Criar um pipeline
No Azure Machine Learning, um pipeline é um fluxo de trabalho de tarefas de aprendizado de máquina no qual cada tarefa é definida como um componente.
Os componentes podem ser organizados sequencialmente ou em paralelo, permitindo que você crie uma lógica de fluxo sofisticada para orquestrar operações de aprendizado de máquina. Cada componente pode ser executado em um alvo de computação específico, tornando possível combinar diferentes tipos de processamento conforme necessário para atingir um objetivo geral.
Um pipeline pode ser executado como um processo executando o pipeline como um trabalho de pipeline. Cada componente é executado como um trabalho filho como parte do trabalho de pipeline geral.
Construa um pipeline
Um pipeline do Azure Machine Learning é definido em um arquivo YAML. O arquivo YAML inclui o nome do trabalho de pipeline, entradas, saídas e configurações.
Você pode criar o arquivo YAML ou usar a @pipeline() função para criar o arquivo YAML.
Gorjeta
Analise a documentação de referência para a @pipeline() função.
Por exemplo, se você quiser criar um pipeline que primeiro prepara os dados e, em seguida, treina o modelo, você pode usar o seguinte código:
from azure.ai.ml.dsl import pipeline
@pipeline()
def pipeline_function_name(pipeline_job_input):
prep_data = loaded_component_prep(input_data=pipeline_job_input)
train_model = loaded_component_train(training_data=prep_data.outputs.output_data)
return {
"pipeline_job_transformed_data": prep_data.outputs.output_data,
"pipeline_job_trained_model": train_model.outputs.model_output,
}
Para passar um ativo de dados registrado como a entrada de trabalho de pipeline, você pode chamar a função criada com o ativo de dados como entrada:
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes
pipeline_job = pipeline_function_name(
Input(type=AssetTypes.URI_FILE,
path="azureml:data:1"
))
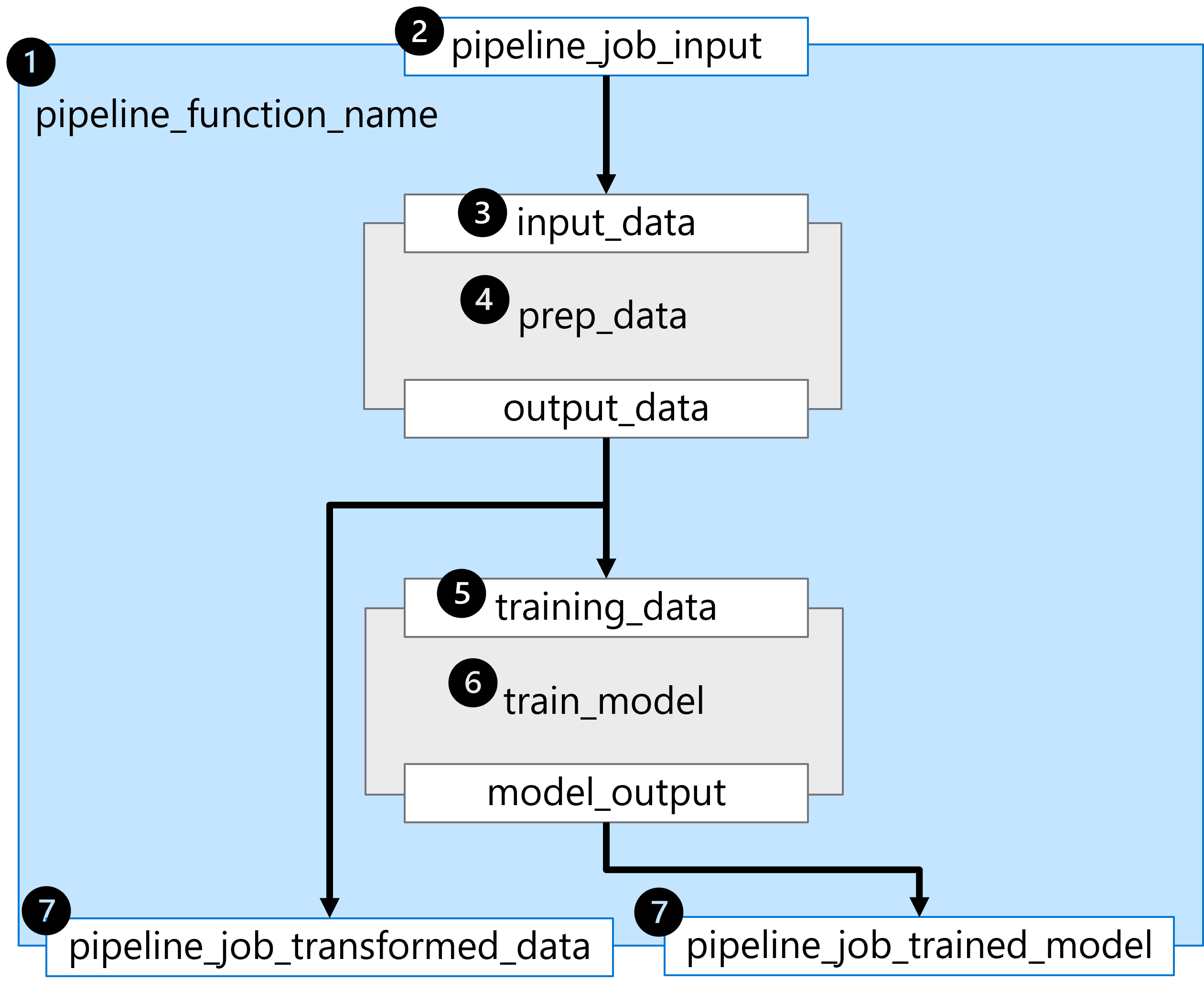
A @pipeline() função constrói um pipeline que consiste em duas etapas sequenciais, representadas pelos dois componentes carregados.
Para entender o pipeline construído no exemplo, vamos explorá-lo passo a passo:
- O pipeline é construído definindo a função
pipeline_function_name. - A função de pipeline espera
pipeline_job_inputcomo a entrada geral do pipeline. - A primeira etapa do pipeline requer um valor para o parâmetro
input_datade entrada. O valor para a entrada será o valor depipeline_job_input. - A primeira etapa do pipeline é definida pelo componente carregado para
prep_data. - O valor da
output_dataprimeira etapa do pipeline é usado para a entradatraining_dataesperada da segunda etapa do pipeline. - A segunda etapa do pipeline é definida pelo componente carregado para
train_modele resulta em um modelo treinado referido pormodel_output. - As saídas de pipeline são definidas retornando variáveis da função de pipeline.
Existem duas saídas:
pipeline_job_transformed_datacom o valor deprep_data.outputs.output_datapipeline_job_trained_modelcom o valor detrain_model.outputs.model_output
O resultado da execução da @pipeline() função é um arquivo YAML que você pode revisar imprimindo o pipeline_job objeto criado ao chamar a função:
print(pipeline_job)
A saída será formatada como um arquivo YAML, que inclui a configuração do pipeline e seus componentes. Alguns parâmetros incluídos no arquivo YAML são mostrados no exemplo a seguir.
display_name: pipeline_function_name
type: pipeline
inputs:
pipeline_job_input:
type: uri_file
path: azureml:data:1
outputs:
pipeline_job_transformed_data: null
pipeline_job_trained_model: null
jobs:
prep_data:
type: command
inputs:
input_data:
path: ${{parent.inputs.pipeline_job_input}}
outputs:
output_data: ${{parent.outputs.pipeline_job_transformed_data}}
train_model:
type: command
inputs:
input_data:
path: ${{parent.outputs.pipeline_job_transformed_data}}
outputs:
output_model: ${{parent.outputs.pipeline_job_trained_model}}
tags: {}
properties: {}
settings: {}
Gorjeta
Saiba mais sobre o esquema YAML do trabalho de pipeline para explorar quais parâmetros são incluídos ao criar um pipeline baseado em componentes.