Quando você deve usar a Consulta Interativa do HDInsight?
Como analista de negócios, você precisa determinar o tipo mais apropriado de cluster HDInsight a ser criado para criar sua solução. Os clusters de consulta interativa fornecem uma série de recursos e opções de interoperabilidade que o tornam exclusivamente benéfico para analistas de negócios familiarizados com SQL. É ótimo para usuários que querem trabalhar com ferramentas de business intelligence e exigem consultas interativas rápidas. Há outros benefícios, como suporte para uma variedade de formatos de arquivo, simultaneidade e transações atômicas, consistentes, isoladas e duráveis (ACID). Sem mencionar a integração com o Apache Ranger para controle granular de nível de linha e coluna sobre os dados.
Nota
O conteúdo deste módulo pertence aos clusters de Consulta Interativa criados para o HDInsight 4.0, que usa o Hive 3.1 e o LLAP, também conhecido como Hive LLAP.
Você tem um grande conjunto de dados pronto para ser consultado
Os clusters de consulta interativa são mais adequados para grandes conjuntos de dados que podem ser consultados no estado em que se encontram ou com transformações mínimas. Situações em que você estará realizando uma variedade de consultas sobre os dados e precisará de respostas imediatas. Os clusters de consulta interativa não são otimizados para executar cálculos em lote de longa duração. A consulta interativa suporta os seguintes formatos de arquivo: ORC, Parquet, CSV, Avro, JSON, text e tsv.
Você precisa de funcionalidade semelhante ao SQL
Quando você precisa executar consultas interativas e ad hoc de latência de subsegundo no big data que você tem no armazenamento do Azure e no Armazenamento do Azure Data Lake, e prefere uma experiência semelhante ao SQL, os clusters de Consulta Interativa do Azure HDInsight são uma excelente escolha. Como analista de negócios, você está altamente familiarizado com tabelas SQL e criação de consultas usando SQL. O Apache Hadoop é uma ferramenta poderosa para executar análises de big data. O uso do framework MapReduce pelo Apache Hadoop e suas APIs Java pode ser um bloqueador para você se suas habilidades de programação Java estiverem um pouco enferrujadas. Nesse caso, o HDInsight Interactive Query é mais adequado, pois é construído sobre o Apache Hadoop, mas é mais simples de usar para qualquer pessoa com experiência em SQL. O Interactive Query usa tabelas Hive semelhantes a SQL para processar dados e uma linguagem de consulta semelhante a SQL chamada HiveQL para consultar dados. Usar o Hive é menos complexo do que processar dados usando o MapReduce no Apache Hadoop. O Hive torna mais rápido e eficiente implementar soluções para a sua empresa.
Consultas interativas rápidas com cache inteligente
Os clusters de Consulta Interativa usam técnicas de cache inteligentes para hierarquizar os dados na RAM dinâmica, SSD de nó de cluster local e sistemas de armazenamento remoto, como o Blob do Azure e o Armazenamento do Azure Data Lake, para obter resultados de consulta interativos e rápidos sobre o big data. Um bom exemplo de técnica avançada de cache é o cache de texto dinâmico, que converte dados CSV em um formato otimizado na memória em tempo real, de modo que o cache é dinâmico e as consultas determinam quais dados são armazenados em cache. Essa funcionalidade significa que você não precisa carregar e transformar seus dados primeiro. Você pode carregar os dados no armazenamento do Azure em seu formato original e começar a consultá-los. E isso também significa que as consultas têm mais desempenho na segunda vez que são executadas. Na primeira vez que uma consulta é executada, os dados são lidos da camada de armazenamento de dados corporativos no Armazenamento do Azure ou no Azure Data Lake Gen2. Em seguida, os dados são armazenados em cache no cache compartilhado na memória no cluster. Na próxima vez que a consulta for executada, os dados serão simplesmente recuperados do cache compartilhado na memória e você economizará tempo ao não recuperar dados da camada de armazenamento remoto.
Executar consultas usando ferramentas populares
A consulta interativa facilita o trabalho com o big data usando ferramentas de BI com as quais você está familiarizado, como o Microsoft Power BI e o Tableau. Na análise de big data, as organizações estão cada vez mais preocupadas com o fato de que seus usuários finais não estão obtendo valor suficiente dos sistemas de análise, porque muitas vezes é muito desafiador e requer o uso de ferramentas desconhecidas e difíceis de aprender para executar as análises. A Consulta Interativa do HDInsight resolve esse problema exigindo treinamento mínimo ou nenhum novo usuário para obter informações dos dados. Os usuários podem escrever consultas HiveQL semelhantes a SQL nas ferramentas que já usam. Essas ferramentas incluem Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio e Hive ODBC. Não é possível executar consultas no cluster de Consulta Interativa usando o console do Hive, o Templeton, a CLI Clássica do Azure ou o Azure PowerShell.
Você precisa de consistência e simultaneidade da transação
Com a introdução do gerenciamento refinado de recursos, preempção e compartilhamento de dados armazenados em cache entre consultas e usuários, o Interactive Query oferece suporte a usuários simultâneos com facilidade. O HDInsight dá suporte à criação de vários clusters no armazenamento compartilhado do Azure. O metastore do Hive ajuda a alcançar um alto grau de simultaneidade. Você pode dimensionar a simultaneidade adicionando mais nós de cluster ou adicionando mais clusters apontando para os mesmos dados e metadados subjacentes. O Interactive Query também oferece suporte a transações de banco de dados que são Atômicas, Consistentes, Isoladas e Duráveis (ACID). As transações ACID garantem que uma transação, mesmo que contenha várias operações, está contida em uma única unidade. Assim, se qualquer operação na transação falhar, toda a operação pode ser revertida, o que mantém os dados consistentes e precisos.
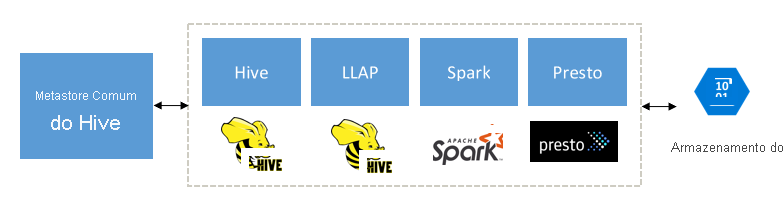
Construído para complementar o Spark, Hive, Presto, e outros mecanismos de big data
A consulta HDInsight Interactive foi projetada para funcionar bem com mecanismos populares de big data, como Apache Spark, Hive, Presto, e muito mais. Esse tipo de consulta é especialmente útil porque seus usuários podem escolher qualquer uma dessas ferramentas para executar suas análises. Com a arquitetura de metadados e dados compartilhados do HDInsight para tabelas externas, os usuários podem criar vários clusters com o mesmo mecanismo ou um mecanismo diferente apontando para os mesmos dados e metadados subjacentes. Essa funcionalidade é um conceito poderoso, pois você não está mais limitado por uma tecnologia para análise.