Descrever o Apache HBase
O Apache HBase é um banco de dados NoSQL de código aberto que é construído no Apache Hadoop. O HBase fornece acesso aleatório e forte consistência para grandes quantidades de dados não estruturados e semiestruturados em um banco de dados sem esquema organizado por famílias de colunas. Os clusters HBase do HDInsight 4.0 são fornecidos com o Apache HBase 2.1.6 e o Apache Phoenix 5.
Do ponto de vista do usuário, o HBase é semelhante a um banco de dados. Os dados são armazenados nas linhas e colunas de uma tabela e os dados dentro de uma linha são agrupados por família de colunas. O HBase é uma base de dados sem esquema uma vez que não é preciso definir as colunas nem os tipos de dados nelas armazenados antes de os utilizar. O código open source é dimensionado linearmente para processar petabytes de dados em milhares de nós.
O HBase tem as seguintes características que o tornam único:
Leitura e gravação consistentes
Operações de baixa latência
Compartilhamento automático
Failovers automáticos do Servidor de Região
Integração Hadoop/HDFS/MapReduce
API do cliente Java
Suporta Thrift e REST para front-ends não-java
Bloquear cache e filtros Bloom
O Azure HDInsight HBase com Apache Phoenix traz os seguintes benefícios extras
Interfaces SQL e Sem SQL
Planejamento de capacidade flexível
Distribuição global e replicação com rede do Azure
Separação de computação e armazenamento
Totalmente integrado com os recursos de segurança do HDInsight Enterprise
Gravações aceleradas do HDInsight HBase para leituras e gravações de latência ultrabaixa
Apache Phoenix para SQL em tempo real como consulta
Usar o Azure HDInsight com o HBase permite executar bancos de dados NoSQL em grande escala. Como engenheiro de dados de uma Contoso, você precisa ser capaz de executar testes de referência para entender o desempenho e a escala do HDInsight HBase antes de usar a plataforma para cenários de produção de missão crítica.
O HBase no HDInsight é executado com a separação de computação e armazenamento. Os clusters HBase do HDInsight são configurados para armazenar dados diretamente no Armazenamento do Azure, o que fornece baixa latência e maior elasticidade nas opções de desempenho e custo. Essa propriedade permite que os clientes criem sites interativos que funcionam com grandes conjuntos de dados. Para criar serviços que armazenam dados de sensores e telemetria de milhões de pontos finais e analisar esses dados com trabalhos do Hadoop. O HBase e o Hadoop são bons pontos de partida para projetos de big data no Azure. Os serviços podem permitir que aplicativos em tempo real trabalhem com grandes conjuntos de dados. As implementações do HBase do HDInsight usam uma arquitetura de expansão do HBase para fornecer fragmentação automática de tabelas. Ele também fornece forte consistência para leituras e gravações e failover automático. O desempenho é melhorado graças à colocação em cache dentro da memória para as operações de leitura e à transmissão em fluxo de alto débito para as operações de escrita. O cluster HBase pode ser criado no interior da rede virtual. Para obter mais detalhes, veja Create HDInsight clusters on Azure Virtual Network (Criar clusters do HDInsight na Rede Virtual do Azure).
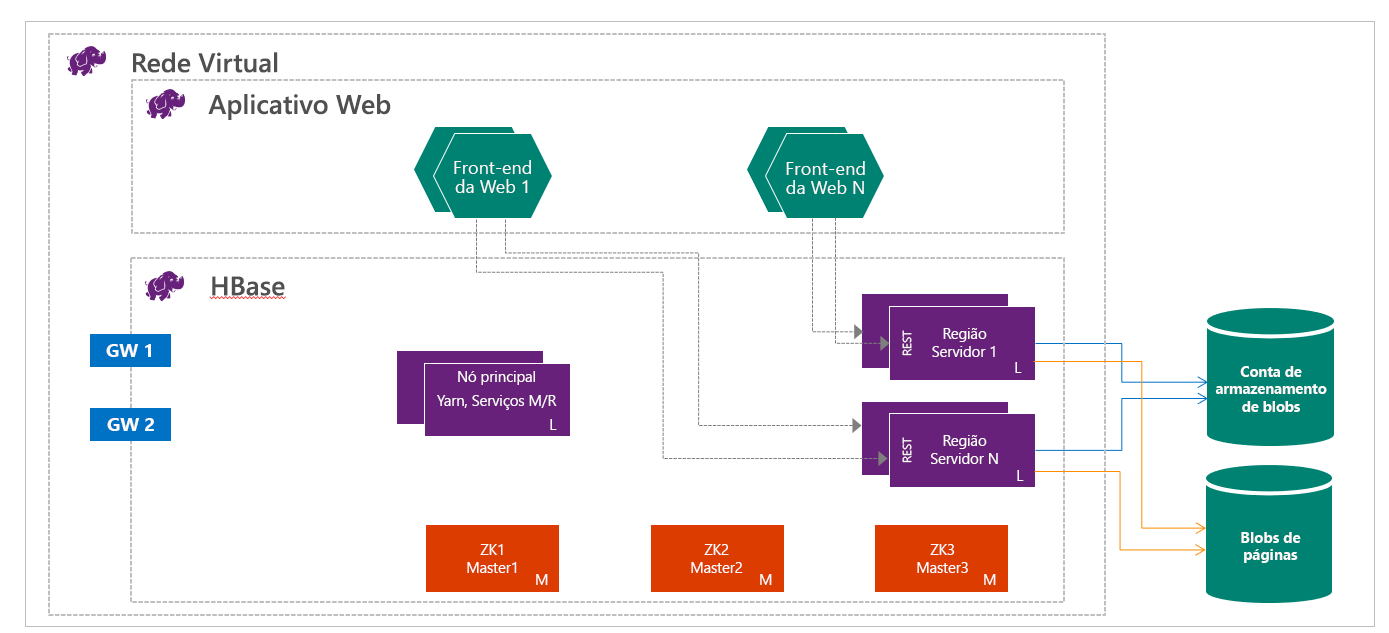
Como engenheiro de dados, você precisa determinar o tipo mais apropriado de cluster HDInsight a ser criado para criar sua solução. Você usará clusters HBase no HDInsight para um banco de dados NoSQL que é dimensionado linearmente, alcançando uma enorme quantidade de taxa de transferência, fornece leituras de baixa latência e armazenamento ilimitado na fração do custo.
A seguir estão os principais cenários para usar o HBase no HDInsight.
Arquivo de chave-valor
O HBase é normalmente usado como um armazenamento de chave-valor e é adequado para gerenciar sistemas de mensagens.
Dados de sensores
O HBase é útil para capturar dados coletados incrementalmente de várias fontes, o que inclui análises sociais, séries temporais, manter painéis interativos atualizados com tendências e contadores e gerenciar sistemas de log de auditoria.
Consulta em tempo real
Apache Phoenix é um mecanismo de consulta SQL para Apache HBase. Ele é acessado como um driver JDBC e permite consultar e gerenciar tabelas do HBase usando SQL.
HBase como uma plataforma
As aplicações podem ser executadas sobre o HBase ao utilizá-lo como um arquivo de dados. Os exemplos incluem Phoenix, OpenTSDB, Kiji e Titan. As aplicações também podem ser integradas no HBase. Exemplos incluem Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia e Apache Drill.
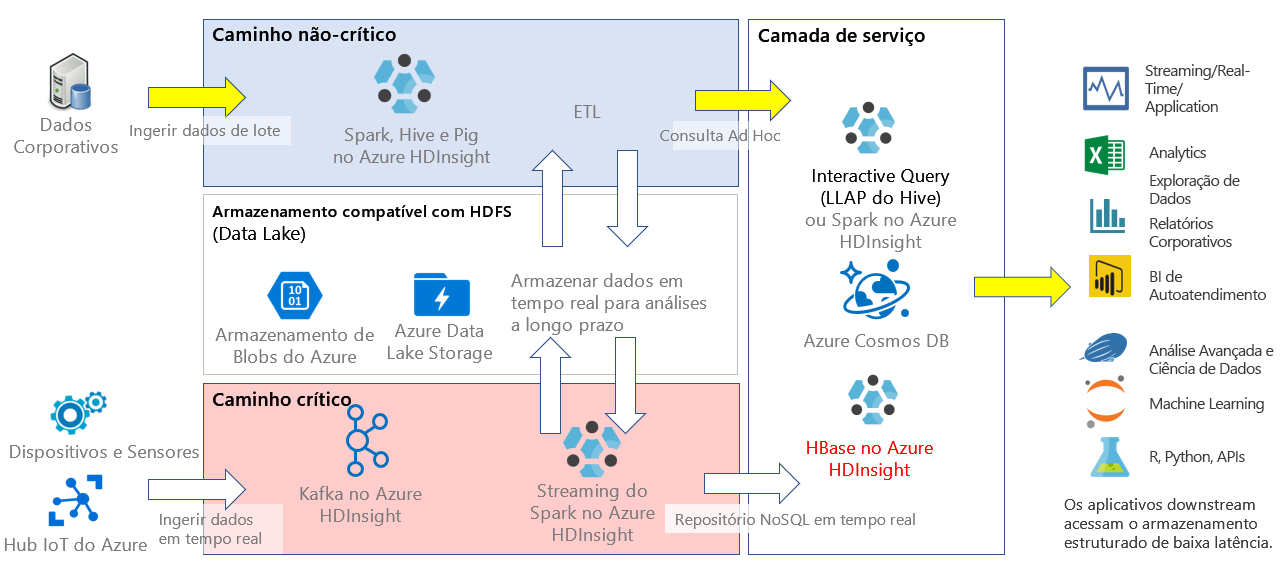
No HDInsight, o HBase pode ser usado como aplicativo autônomo ou implantado junto com outros aplicativos de análise de big data, como Spark, Hadoop, Hive ou Kafka.
O modelo de dados do HBase armazena dados semiestruturados com diferentes tipos de dados, variando o tamanho da coluna e do campo. O layout do modelo de dados do HBase facilita o particionamento e a distribuição de dados no cluster. O modelo de dados do HBase consiste em vários componentes lógicos - chaves de linha, família de colunas, nome da tabela, carimbo de data/hora, etc.
Uma chave de linha é usada para identificar exclusivamente as linhas nas tabelas do HBase. No HDInsight, você pode gravar os dados no HBase diretamente usando as várias APIs disponíveis, como HBase REST, HBase RPC, Phoenix Query Server, HBase bulk load, ou usar a integração com várias estruturas de big data, como Apache Spark, Hive etc.
Você pode aproveitar o recurso de gravações aceleradas do HBase para habilitar uma alta taxa de transferência de gravação. Para saber mais sobre a arquitetura do HBase e as práticas recomendadas, consulte o Livro do HBase.