Exercício - Carregar e consultar dados no HDInsight
Agora que você provisionou uma conta de armazenamento e um cluster de consulta interativa, é hora de carregar seus dados imobiliários e executar algumas consultas. Os dados que você carregará são dados imobiliários da cidade de Nova York. Ele inclui mais de 28.000 registros de propriedade, incluindo endereços, preços de venda, metragem quadrada e informações de localização geocodificadas para facilitar o mapeamento. A sua empresa de investimento imobiliário utiliza esta informação para determinar os preços adequados de metragem quadrada para novas propriedades que chegam ao mercado, com base nos preços de venda de propriedades vendidas anteriormente.
Para carregar e consultar dados, usaremos o Data Analytics Studio, que é um aplicativo baseado na Web que foi instalado na ação de script que usamos quando criamos o cluster de Consulta Interativa. Você pode usar o Data Analytics Studio para carregar dados no armazenamento do Azure, transformar os dados em tabelas do Hive usando os tipos de dados e nomes de coluna definidos e, em seguida, consultar dados em seu cluster usando o HiveQL. Além do Data Analytic Studio, você pode usar qualquer ferramenta compatível com ODBC/JDBC para trabalhar com seus dados usando o Hive, como o Spark & Hive Tools for Visual Studio Code.
Em seguida, você usará um Notebook do Zeppelin para visualizar rapidamente as tendências nos dados. Os Blocos de Anotações do Zeppelin permitem que você envie consultas e visualize os resultados em vários gráficos predefinidos diferentes. Os Notebooks Zeppelin instalados em clusters do Interactive Query têm um interpretador JDBC com um driver Hive.
Download de dados imobiliários
- Aceda a https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20data, e transfira o conjunto de dados para guardar o ficheiro propertysales.csv no seu computador.
Carregue os dados usando o Data Analytics Studio
- Agora, abra o estúdio do Data Analytics em seu navegador da Internet usando a seguinte URL, substituindo servername pelo nome do cluster usado: https:// servername.azurehdinsight.net/das/
Para iniciar sessão, o nome de utilizador é admin e a palavra-passe é a palavra-passe que criou.
Se você encontrar um erro, vá para a guia Visão geral do cluster no portal do Azure e verifique se o status está definido como Em execução e se o tipo de cluster, versão HDI está definido como Consulta Interativa 3.1 (HDI 4.0).
- O Data Studio Analytics é iniciado no navegador da Internet.
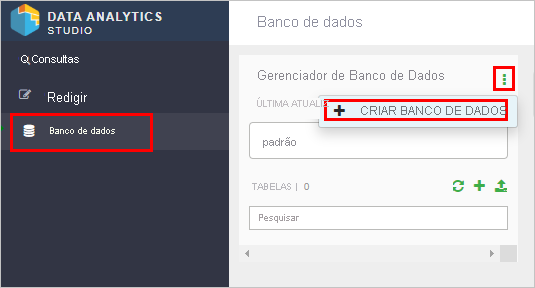
- Clique em Banco de Dados no menu à esquerda, clique no botão verde de reticências verticais e clique em Criar Banco de Dados.
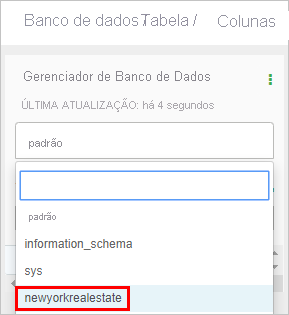
Nomeie o banco de dados como 'newyorkrealestate' e clique em Criar.
No Database Explorer, clique na caixa nome do banco de dados e selecione newyorkrealestate.
- No Database Explorer, clique em e, em seguida, clique em + Criar tabela.
- Nomeie a nova tabela como 'propertysales' e clique em Carregar tabela. Os nomes das tabelas devem conter apenas letras minúsculas e números, sem caracteres especiais.
- Na área Selecionar Formato de Arquivo da página:
- Verifique se o formato do arquivo é csv
- Marque a caixa É cabeçalho da primeira linha?
- Na área Selecionar Fonte de Arquivo da página:
- Selecione Carregar a partir de Local.
- Clique em Arrastar arquivo para carregar ou clique em Procurar e navegue até o arquivo .csv propertysales.
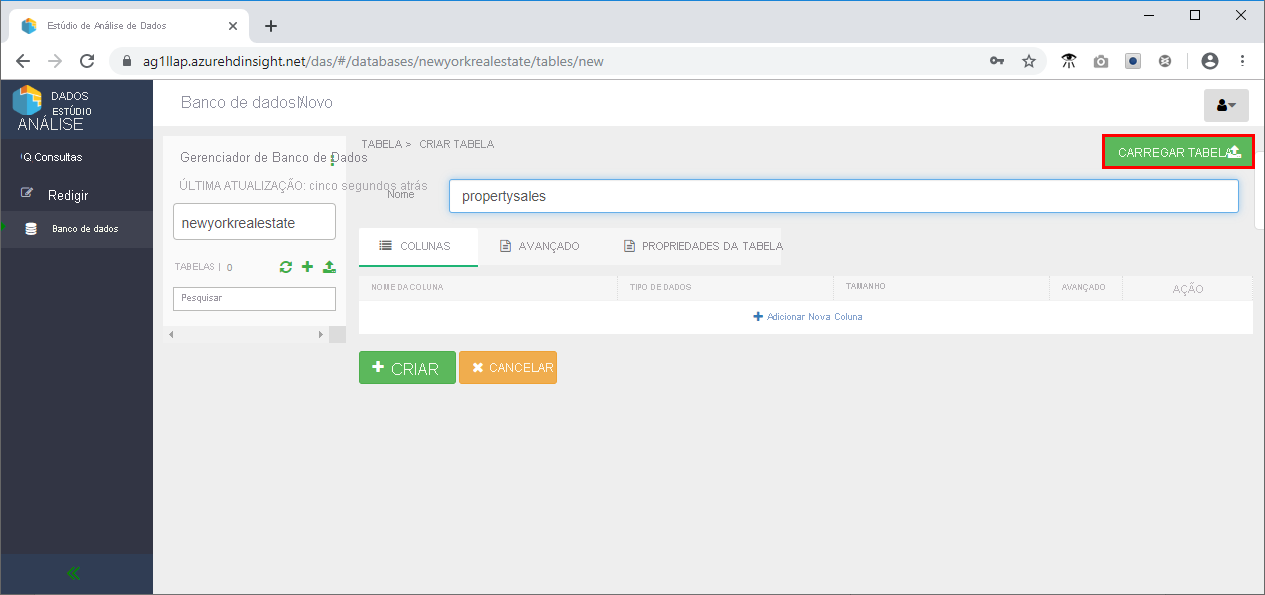
- Na seção Colunas, altere o tipo de dados Latitude e Longitude para Cadeia de Caracteres e Data de venda para Data.
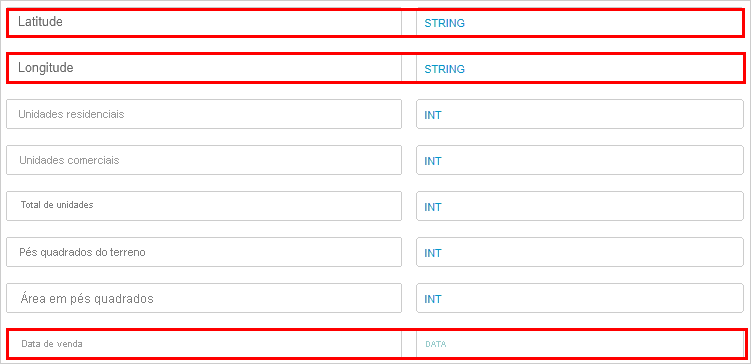
- Desloque-se para cima e reveja a secção Pré-visualização da Tabela para validar se os cabeçalhos das colunas estão corretos.
- Role até o fim e clique em Criar para criar a tabela Hive no banco de dados newyorkrealestate.

- No menu à esquerda, clique em Compor.
- Tente a seguinte consulta do Hive para garantir que tudo esteja funcionando conforme o esperado.
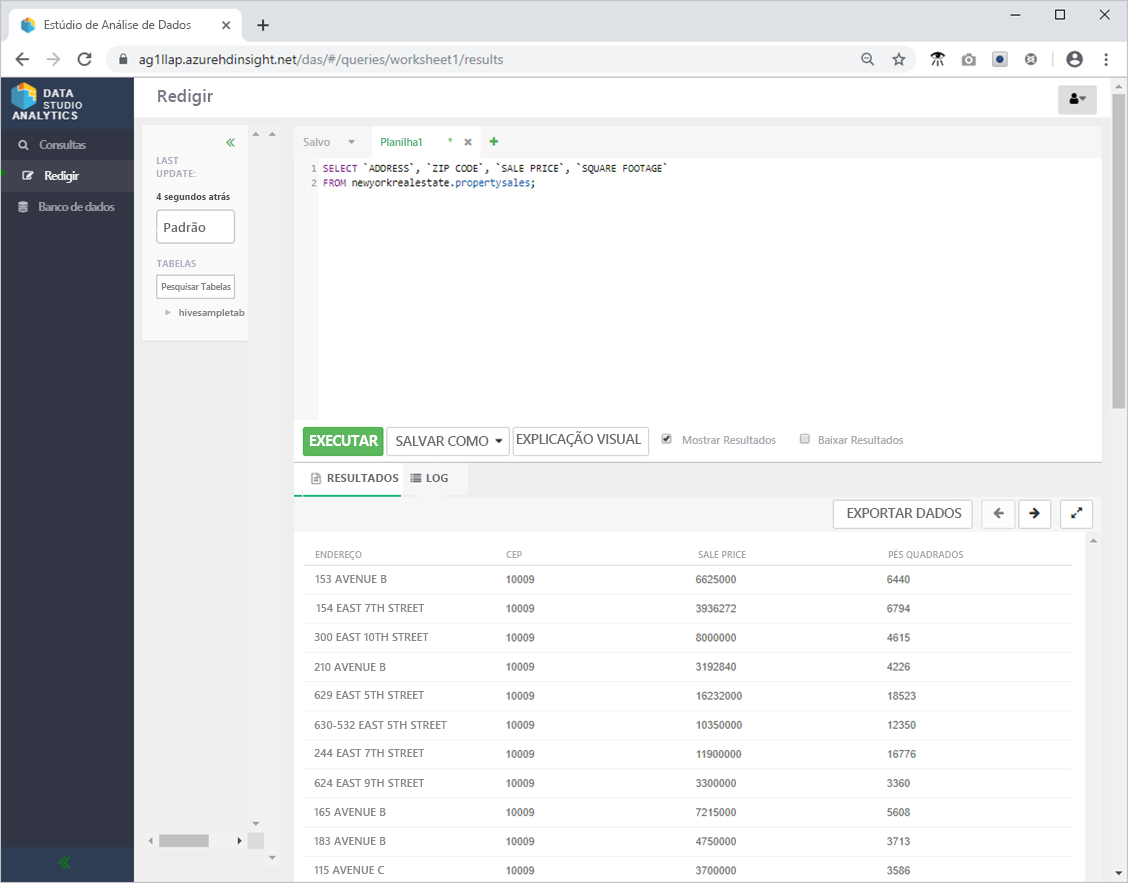
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- A saída deve ser semelhante à seguinte.
- Revise o desempenho da sua consulta clicando em Consultas no menu à esquerda e, em seguida, selecionando a consulta SELECT
ADDRESS,ZIP CODE, ,SALE PRICESQUARE FOOTAGEFROM newyorkrealestate.propertysales que você acabou de executar.
Se houvesse recomendações de desempenho disponíveis, a ferramenta exibiria essas recomendações. Esta página também exibe a consulta SQL real que foi executada, fornece uma explicação visual da consulta, mostra os detalhes de configuração inferidos pelo Hive ao executar a consulta e fornece uma linha do tempo que mostra quanto tempo foi gasto executando cada parte da consulta.
Explore as tabelas do Hive usando um bloco de anotações do Zeppelin
- No portal do Azure, na página Visão geral, na caixa Painel do cluster, clique em Bloco de Anotações do Zeppelin.

- Clique em Nova Nota, nomeie a nota Dados Imobiliários e clique em Criar.
- Cole o seguinte trecho de código no prompt de comando na janela do Zeppelin e clique no ícone de reprodução.
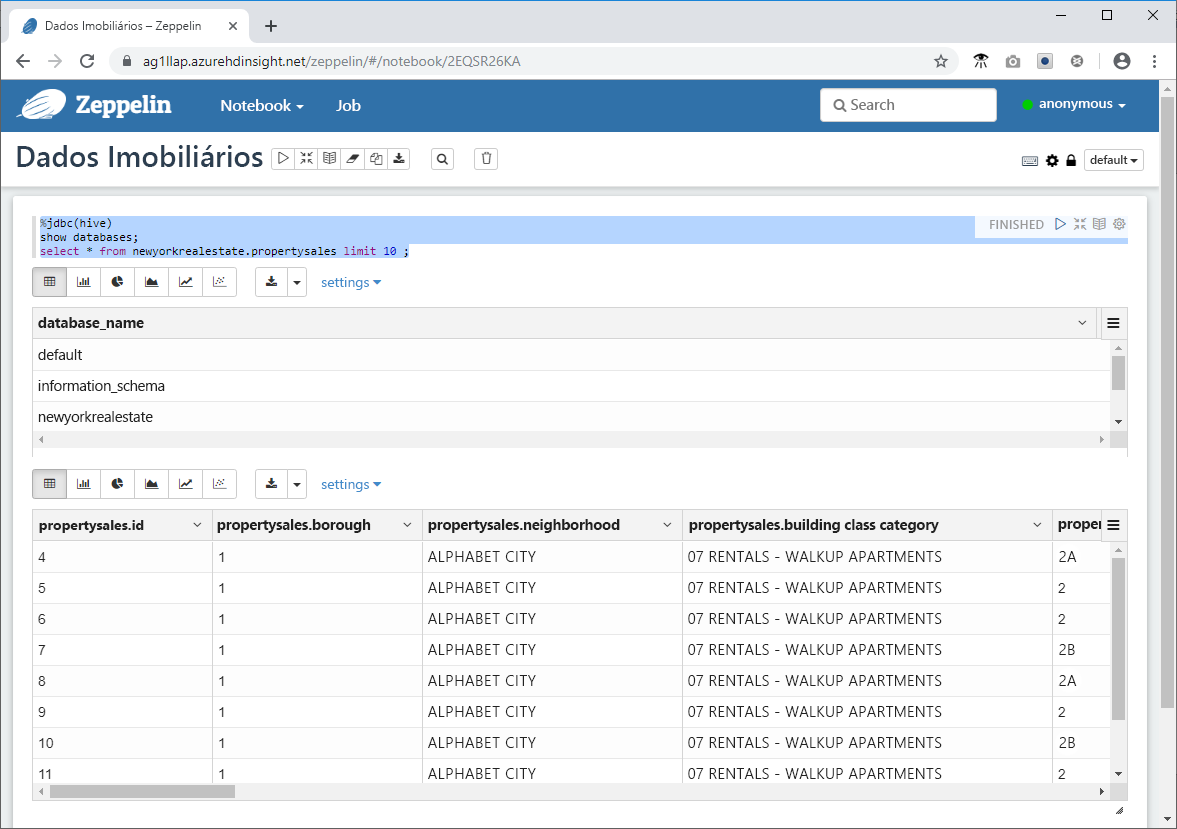
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
A saída da consulta é exibida na janela. Você pode ver que os primeiros 10 resultados são retornados.
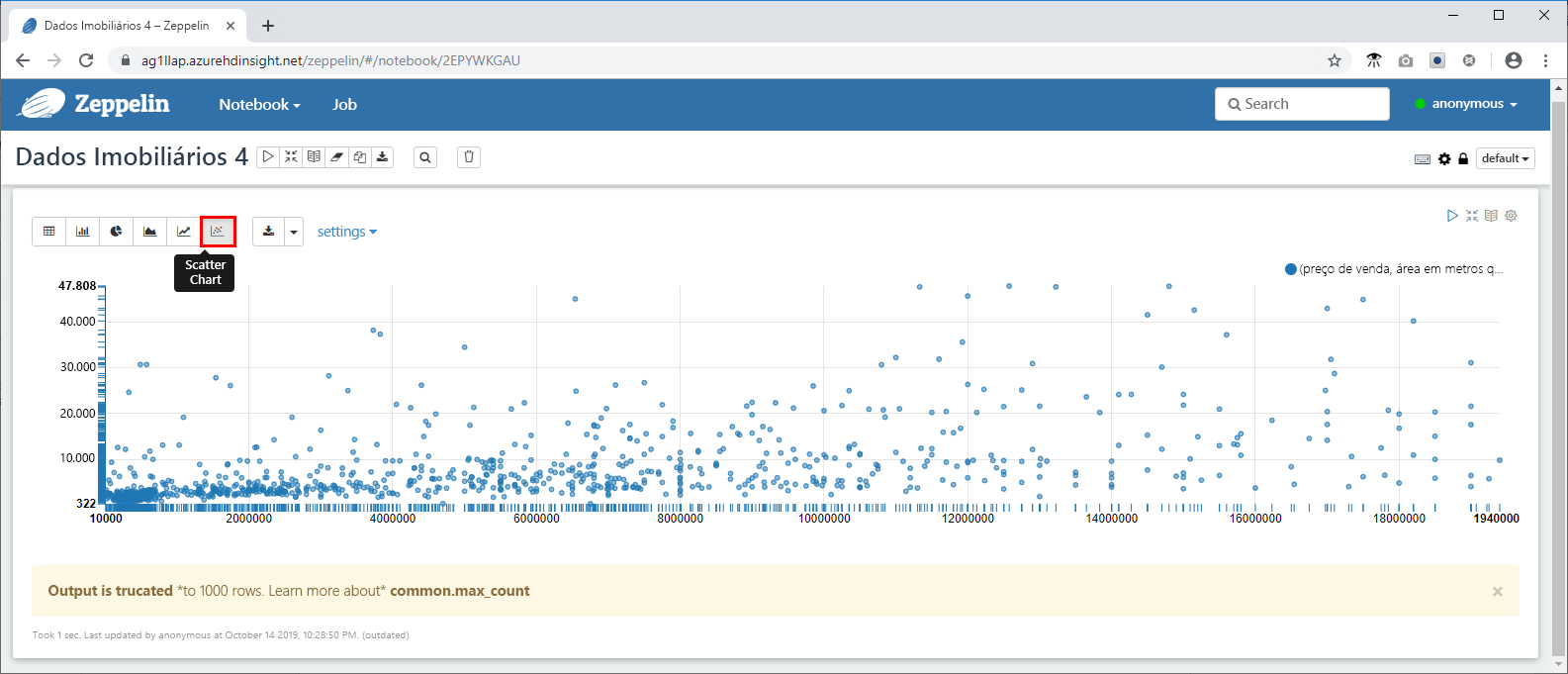
- Agora dispare uma consulta mais complexa para usar alguns dos recursos de visualização e gráficos disponíveis no Zeppelin. Copie a seguinte consulta para o prompt de comando e clique em .
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
Por padrão, a saída da consulta é exibida em formato de tabela. Em vez disso, selecione Gráfico de dispersão para ver um dos elementos visuais fornecidos pelos blocos de anotações do Zeppelin.