Integre consultas Apache Spark e Hive LLAP
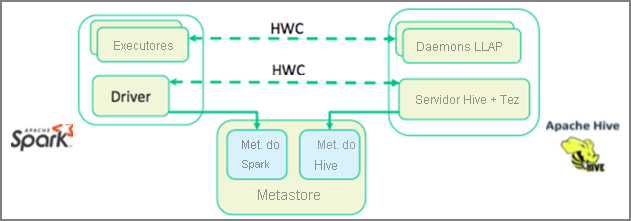
Na unidade anterior, analisamos duas maneiras de consultar dados estáticos armazenados em um cluster de Consulta Interativa – o Data Analytics Studio e um bloco de anotações do Zeppelin. Mas e se você quisesse transmitir dados imobiliários novos para seus clusters usando o Spark e, em seguida, consultá-los usando o Hive? Como o Hive e o Spark têm dois metastores diferentes, eles precisam de um conector para fazer a ponte entre os dois – e o Apache Hive Warehouse Connector (HWC) é essa ponte. A biblioteca do Hive Warehouse Connector permite que você trabalhe mais facilmente com o Apache Spark e o Apache Hive, suportando tarefas como mover dados entre DataFrames do Spark e tabelas do Hive e também direcionando dados de streaming do Spark para tabelas do Hive. Não vamos configurar o conector em nosso cenário, mas é importante saber que a opção existe.
O Apache Spark tem uma API de Streaming Estruturado que fornece recursos de streaming não disponíveis no Apache Hive. A partir do HDInsight 4.0, o Apache Spark 2.3.1 e o Apache Hive 3.1.0 têm metastores separados, o que dificultou a interoperabilidade. O Hive Warehouse Connector facilita o uso do Spark e do Hive juntos. A biblioteca do Hive Warehouse Connector carrega dados de daemons LLAP em executores do Spark em paralelo, tornando-os mais eficientes e escaláveis do que usar uma conexão JDBC padrão do Spark para o Hive.
Algumas das operações suportadas pelo Hive Warehouse Connector são:
- Descrição de uma tabela
- Criando uma tabela para dados formatados em coluna de linha otimizada (ORC)
- Selecionando dados do Hive e recuperando um DataFrame
- Gravando um DataFrame no Hive em lote
- Executando uma instrução de atualização do Hive
- Ler dados da tabela do Hive, transformá-los no Spark e gravá-los em uma nova tabela do Hive
- Gravando um fluxo DataFrame ou Spark no Hive usando o HiveStreaming
Depois de implantar um cluster do Spark e um cluster de Consulta Interativa, você define as configurações do cluster do Spark no Ambari, que é uma ferramenta baseada na Web incluída em todos os clusters HDInsight. Para abrir o Ambari, navegue até https:// servername.azurehdinsight.net no navegador da Internet, onde servername é o nome do cluster do Interactive Query.
Em seguida, para gravar dados de streaming do Spark nas tabelas, crie uma tabela do Hive e comece a gravar dados nela. Em seguida, execute consultas em seus dados de streaming, você pode usar qualquer um dos seguintes:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy