Executar a exploração de dados
O Data Wrangler facilita a exploração dos seus dados com uma interface de grelha fácil de utilizar que apresenta dinamicamente estatísticas resumidas dos seus dados.
Através da exploração visual de estatísticas resumidas, os cientistas de dados são capazes de selecionar os modelos estatísticos ou de aprendizagem automática apropriados que melhor se ajustam aos dados. Por exemplo, alguns modelos assumem que os dados são normalmente distribuídos e podem não ter um bom desempenho se essa suposição for violada.
Gorjeta
Para saber mais sobre os fundamentos da exploração de dados usando blocos de anotações, consulte Explorar dados para ciência de dados com blocos de anotações no Microsoft Fabric.
Ver estatísticas resumidas
Para fins de demonstração, vamos gerar alguns dados aleatórios para simular um cenário hipotético envolvendo os preços das casas em um determinado bairro.
import pandas as pd
import numpy as np
# Set the seed
np.random.seed(0)
# Define the size of the dataset
size = 500
# Generate random data
data = {
'Size': np.random.randint(1000, 4001, size, dtype=int) // 10 * 10, # any integer value between 1000 and 4000, with multiple of 10
'Bedrooms': np.random.choice([2, 4, 3, 2, 1], size),
'YearBuilt': np.random.randint(1980, 2021, size), # any integer value between 1980 and 2020
'Price': np.random.normal(loc=110000, scale=20000, size=size), # normally distributed prices
'Type': np.random.choice(['Single Family', 'Townhouse', 'Condo', 'Duplex'], size) # type of the house
}
# Create a DataFrame
df = pd.DataFrame(data)
Para exibir estatísticas de resumo para o df dataframe, selecione Dados na faixa de opções do bloco de anotações e escolha Iniciar Data Wrangler para o df dataframe.

Para variáveis numéricas, a grade exibe um histograma, contagens de valores ausentes e exclusivos, bem como os valores mínimo e máximo. Quando se trata de variáveis categóricas, a grade oferece insights sobre a proporção de cada categoria dentro da variável.
O painel Resumo fornece estatísticas descritivas detalhadas e atualizações dinâmicas à medida que você seleciona diferentes colunas na grade.
Agrupar e agregar dados
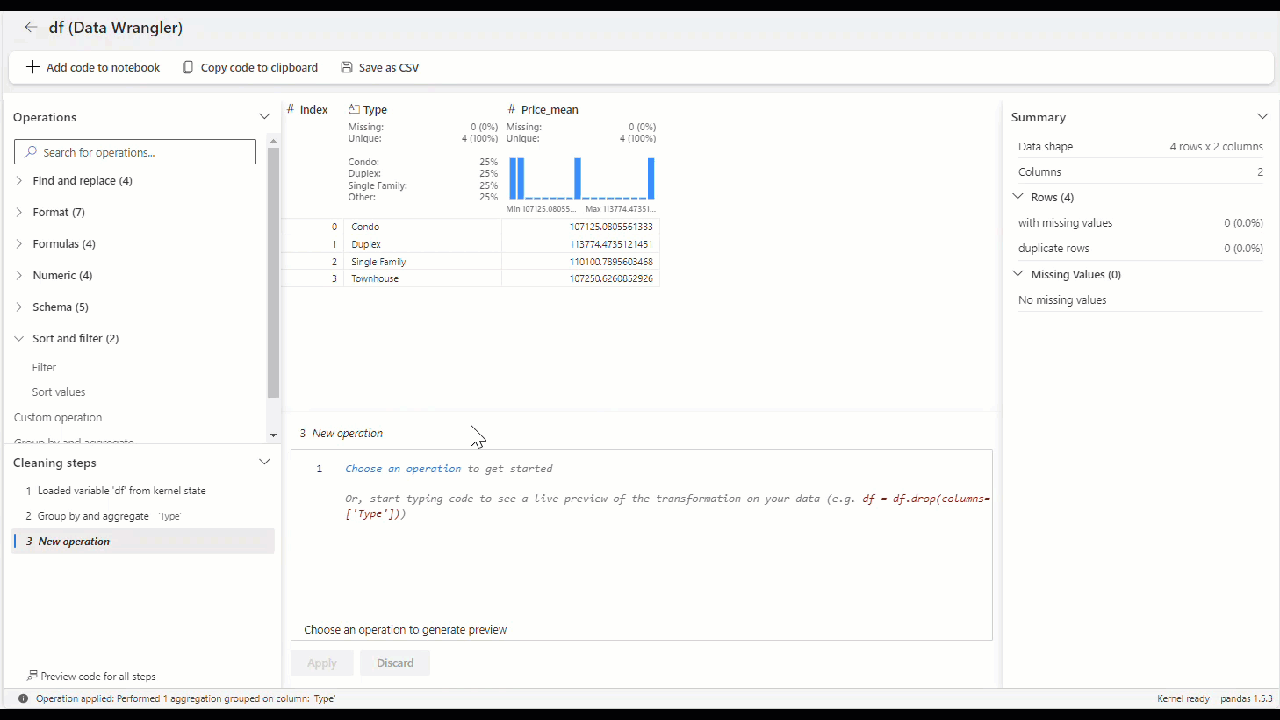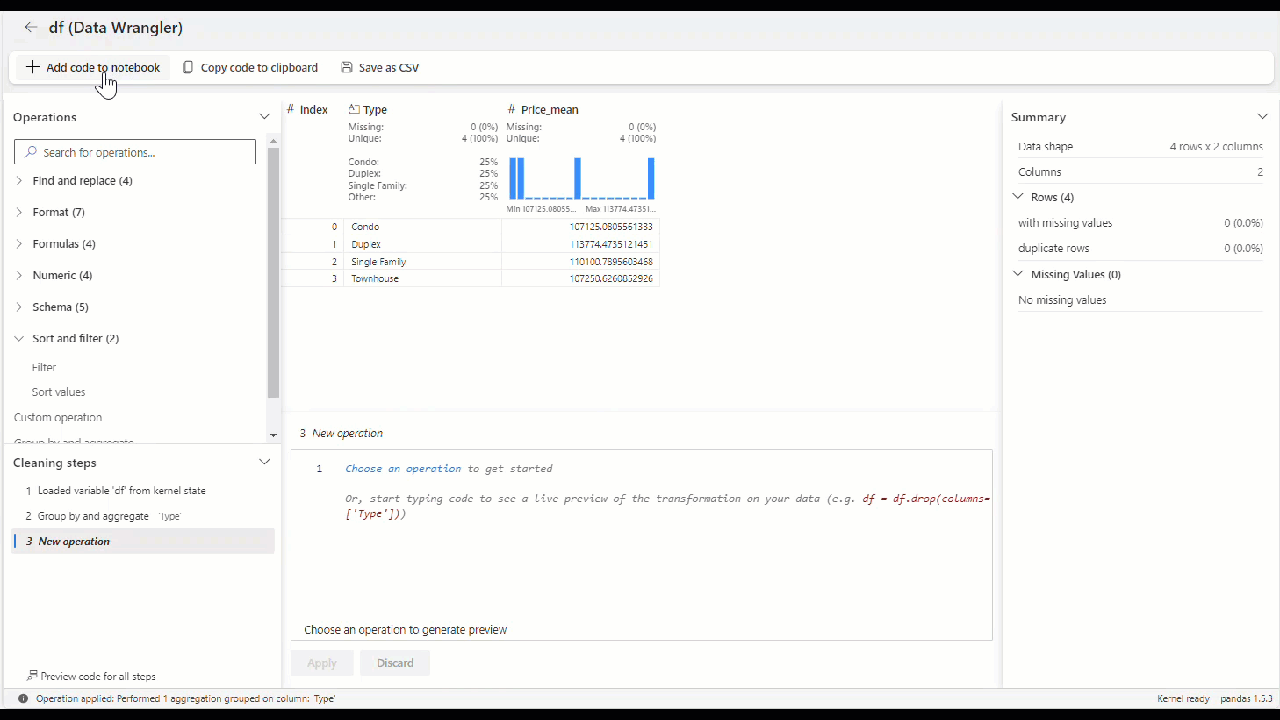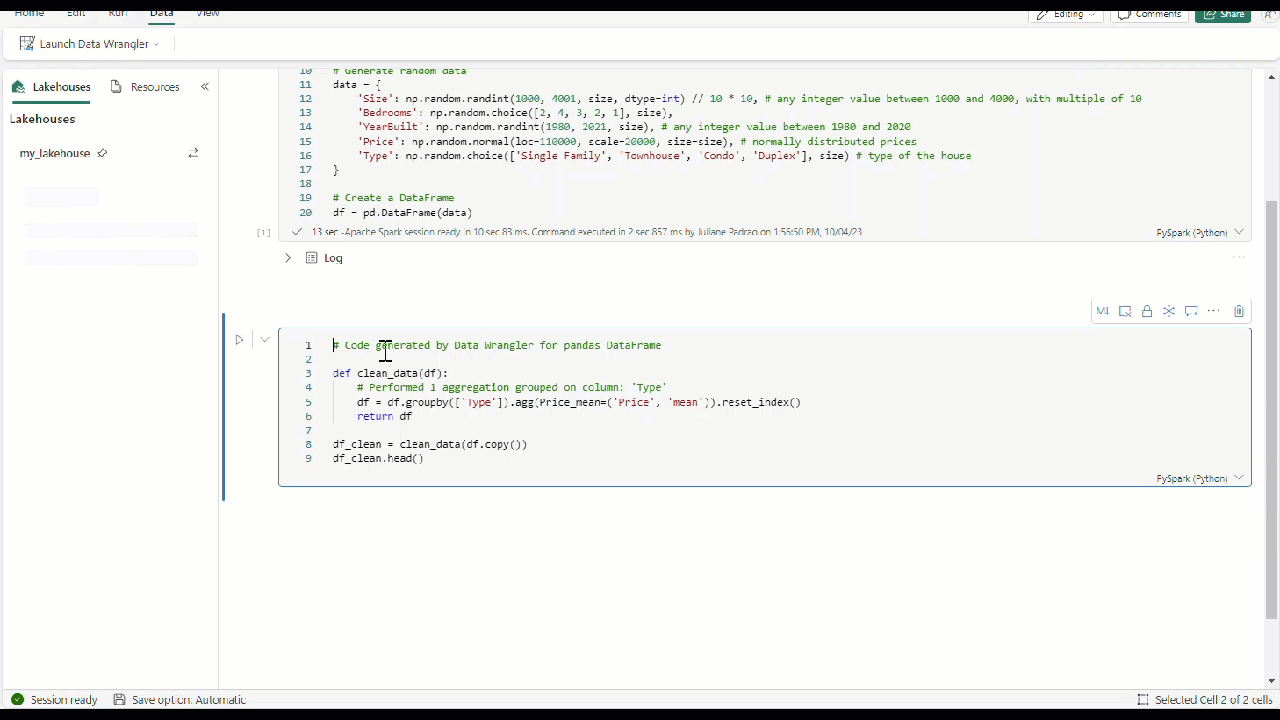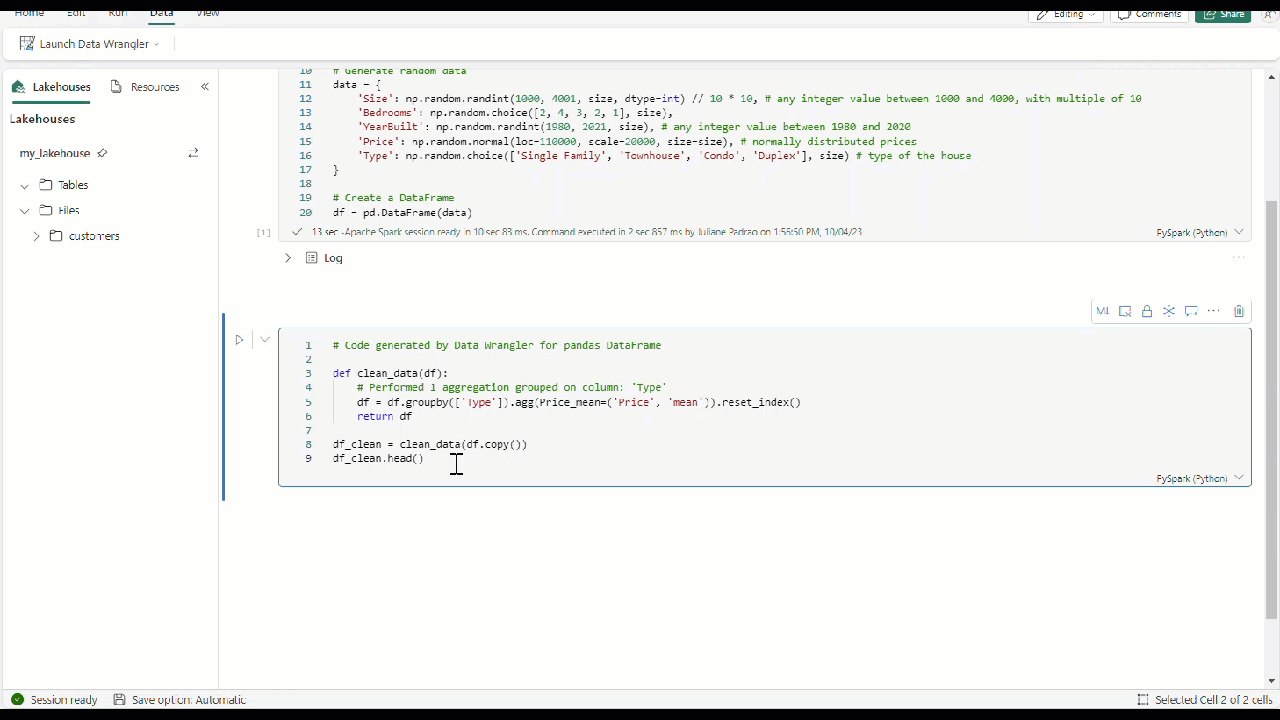
Como alternativa, você pode aplicar a agregação em seus dados usando o operador Group by e aggregate no painel do operador.
Para o nosso cenário de preços de casas, imagine que precisamos da média do preço da casa por tipo.

Em apenas alguns segundos, podemos configurar o grupo por e agregar operador, onde o código é gerado automaticamente para você. Além disso, a grade mostra os novos dados em verde e as colunas a serem removidas em vermelho.
Uma vez aplicado o operador, é assim que a sua grelha final deve aparecer.

Neste ponto, você pode decidir gerar o código ou baixar o dataframe transformado como um arquivo CSV (valores separados por vírgula).
Gerar código
No Data Wrangler, quando você usa qualquer operador interno ou personalizado, o dataframe não é alterado até que você adicione e execute o código gerado em seu bloco de anotações.
Depois de aplicar todos os operadores para transformar os dados, selecione + Adicionar código ao bloco de anotações na barra de ferramentas acima da grade do Data Wrangler. Isso gera uma função que você pode executar em seu pipeline de dados.
Esse recurso simplifica as tarefas de exploração e pré-processamento de dados em seu fluxo de trabalho de ciência de dados.