Entenda o Data Wrangler
O Data Wrangler é uma ferramenta criada em notebooks Microsoft Fabric que oferece uma plataforma abrangente para tarefas exploratórias e de pré-processamento. Ele oferece uma exibição de dados, estatísticas de resumo dinâmicas, visualizações internas e uma biblioteca de operações comuns de pré-processamento de dados.
Cada operação atualiza a exibição de dados em tempo real e gera código reutilizável que pode ser salvo de volta no notebook. Sua interface amigável o torna uma ferramenta eficiente para cientistas de dados lidarem com grandes volumes de dados, transformando dados brutos em um conjunto de dados pronto para uso para análise.
Pense no Data Wrangler como uma ferramenta que gera código para suas necessidades de exploração e pré-processamento de dados.
Nota
Atualmente, o Data Wrangler suporta apenas dataframe Pandas .
Trabalhar com o Data Wrangler
O Data Wrangler pode ajudar na fase de pré-processamento da construção de um modelo de aprendizado de máquina, fornecendo ferramentas e funcionalidades para limpeza de dados, engenharia de recursos, exploração de dados e melhoria da eficiência no pré-processamento de dados.
Exploração de dados: A exibição de dados em forma de grade da ferramenta permite que você explore visualmente seus dados, o que pode levar a insights sobre variáveis.
Limpeza de dados: o Data Wrangler fornece uma biblioteca de operações comuns de limpeza de dados, facilitando o tratamento de valores ausentes, valores atípicos e tipos de dados incorretos.
Engenharia de recursos: Com suas visualizações integradas e estatísticas de resumo dinâmico, o Data Wrangler pode ajudá-lo a entender a distribuição de seus dados e criar novos recursos.
O Data Wrangler pode ajudar a garantir que seus dados estejam na melhor forma possível antes de serem usados para treinar um modelo de aprendizado de máquina. Isso pode levar a modelos mais precisos e melhores previsões.
Iniciar o Data Wrangler a partir de um bloco de notas
Para iniciar o Data Wrangler no Microsoft Fabric, siga estas etapas.
Mude do Power BI para Ciência de Dados usando o ícone do seletor de experiência no lado esquerdo da sua home page. Em seguida, crie um novo bloco de anotações.
Leia seus dados em um Pandas DataFrame em um bloco de anotações do Microsoft Fabric.
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") Add another dataset example.Depois que os dados forem carregados em um dataframe, selecione Dados na faixa de opções do bloco de anotações.
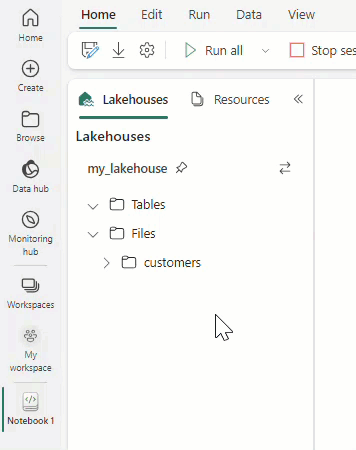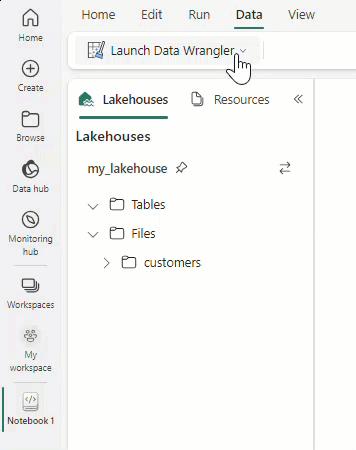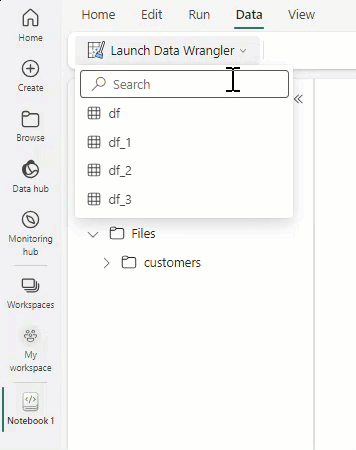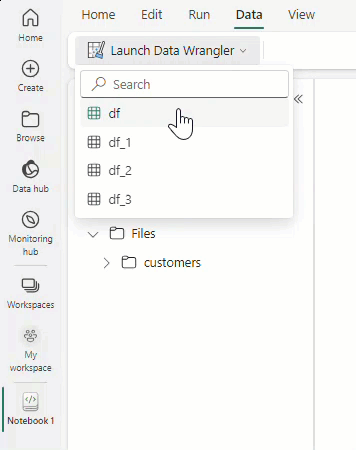
Selecione Iniciar Data Wrangler e, em seguida, selecione o dataframe que pretende abrir no Data Wrangler. Se você tiver vários dataframes, todos eles aparecerão.
Gorjeta
A extensão Data Wrangler para Visual Studio Code permite a integração do Data Wrangler em ambos VS Code e VS Code Jupyter Notebooks.
Trabalhar com operadores
Imagine que você está trabalhando em um grande conjunto de dados para um projeto crítico. Os dados precisam de muito trabalho. Você tem valores ausentes, linhas duplicadas e colunas que precisam ser renomeadas. Além disso, você precisa transformar alguns dados categóricos em um formato que seu modelo de aprendizado de máquina possa entender.
É aqui que entra o Data Wrangler. Com o mínimo de esforço, você pode classificar e filtrar linhas, codificar dados categóricos a quente, alterar tipos de coluna, soltar colunas desnecessárias, renomear colunas, manipular valores ausentes e muito mais. O Data Wrangler não só facilita essas tarefas, mas também gera código Python reutilizável para cada operação, que você pode salvar de volta em seu notebook. Isso significa que você pode automatizar tarefas de processamento de dados para conjuntos de dados futuros.
Aqui estão as categorias de operadores que estão atualmente disponíveis no Data Wrangler.
| Categoria | Description |
|---|---|
| Localizar e substituir | Inclui operações como descartar linhas duplicadas, manipular valores ausentes e localizar e substituir valores. |
| Formato | Envolve transformações de texto, como conversão em maiúsculas/minúsculas/maiúsculas, divisão de texto, remoção de espaços em branco e transformações automáticas alimentadas pelo Microsoft Flash Fill. |
| Fórmulas | Permite a criação de novas colunas usando fórmulas Python personalizadas, binarizador multi-label, codificação one-hot e cálculo do comprimento do texto. |
| Numérico | Inclui operações como arredondamento (para cima, para baixo ou para o número mais próximo) e dimensionamento de valores min/max. |
| Esquema | Permite alterações no esquema DataFrame, como alterar o tipo de coluna, clonar/soltar/renomear/selecionar colunas. |
| Ordenar e filtrar | Inclui operações de filtragem e classificação de valores. |
| Outras | Inclui operações personalizadas para modificar o quadro de dados, agrupar e agregar e criar colunas automáticas com tecnologia Microsoft Flash Fill. |
Nas próximas unidades, exploraremos uma variedade de operadores e obteremos informações sobre como eles podem facilitar as tarefas de pré-processamento para a construção de modelos preditivos.