Exercício: proteger, monitorar e ajustar um banco de dados migrado
Você trabalha como desenvolvedor de banco de dados para a organização AdventureWorks. A AdventureWorks vende bicicletas e peças de bicicletas diretamente para consumidores finais e distribuidores há mais de uma década. Seus sistemas armazenam informações em um banco de dados que você migrou anteriormente para o Banco de Dados do Azure para PostgreSQL.
Depois de ter realizado a migração, você quer ter a garantia de que o sistema está funcionando bem. Você decide usar as ferramentas do Azure disponíveis para monitorar o servidor. Para aliviar a possibilidade de tempos de resposta lentos causados por contenção e latência, você decide implementar a replicação de leitura. Você precisa monitorar o sistema resultante e comparar os resultados com a arquitetura de servidor flexível.
Neste exercício, você executará as seguintes tarefas:
- Configure métricas do Azure para seu serviço Banco de Dados do Azure para PostgreSQL.
- Execute um aplicativo de exemplo que simula vários usuários consultando o banco de dados.
- Veja as métricas.
Configurar o ambiente
Execute esses comandos da CLI do Azure no Cloud Shell para criar um banco de dados do Azure para PostgreSQL, com uma cópia do banco de dados adventureworks. Os últimos comandos imprimirão o nome do servidor.
SERVERNAME="adventureworks$((10000 + RANDOM % 99999))"
PUBLICIP=$(wget http://ipecho.net/plain -O - -q)
git clone https://github.com/MicrosoftLearning/DP-070-Migrate-Open-Source-Workloads-to-Azure.git workshop
az postgres server create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--name $SERVERNAME \
--location westus \
--admin-user awadmin \
--admin-password Pa55w.rdDemo \
--version 10 \
--storage-size 5120
az postgres db create \
--name azureadventureworks \
--server-name $SERVERNAME \
--resource-group <rgn>[sandbox resource group name]</rgn>
az postgres server firewall-rule create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--server $SERVERNAME \
--name AllowMyIP \
--start-ip-address $PUBLICIP --end-ip-address $PUBLICIP
PGPASSWORD=Pa55w.rdDemo psql -h $SERVERNAME.postgres.database.azure.com -U awadmin@$SERVERNAME -d postgres -f workshop/migration_samples/setup/postgresql/adventureworks/create_user.sql
PGPASSWORD=Pa55w.rd psql -h $SERVERNAME.postgres.database.azure.com -U azureuser@$SERVERNAME -d azureadventureworks -f workshop/migration_samples/setup/postgresql/adventureworks/adventureworks.sql 2> /dev/null
echo "Your PostgreSQL server name is:\n"
echo $SERVERNAME.postgres.database.azure.com
Configurar métricas do Azure para seu serviço Banco de Dados do Azure para PostgreSQL
Usando um navegador da Web, abra uma nova guia e navegue até o portal do Azure.
No portal do Azure, selecione Todos os recursos.
Selecione o Banco de Dados do Azure para o nome do servidor PostgreSQL começando com adventureworks.
Em Monitorização, selecione Métricas.
Na página do gráfico, adicione a seguinte métrica:
Property valor Âmbito AdventureWorks[NNN] Espaço de Nomes das Métricas Métricas padrão do servidor PostgreSQL Metric Conexões ativas Agregação Preço médio Essa métrica exibe o número médio de conexões feitas ao servidor a cada minuto.
Selecione Adicionar métrica e adicione a seguinte métrica:
Property valor Âmbito AdventureWorks[NNN] Espaço de Nomes das Métricas Métricas padrão do servidor PostgreSQL Metric Percentagem de CPU Agregação Preço médio Selecione Adicionar métrica e adicione a seguinte métrica:
Property valor Âmbito AdventureWorks[NNN] Espaço de Nomes das Métricas Métricas padrão do servidor PostgreSQL Metric Percentagem de memória Agregação Preço médio Selecione Adicionar métrica e adicione a seguinte métrica:
Property valor Âmbito AdventureWorks[NNN] Espaço de Nomes das Métricas Métricas padrão do servidor PostgreSQL Metric Percentagem de IO Agregação Preço médio Essas três métricas finais mostram como os recursos estão sendo consumidos pelo aplicativo de teste.
Defina o intervalo de tempo do gráfico como Últimos 30 minutos.
Selecione Fixar no Painel e, em seguida, selecione Fixar.
Executar um aplicativo de exemplo que simula vários usuários consultando o banco de dados
No portal do Azure, na página do seu Banco de Dados do Azure para servidor PostgreSQL, em Configurações, selecione Cadeias de Conexão. Copie a cadeia de ligação ADO.NET para a área de transferência.
Mova para a pasta ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest .
cd ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTestAbra o arquivo App.config usando o editor de código:
code App.configSubstitua o valor de Database por azureadventureworks e substitua ConectionString0 pela cadeia de conexão da área de transferência. Altere o ID de usuário para azureuser@adventureworks[nnn] e defina a senha como Pa55w.rd. O arquivo concluído deve ser semelhante ao exemplo abaixo:
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="INSERT CONNECTION STRING HERE" /> <add key="ConnectionString2" value="INSERT CONNECTION STRING HERE" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="1"/> </appSettings> </configuration>Nota
Ignore as configurações de ConnectionString1 e ConnectionString2 por enquanto. Você atualizará esses itens posteriormente no laboratório.
Salve as alterações e feche o editor.
No prompt do Cloud Shell, execute o seguinte comando para criar e executar o aplicativo:
dotnet runQuando o aplicativo é iniciado, ele gera vários threads, cada thread simulando um usuário. Os threads executam um loop, executando uma série de consultas. Você verá mensagens como as mostradas abaixo começando a aparecer:
Client 48 : SELECT * FROM purchasing.vendor Response time: 630 ms Client 48 : SELECT * FROM sales.specialoffer Response time: 702 ms Client 43 : SELECT * FROM purchasing.vendor Response time: 190 ms Client 57 : SELECT * FROM sales.salesorderdetail Client 68 : SELECT * FROM production.vproductanddescription Response time: 51960 ms Client 55 : SELECT * FROM production.vproductanddescription Response time: 160212 ms Client 59 : SELECT * FROM person.person Response time: 186026 ms Response time: 2191 ms Client 37 : SELECT * FROM person.person Response time: 168710 msDeixe o aplicativo em execução enquanto executa as próximas etapas.
Veja as métricas
Regresse ao portal do Azure.
No painel esquerdo, selecione Painel.
Você deve ver o gráfico exibindo as métricas do seu serviço Banco de Dados do Azure para PostgreSQL.
Selecione o gráfico para abri-lo no painel Métricas .
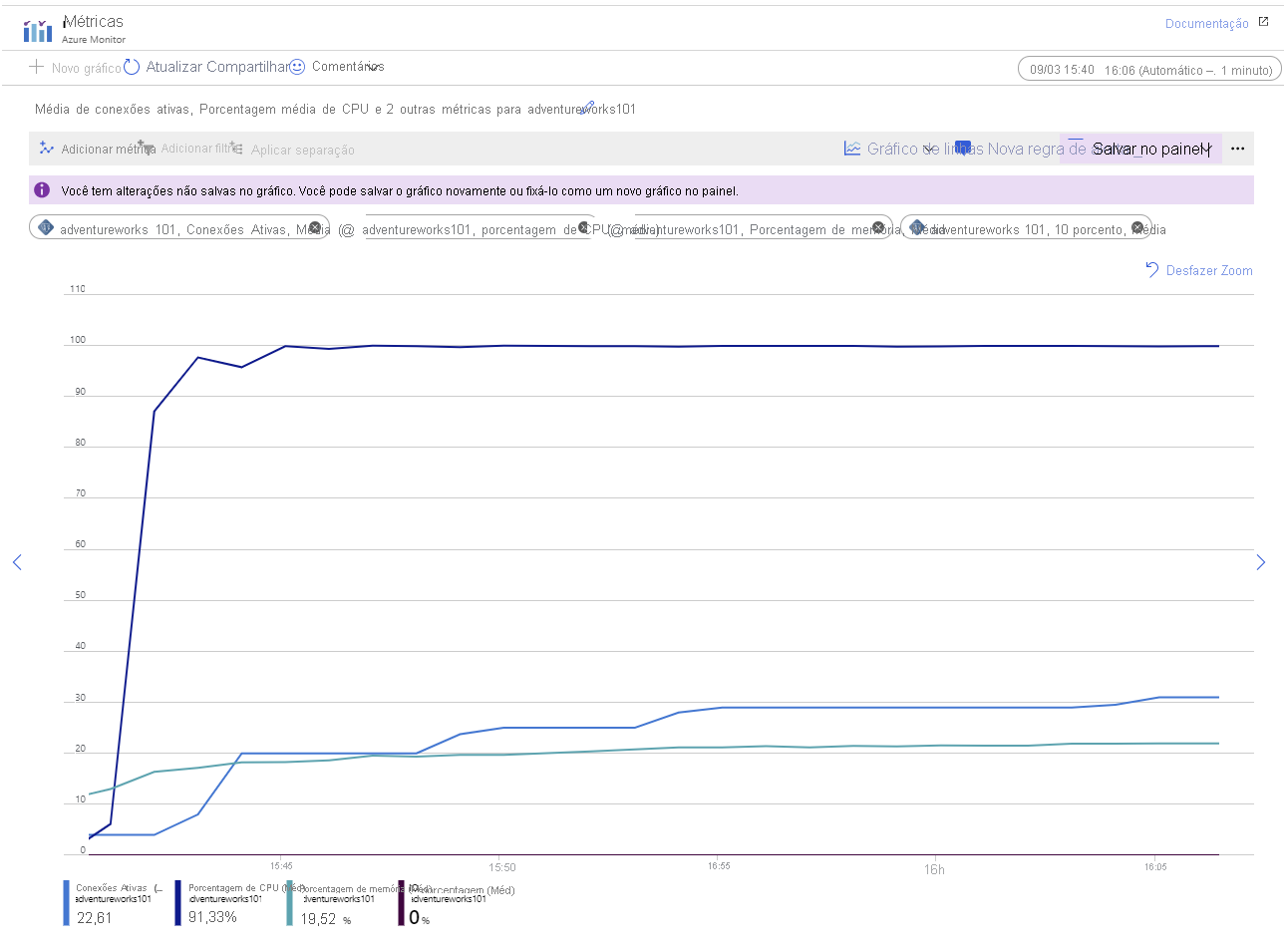
Permita que o aplicativo seja executado por vários minutos (quanto mais tempo, melhor). Com o passar do tempo, as métricas no gráfico devem se assemelhar ao padrão ilustrado na imagem a seguir:
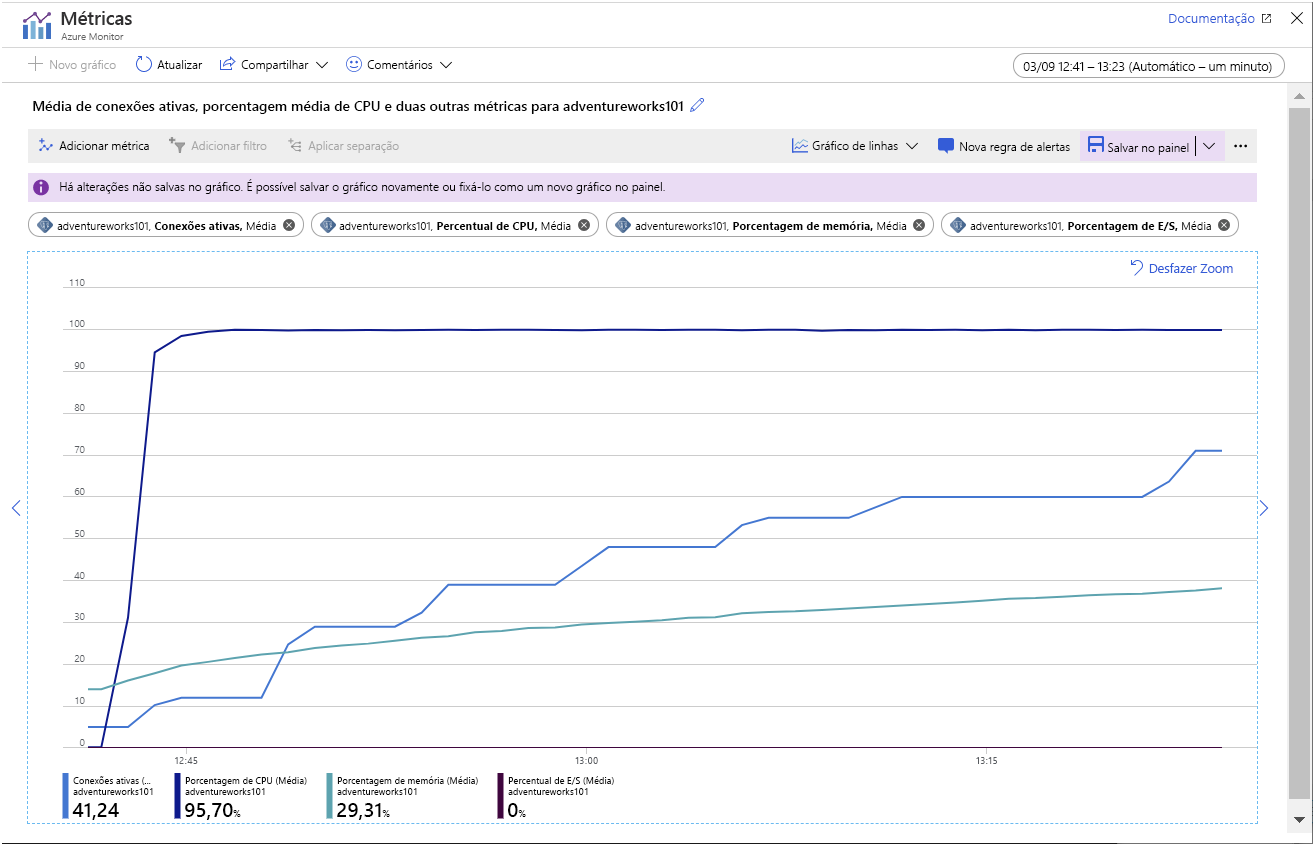
Este gráfico destaca os seguintes pontos:
- A CPU está funcionando em plena capacidade; A utilização atinge 100% muito rapidamente.
- O número de conexões aumenta lentamente. O aplicativo de exemplo é projetado para iniciar 101 clientes em rápida sucessão, mas o servidor só pode lidar com a abertura de algumas conexões de cada vez. O número de conexões adicionadas em cada "etapa" no gráfico está ficando menor, e o tempo entre as "etapas" está aumentando. Após aproximadamente 45 minutos, o sistema só foi capaz de estabelecer 70 conexões de clientes.
- A utilização da memória está aumentando consistentemente ao longo do tempo.
- A utilização de IO está próxima de zero. Todos os dados exigidos pelos aplicativos cliente estão atualmente armazenados em cache na memória.
Se você deixar o aplicativo funcionando por tempo suficiente, verá conexões começando a falhar, com as mensagens de erro mostradas na imagem a seguir.
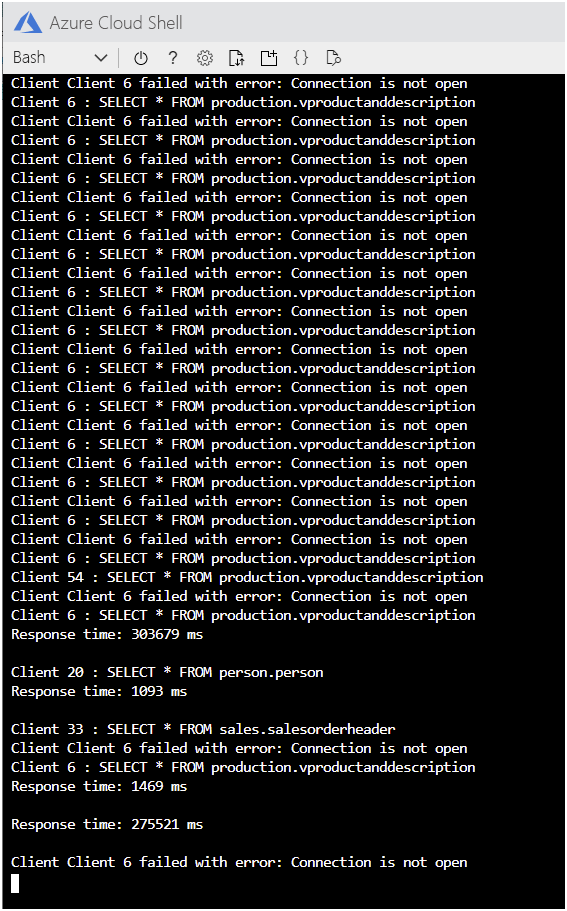
No Cloud Shell, pressione Enter para parar o aplicativo.
Configurar o servidor para coletar dados de desempenho de consulta
No portal do Azure, na página do seu Banco de Dados do Azure para servidor PostgreSQL, em Configurações, selecione Parâmetros do servidor.
Na página Parâmetros do servidor, defina os seguintes parâmetros para os valores especificados na tabela abaixo.
Parâmetro Valor pg_qs.max_query_text_length 6000 pg_qs.query_capture_mode TODOS pg_qs.replace_parameter_placeholders EM pg_qs.período_de_retenção_em_dias 7 pg_qs.track_utilitário EM pg_stat_statements.track TODOS pgms_wait_sampling.período_história 100 pgms_wait_sampling.query_capture_mode TODOS Selecione Guardar.
Examine as consultas executadas pelo aplicativo usando o Repositório de Consultas
Retorne ao Cloud Shell e reinicie o aplicativo de exemplo:
dotnet runPermita que o aplicativo seja executado por cerca de 5 minutos antes de continuar.
Deixe o aplicativo em execução e alterne para o portal do Azure
Na página do seu Banco de Dados do Azure para servidor PostgreSQL, em Desempenho inteligente, selecione Query Performance Insight.
Na página Insight do Desempenho da Consulta, na guia Consultas de longa execução, defina Número de consultas como 10, defina Selecionado por como avg e defina o período de tempo como Últimas 6 horas.
Acima do gráfico, selecione Ampliar (o ícone da lupa com o sinal de "+") algumas vezes, para acompanhar os dados mais recentes.
Dependendo de quanto tempo você deixou o aplicativo funcionar, você verá um gráfico semelhante ao mostrado abaixo. O Repositório de Consultas agrega as estatísticas de consultas a cada 15 minutos, de modo que cada barra mostra o tempo relativo consumido por cada consulta em cada período de 15 minutos:
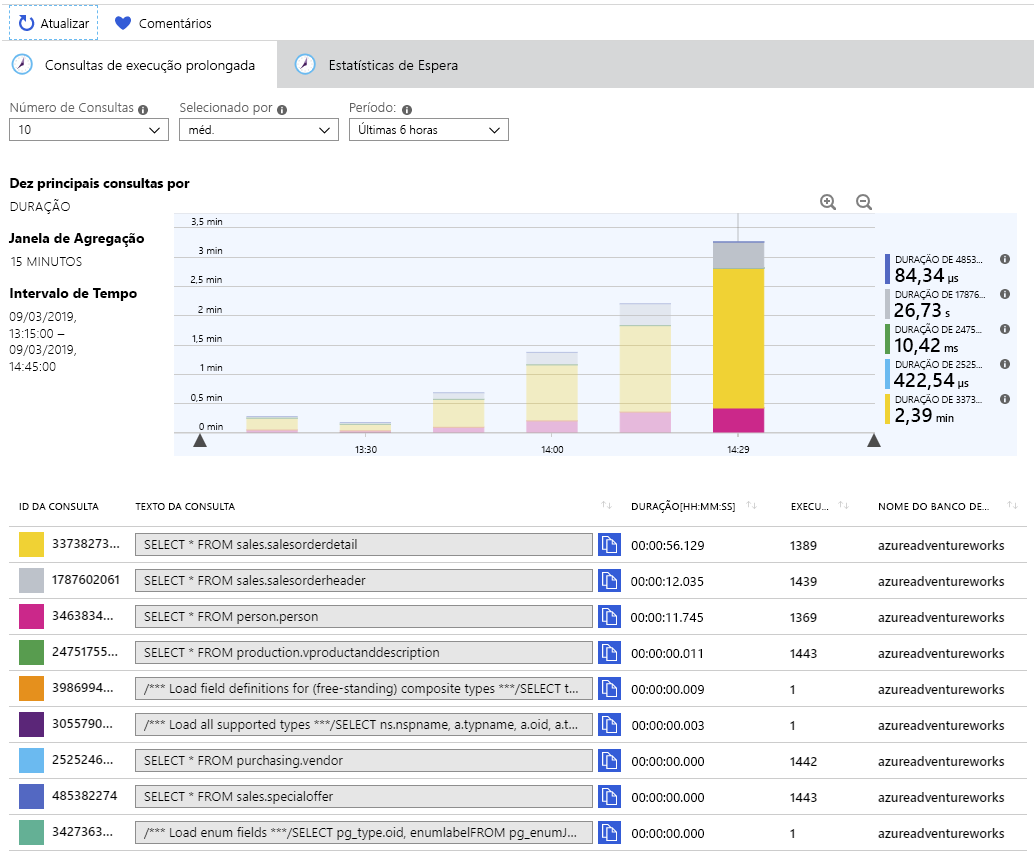
Passe o mouse sobre cada barra para visualizar as estatísticas das consultas nesse período de tempo. As três consultas que o sistema está gastando a maior parte do tempo realizando são:
SELECT * FROM sales.salesorderdetail SELECT * FROM sales.salesorderheader SELECT * FROM person.personEssas informações são úteis para um administrador que monitora um sistema. Ter uma visão sobre as consultas que estão sendo executadas por usuários e aplicativos permite que você entenda as cargas de trabalho que estão sendo executadas e, possivelmente, faça recomendações aos desenvolvedores de aplicativos sobre como eles podem melhorar seu código. Por exemplo, é realmente necessário que um aplicativo recupere todas as 121.000+ linhas da tabela sales.salesorderdetail ?
Examinar quaisquer esperas que ocorram usando o Repositório de Consultas
Selecione a guia Estatísticas de espera.
Defina o período de tempo para Últimas 6 horas, defina Grupo por para Evento e defina o Número Máximo de Grupos como 5.
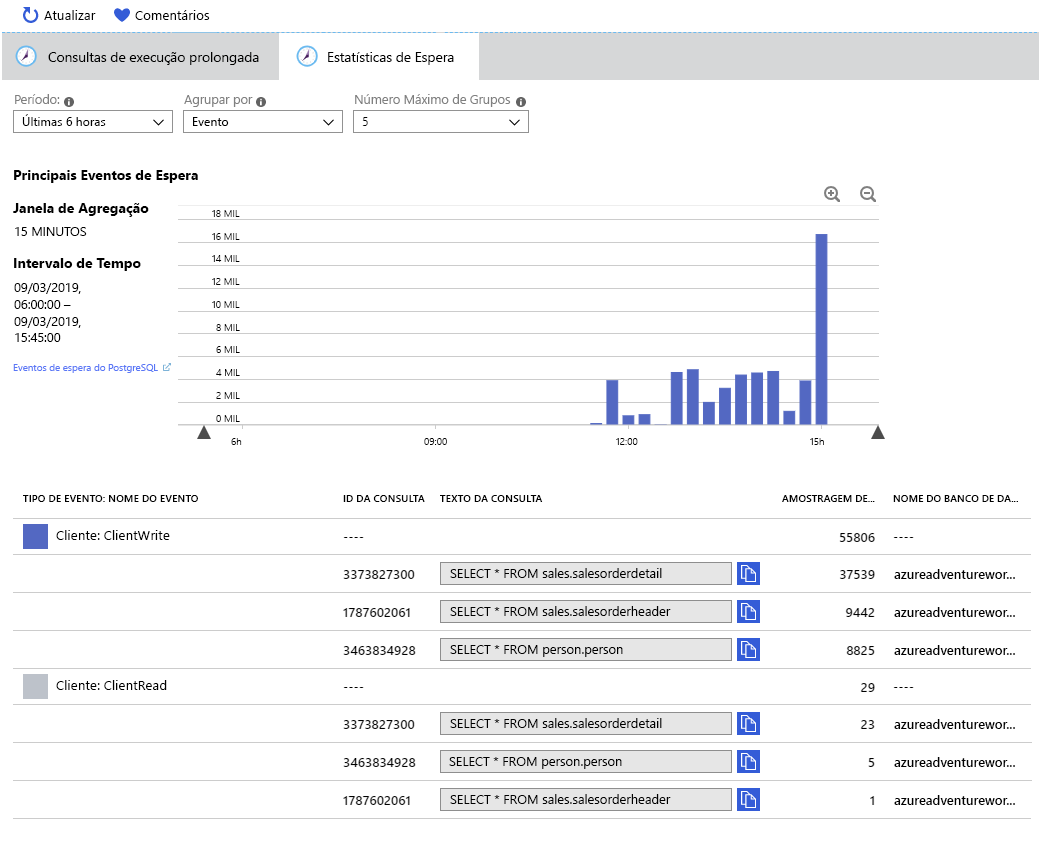
Assim como na guia Consultas de longa duração, os dados são agregados a cada 15 minutos. A tabela abaixo do gráfico mostra que o sistema foi objeto de dois tipos de evento de espera:
- Cliente: ClientWrite. Esse evento de espera ocorre quando o servidor está gravando dados (resultados) de volta para o cliente. Ele não indica esperas incorridas durante a gravação no banco de dados.
- Cliente: ClientRead. Esse evento de espera ocorre quando o servidor está aguardando para ler dados (solicitações de consulta ou outros comandos) de um cliente. Não está associado ao tempo gasto a ler a partir da base de dados.
Nota
A leitura e a gravação no banco de dados são indicadas por eventos de E/ S em vez de eventos de Cliente . O aplicativo de exemplo não incorre em nenhuma espera de E/S, pois todos os dados necessários são armazenados em cache na memória após a primeira leitura. Se as métricas mostrassem que a memória estava acabando, você provavelmente veria os eventos de espera de E/S começarem a ocorrer.
Retorne ao Cloud Shell e pressione Enter para parar o aplicativo de exemplo.
Adicionar réplicas ao serviço Banco de Dados do Azure para PostgreSQL
No portal do Azure, na página do seu Banco de Dados do Azure para servidor PostgreSQL, em Configurações, selecione Replicação.
Na página Replicação, selecione + Adicionar réplica.
Na página do servidor PostgreSQL, na caixa Nome do servidor, digite adventureworks[nnn]-replica1 e selecione OK.
Quando a primeira réplica tiver sido criada (levará vários minutos), repita a etapa anterior e adicione outra réplica chamada adventureworks[nnn]-replica2.
Aguarde até que o status de ambas as réplicas mude de Implantando para Disponível antes de continuar.
Configurar as réplicas para habilitar o acesso do cliente
- Selecione o nome da réplica adventureworks[nnn]-replica1 . Você será direcionado para a página do Banco de Dados do Azure para PostgreSQL dessa réplica.
- Em Configurações, selecione Segurança da conexão.
- Na página Segurança da conexão , defina Permitir acesso aos serviços do Azure como ATIVADO e selecione Salvar. Essa configuração permite que os aplicativos executados usando o Cloud Shell acessem o servidor.
- Quando a configuração tiver sido salva, repita as etapas anteriores e permita que os serviços do Azure acessem a réplica adventureworks[nnn]-replica2 .
Reinicie cada servidor
Nota
A configuração da replicação não requer a reinicialização de um servidor. O objetivo desta tarefa é limpar a memória e quaisquer conexões estranhas de cada servidor, para que as métricas coletadas ao executar o aplicativo novamente sejam limpas.
- Vá para a página do servidor adventureworks[nnn].
- Na página Visão geral, selecione Reiniciar.
- Na caixa de diálogo Reiniciar servidor, selecione Sim.
- Aguarde até que o servidor seja reiniciado antes de continuar.
- Seguindo o mesmo procedimento, reinicie os servidores adventureworks[nnn]-replica1 e adventureworks[nnn]-replica2 .
Reconfigurar o aplicativo de exemplo para usar as réplicas
No Cloud Shell, edite o arquivo App.config.
code App.configAdicione as cadeias de caracteres de conexões para as configurações ConnectionString1 e ConnectionString2 . Esses valores devem ser os mesmos de ConnectionString0, mas com o texto adventureworks[nnn] substituído por adventureworks[nnn]-replica1 e adventureworks[nnn]-replica2 nos elementos Server e User Id.
Defina a configuração NumReplicas como 3.
O arquivo App.config agora deve ser semelhante a este:
<configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="Server=adventureworks101-replica1.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica1;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString2" value="Server=adventureworks101-replica2.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica2;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="3"/> </appSettings> </configuration>Guarde o ficheiro e feche o editor.
Inicie o aplicativo em execução novamente:
dotnet runO aplicativo será executado como antes. No entanto, desta vez, as solicitações são distribuídas pelos três servidores.
Permita que o aplicativo seja executado por alguns minutos antes de continuar.
Monitore o aplicativo e observe as diferenças nas métricas de desempenho
Deixe o aplicativo em execução e retorne ao portal do Azure.
No painel esquerdo, selecione Painel.
Selecione o gráfico para abri-lo no painel Métricas .
Lembre-se de que este gráfico exibe as métricas do servidor adventureworks*[nnn]*, mas não as réplicas. A carga para cada réplica deve ser praticamente a mesma.
O gráfico de exemplo ilustra as métricas coletadas para o aplicativo durante um período de 30 minutos, desde a inicialização. O gráfico mostra que a utilização da CPU ainda era alta, mas a utilização da memória era menor. Além disso, após aproximadamente 25 minutos, o sistema estabeleceu conexões para mais de 30 conexões. Isso pode não parecer uma comparação favorável com a configuração anterior, que suportava 70 conexões após 45 minutos. No entanto, a carga de trabalho estava agora distribuída por três servidores, que estavam todos funcionando no mesmo nível, e todas as 101 conexões haviam sido estabelecidas. Além disso, o sistema foi capaz de continuar funcionando sem relatar nenhuma falha de conexão.
Você pode resolver o problema da utilização da CPU escalando para uma camada de preço mais alta com mais núcleos de CPU. O sistema de exemplo usado neste laboratório é executado usando a camada de preço Básico com 2 núcleos. Mudar para o nível de preço de uso geral lhe dará até 64 núcleos.
Volte para o Cloud Shell e pressione enter, para parar o aplicativo.
Agora você viu como monitorar a atividade do servidor usando as ferramentas disponíveis no portal do Azure. Você também aprendeu como configurar a replicação e viu como a criação de réplicas somente leitura pode distribuir a carga de trabalho em cenários de dados com uso intensivo de leitura.