que o programa é acionado. O valor precisa ser um inteiro.
Para criar uma agenda que é acionada a cada minuto, execute o seguinte código:
from azure.ai.ml.entities import RecurrenceTrigger
schedule_name = "run_every_minute"
recurrence_trigger = RecurrenceTrigger(
frequency="minute",
interval=1,
)
Para agendar um pipeline, você precisará pipeline_job representar o pipeline que você criou:
from azure.ai.ml.entities import JobSchedule
job_schedule = JobSchedule(
name=schedule_name, trigger=recurrence_trigger, create_job=pipeline_job
)
job_schedule = ml_client.schedules.begin_create_or_update(
schedule=job_schedule
).result()
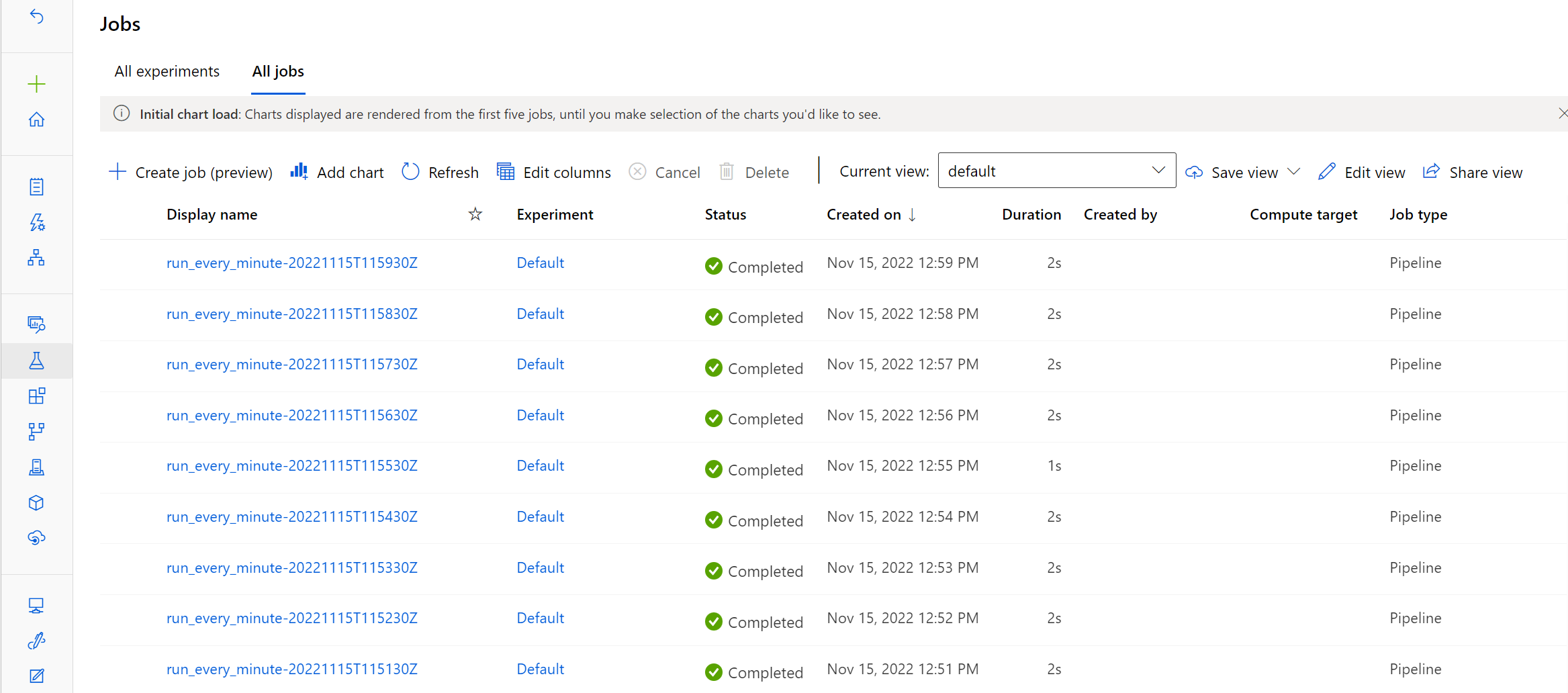
Os nomes de exibição dos trabalhos acionados pela agenda serão prefixados com o nome da sua agenda. Você pode revisar os trabalhos no estúdio do Azure Machine Learning:
Para excluir uma agenda, primeiro você precisa desativá-la:
ml_client.schedules.begin_disable(name=schedule_name).result()
ml_client.schedules.begin_delete(name=schedule_name).result()
Gorjeta
Saiba mais sobre as agendas que você pode criar para disparar trabalhos de pipeline no Aprendizado de Máquina do Azure. Ou explore um bloco de anotações de exemplo para aprender a trabalhar com horários.