Exercício - Transmita dados Kafka para um bloco de anotações Jupyter e janela os dados
O cluster Kafka agora está gravando dados em seu log, que podem ser processados via Spark Structured Streaming.
Um bloco de anotações do Spark está incluído no exemplo clonado, portanto, você precisa carregar esse bloco de anotações no cluster do Spark para usá-lo.
Carregue o bloco de anotações Python para o cluster do Spark
No portal do Azure, clique em Clusters HDInsight Home > e selecione o cluster do Spark que você acabou de criar (não o cluster Kafka).
No painel Painéis de cluster, clique em Bloco de anotações Jupyter.

Quando as credenciais forem solicitadas, insira um nome de usuário de administrador e digite a senha que você criou quando criou os clusters. O site Jupyter é exibido.
Clique em PySpark e, em seguida, na página PySpark, clique em Carregar.
Navegue até o local onde você baixou o exemplo do GitHub, selecione o arquivo RealTimeStocks.ipynb, clique em Abrir, clique em Carregar e clique em Atualizar no navegador da Internet.
Depois que o bloco de anotações for carregado para a pasta PySpark, clique em RealTimeStocks.ipynb para abrir o bloco de anotações no navegador.
Execute a primeira célula do bloco de notas colocando o cursor na célula e, em seguida, clicando em Shift+Enter para executar a célula.
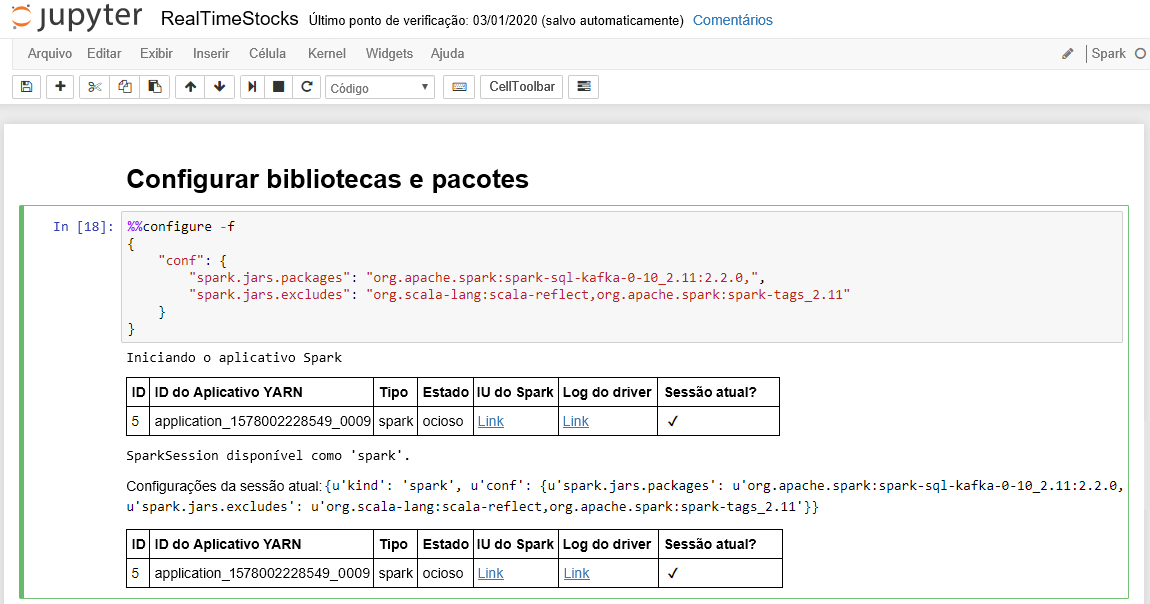
A célula Configurar bibliotecas e pacotes é concluída com êxito quando exibe a mensagem do aplicativo Iniciando o Spark e informações adicionais, conforme mostrado na legenda da tela a seguir.
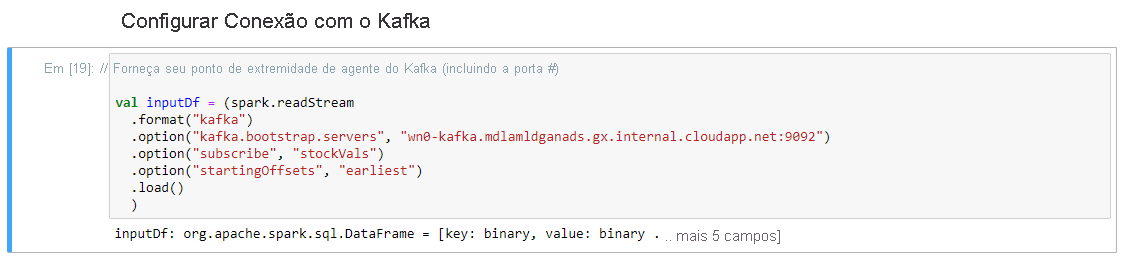
Na célula Configurar Conexão com Kafka, na linha .option("kafka.bootstrap.servers", ""), insira o broker Kafka entre o segundo conjunto de aspas. Por exemplo. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), em seguida, clique em Shift+Enter para executar a célula.
A conexão de configuração com a célula Kafka é concluída com êxito quando exibe a mensagem inputDf: org.apache.spark.sql.DataFrame = [chave: binário, valor: binário ... Mais 5 campos]. O Spark usa a API readStream para ler os dados.
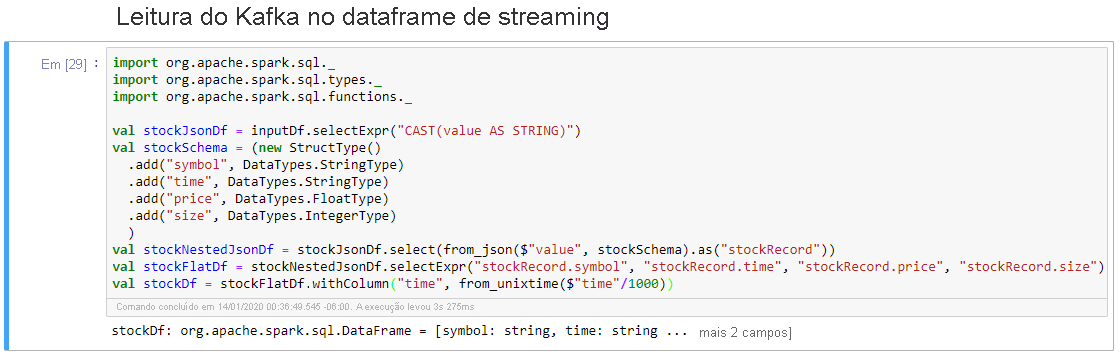
Selecione Ler de Kafka na célula Streaming Dataframe e clique em Shift+Enter para executar a célula.
A célula é concluída com êxito quando exibe a seguinte mensagem: stockDf: org.apache.spark.sql.DataFrame = [símbolo: string, time: string ... Mais 2 campos]
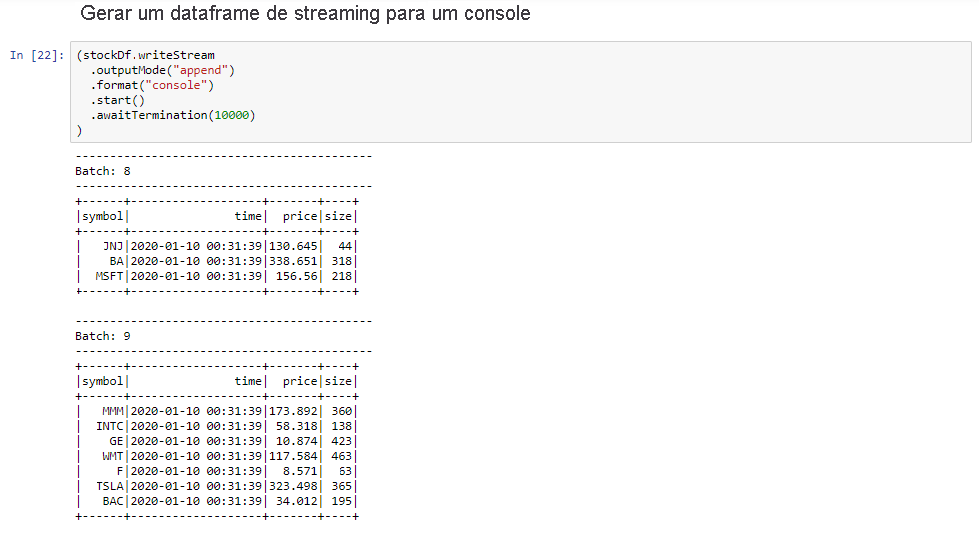
Selecione o Dataframe de Streaming de Saída para a célula Console e clique em Shift+Enter para executar a célula.
A célula é concluída com êxito quando mostra informações semelhantes às seguintes. A saída mostra o valor de cada célula como ela foi passada no microlote, e há um lote por segundo.
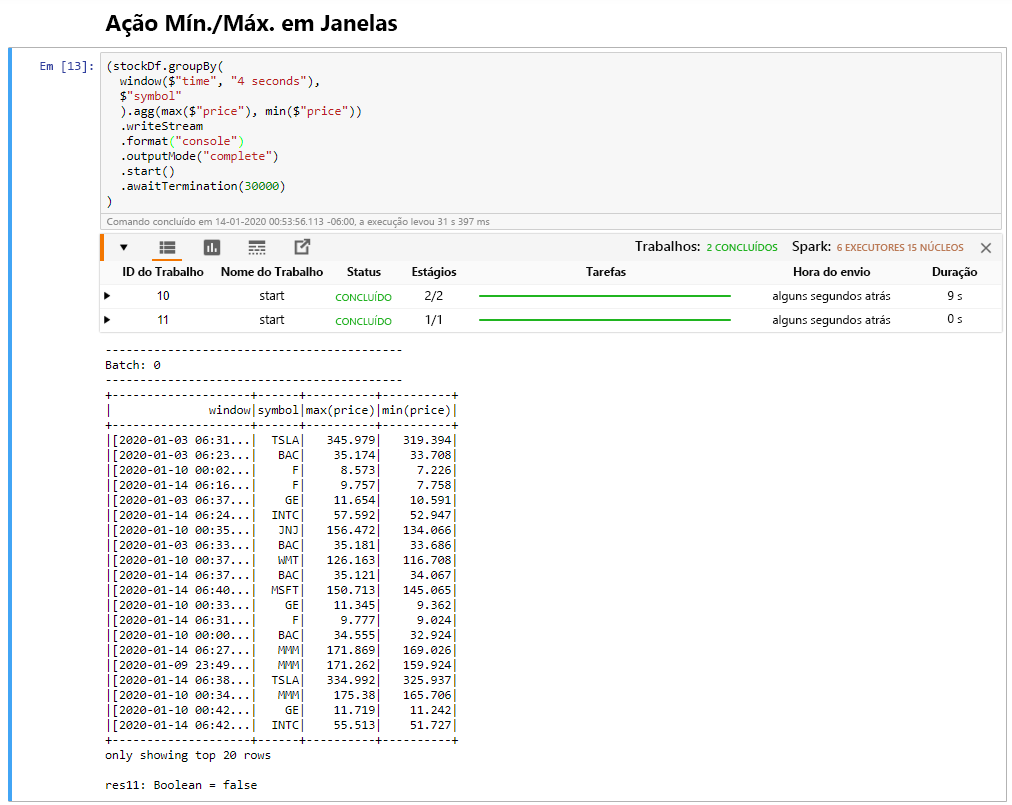
Selecione a célula Windowed Stock Min / Max e, em seguida, clique em Shift + Enter para executar a célula.
A célula é concluída com êxito quando fornece o preço máximo e mínimo para cada ação na janela de 4 segundos, que é definida na célula. Como discutido em uma unidade anterior, fornecer informações sobre janelas de tempo específicas é um dos benefícios que você ganha usando o Spark Structured Streaming.
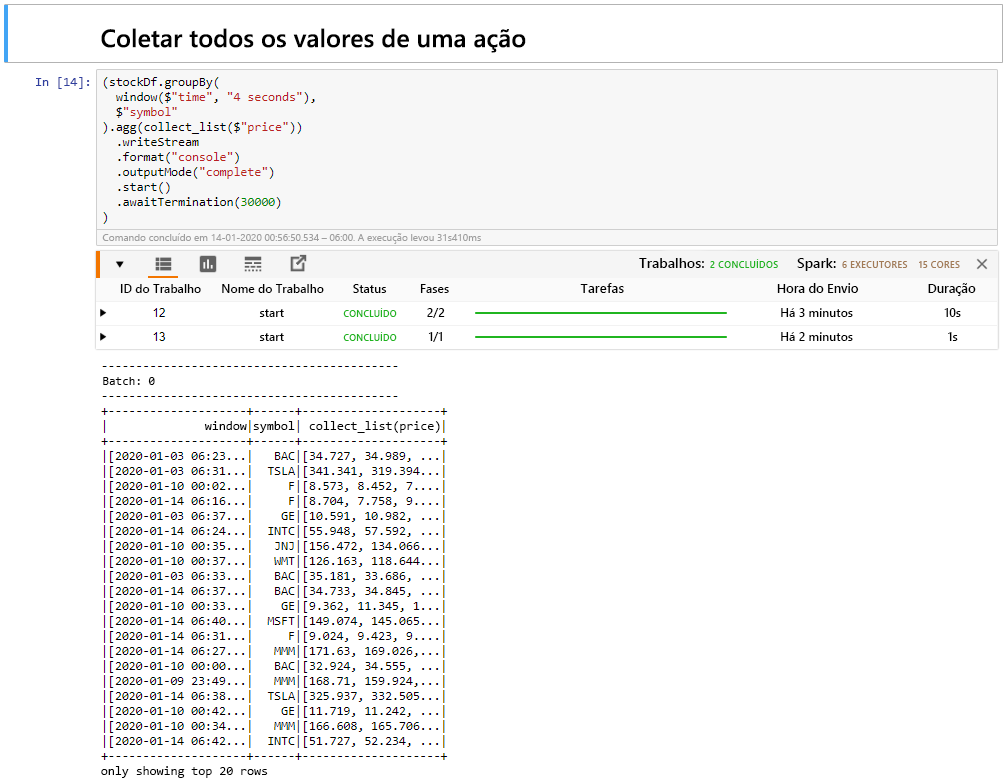
Selecione Coletar todos os valores para ações em uma célula da janela e clique em Shift + Enter para executar a célula.
A célula é concluída com êxito quando fornece uma tabela dos valores para os estoques na tabela. O outputMode está completo, para que todos os dados sejam mostrados.
Nesta unidade, você carregou um notebook Jupyter em um cluster Spark, conectou-o ao cluster Kafka, enviou os dados de streaming que estão sendo criados pelo arquivo produtor Python para o bloco de anotações Spark, definiu uma janela para os dados de streaming e exibiu os preços altos e baixos das ações nessa janela e exibiu todos os valores das ações na tabela. Parabéns, você realizou com sucesso streaming estruturado usando Spark e Kafka!