Usar o Apache Phoenix no HDInsight HBase
Os clusters HBase no HDInsight são fornecidos com o Apache Phoenix. O Apache Phoenix é uma camada de banco de dados relacional massivamente paralela de código aberto construída no Apache HBase. O Apache Phoenix permite que você use consultas do tipo SQL no HBase. Ele usa drivers JDBC abaixo para permitir que os usuários criem, excluam e alterem tabelas SQL. Você também pode indexar, criar exibições e sequências e upsert linhas individualmente e em massa. Phoenix usa compilação nativa noSQL em vez de usar MapReduce para compilar consultas, permitindo a criação de aplicativos de baixa latência sobre o HBase. Phoenix adiciona coprocessadores para suportar a execução de código fornecido pelo cliente no espaço de endereço do servidor, executando o código colocalizado com os dados. Essa abordagem minimiza a transferência de dados cliente/servidor. Para obter mais informações, consulte a documentação do Apache Phoenix.
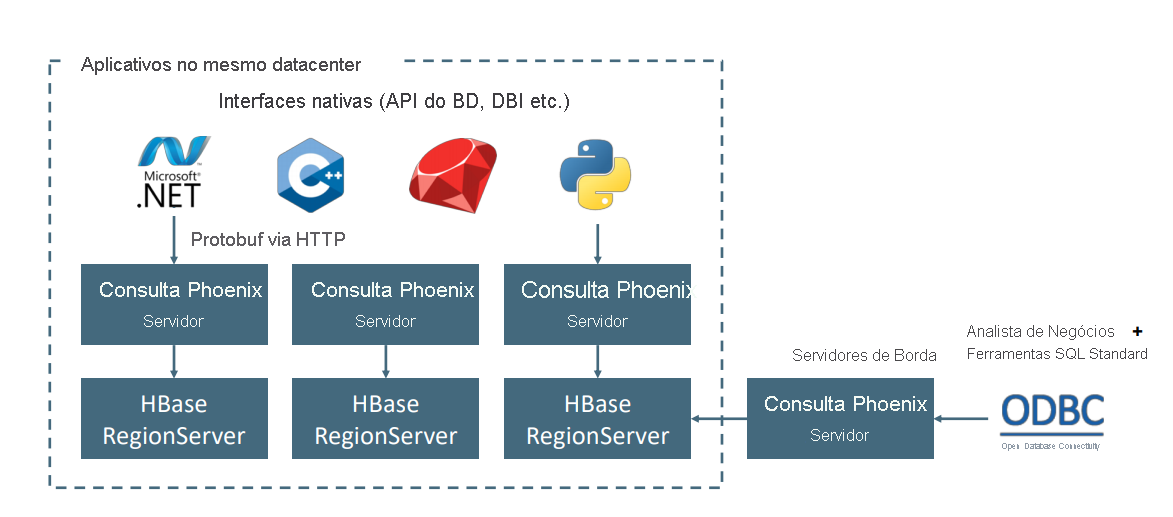
O Apache Phoenix no HDInsight HBase é normalmente usado para habilitar análises de autoatendimento e extrair informações, conforme descrito abaixo. Phoenix pode se conectar a qualquer ferramenta de BI compatível com ODBC e habilitar análises SQL ad-hoc no HBase.
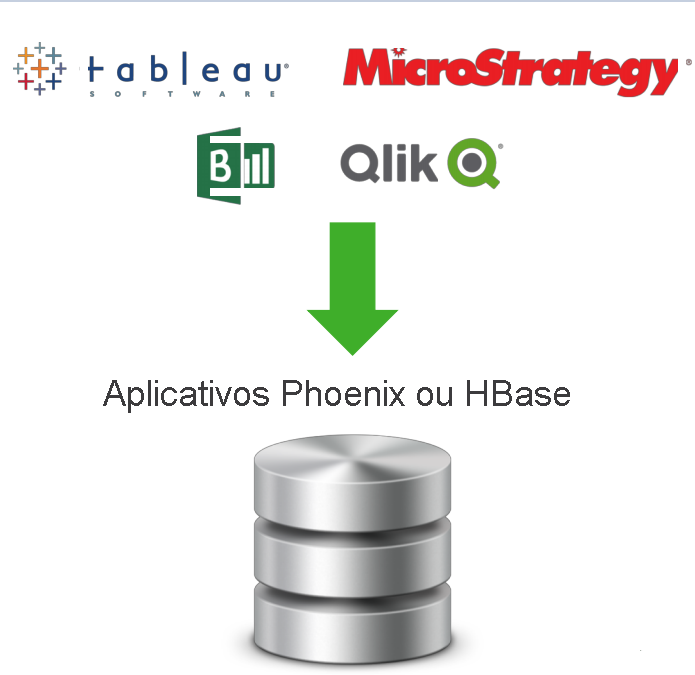
A combinação do Apache HBase e do Phoenix pode ser usada como um armazenamento de dados para dados mutáveis. O mecanismo de consulta Apache Phoenix no HBase vem com alguns recursos importantes.
Índices secundários
Os registros no HBase são acessados usando a chave de linha primária usando um único índice que é classificado lexicograficamente na chave de linha primária. Se você tentar acessar os registros de qualquer outra forma que não seja a linha primária, isso levaria a uma verificação ineficiente de todos os dados na tabela do HBase. O Apache Phoenix permite que você crie índices secundários em colunas e expressões para criar chaves de linha alternativas para permitir pesquisas de pontos ou varreduras de intervalo ao longo desse novo índice. Para obter mais informações, consulte a documentação do Apache Phoenix Secondary Indexes.
O comando CREATE INDEX é usado para criar índices secundários no HBase, conforme mostrado abaixo.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Visualizações
Limitar o número de tabelas físicas no HBase e, por sua vez, limitar o número de regiões é uma estratégia recomendada. As visualizações em Phoenix ajudam nessa recomendação, permitindo a criação de várias tabelas virtuais compartilhando a mesma tabela física subjacente no HBase. Para obter mais informações, consulte a documentação do Apache Phoenix Views.
Dada a definição da tabela abaixo em HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Você pode definir o modo de exibição a seguir.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transações
Enquanto o HBase funciona apenas com transações de nível de linha, o Apache Phoenix permite transações entre tabelas e entre linhas com suporte total a ACID por meio da integração com o Apache Tephra.
Para obter mais informações, consulte a documentação do Apache Phoenix Transactions
O exemplo a seguir cria uma tabela chamada my_table e, em seguida, altera a tabela para habilitar transações.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Mesas Salgadas
O hotspot do Servidor de Região no HBase pode ocorrer durante gravações sequenciais se as chaves de linha aumentarem monotonicamente. O Apache Phoenix pode aliviar o hotspotting fornecendo uma maneira de salgar a chave de linha com um byte de salga para uma tabela específica. Para obter mais informações, consulte a documentação da Tabela Salgada do Apache Phoenix.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Saltar verificação
Para um determinado conjunto de linhas, o Apache Phoenix usa o Skip Scan para varredura intra-linha em uma varredura de intervalo para melhorar o desempenho. O Skip Scan aproveita o SEEK_NEXT_USING_HINT Filtro HBase. Ele armazena informações sobre qual conjunto de chaves/intervalos de chaves estão sendo pesquisados em cada coluna. Em seguida, ele pega uma chave (passada para ela durante a avaliação do filtro) e descobre se ela está em uma das combinações ou intervalo ou não. Se não, ele descobre para qual próxima chave mais alta para saltar. Para obter mais informações, consulte a documentação do Apache Phoenix Skip Scan.
A otimização de desempenho no Apache Phoenix é um recurso opcional solicitado e depende principalmente da otimização do desempenho do HBase por baixo. A otimização de desempenho é um tópico complexo e está além do escopo deste curso. No entanto, se estiver interessado, pode consultar a documentação sobre as melhores práticas de desempenho do Apache Phoenix.