Exercício – criar um modelo de machine learning
Para criar um modelo de machine learning, precisa de dois conjuntos de dados: um para preparação e um para testes. Na prática, muitas vezes tem apenas um conjunto de dados, por isso divide-o em dois. Neste exercício, vai realizar uma divisão de 80-20 sobre o DataFrame que preparou no laboratório anterior para que o possa utilizar na preparação de um modelo de machine learning. Irá também separar o DataFrame em colunas de funcionalidades e colunas de etiquetas. A primeira contém as colunas utilizadas como entrada para o modelo (por exemplo, o local de partida e o destino do voo e a hora prevista de partida), ao passo que a segunda contém a coluna que o modelo irá tentar prever, neste caso a coluna ARR_DEL15, que indica se um voo irá chegar à hora prevista.
Mude novamente para o bloco de notas do Azure que criou na secção anterior. Se você fechou o bloco de anotações, poderá entrar novamente no portal de Blocos de Anotações do Microsoft Azure, abrir seu bloco de anotações e usar a célula ->Executar Tudo para executar novamente todas as células do bloco de anotações depois de abri-lo.
Numa nova célula no final do bloco de notas, introduza e execute as seguintes instruções:
from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(df.drop('ARR_DEL15', axis=1), df['ARR_DEL15'], test_size=0.2, random_state=42)A primeira instrução importa a função auxiliar train_test_split do Scikit-learn. A segunda linha utiliza a função para dividir o DataFrame num conjunto de preparação que contém 80% dos dados originais e um conjunto de teste que contém os restantes 20%. O parâmetro
random_stateimplementa o gerador de números aleatórios utilizado para fazer a divisão, ao passo que o primeiro e segundo parâmetros são DataFrames que contêm as colunas de funcionalidade e a coluna de etiqueta.A
train_test_splitdevolve quatro DataFrames. Utilize o seguinte comando para apresentar o número de linhas e colunas no DataFrame que contêm as colunas de funcionalidade utilizadas para preparação:train_x.shapeUtilize agora este comando para apresentar o número de linhas e colunas no DataFrame que contêm as colunas de funcionalidade utilizadas para teste:
test_x.shapeEm que medida diferem os dois resultados e porquê?
Pode prever o que veria se tivesse chamado shape nos outros dois DataFrames, train_y e test_y? Se não tiver a certeza, experimente e descubra.
Existem muitos tipos de modelos de machine learning. Um dos tipos mais comuns é o modelo de regressão, que utiliza um dos vários algoritmos de regressão para produzir um valor numérico: por exemplo, a idade de uma pessoa ou a probabilidade de uma transação com cartão de crédito ser fraudulenta. Irá preparar um modelo de classificação, que procura resolver um conjunto de entradas num de um conjunto de resultados conhecidos. Um exemplo clássico de um modelo de classificação é aquele que examina e-mails e os classifica como "spam" ou "não spam". Seu modelo será um modelo de classificação binária que prevê se um voo chegará a tempo ou tarde ("binário" porque há apenas duas saídas possíveis).
Uma das vantagens da utilização do Scikit-learn é a de não ter de criar estes modelos nem de implementar os algoritmos que utilizam de forma manual. O Scikit-learn inclui uma variedade de classes para implementar modelos comuns de machine learning. Uma delas é o RandomForestClassifier, que ajusta múltiplas árvores de decisões aos dados e utiliza a média de mensagens em fila para aumentar a precisão geral e limitar o sobreajuste.
Execute o seguinte código numa nova célula para criar um objeto do
RandomForestClassifiere prepare-o ao chamar o método fit.from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(random_state=13) model.fit(train_x, train_y)O resultado mostra os parâmetros utilizados no classificador, incluindo
n_estimators, que especifica o número de árvores em cada floresta de árvores de decisões, emax_depth, que especifica a profundidade máxima das árvores de decisões. Os valores apresentados são os predefinidos, mas pode substituir qualquer um ao criar o objeto doRandomForestClassifier.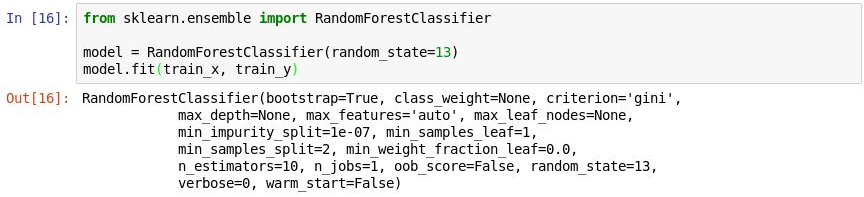
Preparar o modelo
Chame agora o método prever para testar o modelo com os valores em
test_x, seguido do método pontuação para determinar a precisão média do modelo:predicted = model.predict(test_x) model.score(test_x, test_y)Confirme que vê o seguinte resultado:

Testar o modelo
A precisão média é de 86%, o que parece ser uma boa média à primeira vista. No entanto, a precisão média nem sempre é um indicador confiável da precisão de um modelo de classificação. Vamos aprofundar um pouco mais e determinar o grau real de precisão do modelo, ou seja, o quão proficiente é em determinar se um voo vai chegar à hora prevista.
Existem várias formas para medir a precisão de um modelo de classificação. Uma das melhores medidas gerais para um modelo de classificação binária é a Área Sob o Recetor a Operar Curva Característica (por vezes referida como "ROC AUC"), que basicamente quantifica a frequência com que o modelo fará uma previsão correta, independentemente do resultado. Nesta unidade, irá calcular uma pontuação de ROC AUC para o modelo criado anteriormente e saber mais sobre algumas das razões por que essa classificação é inferior ao resultado de precisão média obtido pelo método score. Também aprenderá sobre outras formas de medir a precisão do modelo.
Antes de calcular a AUC ROC, tem de gerar as probabilidades de previsão para o teste definido. Estas probabilidades são estimativas para cada uma das classes ou respostas, que o modelo consegue prever. Por exemplo,
[0.88199435, 0.11800565]significa que há uma probabilidade de 89% de um voo chegar à hora prevista (ARR_DEL15 = 0) e uma probabilidade de 12% de o voo não chegar à hora prevista (ARR_DEL15 = 1). A soma das duas probabilidades é de 100%.Execute o seguinte código para gerar um conjunto de probabilidades de previsão a partir dos dados de teste:
from sklearn.metrics import roc_auc_score probabilities = model.predict_proba(test_x)Utilize agora a seguinte instrução para gerar uma pontuação de ROC AUC a partir das probabilidades através do método roc_auc_score do Scikit-learn:
roc_auc_score(test_y, probabilities[:, 1])Confirme que o resultado mostra uma pontuação de 67%:

Gerar uma pontuação de AUC
Por que razão é a pontuação de AUC inferior à da precisão média calculada no exercício anterior?
O resultado do método
scorereflete o número de itens no conjunto de teste que o modelo previu corretamente. Esta pontuação é distorcida pelo facto de que o conjunto de dados com o qual o modelo foi preparado e testado contém muito mais linhas que representam as chegadas à hora prevista do que linhas que representam as chegadas atrasadas. Devido a este desequilíbrio nos dados, tem mais probabilidade de estar correto se previr que um voo vai chegar à hora prevista do que se previr que um voo irá chegar atrasado.A ROC AUC tem isto em consideração e fornece uma indicação mais precisa relativa à probabilidade de uma previsão de chegada à hora prevista ou atrasada estar correta.
Pode saber mais sobre o comportamento do modelo através da geração de uma matriz de confusão, também conhecida como uma matriz de erro. A matriz de confusão quantifica o número de vezes que cada resposta foi classificada correta ou incorreta. Especificamente, ela quantifica o número de falsos positivos, falsos negativos, verdadeiros positivos e verdadeiros negativos. Isto é importante porque se um modelo de classificação binária preparado para reconhecer gatos e cães for testado com um conjunto de dados que seja 95% de cães, pode ter uma pontuação de 95% simplesmente ao adivinhar "cão" todas as vezes. No entanto, se falhar em identificar gatos de todo, seria de pouco valor.
Utilize o seguinte código para produzir uma matriz de confusão para o seu modelo:
from sklearn.metrics import confusion_matrix confusion_matrix(test_y, predicted)A primeira linha no resultado representa os voos que chegaram à hora prevista. A primeira coluna nessa linha mostra quantos voos foram previstos corretamente para terem chegado à hora prevista, ao passo que a segunda coluna revela quantos voos foram previstos como atrasados, mas efetivamente não chegaram atrasados. A partir daqui, o modelo parece estar proficiente na previsão de que um voo irá chegar à hora prevista.

Gerar uma matriz de confusão
Veja a segunda linha, que representa os voos atrasados. A primeira coluna mostra quantos voos atrasados foram incorretamente previstos como tendo chegado à hora prevista. A segunda coluna mostra quantos voos foram corretamente previstos como atrasados. Sem dúvida, o modelo não é tão proficiente a prever que um voo vai chegar atrasado como o é a prever que um voo vai chegar à hora prevista. O que pretende numa matriz de confusão são números grandes nos cantos superior esquerdo e inferior direito e números pequenos (preferencialmente zeros) nos cantos superior direito e inferior esquerdo.
Outras medidas de precisão para um modelo de classificação incluem precisão e revocação. Suponha que o modelo foi apresentado com três chegadas à hora prevista e três chegadas atrasadas, e que previu corretamente duas das chegadas à hora prevista, mas previu incorretamente que duas das chegadas em atraso iriam chegar à hora prevista. Neste caso, a precisão seria de 50% (classificou dois dos quatro voos como tendo chegado a horas e esses chegaram efetivamente a horas), ao passo que a revocação seria de 67% (identificou corretamente duas das três chegadas a horas). Pode saber mais sobre a precisão e a revocação em https://en.wikipedia.org/wiki/Precision_and_recall
O Scikit-learn contém um método prático chamado precision_score para precisão de cálculo. Para quantificar a precisão do seu modelo, execute as seguintes instruções:
from sklearn.metrics import precision_score train_predictions = model.predict(train_x) precision_score(train_y, train_predictions)Examinar a saída. Qual é a precisão do seu modelo?

Medir a precisão
O Scikit-learn também contém um método chamado recall_score para a revocação de cálculo. Para medir a revocação do modelo, execute as seguintes instruções:
from sklearn.metrics import recall_score recall_score(train_y, train_predictions)Qual é a revocação do modelo?

Medir a revocação
Use o comando Arquivo ->Salvar e Ponto de verificação para salvar o bloco de anotações.
No mundo real, um cientista de dados treinado iria procurar formas de tornar o modelo ainda mais preciso. Entre outras coisas, iria tentar algoritmos diferentes e tomar medidas para otimizar o algoritmo escolhido para encontrar a combinação ideal de parâmetros. Outra etapa provável seria expandir o conjunto de dados para milhões de linhas, em vez de alguns milhares, e tentar também reduzir o desequilíbrio entre as chegadas atrasadas e as chegadas à hora prevista. No entanto, para o nosso objetivo, o modelo está bem tal como está.